- Назад
- Обзор: Introduction to HTML
- Далее
Написать HTML — здорово, но как понять, где ошибка, когда что-то не работает? В этой статье описаны несколько инструментов, которые помогают искать и исправлять ошибки в HTML.
| Что нужно знать: | Базовые знания HTML на уровне Начало работы с HTML, Основы редактирования текста в HTML, и Создание гиперссылок. |
|---|---|
| Чему вы научитесь: | Искать проблемы в HTML с помощью инструментов отладки. |
Отладка — это не страшно
Во время написания какого-нибудь кода, обычно все идёт хорошо, пока не появляется тот момент, когда вы совершаете ошибку. Итак, ваш код не работает, или работает не так, как вы задумывали. Если вы попытаетесь скомпилировать неработающую программу на языке Rust, компилятор укажет на ошибку:
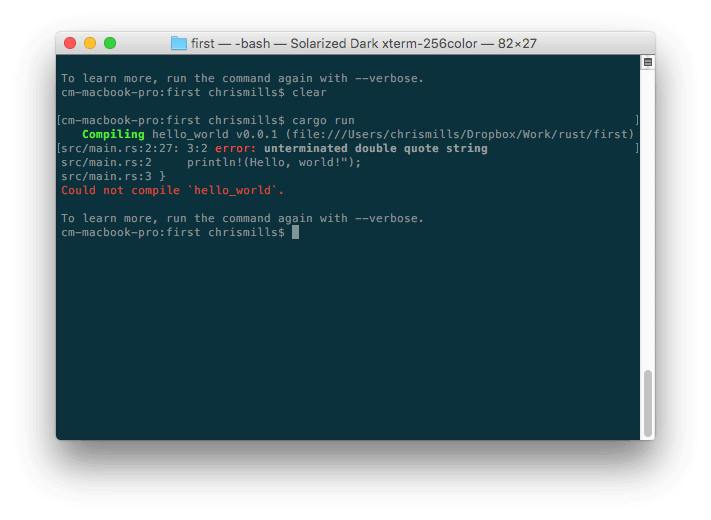 В данном случае, сообщение об ошибке понять относительно просто — «unterminated double quote string». Если вы внимательно посмотрите на
В данном случае, сообщение об ошибке понять относительно просто — «unterminated double quote string». Если вы внимательно посмотрите на println!(Hello, world!"); , то заметите, что здесь отсутствует двойная кавычка. Разумеется, сообщения об ошибках могут становиться куда более сложными для понимания по мере роста вашего кода, и даже самые простые случаи могут показаться пугающими для тех, кто ничего не знает о Rust.
Но не бойтесь отладки! Чтобы комфортно писать и отлаживать любой код, нужно понимать язык и его инструменты.
HTML и отладка
HTML не так сложен к пониманию, как Rust. HTML не компилируется в какую-либо другую форму перед тем, как браузер проанализирует это и покажет результат (он является интерпретируемым, а не компилируемым). Синтаксис HTML элементов намного понятнее, чем у «настоящих языков программирования», таких как Rust, JavaScript, или Python (en-US). Способ, которым браузеры читают HTML более толерантен, чем у языков программирования, интерпретирующих свой код строже. Это одновременно и плохо, и хорошо.
Толерантный код
Так что же означает толерантный? В общих чертах, когда вы напортачили в коде, есть два типа ошибок, с которыми вы столкнётесь:
- Синтаксические ошибки (Syntax errors): Это ошибки в правильности написания, как это было выше, в примере с Rust. Такие обычно легко исправлять, в той мере, в какой вы знакомы с синтаксисом языка и знаете, что означают сообщения об ошибках.
- Логические ошибки (Logic errors): Это ошибки, появляющиеся в том случае, если синтаксис корректен, но код не выполняет своего предназначения, то есть программа выполняется неверно. Такие исправлять сложнее, чем синтаксические, поскольку не выводится сообщений, указывающих место, где вы ошиблись.
HTML не страдает от синтаксических ошибок, потому что браузер читает код толерантно, в том смысле, что страницы могут отображаться даже если синтаксические ошибки присутствуют. Браузеры имеют встроенные правила по интерпретации неверно написанной разметки, и вы можете запустить что-либо, даже если вы имели в виду другое. Это может стать настоящей проблемой!
Примечание: На заметку: HTML читается толерантно, потому что когда веб только появился, было решено позволить людям публиковать контент даже при условии некорректностей в коде, так как это куда более важно, чем уверенность в абсолютно верном синтаксисе. Веб не был бы сейчас так популярен, если бы относился к новичкам строго.
Активное обучение: Знакомство с толерантным кодом
Время изучить природу толерантного кода в HTML.
- Для начала, скачайте наш пример отладки и сохраните локально. Эта демонстрация намеренно написана с ошибками, которые нам предстоит обнаружить.
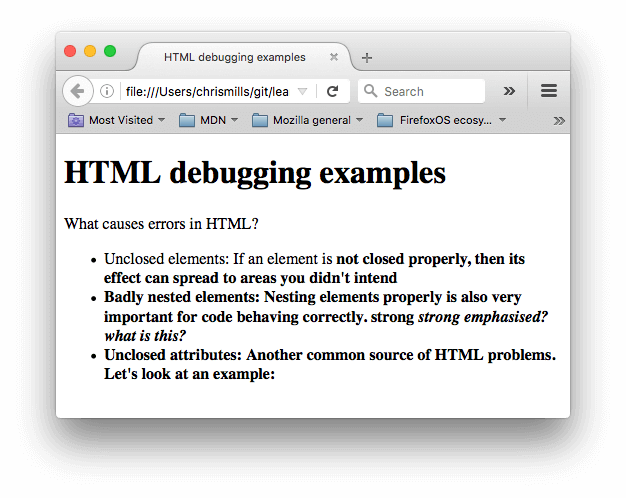
- Далее, откройте её в браузере. Вы увидите нечто вроде этого :

- Сейчас документ выглядит не особо хорошо; Давайте посмотрим в код и выясним почему (Показано только тело документа):
<h1>HTML debugging examples</h1> <p>What causes errors in HTML? <ul> <li>Unclosed elements: If an element is <strong>not closed properly, then its effect can spread to areas you didn't intend <li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasised?</strong> what is this?</em> <li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> </ul> - Рассмотрим проблемы:
- У параграфа и элемента списка не закрыты теги. На изображении выше видно, что разметка не пострадала, так как браузеру легко сделать вывод о том, где заканчивается один элемент и начинается другой.
- Первый
<strong>элемент также не имеет закрывающего тега. Это уже более проблематично, так как сложно сказать, где элемент должен заканчиваться. На деле, весь оставшийся текст был выделен жирным. - Следующая часть нарушает правила вложенности:
<strong>strong <em>strong emphasised?</strong> what is this?</em>. В этом случае код тоже сложно проинтерпретировать по причине, описанной выше. - В атрибуте
hrefотсутствует закрывающая двойная кавычка. Это послужило причиной крупной проблемы — ссылка не воспроизвелась вовсе.
- Сейчас же посмотрим, как браузер сгенерировал собственную разметку, в противовес исходной разметке документа. Чтобы сделать это, воспользуемся инструментами разработчика. Если вы не знакомы с инструментами разработчика, потратьте несколько минут на Обзор инструментов разработки в браузерах.
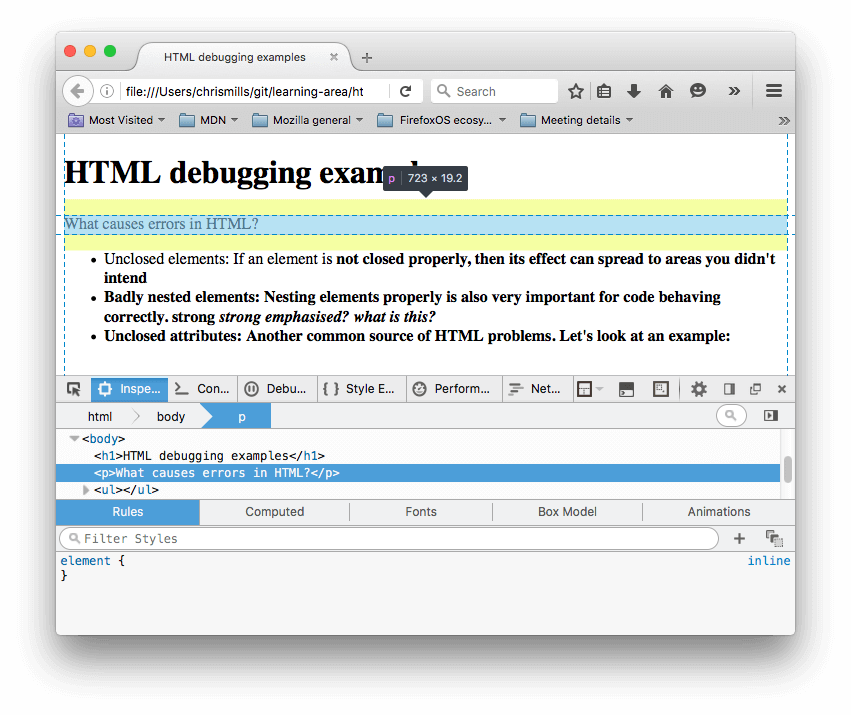
- В DOM инспекторе вы можете увидеть как сгенерировалась новая разметка:

- Используя DOM инспектор, давайте рассмотрим детали нашего кода, чтобы увидеть, как браузер пытается исправить наши ошибки в HTML (мы обозреваем в Firefox; другой современный браузер должен выдать те же результаты):
- Параграфы и элементы списка получены с закрывающими тегами.
- Было неочевидно, где элемент
<strong>должен был закрыться, так что браузер обернул каждый отдельный блок текста своими собственными тегами strong, причём до самого низа документа! - Некорректная вложенность была исправлена браузером следующим образом:
<strong>strong <em>strong emphasised?</em> </strong> <em> what is this?</em> - Ссылка с отсутствующими двойными кавычками была удалена насовсем. Последний элемент списка будет выглядеть так:
<li> <strong>Unclosed attributes: Another common source of HTML problems. Let's look at an example: </strong> </li>
Валидация HTML
Из примера выше ясно, что стоит проверять валидность HTML. В простом примере сверху можно просто просмотреть весь код и найти ошибки, но как быть с огромными, сложными страницами?
Лучше всего проверить страницу в сервисе валидации разметки. Его создал и поддерживает W3C — организация, которая занимается спецификациями HTML, CSS и других веб-технологий. Сервис проверит ваш HTML и составит отчёт по ошибкам в нем.
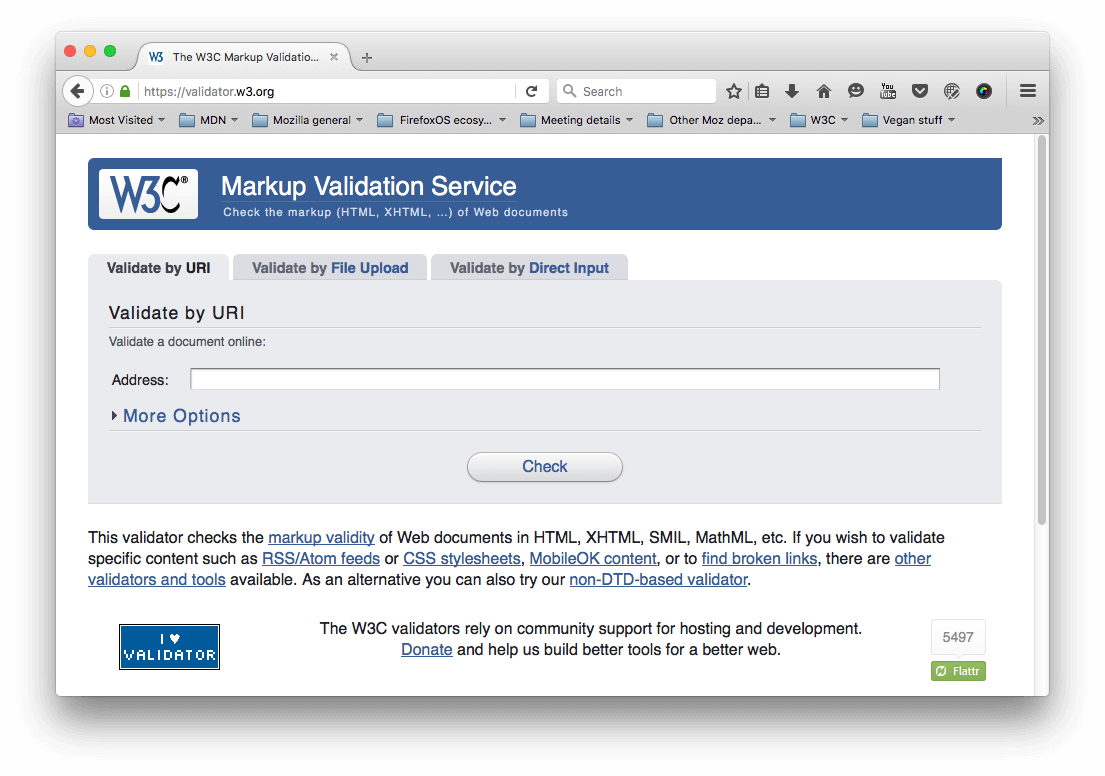
HTML можно проверить по адресу, загрузив файл или напрямую ввести код HTML.
Активное обучение: Валидируем HTML-документ
Попробуем проверить документ-пример.
- Откройте сервис валидации разметки в браузере.
- Перейдите в режим Validate by Direct Input.
- Скопируйте весь код документа (не только body) и вставьте в место для ввода.
- Нажмите на Check (проверить).
Вы увидите список ошибок и другую информацию.
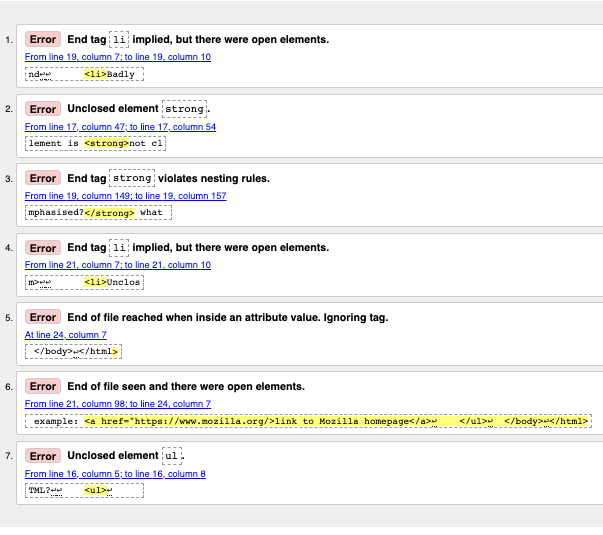
Работа с сообщениями об ошибках
Обычно сразу ясно, что значат сообщения, но иногда приходится постараться, чтобы понять, в чем дело. Сейчас мы пройдёмся по всем ошибкам и разберём, что они значат. Обратите внимание, что в сообщениях указаны строка и столбец кода, чтобы ошибки было проще искать.
- «End tag
liimplied, but there were open elements» (2 instances): Нет явного закрывающего тега, хотя браузер догадывается, где он должен быть. Сообщение указывает на строку после той, на которой ожидался закрывающий тег, но вы найдёте нужное место. - «Unclosed element
strong«: Это очень простая ошибка — элемент<strong>не закрыт, и сообщение указывает прямо на открывающий тег. - «End tag
strongviolates nesting rules»: Элемент неправильно вложен — на этом уровне нет парного открывающего тега. - «End of file reached when inside an attribute value. Ignoring tag»: Загадочное сообщение. Дело в том, что где-то (скорее всего, в конце документа) неправильно прописано свойство элемента, и конец файла оказался внутри этого свойства. В браузере не видно ссылки — скорее всего, проблема рядом с ней.
- «End of file seen and there were open elements»: Файл закончился, но некоторые элементы не закрыты. Сообщение указывает на конец файла, в данном случае не закрыт элемент
example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> ↩ </ul>↩ </body>↩</html>
Примечание: Свойство без закрывающей кавычки может проглотить закрывающий тег — браузер считает его частью значения этого свойства.
- «Unclosed element
ul«: Странно, ведь элемент<ul>закрыт. Настоящая проблема всё там же — элемент<a>не закрыт из-за недостающей кавычки в свойстве.
Если некоторые ошибки кажутся вам странными, начните исправление с остальных и проверьте документ ещё раз. Иногда одна ошибка ломает большую часть документа.
Когда вы увидите эту надпись, в вашем документе больше нет ошибок:
![]()
Заключение
Теперь вы умеете отлаживать HTML. С новыми знаниями вам будет проще разобраться и в отладке более сложных языков — например, CSS и JavaScript. На этом мы заканчиваем вводный модуль курса HTML — время попробовать свои силы в упражнениях.
- Назад
- Обзор: Introduction to HTML
- Далее
В этом модуле
Браузер выдает ошибку при просмотре страницы
Веб-страницы сами по себе редко вызывают сообщение об ошибках. Причина в том, что большинство браузеров просто игнорируют код HTML, который не понимают. Если вы видите сообщение об ошибке при просмотре вашей страницы, причина, скорее всего, в самом браузере или в подключении к интернет. Новые версии браузеров скрывают ошибки программирования, останавливая неправильные сценарии без отображения сообщения об ошибке посетителю.
Если ваш браузер настроен так, чтобы отображать ошибки сценария, вы увидите сообщения об ошибке, когда сценарий написан неправильно. Ошибки не всегда легко отследить и исправить, но определение причины –зачастую самый важный шаг. Если вы получили сообщение об ошибке, сделайте следующее.
Если ошибка в браузере
- Если браузер отображает сообщение Windows «Illegal operation», вы, скорее всего, не сможете решить проблему, сменив страницу. Это может быть внутренняя проблема. Перезагрузите компьютер и попробуйте просмотреть страницу снова.
- Если вы все еще не можете просмотреть страницу, вам, возможно, нужен обновленный браузер. (Браузеры Microsoft можно найти на www.microsoft.com/windows/ie, а Netscape – на home.netscape.com/download.) Также проблема часто бывает вызвана вашей видеокартой или программным обеспечением – вам стоит обновить видеодрайвер или проверить, поддерживает ли браузер видеокарту.
Если браузер сообщает, что не может найти и отобразить страницу
- Браузеры используют набор различных сообщений о том, что они не могут отобразить страницу. В любом случае сперва проверьте, не ошиблись ли вы где-нибудь в имени домена или страницы. Проверьте расширение файла и веб-страницы и правильность написания имени домена, такого как www.w3.org.

Если вы набрали неправильное имя или файл находится не в том месте, ваш браузер не сможет его отыскать
- Если вы ввели верный адрес, возможно, файл не находится сейчас в этом месте. Используя вашу FTP программу – или Windows Explorer для локальных файлов – убедитесь, что вы сохранили или опубликовали свою страницу в нужном месте на веб-сервере.
- Если у вас не получается открыть стартовую страницу вашего сервера – набрав, например, www.yahoo.com, – то возможно, что ваш веб-сервер не настроен для поиска имени файла вашей страницы. Проверьте, какое имя ищет сервер – зачастую это index.htm или default.htm.
- Если браузер не может отыскать домен указанного вами сервера, возможно, подключение к интернет или веб-сервер не работает. Проверьте, подключены ли вы к интернет. Если подключены, попробуйте загрузить сервер позже или свяжитесь с вашим провайдером или администратором веб-сервера.

Браузер выводит сообщение о безопасности
- Есть две причины ошибок безопасности – параметры доступа на сервере и предосторожности, принятые браузером. Если ваш браузер отображает сообщения вроде «401 Unauthorized«, «403 Forbidden» или «You are not authorized to view this page», веб-сервер настроен так, чтобы не допускать вас на эту страницу. Для решения этой проблемы измените настройки безопасности, разрешив анонимный вход (или доступ для определенных пользователей).
- Если браузер отображает свое собственное сообщение безопасности для вашей страницы, это означает, что настройки браузера не допускают использования некоторых особенностей вашей страницы.
Предупреждения зачастую являются результатом настроек безопасности браузера
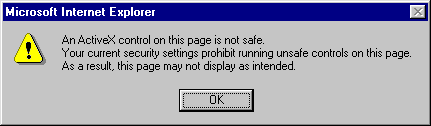
Если, к примеру, ваша страница пытается загрузить ActiveX, настройки безопасности могут не допустить этого. Чтобы просмотреть страницу, вы можете поступиться ограничениями безопасности браузера. Чтобы решить проблему для посетителей, убедитесь, что вы используете компоненты только из надежных источников – и предусмотрите альтернативную страницу для посетителей, которые будут следовать правилам безопасности.
Недавно мы рассказали о том, как начать писать программы на JavaScript:
- что такое HTML и JavaScript;
- из чего состоят скрипты;
- как и где их выполнять и куда вставлять;
- где искать готовые решения и что с ними потом делать;
- как работать с разными элементами и обрабатывать нажатия клавиш.
Теперь шагнём дальше — изучим отладку скриптов в браузере и посмотрим, чем она может нам помочь.
Что такое отладка
Отладка — это поиск и исправление ошибок в программе. Например, мы написали скрипт, добавили его на страницу, настроили запуск по нажатию кнопки — а при нажатии ничего не происходит. При этом в консоли нет никаких ошибок — все команды верные, браузер просто что-то делает, а результата нет. Отладка нужна как раз для того, чтобы найти ошибку и исправить её.
Варварская отладка
Самый примитивный вариант отладки — добавить в код на JavaScript метод console.log(), поместив в скобки нужные данные для отладки. Console.log() — это просто способ вывести в консоль какой-нибудь текст.
Например, внутри функции можно сказать: console.log(‘Вызвана такая-то функция’) — и в нужный момент мы увидим, что функция вызвалась (или нет).
Минус этого подхода в том, что в коде появляется много отладочного мусора. А ещё, если мы не предусмотрели логирование для какой-то функции, то мы не поймаем в ней ошибку.
К счастью, помимо console.log() человечество изобрело много удобных инструментов отладки.
Что нужно для отладки
Для несложных проектов на JavaScript проще всего использовать встроенный отладчик в браузере Google Chrome. Единственное ограничение — он работает только с файлами скриптов, а не со встроенным в страницу кодом. Это значит, что если код скрипта находится внутри HTML-файла внутри тега <script>, то отладка не сработает.
Чтобы открыть панель отладки в Chrome, нажимаем ⌘+⌥+I и переходим на вкладку Sources (Источники):

Открываем скрипт
Допустим, мы хотим посмотреть, как работает скрипт из задачи про выпечку и как он перебирает все варианты.
Всё, что у нас есть, — это код. Чтобы мы смогли его отладить, его нужно положить в отдельный файл скрипта, присоединить к HTML-документу и запустить в браузере.
Открываем любой текстовый редактор, например Sublime Text, вставляем код скрипта и сохраняем файл как temp.js. Имя может быть любым, а после точки всегда должно стоять js — так браузер поймёт, что перед нами скрипт.
После этого в новом файле вставляем шаблон пустой HTML-страницы и подключаем наш скрипт — добавляем в раздел <body> такую строку:
<script type="text/javascript" src="temp.js"></script>
Получиться должно что-то вроде такого:
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title></title>
</head>
<body>
<script type="text/javascript" src="temp.js"></script>
</body>
</html>Сохраняем этот код как HTML-файл, например index.html, и кладём в ту же папку, что и скрипт. Теперь заходим в папку и дважды щёлкаем по HTML-файлу, чтобы открыть эту страницу в браузере:

На странице ничего нет, но нам нужна не страница, а скрипт, поэтому находим слева наш файл temp.js и нажимаем на него — откроется код скрипта. Теперь можно начинать отладку:

Добавляем точки остановки
Точка остановки — это место, в котором наш скрипт должен остановиться и ждать дальнейших действий программиста. Их ещё называют брейкпоинты, от английского breakpoint — точка, где всё останавливается.
Когда скрипт доходит до этой точки, он ставит скрипт на паузу. При этом все данные и значения переменных скрипта остаются в памяти — в них можно заглянуть.
Брейкпоинт нужен для того, чтобы выполнить скрипт по шагам, начиная с первой команды. Чтобы его установить, нажимаем на номер строки с первой командой — в нашем случае это строка 2:

Обновим страницу и увидим, что скрипт начал работу и остановился. Но он остановился не на второй строке, а на шестой — всё потому, что это первая строка в скрипте, где происходит какое-то действие. Дело в том, что просто объявление новых переменных не влияет на работу скрипта, поэтому он ищет первую команду с действием. В нашем случае — это цикл for:

Пошаговая отладка
Чтобы посмотреть на работу скрипта по шагам, надо нажимать F9 или стрелку вправо с точкой на панели отладки:

Каждый раз, как мы будем нажимать F9 или эту кнопку, скрипт будет переходить к следующей команде, выполнять её и снова становиться на паузу:

Добавляем переменные для отслеживания
Если просто выполнять скрипт по шагам, то мы увидим, какие команды и в каком порядке выполняются, но не будем знать, какие значения лежат в переменных на каждом шагу. Их можно увидеть, просто наведя курсор на любую переменную — над ней появится всплывающая подсказка с текущим значением. Но так работать неудобно — проще сразу видеть значения всех переменных.
Чтобы добавить переменную и видеть её значение во время выполнения, в панели отладки в разделе Watch нажимаем плюсик, вводим имя переменной, выбираем её из списка и нажимаем энтер:

Теперь видно, что на этом шаге значение переменной a равно нулю:

Точно так же добавим остальные переменные: i, b, c. Так мы увидим, что первые два цикла только начались, а внутренний прошёл уже три итерации:

Так, нажимая постоянно F9, мы прогоним весь скрипт до конца и посмотрим, при каких значениях какие условия выполняются и как находится решение:

Но у такого подхода есть минус — если вложенных циклов много или скрипт очень большой, то на пошаговое выполнение уйдёт много времени. Чтобы не перебирать всё вручную, ставят дополнительные брейкпойнты в нужных местах.
Отладка брейкпойнтами
Допустим, нам важно понять, в какой момент скрипт находит и выдаёт решение. Глядя в код, мы понимаем, что как только скрипт дошёл до команды console.log() — он нашёл очередное решение. Это значит, что мы можем поставить брейкпоинт только на эту строчку и не прогонять вручную весь скрипт: он сам остановится, когда дойдёт до неё, а мы сможем посмотреть значения переменных в этот момент.
Для этого:
- Нажимаем снова на строку 2 и убираем предыдущую точку остановки.
- Ставим брейкпоинт на строку 20 — там, где происходит вывод решения в консоль.
- Нажимаем F8.
После этого скрипт продолжит работу сам и снова остановится, как только дойдёт до этой строки. Обратите внимание на значения переменных — они меняются к каждой остановке, а значит, скрипт работает как обычно, но останавливается в нужном нам месте:

Таких точек остановки можно поставить сколько угодно и в любой момент — на каждой из них отладчик остановится и покажет текущее состояние скрипта.
Зачем это всё
Отладка нужна, чтобы найти ошибки в программе. Если мы видим, что на очередном шаге в переменной находится не то, что мы ожидали увидеть, значит, что-то в коде идёт не так. Мы ставим брейкпоинт на начало нужных команд, запускаем отладку и находим команду, которая приводит к ошибке.
В следующей статье мы покажем на примере с реальным кодом, как отладка помогает находить и исправлять такие ошибки. Подпишитесь, чтобы не пропустить это.
Вёрстка:
Кирилл Климентьев
HTML — это язык гипертекстовой разметки. Благодаря ему мы видим не просто текст, а полноценные страницы с интерактивным контентом. Сегодня он поддерживается организацией W3C — World Wide Web Consortium. Она разрабатывает принципы и стандарты, в соответствии с которыми делаются все современные сайты.
Что такое ошибки HTML? Это несоответствие кода разметки общепринятым стандартам, руководству W3C. А код с ошибками иначе называют невалидным (с английского Invalid code).
Невалидный код работает (да!)
В отличие от языков программирования, где любая пропущенная ошибка останавливает программу, HTML очень даже неплохо работает с невалидным кодом. Его основная цель — отобразить страницу “как есть”. Однако тут и возникает заметная проблема.
Если часть тегов не закрыта, а другие находятся в неправильном месте с неверными атрибутами, компьютер все равно выводит страницу на экран. Но у разных браузеров это получится по-разному, а поисковик может совсем не найти часть вашей статьи. И вы вряд ли узнаете об этом, а SEO продвижение сайта в Google и Яндекс значительно замедлится.

Как проверить ошибки HTML
Какая ошибка выкинет сайт из поисковой выдачи, а на какую не обращать внимания? Ответ на этот вопрос хочет знать каждый. Конечно, основные факторы ранжирования поисковиков известны, но реальные алгоритмы остаются в тайне даже для большинства разработчиков Google и Яндекс. Поэтому самое надежное решение — полностью устранять невалидный код. А проверить ошибки HTML кода на странице удобнее всего на официальном сайте W3C.

Расшифровка ошибок на сайте validator.w3.org

Валидатор не выявил ошибок на странице
Откуда берутся ошибки HTML и невалидный код
В современном мире большинство сайтов создаются на CMS — системах управления контентом. А значит разметку HTML больше не приходится писать вручную. Такой подход сильно ускоряет и упрощает процесс разработки, но не без ложки дегтя.
При верстке страниц вручную любые ошибки легко устраняются, а код остается легко читаемым и полностью валидным. Но CMS, например, самый популярный движок WordPress, генерируют код автоматически. А значит уследить за ним на порядок сложнее, такой HTML трудно поддается корректировке.
И редко какие недостатки можно устранить из меню настроек. Почти всегда за этим надо лезть в библиотеки CMS, либо применять самописные плагины.
Если исправить все ошибки, сайт сразу попадет в ТОП? Никто не может давать гарантий, являлась ли конкретная ошибка причиной плохих позиций сайта или страницы. Поэтому стоит комплексно подходить к поисковому продвижению, исправляя и улучшая множество параметров.
Итоги
Летом 2021 года ведущий аналитик Google Джон Мюллер заявил, что ошибки HTML прямо не влияют на ранжирование. Но они точно играют свою косвенную роль в жизни каждого веб-сайта. В частности, невалидный код HTML может ломать сайт на некоторых устройствах (телефоны, планшеты и т.д.) и блокировать текст для поисковых роботов. А если поисковики не найдут часть контента на странице, о дальнейшем SEO продвижении сайта можно забыть.