attributeerror: can only use .dt accessor with datetimelike values error occurs while converting string to datetime format in the specific situation. These specific situations are if are converting multiple string values into datetime format values (complete pandas dataframe column) and some of the values are having errors in conversion. Here we need to provide the error handling mechanism too with the syntax. Apart from this, In some scenario, the interpreter throws the same error when we do not pass the format for conversion. We face this error.
As I already explained the root cause for the error. In this section we will see the best way to fix can only use .dt accessor with datetime like values error.
Approach 1: Error handler type –
While converting any string object to datatime object in python we all use the to_datetime() function. But we do add any error handler type and if it fails, The interpreter thows the same error. Actually In to_datetime() we can provide an error handler type while calling the same function. Here is an example.
df['converted_col'] = pd.to_datetime(df['col'], errors='coerce')Suppose you have multiple values in the dataframe column “col” in string format and you want to convert them into datetime format. Then you can use the same syntax. If there will be any error in any row, It will convert the same into NaN and rest will be converted.
There are two more possible arguments with errors –
1. Ignore – It will throw the same input
2. raise – It will throw the exception and halt the process there only.
Approach 2 :
In some scenarios, if we add the format of the date conversion in the to_datetime() function. We can get rid of the same error. Here is an example of this –
df['converted_col'] = pd.to_datetime(df.col, format='%Y-%m-%d %H:%M:%S')Here “col” is the column where we are Appling the same function.
Note :
Here is the generic solution for all types of AttributeError. Please go throw it for in-depth knowledge on the same line.
What is AttributeError in Python ? Complete Overview
Thanks
Data Science Learner Team

Join our list
Subscribe to our mailing list and get interesting stuff and updates to your email inbox.
We respect your privacy and take protecting it seriously
Thank you for signup. A Confirmation Email has been sent to your Email Address.
Something went wrong.
#python-3.x #pandas #datetime
#python-3.x #панды #datetime
Вопрос:
Я пытаюсь преобразовать формат строки даты в числовой, но я получаю некоторую ошибку, мой столбец даты выглядит следующим образом :
train['AVERAGE_ACCT_AGE'].head(6)
0 0yrs 0mon
1 1yrs 11mon
2 0yrs 0mon
3 0yrs 8mon
4 0yrs 0mon
5 1yrs 9mon
Name: AVERAGE_ACCT_AGE, dtype: object
Я попробовал этот код, чтобы добавить формат даты и времени к этой переменной.
train['AVERAGE_ACCT_AGE']=pd.to_datetime(train['AVERAGE.ACCT.AGE'], format='%Y%m')
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
~Anaconda3libsite-packagespandascoretoolsdatetimes.py in _convert_listlike(arg, box, format, name, tz)
376 try:
--> 377 values, tz = conversion.datetime_to_datetime64(arg)
378 return DatetimeIndex._simple_new(values, name=name, tz=tz)
pandas_libstslibsconversion.pyx in pandas._libs.tslibs.conversion.datetime_to_datetime64()
TypeError: Unrecognized value type: <class 'str'>
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
<ipython-input-49-13f5c298f460> in <module>()
----> 1 train['AVERAGE_ACCT_AGE']=pd.to_datetime(train['AVERAGE.ACCT.AGE'], format='%Y-%m')
~Anaconda3libsite-packagespandascoretoolsdatetimes.py in to_datetime(arg, errors, dayfirst, yearfirst, utc, box, format, exact, unit, infer_datetime_format, origin, cache)
449 else:
450 from pandas import Series
--> 451 values = _convert_listlike(arg._values, True, format)
452 result = Series(values, index=arg.index, name=arg.name)
453 elif isinstance(arg, (ABCDataFrame, MutableMapping)):
~Anaconda3libsite-packagespandascoretoolsdatetimes.py in _convert_listlike(arg, box, format, name, tz)
378 return DatetimeIndex._simple_new(values, name=name, tz=tz)
379 except (ValueError, TypeError):
--> 380 raise e
381
382 if arg is None:
~Anaconda3libsite-packagespandascoretoolsdatetimes.py in _convert_listlike(arg, box, format, name, tz)
366 dayfirst=dayfirst,
367 yearfirst=yearfirst,
--> 368 require_iso8601=require_iso8601
369 )
370
pandas_libstslib.pyx in pandas._libs.tslib.array_to_datetime()
pandas_libstslib.pyx in pandas._libs.tslib.array_to_datetime()
ValueError: time data 0yrs 0mon doesn't match format specified
После этого я попробовал этот код, чтобы добавить игнорирование ошибки в столбец.
train['AVERAGE_ACCT_AGE']=pd.to_datetime(train['AVERAGE.ACCT.AGE'], format='%Y%m',errors='ignore',infer_datetime_format=True)
Его добавленный формат даты и времени, затем я этот код
train['yrs']=train['AVERAGE_ACCT_AGE'].dt.year
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-50-39b8c6e07f77> in <module>()
----> 1 train['yrs']=train['AVERAGE_ACCT_AGE'].dt.year
~Anaconda3libsite-packagespandascoregeneric.py in __getattr__(self, name)
4366 if (name in self._internal_names_set or name in self._metadata or
4367 name in self._accessors):
-> 4368 return object.__getattribute__(self, name)
4369 else:
4370 if self._info_axis._can_hold_identifiers_and_holds_name(name):
~Anaconda3libsite-packagespandascoreaccessor.py in __get__(self, obj, cls)
130 # we're accessing the attribute of the class, i.e., Dataset.geo
131 return self._accessor
--> 132 accessor_obj = self._accessor(obj)
133 # Replace the property with the accessor object. Inspired by:
134 # http://www.pydanny.com/cached-property.html
~Anaconda3libsite-packagespandascoreindexesaccessors.py in __new__(cls, data)
323 pass # we raise an attribute error anyway
324
--> 325 raise AttributeError("Can only use .dt accessor with datetimelike "
326 "values")
пожалуйста, помогите мне, как преобразовать тип объекта в числовой тип. Мне нужны столбцы по годам и месяцам отдельно.
AttributeError: Can only use .dt accessor with datetimelike values
Комментарии:
1. Числовой? Вам нужен столбец с количеством лет, а другой с месяцами или месяцами, преобразованными в годы, в столбце years?
2. Мне нужны годы и месяцы столбцов отдельно.
3. Может помочь подумать о том, чего вы на самом деле хотите. 1 год и 11 месяцев — это не дата, это промежуток времени. Вы хотите отслеживать эту длину? Или получить дату задолго до настоящего времени? Или что-то еще?
4. да, ArKF я хочу, чтобы время представления
Ответ №1:
Столбец не Datetime имеет формата.
Вот быстрый способ перевести его в числовое значение. Я использую больше строк, чем необходимо.
# doing this so we can have it in string format
train['AVERAGE_ACCT_AGE'] = train['AVERAGE_ACCT_AGE'].astype(str)
#Now remove the trailing or any such spaces
train['AVERAGE_ACCT_AGE'] = train['AVERAGE_ACCT_AGE'].map(lambda x: x.strip())
#Next we split and expand the column into 2 columns:
train[['yrs','months']] = train['AVERAGE_ACCT_AGE'].str.split(' ',n=1,expand=True)
#remove characters from new columns,
#I am assuming the characters remain the same
train['yrs'] = train['yrs'].str.replace('yrs','')
train['months'] = train['months'].str.replace('mon','')
# Convert yrs to float
train['yrs'] = train['yrs'].astype('float')
# Convert months to float
train['months'] = train['yrs'].astype('float')
Надеюсь, это поможет.
I built a custom transform primitive that takes in a Boolean and a Datetime and returns the time since the previous True value. The primitive works fine by itself, but once I stack it on top of a last aggregation primitive and a weekend transformation primitive, I run into the error: Can only use .dt accessor with datetimelike values. It seems like Featuretools is sending afloat instead of a Datetime as the second input into the custom primitive.
Below is the code to produce the error with the attached label times and EntitySet.
I have also included my fix (commented out) where I filter the datetime to make sure it is indeed a datetime.
cutoff_and_es.zip
import pandas as pd import numpy as np import featuretools as ft import featuretools.variable_types as vtypes from featuretools.primitives import make_trans_primitive from featuretools.primitives import make_agg_primitive def time_since_true(boolean, datetime): """Calculate time since previous true value (for a Boolean) in seconds""" ## This line works to filter out non datetime values # if np.any(np.array(boolean) == 1) and (pd.core.dtypes.common.is_datetimelike(datetime)): # Just using this line causes an error if np.any(np.array(boolean) == 1): # Create dataframe sorted from oldest to newest df = pd.DataFrame({'value': boolean, 'date': datetime}). sort_values('date', ascending=False).reset_index() older_date = None # Iterate through each date in reverse order for date in df.loc[df['value'] == 1, 'date']: # If there was no older true value if older_date == None: # Subset to times on or after true times_after_idx = df.loc[df['date'] >= date].index else: # Subset to times on or after true but before previous true times_after_idx = df.loc[(df['date'] >= date) & ( df['date'] < older_date)].index older_date = date # Calculate time since previous true df.loc[times_after_idx, 'time_since_previous'] = ( df.loc[times_after_idx, 'date'] - date).dt.total_seconds() return list(df['time_since_previous'])[::-1] # Handle case with no true values else: return [np.nan for _ in range(len(boolean))] # Specify the inputs and return time_since_previous_true = make_trans_primitive(time_since_true, input_types=[ vtypes.Boolean, vtypes.Datetime], return_type=vtypes.Numeric) # Read in EntitySet es = ft.read_pickle('churn_example/') # Read in cutoff times cutoff_times = pd.read_csv('cutoff_times.csv', index_col=0, parse_dates=['cutoff_time']) cutoff_times = cutoff_times.drop_duplicates(subset=['msno', 'cutoff_time']) cutoff_times = cutoff_times.dropna(subset=['label']) agg_primitives = ['last'] # Specify transformation primitives trans_primitives = ['weekend', time_since_previous_true] # Calculate the feature matrix feature_matrix, feature_defs = ft.dfs(entityset=es, target_entity='members', agg_primitives=agg_primitives, trans_primitives=trans_primitives, cutoff_time=cutoff_times.iloc[:100], cutoff_time_in_index=True, chunk_size=1000, n_jobs=1, verbose=1)
In this article we will see how to solve errors related to pd.to_datetime() in Pandas.
Typical errors for datetime conversion in Pandas are:
ParserError: Unknown string format: 27-02-2022 sdsd6:25:00 PMAttributeError: Can only use .dt accessor with datetimelike valuesValueError: only leading negative signs are allowedValueError: time data '1975-02-23T02:58:41.000Z' does not match format '%H:%M:%S' (match)
This could be due to:
- mixed dates and time formats in single column
- wrong date format
- datetime conversion with errors
Setup
In this tutorial we will work with this dataset from Kaggle: earthquake-database.
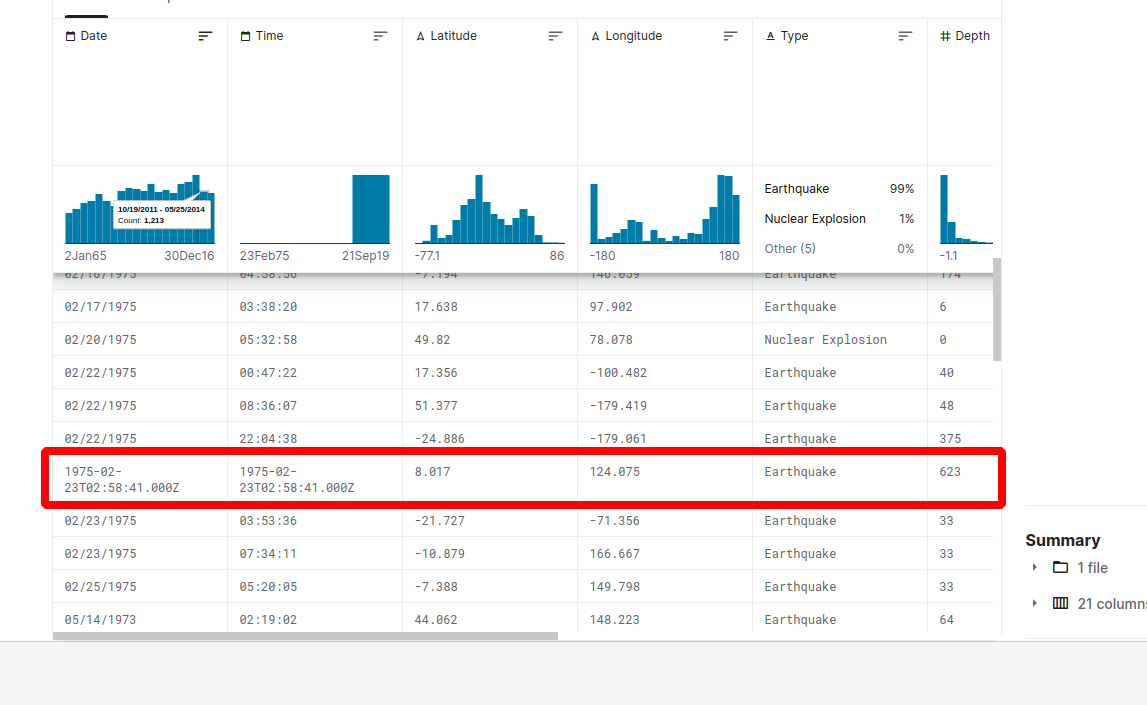
As we can see from the image above there are errors related to mixed formats in the dataset:
Detect wrong dates in Pandas — errors=’coerce’
First we will try to detect the wrong date of time format by using the date parameter — errors='coerce'.
So after looking at the data we know that column «Time» has the following format: '%H:%M:%S'.
Now we can try to parse all times in this column and extract only the ones which are parsed with errors:
df[pd.to_datetime(df['Time'], format='%H:%M:%S', errors='coerce').isna()]['Time']
the result is 3 rows with wrong format:
3378 1975-02-23T02:58:41.000Z
7512 1985-04-28T02:53:41.530Z
20650 2011-03-13T02:23:34.520Z
Name: Time, dtype: object
Detect mixed time formats — str.len()
Let’s see how to detect problematic values in the DateTime column of Pandas DataFrame. We can find the wrong date format by using string methods.
We will count the length of each date time:
df['Time'].str.len().value_counts()
the results show us 3 problematic rows:
8 23409
24 3
Name: Time, dtype: int64
To extract the wrong or different ones we can do:
df[df['Time'].str.len() > 8]['Time']
Which will give us:
3378 1975-02-23T02:58:41.000Z
7512 1985-04-28T02:53:41.530Z
20650 2011-03-13T02:23:34.520Z
Name: Time, dtype: object
To exclude rows with different rows we can do:
df = df[df['Date'].str.len() == 8]
This way is better for for working with date or time formats like:
- HH:MM:SS
- dd/mm/YYYY
Infer date and time format from datetime
This option is best when we need to work with formats which has date and time like:
- ‘%Y-%m-%dT%H:%M:%S.%f’
- ‘%Y-%m-%dT%H:%M:%S’
First we will find the most frequent format in the column by:
import numpy as np
from pandas.core.tools.datetimes import _guess_datetime_format_for_array
array = np.array(df["Date"].to_list())
_guess_datetime_format_for_array(array)
This would give us:
'%m/%d/%Y'
Next we will try to convert the whole column with this format:
pd.to_datetime(df["Date"], format='%m/%d/%Y')
This will result into error:
ValueError: time data '1975-02-23T02:58:41.000Z' does not match format '%m/%d/%Y' (match)
Now we can exclude rows with this format or convert them with different format:
Semantic date errors in Pandas
Sometimes there isn’t a code error but the date is wrong. This is when there are parsing errors. For example day and month are wrongly inferred or there are two date formats. To find more to this problem check:
How to Fix Pandas to_datetime: Wrong Date and Errors
Convert string to datetime
If you want to find more about convert string to datetime and infer date formats you can check: Convert String to DateTime in Pandas
Привет, я использую pandas для преобразования столбца в месяц.
Когда я читаю свои данные, они являются объектами:
Date object
dtype: object
Поэтому я сначала делаю их на дату, а затем пытаюсь сделать их месяцами:
import pandas as pd
file = '/pathtocsv.csv'
df = pd.read_csv(file, sep = ',', encoding='utf-8-sig', usecols= ['Date', 'ids'])
df['Date'] = pd.to_datetime(df['Date'])
df['Month'] = df['Date'].dt.month
Также, если это помогает:
In [10]: df['Date'].dtype
Out[10]: dtype('O')
Итак, ошибка, которую я получаю, выглядит так:
/Library/Frameworks/Python.framework/Versions/2.7/bin/User/lib/python2.7/site-packages/pandas/core/series.pyc in _make_dt_accessor(self)
2526 return maybe_to_datetimelike(self)
2527 except Exception:
-> 2528 raise AttributeError("Can only use .dt accessor with datetimelike "
2529 "values")
2530
AttributeError: Can only use .dt accessor with datetimelike values
EDITED:
Столбцы даты выглядят следующим образом:
0 2014-01-01
1 2014-01-01
2 2014-01-01
3 2014-01-01
4 2014-01-03
5 2014-01-03
6 2014-01-03
7 2014-01-07
8 2014-01-08
9 2014-01-09
Есть ли у вас идеи?
Большое спасибо!
Ответ 1
Ваша проблема здесь в том, что to_datetime молча провалился, поэтому dtype остался как str/object, если вы установите param errors='coerce', то если преобразование не удастся для какой-либо конкретной строки, тогда эти строки будут установлены в NaT.
df['Date'] = pd.to_datetime(df['Date'], errors='coerce')
Так что вам нужно выяснить, что не так с этими конкретными значениями строк.
Смотрите документы
Ответ 2
Ваша проблема здесь в том, что dtype «Date» остался как str/object. Вы можете использовать параметр parse_dates при использовании read_csv
import pandas as pd
file = '/pathtocsv.csv'
df = pd.read_csv(file, sep = ',', parse_dates= [col],encoding='utf-8-sig', usecols= ['Date', 'ids'],)
df['Month'] = df['Date'].dt.month
Из документации по параметру parse_dates
parse_dates: bool или список int или имен или список списков или dict, по умолчанию FalseПоведение выглядит следующим образом:
- логическое значение. Если True → попробуйте выполнить синтаксический анализ индекса.
- список int или имен. например Если [1, 2, 3] ->, попробуйте проанализировать столбцы 1, 2, 3, каждый как отдельный столбец даты.
- список списков. например Если [[1, 3]] → объединить столбцы 1 и 3 и проанализировать как один столбец даты.
- диктовать, например {‘Foo: [1, 3]} → проанализировать столбцы 1, 3 как дату и результат вызова‘ foo
Если столбец или индекс не могут быть представлены в виде массива даты и времени, скажем, из-за неразборчивого значения или комбинации часовых поясов, столбец или индекс будут возвращены без изменений в качестве типа данных объекта. Для нестандартного анализа даты и времени используйте
pd.to_datetimeпослеpd.read_csv. Чтобы проанализировать индекс или столбец со смесью часовых поясов, укажите, чтоdate_parserявляется частично примененнымpandas.to_datetime()сutc=True. Дополнительную информацию смотрите в разделе Анализ CSV со смешанными часовыми поясами.Note: A fast-path exists for iso8601-formatted dates.
Соответствующим случаем для этого вопроса является «список целых или имен».
col — это индекс столбцов «Date», который анализируется как отдельный столбец даты.