Классификация ошибок
Отладка – это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
В целом сложность отладки обусловлена следующими причинами:
- требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
- психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
- возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
- отсутствуют четко сформулированные методики отладки.
В соответствии с этапом обработки, на котором проявляются ошибки, различают:
- синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы;
- логические ошибки — …;
- ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
- ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых.
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами, обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
- появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
- появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
- «зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
- несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
- неверное определение исходных данных,
- логические ошибки,
- накопление погрешностей результатов вычислений.

Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
- ручного тестирования;
- индукции;
- дедукции;
- обратного прослеживания.
Метод ручного тестирования
Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которыми была обнаружена ошибка. Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций. Данный метод часто используют как составную часть других методов отладки.
Метод индукции
Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рисунке в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о её проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов. В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции
По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину.
Метод обратного прослеживания
Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Методы и средства получения дополнительной информации
Для получения дополнительной информации об ошибке можно выполнить добавочные тесты или использовать специальные методы и средства:
- отладочный вывод;
- интегрированные средства отладки;
- независимые отладчики.
Отладочный вывод. Метод требует включения в программу дополнительного отладочного вывода в узловых точках. Узловыми считают точки алгоритма, в которых основные переменные программы меняют свои значения. Например, отладочный вывод следует предусмотреть до и после завершения цикла изменения некоторого массива значений. (Если отладочный вывод предусмотреть в цикле, то будет выведено слишком много значений, в которых, как правило, сложно разбираться.) При этом предполагается, что, выполнив анализ выведенных значений, программист уточнит момент, когда были получены неправильные значения, и сможет сделать вывод о причине ошибки.
Данный метод не очень эффективен и в настоящее время практически не используется, так как в сложных случаях в процессе отладки может потребоваться вывод большого количества — «трассы» значений многих переменных, которые выводятся при каждом изменении. Кроме того, внесение в программы дополнительных операторов может привести к изменению проявления ошибки, что нежелательно, хотя и позволяет сделать определенный вывод о ее природе.
Примечание. Ошибки, исчезающие при включении в программу или удалению из нее каких-либо «безобидных» операторов, как правило, связаны с «затиранием» памяти. В результате добавления или удаления операторов область затирания может сместиться в другое место и ошибка либо перестанет проявляться, либо будет проявляться по-другому.
Интегрированные средства отладки. Большинство современных сред программирования (Delphi, Builder C++, Visual Studio и т. д.) включают средства отладки, которые обеспечивают максимально эффективную отладку. Они позволяют:
- выполнять программу по шагам, причем как с заходом в подпрограммы, так и выполняя их целиком;
- предусматривать точки останова;
- выполнять программу до оператора, указанного курсором;
- отображать содержимое любых переменных при пошаговом выполнении;
- отслеживать поток сообщений и т. п.
Отладка с использованием независимых отладчиков.
При отладке программ иногда используют специальные программы — отладчики, которые позволяют выполнить любой фрагмент программы в пошаговом режиме и проверить содержимое интересующих программиста переменных. Как правило такие отладчики позволяют отлаживать программу только в машинных командах, представленных в 16-ричном коде.
Общая методика отладки программного обеспечения
Суммируя все сказанное выше, можно предложить следующую методику отладки программного обеспечения:
1 этап — изучение проявления ошибки — если выдано какое-либо сообщение или выданы неправильные или неполные результаты, то необходимо их изучить и попытаться понять, какая ошибка могла так проявиться. При этом используют индуктивные и дедуктивные методы отладки. В результате выдвигают версии о характере ошибки, которые необходимо проверить. Для этого можно применить методы и средства получения дополнительной информации об ошибке. Если ошибка не найдена или система просто «зависла», переходят ко второму этапу.
2 этап — локализация ошибки — определение конкретного фрагмента, при выполнении которого произошло отклонение от предполагаемого вычислительного процесса. Локализация может выполняться:
- путем отсечения частей программы, причем, если при отсечении некоторой части программы ошибка пропадает, то это может означать как то, что ошибка связана с этой частью, так и то, что внесенное изменение изменило проявление ошибки;
- с использованием отладочных средств, позволяющих выполнить интересующих нас фрагмент программы в пошаговом режиме и получить дополнительную информацию о месте проявления и характере ошибки, например, уточнить содержимое указанных переменных.
При этом если были получены неправильные результаты, то в пошаговом режиме проверяют ключевые точки процесса формирования данного результата. Как подчеркивалось выше, ошибка не обязательно допущена в том месте, где она проявилась. Если в конкретном случае это так, то переходят к следующему этапу.
3 этап — определение причины ошибки — изучение результатов второго этапа и формирование версий возможных причин ошибки. Эти версии необходимо проверить, возможно, используя отладочные средства для просмотра последовательности операторов или значений переменных.
4 этап — исправление ошибки — внесение соответствующих изменений во все операторы, совместное выполнение которых привело к ошибке.
5 этап — повторное тестирование — повторение всех тестов с начала, так как при исправлении обнаруженных ошибок часто вносят в программу новые.
Следует иметь в виду, что процесс отладки можно существенно упростить, если следовать основным рекомендациям структурного подхода к программированию:
- программу наращивать «сверху-вниз», от интерфейса к обрабатывающим подпрограммам, тестируя ее по ходу добавления подпрограмм;
- выводить пользователю вводимые им данные для контроля и проверять их на допустимость сразу после ввода;
- предусматривать вывод основных данных во всех узловых точках алгоритма (ветвлениях, вызовах подпрограмм).
Кроме того, следует более тщательно проверять фрагменты программного обеспечения, где уже были обнаружены ошибки, так как вероятность ошибок в этих местах по статистике выше. Это вызвано следующими причинами. Во-первых, ошибки чаще допускают в сложных местах или в тех случаях, если спецификации на реализуемые операции недостаточно проработаны. Во-вторых, ошибки могут быть результатом того, что программист устал, отвлекся или плохо себя чувствует. В-третьих, как уже упоминалось выше, ошибки часто появляются в результате исправления уже найденных ошибок.
Источник:

Добавил:
Upload
Опубликованный материал нарушает ваши авторские права? Сообщите нам.
Вуз:
Предмет:
Файл:
шпоры.doc
Скачиваний:
57
Добавлен:
29.05.2015
Размер:
28.35 Mб
Скачать
Тестирование
–выполнение
программы для набора проверочных сходных
значений и сравнение полученных
результатов с ожидаемыми.
Отладка
– процесс локализации и исправления
ошибок в программе. При тестировании
проверяется: работает ли программа и
все ее ветви в соответствии со своей
спецификацией. Для этого разрабатывается
стратегия тестирования.
Если
при тестировании полученные результаты
отличаются от эталонных, необходимо
определить местоположение ошибки
(локализовать ее), определить ее характер,
а затем выработать гипотезу о природе
ошибки.
Т.о.
локализация
— это нахождение места ошибки в программе.
Классификация
ошибок.
-
Синтаксические
ошибки. Синтаксические ошибки – это
ошибки, допущенные при неверном
употреблении конструкции языка.
Синтаксические ошибки, как правило,
обнаруживаются транслятором, и их
устранение не представляет особого
труда. -
Опечатки.
Опечатки, как правило, вызваны
невнимательностью программиста при
механическом наборе или редактировании
исх1 текста. Подобные ошибки, несмотря
на их видимую простоту, довольно сложно
находить без тщательной пошаговой
отладки. -
Ошибки
реализации алгоритма. Под эту категорию
попадают все ошибки вызванные неверным
программированием при верном алгоритме.
Данные
ошибки труднее всего находить, поскольку
их проявление зачастую зависит от
текущего содержимого памяти на конкретном
компьютере.
-
Ошибки
алгоритма. Алгоритм может содержать
логические ошибки, которые закономерно
приводят к ошибочной работе программы
при безупречном программировании.
Такие ошибки тяжело выявлять, поскольку
на них довольно часто накладываются
ошибки реализации. -
Ошибки
метода. Ошибки метода заключаются в
неверном описании метода вычисления.
Такие ошибки программисту обнаружить
достаточно тяжело, поскольку
ответственность за описание метода
лежит на эксперте в конкретной Предметн.
обл..
17 Документирование. Состав и содержание документов прилагаемых к программной системе.
Основу
отечественной нормативной базы в области
документирования ПС составляет комплекс
стандартов Единой системы программной
документации (ЕСПД). Основная и большая
часть комплекса ЕСПД была разработана
в 70-е и 80-е годы 20 века. Сейчас этот
комплекс представляет собой систему
межгосударственных стандартов стран
СНГ (ГОСТ), действующих на территории
РФ на основе межгосударственного
соглашения по стандартизации.
Единая
система программной документации —
это комплекс государственных стандартов,
устанавливающих взаимоувязанные правила
разработки, оформления и обращения
программ и программной документации.
Виды
документов:
Эксплутационные
– руководства пользователей
Технические
– при разработке ПО
Технические
-
Текст
программы (код, с необходимыми
комментариями) -
Описание
программы (сведения о логической
структуре и функционировании программы
-общие положения (обозначение и
наименование); функциональное назначение
(описываются классы задач, которые
решает программа); описание логической
структуры (архитектуры программной
системы); используемые технич средства;
вызов и загрузка программы -
Программа
и методика испытаний (Требования,
подлежащие проверке при испытании,
порядок и методы контроля) -объект
испытаний (наименование,область
применения,обозначение испытуемой
программы); цель испытаний (для чего?);
состав предъявляемой документации
(указывается документация, предоставляемая
при испытании); технические требования
(аппаратные средства, на которых
проводятся испытания); порядок проведения
испытания (все тесты, которые должна
пройти система, тестовые данные,
определяются сроки проведения испытаний,
состав комиссии, которая будет проводить
испытания). -
Пояснительная
записка (общее описание и функционирование
программы)
Повторяет
описание программы, за одним исключением,
присутствует раздел технико-экономических
показателей.
-
Техническое
задание.
Эксплутационные:
-
Руководство
пользователя -выполнение программы
(указывается последовательность
действий пользователя, для выполнения
того или иного функционала программы);
сообщения об ошибках -
Руководство
системного администратора -настройка
программы (указываются все сведения
по дополнительным и основным настройкам
ПО); проверка программы (описываются
способы проверки работоспособности
ПО); дополнительные возможности
(дополнительные опции и возможности
программы); сообщение об ошибке
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Отладка, или debugging, — это поиск (локализация), анализ и устранение ошибок в программном обеспечении, которые были найдены во время тестирования.
Это простые ошибки, которые в компилируемых языках программирования выявляет компилятор (программа, которая преобразует текст на языке программирования в набор машинных кодов). Если компилятор показывает несколько ошибок, отладку кода начинают с исправления самой первой, так как она может быть причиной других.
В интерпретируемых языках (например Python) текст программы команда за командой переводится в машинный код и сразу исполняется. К моменту обнаружения ошибки часть программы уже может исполниться.
Ошибки связаны с разрешением внешних ссылок. Выявляет компоновщик (редактор связей) при объединении модулей программы. Простой пример — ситуация, когда требуется обращение к подпрограмме другого модуля, но при компоновке она не найдена. Ошибки также просто найти и устранить.
Ошибки, которые обнаруживают операционная система, аппаратные средства или пользователи при выполнении программы. Они считаются непредсказуемыми и проявляются после успешной компиляции и компоновки. Можно выделить четыре вида проявления таких ошибок:
- сообщение об ошибке, которую зафиксировали схемы контроля машинных команд. Это может быть переполнение разрядной сетки (когда старшие разряды результата операции не помещаются в выделенной области памяти), «деление на ноль», нарушение адресации и другие;
- сообщение об ошибке, которую зафиксировала операционная система. Она же, как правило, и документирует ошибку. Это нарушение защиты памяти, отсутствие файла с заданным именем, попытка записи на устройство, защищенное от записи;
- прекращение работы компьютера или зависание. Это и простые ошибки, которые не требуют перезагрузки компьютера, и более сложные, когда нужно выключать ПК;
- получение результатов, которые отличаются от ожидаемых. Программа работает стабильно, но выдает некорректный результат, который пользователь воспринимает за истину.
Ошибки выполнения можно разделить на три большие группы.
Ошибки определения данных или неверное определение исходных данных. Они могут появиться во время выполнения операций ввода-вывода.
К ним относятся:
- ошибки преобразования;
- ошибки данных;
- ошибки перезаписи.
Как правило, использование специальных технических средств для отладки (API-логгеров, логов операционной системы, профилировщиков и пр.) и программирование с защитой от ошибок помогает обнаружить и решить лишь часть из них.
Логические ошибки. Они могут возникать из ошибок, которые были допущены при выборе методов, разработке алгоритмов, определении структуры данных, кодировании модуля.
В эту группу входят:
- ошибки некорректного использования переменных. Сюда относятся неправильный выбор типов данных, использование индексов, выходящих за пределы определения массивов, использование переменных до присвоения переменной начального значения, нарушения соответствия типов данных;
- ошибки вычислений. Это некорректная работа с переменными, неправильное преобразование типов данных в процессе вычислений;
- ошибки взаимодействия модулей или межмодульного интерфейса. Это нарушение типов и последовательности при передаче параметров, области действия локальных и глобальных переменных, несоблюдение единства единиц измерения формальных и фактических параметров;
- неправильная реализация логики при программировании.
Ошибки накопления погрешностей. Могут возникать при неправильном округлении, игнорировании ограничений разрядной сетки, использовании приближенных методов вычислений и т.д.
Отладка программы заключается в тестировании вручную с помощью тестового набора, при работе с которым была допущена ошибка. Несмотря на эффективность, метод не получится использовать для больших программ или программ со сложными вычислениями. Ручное тестирование применяется как составная часть других методов отладки.
В основе отладки системы — тщательный анализ проявлений ошибки. Это могут быть сообщения об ошибке или неверные результаты вычислений. Например, если во время выполнения программы завис компьютер, то, чтобы найти фрагмент проявления ошибки, нужно проанализировать последние действия пользователя. На этапе отладки программы строятся гипотезы, каждая из них проверяется. Если гипотеза подтвердилась, информация об ошибке детализируется, если нет — выдвигаются новые.
Вот как выглядит процесс:

Важно, чтобы выдвинутая гипотеза объясняла все проявления ошибки. Если объясняется только их часть, то либо гипотеза неверна, либо ошибок несколько.
Сначала специалисты предлагают множество причин, по которым могла возникнуть ошибка. Затем анализируют их, исключают противоречащие имеющимся данным. Если все причины были исключены, проводят дополнительное тестирование. В обратном случае наиболее вероятную причину пытаются доказать.

Эффективен для небольших программ. Начинается с точки вывода неправильного результата. Для точки выдвигается гипотеза о значениях основных переменных, которые могли привести к ошибке. Далее на основании этой гипотезы строятся предположения о значениях переменных в предыдущей точке. Процесс продолжается до момента, пока не найдут ошибку.
Ранние отладчики, например gdb, представляли собой отдельные программы с интерфейсами командной строки. Более поздние, например первые версии Turbo Debugger, были автономными, но имели собственный графический интерфейс для облегчения работы. Сейчас большинство IDE имеют встроенный отладчик. Он использует такой же интерфейс, как и редактор кода, поэтому можно выполнять отладку в той же среде, которая используется для написания кода.
Отладчик позволяет разработчику контролировать выполнение и проверять (или изменять) состояние программ. Например, можно использовать отладчик для построчного выполнения программы, проверяя по ходу значения переменных. Сравнение фактических и ожидаемых значений переменных или наблюдение за ходом выполнения кода может помочь в отслеживании логических (семантических) ошибок.
Пошаговое выполнение — это набор связанных функций отладчика, позволяющих поэтапно выполнять код.
Команда выполняет очередную инструкцию, а потом приостанавливает процесс, чтобы с помощью отладчика было можно проверить состояние программы. Если в выполняемом операторе есть вызов функции, step into заставляет программу переходить в начало вызываемой функции, где она приостанавливается.
Команда также выполняет очередную инструкцию. Однако когда step into будет входить в вызовы функций и выполнять их строка за строкой, step over выполнит всю функцию, не останавливаясь, и вернет управление после ее выполнения. Команда step over позволяет пропустить функции, если разработчик уверен, что они уже исправлены, или не заинтересован в их отладке в данный момент.
В отличие от step into и step over, step out выполняет не следующую строку кода, а весь оставшийся код функции, исполняемой в настоящее время. После возврата из функции он возвращает управление разработчику. Эта команда полезна, когда специалист случайно вошел в функцию, которую не нужно отлаживать.
Как правило, при пошаговом выполнении можно идти только вперед. Поэтому легко перешагнуть место, которое нужно проверить. Если это произошло, необходимо перезапустить отладку.
У некоторых отладчиков (таких как GDB 7.0, Visual Studio Enterprise Edition 15.5 и более поздних версий) есть возможность вернуться на шаг назад. Это полезно, если пропущена цель либо нужно повторно проверить выполненную инструкцию.
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
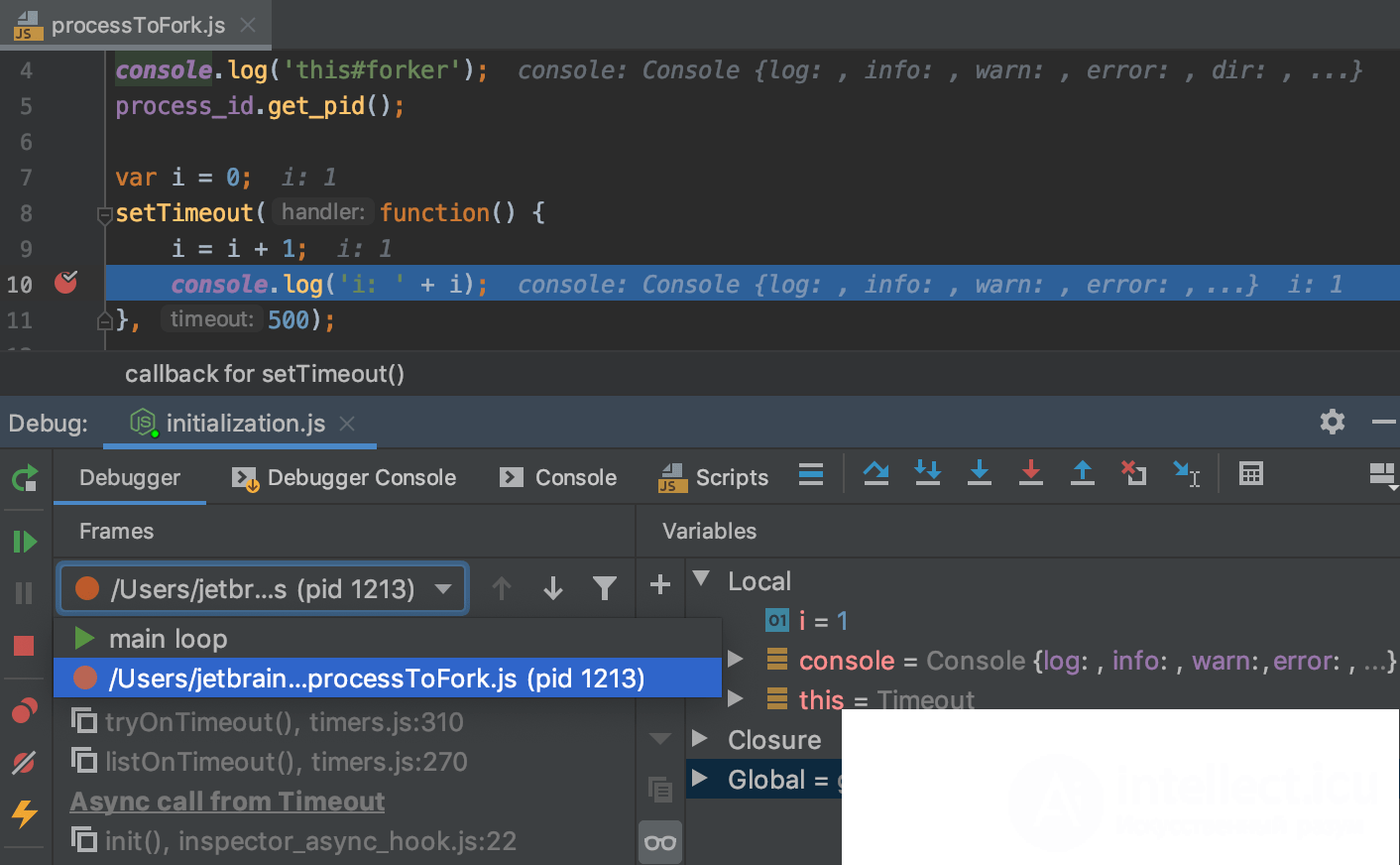 Рис Пример отладки приложения
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
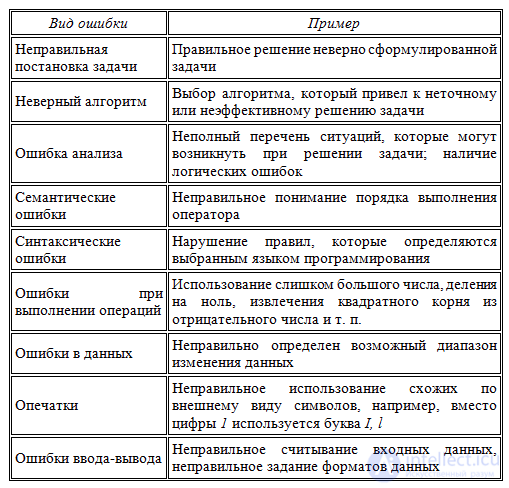
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
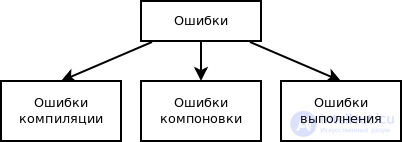
Классификация ошибок по этапу обработки программы
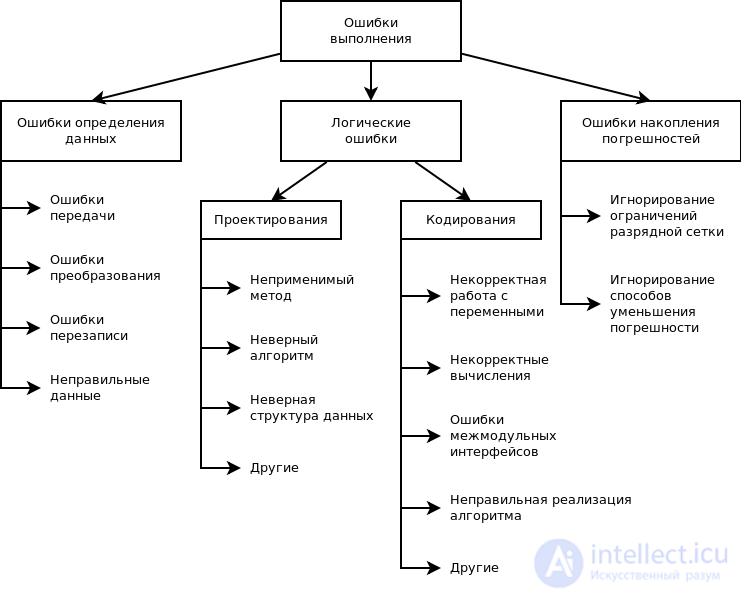
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
 Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
См. также
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
Содержание:

ВВЕДЕНИЕ
Повышение интереса к тестированию программного обеспечения пришлось на 90-е годы XX века в США. Стремительный рост систем автоматизированной разработки программного обеспечения и компьютерных сетей привел к увеличению производства программного обеспечения и к разработке подходов к обеспечению качества и надёжности разрабатываемых приложений. Рост конкуренции между создателями программного обеспечения потребовал определенного внимания к качеству производимых приложений, так как у пользователей появился выбор: разработчики предоставляли свои программы по достаточно приемлемым ценам, что позволяло обращаться к тому, кто разработает необходимый продукт не только дёшево и быстро, но и качественно[3].
В настоящее время компьютеризация вошла практически во все сферы человеческой жизни. Поэтому качество программного обеспечения приобрело особую важность: в современном мире это уже не только удобство в работе программ – программное обеспечение управляет работой диспетчерских систем в аэропортах, оборудования в больницах, космических кораблей, атомных реакторов и т.д [5].
Анализ актуальности обусловили выбор темы исследования: «Отладка и тестирование программ: основные подходы и ограничения».
Объектом исследования является процесс тестирования программного обеспечения.
Предметом исследования являются техники тестирования и отладки программного обеспечения.
Цель исследования состоит в изучении процесса тестирования, основных технологий отладки и тестирования программного обеспечения.
Для достижения поставленной цели необходимо решить следующие задачи:
- определить место, которое занимает процесс тестирования в разработке программного обеспечения;
- ознакомиться с процессом тестирования;
- изучить технологии тестирования программного обеспечения и его отладки.
1. ОСНОВНЫЕ АСПЕКТЫ ТЕСТИРОВАНИЯ И ОТЛАДКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
1.1 Понятия тестирования и отладки программного обеспечения
Тестированием программного обеспечения (software testing) является процесс эксплуатации или анализа программного обеспечения для выявления дефектов[1].
Разберём более подробно данное определение. Понятие «процесс» используется выделения того, что тестирование является плановой, упорядоченной деятельностью. На это необходимо обратить внимание, так как хорошо организованная, систематическая проверка упрощает обнаружение программных ошибок, в сравнении с плохо спланированным тестированием.
Из определения следует, что тестирование подразумевает «эксплуатацию» или «анализ» программного обеспечения. Тестирование, при котором выполняется анализ результатов разработки программного продукта, называют статическим тестированием (static testing), в которое включается проверка кода программы, сквозной контроль и проверка «за столом» (desk checks) , т.е. проверка программного продукта без запуска на компьютере. В отличие от статического тестирования, тестовая деятельность, в которой предусмотрена эксплуатация программы, называется динамическим тестированием (dynamic testing). Эти два типа тестирования дополняют друг друга, реализуя в отдельности собственный подход к определению ошибок в программе.
Понятие дефекта (bug), использующееся в определении, представляет собой программную ошибку, изъян в разработке программы, в результате вызывающий несоответствие ожидаемых и фактически полученных результатов выполнения программного продукта. Дефект может возникнуть на этапе формулирования требований, на этапе проектирования, или на этапе кодирования, также причиной дефекта может быть неправильная конфигурация программы или данных. Дефект может состоять в чём-то другом, что не соответствует требованиям заказчика программного продукта и или не определено в спецификации созданной программы.
Отладкой называют процесс по выявлению источников ошибок, и внесение в программный продукт соответствующих корректировок.
Отладка – это процесс поиска того оператора программы, который вызвал ошибку вычислительного процесса и исправления найденной ошибки, обнаруженной в процессе тестирования программного обеспечения. Чтобы исправить ошибку необходимо выявить ее причину [2]. Различают следующие типы ошибок:
- синтаксические ошибки. Данные ошибки определяются транслятором или компилятором в результате синтаксического и семантического анализа и могут сопровождаться комментариями, в которых указанно их местоположение;
- ошибки компоновки определяются редактором связей (компоновщиком) в процессе объединения программных модулей;
- ошибки выполнения определяются операционной системой, аппаратными средствами или пользователем в процессе выполнения программы.
1.2 Цели и задачи тестирования программного обеспечения
Целями тестирования программного обеспечения являются[8]:
- повышение вероятности правильной работы приложения в различных обстоятельствах;
- повышение вероятности соответствия приложения всем необходимым требованиям.
- проведение полного тестирования приложения в короткие сроки.
Задачами тестирования являются:
- проверка работоспособности системы в соответствии с определенными критериями;
- проверка верности выполнения наиболее критических последовательностей действий пользователя с конечной системой;
- проверка работы пользовательских интерфейсов;
- проверка того, что модификации в базах данных не влияют на выполняемые программные компоненты;
- минимизация переработки тестов при возможных модификациях приложения;
- использование средств автоматизированного тестирования;
- проведение тестирования не только для обнаружения, но и предупреждения дефектов.
1.3 Этапы тестирования программного обеспечения
Первым действием при планировании тестирования программного обеспечения является разработка стратегии испытаний на высоком уровне. В общем, стратегия определяет объем тестовых испытаний, методики тестирования, применяемых для нахождения дефектов, процедуры, которые уведомляют о найденном дефекте и устраняющие его, условия входа и выхода из теста, управляющие различными типами тестов. Учитывая принцип интеграции разработки и тестирования улучшения графика разработки, стратегия испытаний должна включать разнообразные виды тестов жизненного цикла разработки. При разработке общей стратегии должны использоваться тестирования как статического, так и динамического типа.
При использовании автоматизации различных видов тестовой деятельности, данная стратегия должна входить составной частью в общую стратегию тестирования. При автоматизации необходимо выполнение определенных тщательно спланированных параллельных работ, которые должны выполняться только так, чтобы это не приводило к снижению производительности[12].
Существуют несколько подходов при формулировании стратегии тестирования[4]:
1. Определение объемов тестовых испытаний, анализируя документы, которые содержат требования к программе (технические условия), для выяснения, что нужно проверять. При этом необходимо учитывать виды тестов, которые непосредственно не следуют из документов с требованиями, например, возможность установки и увеличение функционала программного продукта, простота и удобство обслуживания программы, а также возможность её взаимодействия с различной аппаратной архитектурой, имеющейся у заказчика.
2. Определение типа тестовых испытаний из разнообразия статических и динамических тестов на каждом этапе разработки. При этом необходимо включение описания всех программных элементов, которые готовятся тестовой группой.
3. Определение условий входа и выхода на каждом этапе тестирования, определение всех точек контроля качества.
4. Определение стратегии автоматизации при использовании автоматизации определенного вида тестовых испытаний.
При определении объемов тестовых работ нет возможности протестировать абсолютно все, поэтому необходимость выбора того, что нужно протестировать очевидна. При избыточности тестового покрытия, времени для отладки программы потребуется значительно больше, что повлияет на срок сдачи работы. Если же тестовое покрытие будет недостаточным, то повысится риск пропуска ошибок, устранение которых после сдачи программного продукта в заказчику будет стоить дороже. Определить норму тестовых испытаний можно при использовании различных способов измерения успешности тестирования.
Можно выделить несколько рекомендаций по разработке стратегии тестирования, использование которых могут обеспечить оптимальное тестовое покрытие[7]:
- в первую очередь необходимо тестирование требований с высоким приоритетом;
- проверка нового функционала программы и программного кода, который был модифицирован для совершенствования или исправления устаревших функциональных возможностей;
- тестирование участков с наиболее вероятным присутствием ошибок;
- использование разбиения на эквивалентные классы и выполнение анализа граничных условий для уменьшения затрат на тестирование;
- сосредоточение внимания на конфигурациях и функциях, с которые наиболее чаще всего будут использованы.
При определении тестированию необходимо вначале исследовать каждый этап жизненного цикла разработки для отбора тестов статического и динамического типов, которые будут использованы на соответствующем этапе. При этом могут быть использованы различные модели жизненного цикла разработки, такие как каскадная, спиралевидная или модель с итеративными версиями. Для примера рассмотрим каскадную модель и определим, какие виды тестирования могут в ней использоваться[4]:
- этап, на котором формулируются требования;
- этап системного проектирования;
- этап, на котором тестируются проекты программы, программные коды, производится модульное тестирование и комплексные испытания;
- системное тестирование;
- приемочное тестирование;
- регрессионное тестирование.
Выбранный подход к тестированию необходимо отразить в документах, которые содержат план проведения тестирования.
Для определения критериев тестирования и точек контроля качества перед началом системного тестирования используют следующие пять типов[6]:
- В критерии входа определяется, что необходимо выполнить сделать перед началом испытания.
- В критерии выхода определяется, что необходимо для завершения испытания.
- В критерии приостановки/возобновления описывается, что будет, если при возникновении дефекта продолжение испытания станет невозможным.
- В критерии успешного/неудачного прохождения теста задаются заранее известные результаты каждого испытания.
- В других критериях, которые определяются стандартами или процессом, задаются соответствующие условия работы программы.
Определение стратегии автоматизации целесообразно при создании любой многократно выполняемой задачи. При этом на автоматизацию задачи требуется намного больше времени, чем на ее выполнение, поэтому необходимо вначале проанализировать потенциальный выигрыша от автоматизации, принимая во внимание, что сама автоматизация имеет отдельный жизненный цикл.
Плохо организованная автоматизация может привести не только к напрасному расходу ресурсов, но и к нарушению графика выполняемых работ, по причине затраты времени на отладку средств автоматизации.
1.4 Комплексное тестирование программного обеспечения
Комплексное тестирование состоит в проверке корректного согласования каждого модуля приложения с остальными его модулями. При этом могут использоваться технологии обработки снизу вверх и сверху вниз, при которых каждый модуль, в виде листа в дереве системы, интегрируется с модулями более высокого или более низкого уровня, пока не будет сформировано дерево программного продукта. Такая технология тестирования необходима для проверки как параметров, передающихся между двумя модулями, так и для проверки глобальных параметров[10].
Отдельные процедуры комплексного тестирования состоят из тестовых кодов верхнего уровня, моделирующих выполнение программой определенного задания. При этом применяются модульные тесты нижнего уровня с определенными параметрами для тестирования интерфейса. После анализа отчетов об обнаруженных дефектах модульного тестирования выполняют объединение модулей инкрементно для их совместного тестирования на основе управляющей логики. Так как в модули могут входить другие модули, то часть комплексного тестирования может проводиться при модульном тестировании. Если коды модульного тестирования создавались с помощью средств автоматизированного тестирования, то возможно их объединение и добавление новых скриптов для проверки межмодульных связей.
Комплексное тестирование выполняется и определенным образом уточняется, при этом отчеты о проблемах документируются и отслеживаются. Отчеты классифицируются по степени их серьезности в четырёхбалльной шкале (4 является наименее критическим состоянием, 1 – наиболее). Обработав отчеты о проблемах необходимо провести регрессионное тестирование, показывающее полное устранение проблемы.
1.5 Восходящее и нисходящее тестирование
Одним из способов локализации ошибок является восходящее тестирование. При обнаружении ошибки в одном модуле при его тестировании, очевидно, что именно в нем она и содержится. Нет необходимости в анализе кода всей системы для поиска источника дефекта. Если же дефект проявляется при совместном тестировании двух модулей, значит, проблема в их интерфейсе. Преимущество восходящего тестирования состоит в том, что концентрация внимания происходит на небольшой области кода, вследствие чего проверка происходит более успешно и с большей вероятностью выявления дефектов.
Недостаток восходящего тестирования состоит в необходимости создания специального скрипта-оболочки, который бы вызывал тестируемый модуль, и «заглушки» для других модулей – имитации вызываемой функции, которая возвращает только данные, ничего больше не выполняя.
Создание оболочек и заглушек приводит к замедлению разработки программы, а для готового приложения не нужны. Однако, эти элементы можно использовать повторно при каждой модификации приложения.
В отличие от восходящего тестирования, при целостном тестировании отдельные модули не проходят особо тщательной проверки до полной интеграции системы.
Достоинствами такого подхода является отсутствие необходимости создания дополнительных скриптов. Поэтому многие разработчики пользуются этим способом для экономии времени. При этом разрабатываются необходимые тесты, с помощью которых проверяется вся система сразу. При этом возникает ряд трудностей[3]:
- Возникает проблема в выявлении источника ошибки. Так как модули не проверяются тщательно, то большинство из них имеет дефекты. При этом неизвестно, какой из дефектов во всех работающих модулях привел к неправильному результату. При наложении дефектов нескольких модулей проблему намного труднее найти.
Также дефект одного модуля может помешать тестированию другого. Как проверить один модуль, если вызывающий его модуль имеет дефект? Тогда для проверяемого модуля необходимо создавать программу-оболочку, или ждать отладки вызывающего модуля, что приводит к потере времени в проверке зависимого модуля.
-
- Проблемы в организации исправления ошибок. При написании программы несколькими программистами, и при этом непонятно, в какой части кода ошибка, необходимо определить, кто будет её устранять.
- Недостаточная автоматизация комплексного тестирования, обусловлена отсутствием необходимости создавать оболочки и заглушки. Программа в процессе разработки постоянно меняется, что приводит к необходимости её частого тестирования. А единожды созданные оболочки и заглушки облегчают автоматизацию этого однообразного труда.
Используют еще один подход в организации тестирования, в котором приложение тестируется по отдельным модулям. В отличие от восходящего тестировании сначала проверяются модули самого верхнего уровня иерархии, а от них тестирование постепенно направляется вниз. Такой подход называется нисходящим тестированием. Оба подхода, и восходящий и нисходящий, называют инкрементальными тестированиями.
В технологии нисходящего тестирования отсутствует необходимость написания оболочек, но написание заглушек нужно. В ходе тестирования заглушки в нужный момент заменяются соответствующими модулями.
Мнения разработчиков об эффективности этих двух инкрементальных подходов тестирования разнятся[4, 9, 11]. Практически выбор стратегии тестирования производится следующим образом: все модули по возможности тестируется сразу после их создания, поэтому тестирование одних частей программы может происходить в восходящей последовательности, а других – в нисходящей.
2. РАЗЛИЧНЫЕ ПОДХОДЫ К ТЕСТИРОВАНИЮ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
2.1 Метод сандвича
Метод сандвича является компромиссным методом между восходящими и нисходящими технологиями тестирования. Здесь делается попытка воспользоваться достоинствами обоих методов, избежав их недостатков. В данном методе нисходящее и восходящее тестирование начинают одновременно, проверяя код как сверху, так и снизу и заканчивая проверку где-то в середине иерархии модулей. Место окончания проверки зависит от программы, которая тестируется и заранее определяется при разборе ее структуры. Например, если программа может быть представлена как совокупность, включающую в себя прикладные модули, затем модули обработки запросов, уровни примитивных функций, то программист может применить нисходящий метод при тестировании прикладных модулей (создавая заглушки, замещающие модули обработки запросов), а остальные модули проверять восходящим методом. Метод сандвича применяется при проверке больших программ, например, операционных систем или пакетов прикладных программ[4].
Достоинством метода сандвича состоит в интеграции системы в самом начале тестирования, что также проявляется в восходящем и нисходящем подходе. Так как верхние уровни программных модулей вступают в проверку рано, то, как в нисходящем методе, уже вначале проверки получается работающий каркас программы. Так как нижние уровни программных модулей проверяются восходящим методом, то исчезают недостатки нисходящего метода, связанные с невозможностью проверять некоторые условия во внутренних модулях программы.
Однако тестирование методом сандвича сохраняет та недостатки нисходящего подхода, состоящие в том, что нет возможности тщательно протестировать отдельные модули. Восходящая часть проверки методом сандвича убирает этот недостаток для модулей нижних уровней, однако он остаётся актуальным для нижней части верхнего уровня модулей программы. Существует модифицированный метод сандвича, в котором верхние уровни модулей вначале проверяются по отдельности, а затем тестируются нисходящим способом, а модули нижних уровней тестируются восходящим.
2.2 Метод «белого ящика»
Метод «белый ящик» состоит в том, что при создании тестовых случаев программисты используют все данные о внутренней структуре программы и её или коде. Технологии, которые применяются при тестировании методом «белого ящика» представляют собой технологии статического тестирования[8].
Этот метод не выявляет синтаксические ошибки, ткоторые обнаруживаются компилятором. Метод «белого ящика» направлен на поиск дефектов, выявить которые сложно, на обнаружение логических ошибок и проверку степени покрытия тестами.
В тестовых испытаниях методом «белого ящика» применяют управляющую логику процедур. Они выполняют следующие функции:
- предоставляют гарантию проверки того по крайней мере один раз всех независимых путей в модуле;
- проверяют истинность или ложность всех логических решений;
- выполняют все циклы с использованием граничных значений внутри операционных границ;
- исследуют структуру внутренних данных для того, чтобы проверить их достоверность.
Метод «белого ящика» является разновидностью стратегии модульного тестирования, при которой тестирование производится на функциональном или модульном уровне и тестирование направлено на исследование внутренней структуры модуля. Такой тип тестирования также носит название модульного тестирования или тестирования «прозрачного ящика» (clear box) или прозрачным (translucent) тестированием, так как специалисты, кторые проводят тестирование, знают весь программный код и видят работу программы изнутри. Подход к тестированию, основанный на открытости кода, ещё называют структурным подходом.
При тестировании на данном уровне выполняется проверка управляющей логики, которая работает на модульном уровне. Для того, все логические решения рассмотрены во всевозможных условиях, чтобы все пути в данном модуле были проверены хотя бы один раз, циклы были выполнены с использованием верхних и нижних границ в данном методе используют тестовые драйверы.
2.3 Методы тестирования на основе стратегии «белого ящика»
2.3.1 Ввод неверных значений
Вводя неверные значения при тестировании программы, программист делает так, чтобы коды возврата показывали ошибки, и смотрит на ответную реакцию кода. Таким способом можно моделировать определенные события, такие как переполнение диска, нехватку памяти и т.д. Такой метод еще называется тестированием ошибочных входных данных, когда проводят проверку работы программы, как при верно, так и неверно введенных входных данных. Программист для этого может выбрать значения, которые входят в границы входных и выходных параметров, а также значения, не выходящие в данный диапазон.
2.3.2 Модульное тестирование
Разработка отдельных модулей программы сопровождается модульным тестированием, в результате которого проверяется, работоспособность кода, верность его работы и корректность реализации интерфейса. Модульное тестирование проверяет новый код на соответствие архитектуры; изучаются пути в коде, определяется, что ниспадающие меню, экраны и сообщения отформатированы должным образом; выполняется проверка диапазона и типов вводимых данных, а также генерацию исключений и возврата ошибок (error returns). Тестирование отдельных модулей программы выполняется для проверки корректности алгоритмов и логики соответствия предъявляемым требованиям функциональности. В результате модульного тестирования определяются ошибки, которые относятся к времени работы, логике программы, выходу из диапазона, перегрузке и утечке памяти.
2.3.3 Тестирование обработки ошибок
Н практике признается, что каждое возможное условие возникновения ошибки проверить невозможно. Поэтому производят сглаживание последствий возникновения неожиданных ошибок с помощью обработки ошибок. Программист должен проверить, что программа правильно выдает сообщения об ошибке.
2.3.4 Утечка памяти
Проверка утечки памяти предполагает исследование приложения на обнаружение ситуаций, в которых не происходит освобождения выделенной памяти, из-за чего уменьшается производительность программы. В данной технологии используется как для проверки готового программного продукта, так и для тестирования версии программы. Инструменты тестирования способны отслеживать использование памяти приложением в течение определенного времени, проверяя, происходит ли рост объема используемой памяти. С помощью инструментов тестирования выявляют те участки программы, в которых не происходит освобождение выделенной памяти.
2.3.5 Комплексное тестирование
При комплексном тестировании выполняется проверка каждого модуля программы на корректную работу со всеми модулями. Данный метод тестирования может использовать технологии обработки снизу вверх и сверху вниз, при которых все модули, являющиеся листьями в дереве системы, соединяются со следующим модулем более высокого или более низкого уровня, пока не будет создано дерево программного продукта. Такой подход к тестированию проверяет не только параметры, передающиеся между двумя компонентами, но и глобальные параметры.
2.3.6 Тестирование цепочек
Метод «Тестирование цепочек» используется для проверки нескольких модулей, которые составляют функцию программы. Данный метод выявляет, надежно ли работают модули для образования единого модуля, и выдают ли модули программы правильные и согласованные результаты.
2.3.7 Исследование покрытия
Выбор средств для исследования покрытия состоит в том, что группа тестирования должна проанализировать тип покрытия, который необходим для программы. Исследование покрытия проводят с помощью разнообразных технологий. Метод покрытия операторов часто называют C1, что также означает покрытие узлов. Эти измерения показывают, был ли проверен каждый исполняемый оператор. Данный метод тестирования обычно использует программу протоколирования (profiler) производительности.
2.3.8 Покрытие решений
Метод покрытия решений направлен на определение (в процентном соотношении) всех возможных исходов решений, которые были проверены с помощью комплекта тестовых процедур. Метод покрытия решений иногда относят к покрытию ветвей и называют C2. Он требует: чтобы каждая точка входа и выхода в программе была достигнута хотя бы единожды, чтобы все возможные условия для решений в программе были проверены не менее одного раза, и чтобы каждое решение в программе хотя бы единожды было протестировано при использовании всех возможных исходов.
2.3.9 Покрытие условий
Покрытие условий похоже на покрытие решений. Оно направлено на проверку точности истинных или ложных результатов каждого логического выражения. Этот метод включает в себя тесты, которые проверяют выражения независимо друг от друга. Результаты этих проверок аналогичны тем, что получают при применении метода покрытия решений, за исключением того, что метод покрытия решений более чувствителен к управляющей логике программы.
2.4 Метод «черного ящика»
Тестирование на основе стратегии черного ящика возможно лишь при наличии установленных открытых интерфейсов, таких как интерфейс пользователя или программный интерфейс приложения (API). Если тестирование на основе стратегии белого ящика исследует внутреннюю работу программы, то методы тестирования черного ящика сравнивают поведение приложения с соответствующими требованиями. Кроме того, эти методы обычно направлены на выявление трех основных видов ошибок: функциональности, поддерживаемой программным продуктом; производимых вычислений; допустимого диапазона или области действия значений данных, которые могут быть обработаны программным продуктом. На этом уровне тестировщики не исследуют внутреннюю работу компонентов программного продукта, тем не менее, они проверяются неявно. Группа тестирования изучает входные и выходные данные программного продукта. В этом ракурсе тестирование с помощью методов черного ящика рассматривается как синоним тестирования на уровне системы, хотя методы черного ящика могут также применяться во время модульного или компонентного тестирования.
При тестировании методами черного ящика важно участие пользователей, поскольку именно они лучше всего знают, каких результатов следует ожидать от бизнес-функций. Ключом к успешному завершению системного тестирования является корректность данных. Поэтому на фазе создания данных для тестирования крайне важно, чтобы конечные пользователи предоставили как можно больше входных данных.
Тестирование при помощи методов черного ящика направлено на получение множеств входных данных, которые наиболее полно проверяют все функциональные требования системы. Это не альтернатива тестированию по методу белого ящика. Этот тип тестирования нацелен на поиск ошибок, относящихся к целому ряду категорий, среди них[9]:
- неверная или пропущенная функциональность;
- ошибки интерфейса;
- проблемы удобства использования;
- методы тестирования на основе автоматизированных инструментов;
- ошибки в структурах данных или ошибки доступа к внешним базам данных;
- проблемы снижения производительности и другие ошибки производительности;
- ошибки загрузки;
- ошибки многопользовательского доступа;
- ошибки инициализации и завершения;
- проблемы сохранения резервных копий и способности к восстановлению работы;
- проблемы безопасности.
2.5 Методы тестирования на основе стратегии «черного ящика»
2.5.1 Эквивалентное разбиение
Исчерпывающее тестирование входных данных, как правило, неосуществимо. Поэтому следует проводить тестирование с использованием подмножества входных данных.
При тестировании ошибок, связанных с выходом за пределы области допустимых значений, применяют три основных типа эквивалентных классов: значения внутри границы диапазона, за границей диапазона и на границе. Оправдывает себя практика создания тестовых процедур, которые проверяют граничные случаи плюс/минус один во избежание пропуска ошибок «на единицу больше» или «на единицу меньше». Кроме разработки тестовых процедур, использующих сильно структурированные классы эквивалентности, группа тестирования должна провести исследовательское тестирование. Тестовые процедуры, при выполнении которых выдаются ожидаемые результаты, называются правильными тестами. Тестовые процедуры, проведение которых должно привести к ошибке, носят название неправильных тестов[7].
2.5.2 Анализ граничных значений
Анализ граничных значений можно применить как на структурном, так и на функциональном уровне тестирования. Границы определяют данные трех типов: правильные, неправильные и лежащие на границе. Тестирование границ использует значения, лежащие внутри или на границе (например, крайние точки), и максимальные/минимальные значения (например, длины полей). При таком исследовании всегда должны учитываться значения на единицу больше и меньше граничного. При тестировании за пределами границы используется репрезентативный образец данных, выходящих за границу, т.е. неверные значения.
2.5.3 Диаграммы причинно-следственных связей
Составление диаграмм причинно-следственных связей — это метод, дающий четкое представление о логических условиях и соответствующих действиях. Метод предполагает четыре этапа. Первый этап заключается в составлении перечня причин (условий ввода) и следствий (действий) для модуля и в присвоении идентификатора каждому модулю. На втором этапе разрабатывается диаграмма причинно-следственных связей. На третьем этапе диаграмма преобразуется в таблицу решений. Четвертый этап включает в себя установление причин и следствий в процессе чтения спецификации функций. Каждой причине и следствию присваивается собственный идентификатор. Причины перечисляются в столбике с левой стороны листа бумаги, а следствия — с правой. Затем причины и следствия соединяются линиями так, чтобы были отражены имеющиеся между ними соответствия. На диаграмме проставляются булевы выражения, которые объединяют две или более причин, связанных со следствием. Далее правила таблицы решений преобразуются в тестовые процедуры.
2.5.4 Системное тестирование
Термин «системное тестирование» часто употребляется как синоним «тестирования с помощью методов черного ящика», поскольку во время системного тестирования группа тестирования рассматривает в основном «внешнее поведение» приложения. Системное тестирование включает в себя несколько подтипов тестирования, в том числе функциональное, регрессионное, безопасности, перегрузок, производительности, удобства использования, случайное, целостности данных, преобразования данных, сохранения резервных копий и способности к восстановлению, готовности к работе, приемо-сдаточные испытания и альфа/бета тестирование.
2.5.5 Функциональное тестирование
Функциональное тестирование проверяет системное приложение в отношении функциональных требований с целью обнаружения несоответствия требованиям конечного пользователя. Для большинства программ тестирования программного продукта данный метод тестирования является главным. Его основная задача – оценка того, работает ли приложение в соответствии с предъявляемыми требованиями.
2.5.6 Регрессионное тестирование.
Смысл проведения тестирования заключается в обнаружении дефектов, их документировании и отслеживании вплоть до устранения. Тестировщик должен быть уверен в том, что меры, принимаемые для устранения найденных ошибок, не породят в свою очередь новых ошибок в других областях системы. Регрессионное тестирование позволяет выяснить, не появились ли какие-либо ошибки в результате ликвидации уже обнаруженных ошибок. Именно для регрессионного тестирования применение инструментов автоматизированного тестирования дает наибольшую отдачу. Все созданные ранее скрипты можно использовать снова для подтверждения того, что в результате изменений, внесенных при устранении ошибки, не появились новые дефекты. Эта цель легко достижима, поскольку скрипты можно выполнять без ручного вмешательства и использовать столько раз, сколько необходимо для обнаружения ошибок.
2.5.7 Тестирование безопасности
Тестирование безопасности включает в себя проверку работы механизмов доступа к системе и к данным. Для этого придумывают тестовые процедуры, которые пытаются преодолеть защиту системы. Тестировщик проверяет степень безопасности и ограничения доступа, определяя таким образом, соответствие установленным требованиям к безопасности и всем применяемым правилам по безопасности системы.
2.5.8 Тестирование перегрузок
При тестировании перегрузок выполняется проверка системы без учета ограничений архитектуры с целью выявления технических ограничений системы. Эти тесты проводятся на пике обработки транзакций и при непрерывной загрузке большого объема данных. Тестирование перегрузок измеряет пропускную способность системы и ее эластичность (resiliency) на всех аппаратных платформах. Этот метод подразумевает одновременное обращение со стороны многих пользователей к определенным функциям системы, причем некоторые вводят значения, выходящие за пределы нормы. От системы требуется обработка огромного количества данных или выполнение большого числа функциональных запросов в течение короткого периода времени.
2.5.9 Тестирование производительности
Тесты производительности проверяют, удовлетворяет ли системное приложение требованиям по производительности. Применяя тестирование производительности, можно замерить и составить отчеты по таким показателям, как скорость передачи входных и выходных данных, общее число действий по вводу и выводу данных, среднее время, затрачиваемое базой данных на отклик на запрос, и интенсивность использования центрального процессора. Как правило, для автоматической проверки степени производительности, проводимой в рамках тестирования производительности, используются те же инструменты, что и при тестировании перегрузок.
2.5.10 Тестирование удобства использования
Тесты удобства использования направлены на подтверждение простоты применения системы и того, что пользовательский интерфейс выглядит привлекательно. Такие тесты учитывают человеческий фактор в работе системы. Тестировщику нужно оценить приложение с точки зрения конечного пользователя.
3. ОТЛАДКА ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
3.1 Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы[2]:
— ручного тестирования;
— индукции;
— дедукции;
— обратного прослеживания.
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 1 в виде схемы алгоритма.
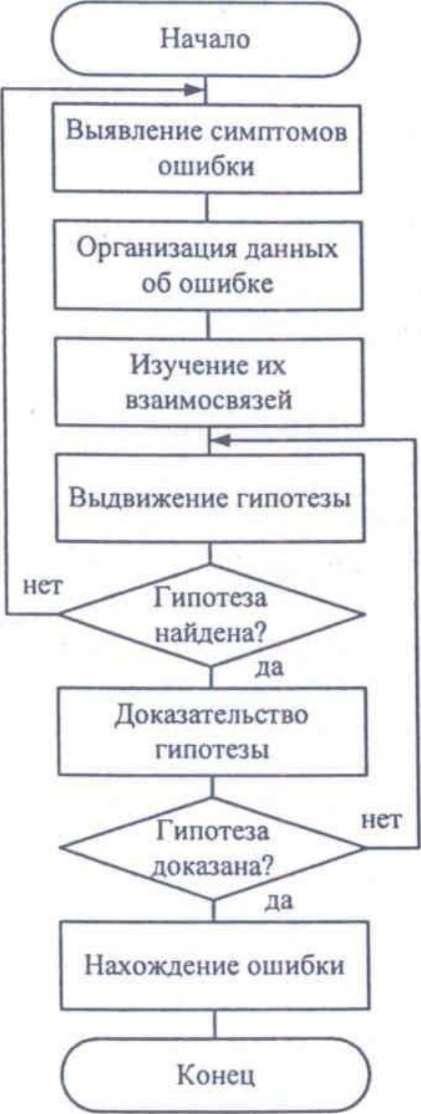
Рисунок 1 — Схема процесса отладки методом индукции
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис. 2).
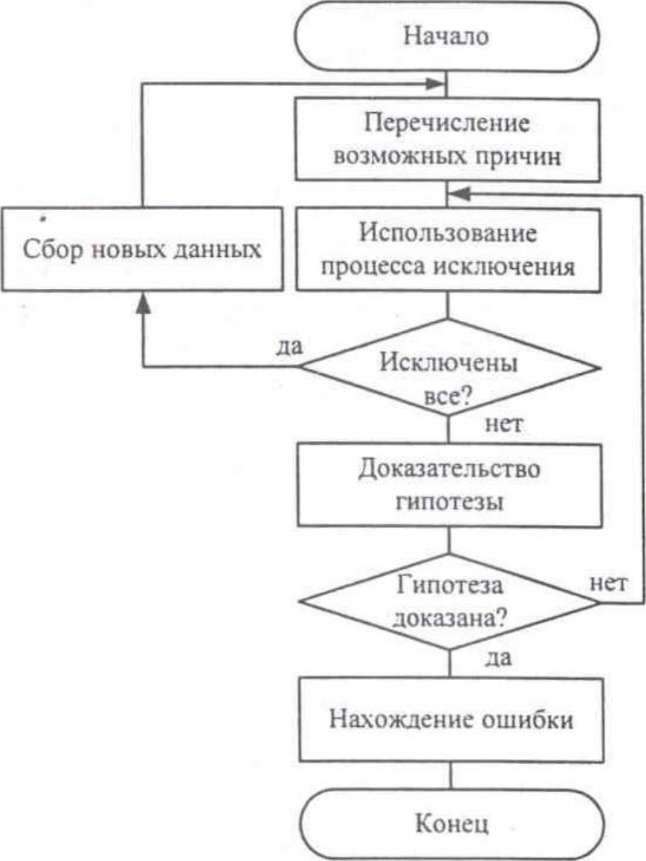
Рисунок 2 — Схема процесса отладки методом дедукции
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
3.2 Общая методика отладки программного обеспечения
Суммируя все сказанное выше, можно предложить следующую методику отладки программного обеспечения, написанного на универсальных языках программирования[9]:
1 этап — изучение проявления ошибки — если выдано какое-либо сообщение или выданы неправильные или неполные результаты, то необходимо их изучить и попытаться понять, какая ошибка могла так проявиться. При этом используют индуктивные и дедуктивные методы отладки. В результате выдвигают версии о характере ошибки, которые необходимо проверить. Для этого можно применить методы и средства получения дополнительной информации об ошибке.
Если ошибка не найдена или система просто «зависла», переходят ко второму этапу.
2 этап — локализация ошибки — определение конкретного фрагмента, при выполнении которого произошло отклонение от предполагаемого вычислительного процесса. Локализация может выполняться:
- путем отсечения частей программы, причем, если при отсечении некоторой части программы ошибка пропадает, то это может означать как то, что ошибка связана с этой частью, так и то, что внесенное изменение изменило проявление ошибки;
- с использованием отладочных средств, позволяющих выполнить интересующих нас фрагмент программы в пошаговом режиме и получить дополнительную информацию о месте проявления и характере ошибки, например, уточнить содержимое указанных переменных.
При этом если были получены неправильные результаты, то в пошаговом режиме проверяют ключевые точки процесса формирования данного результата.
Как подчеркивалось выше, ошибка не обязательно допущена в том месте, где она проявилась. Если в конкретном случае это так, то переходят к следующему этапу.
3этап — определение причины ошибки — изучение результатов второго этапа и формирование версий возможных причин ошибки. Эти версии необходимо проверить, возможно, используя отладочные средства для просмотра последовательности операторов или значений переменных.
4этап — исправление ошибки — внесение соответствующих изменений во все операторы, совместное выполнение которых привело к ошибке.
5 этап — повторное тестирование — повторение всех тестов с начала, так как при исправлении обнаруженных ошибок часто вносят в программу новые.
Следует иметь в виду, что процесс отладки можно существенно упростить, если следовать основным рекомендациям структурного подхода к программированию[7]:
- программу наращивать «сверху-вниз», от интерфейса к обрабатывающим подпрограммам, тестируя ее по ходу добавления подпрограмм;
- выводить пользователю вводимые им данные для контроля и проверять их на допустимость сразу после ввода;
- предусматривать вывод основных данных во всех узловых точках алгоритма (ветвлениях, вызовах подпрограмм).
Кроме того, следует более тщательно проверять фрагменты программного обеспечения, где уже были обнаружены ошибки, так как вероятность ошибок в этих местах по статистике выше. Это вызвано следующими причинами. Во-первых, ошибки чаще допускают в сложных местах или в тех случаях, если спецификации на реализуемые операции недостаточно проработаны. Во-вторых, ошибки могут быть результатом того, что программист устал, отвлекся или плохо себя чувствует. В-третьих, как уже упоминалось выше, ошибки часто появляются в результате исправления уже найденных ошибок.
Можно отметить, что проще всего обычно искать ошибки определения данных и ошибки накопления погрешностей: их причины локализованы в месте проявления. Логические ошибки искать существенно сложнее. Причем обнаружение ошибок проектирования требует возврата на предыдущие этапы и внесения соответствующих изменений в проект.
Ошибки кодирования бывают как простые, например, использование неинициализированной переменной, так и очень сложные, например, ошибки, связанные с затиранием памяти. Затиранием памяти называют ошибки, приводящие к тому, что в результате записи некоторой информации не на свое место в оперативной памяти, затираются фрагменты данных или даже команд программы. Ошибки подобного рода обычно вызывают появление сообщения об ошибке. Поэтому определить фрагмент, при выполнении которого ошибка проявляется, несложно. А вот определение фрагмента программы, который затирает память – сложная задача, причем, чем длиннее программа, тем сложнее искать ошибки такого рода. Именно в этом случае часто прибегают к удалению из программы частей, хотя это и не обеспечивает однозначного ответа на вопрос, в какой из частей программы находится ошибка. Эффективнее попытаться определить операторы, которые записывают данные в память не по имени, а по адресу, и последовательно их проверить. Особое внимание при этом следует обращать на корректное распределение памяти под данные.
ЗАКЛЮЧЕНИЕ
В современной работе программиста тестирование занимает важную часть процесса производства программного обеспечения. Качественно организованное тестирование своевременно выявляет и исправляет ошибки, что позволяет уменьшить риски и затраты на разработку приложений. Автоматизация тестирования повышает качество и скорость проверки, что приводит к еще большему повышению качества и уменьшению издержек.
В данной курсовой работе были рассмотрены принципы тестирования и отладки программного обеспечения, цели и задачи тестирования, основные этапы тестирования.
Были изучены стратегии тестирования, такие как стратегии белого и черного ящиков, и методы тестирования, основанные на данных стратегиях. К стратегии белого ящика относят следующие методы: ввод неверных значений, модульное тестирование, тестирование обработки ошибок, утечка памяти, комплексное тестирование, тестирование цепочек, исследование покрытия, покрытие решений, покрытие условий. К стратегии черного ящик относятся методы эквивалентного разбиения, анализа граничных значений, диаграммы причинно-следственных связей, системного тестирования, функционального тестирования, регрессионного тестирования, тестирования безопасности, тестирования перегрузок, тестирования производительности, тестирования удобства использования.
Также в работе были изучены методы отладки программного обеспечения и рассмотрена общая методика отладки приложений.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- Бейзер Б. Тестирование черного ящика. Технологии функционального тестирования программного обеспечения и систем [текст] / Б. Бейзер; — Питер, 2004, 320 с. ISBN 5-94723-698-2.
- Брауде Э.Д. Технология разработки программного обеспечения [текст] / Э.Д. Брауде; — Питер, 2004, 656 с. ISBN 5-94723-663-X.
- Винниченко И.В. Автоматизация процессов тестирования [текст] / И. В. Винниченко; — Питер, 2005, 208 с. ISBN 5-469-00798-7.
- Канер С. Тестирование программного обеспечения. Фундаментальные концепции менеджмента бизнес-приложений [текст] / С. Канер; — ДиаСофт, 2001, 544 с, ISBN 966-7393-87-9.
- Калбертсон Р. Быстрое тестирование [текст] / Р. Калбертсон, К. Браун, Г. Кобб; — Вильямс, 2002, 384 с. ISBN 5-8459-0336-X.
- Коликова Т.В. Основы тестирования программного обеспечения. Учебное пособие [текст] / Т.В. Коликова, В.П. Котляров; — Интуит, 2006, — 285 с. ISBN 5-85582-186-2.
- Касперски К. Техника отладки программ без исходных текстов [текст] / К. Касперски; — БХВ-Петербург, 2005, 832 с. ISBN 5-94157-229-8.
- Макгрегор Д. Тестирование объектно-ориентированного программного обеспечения. Практическое пособие [текст] / Д. Макгрегор, Д. Сайкс; — ТИД «ДС», 2004, 432 с. ISBN 966-7992-12-8.
- Плаксин М. Тестирование и отладка программ — для профессионалов будущих и настоящих [текст] / М. Пласкин; — Бином. Лаборатория знаний, 2007, — 168 с. ISBN 978-5-94774-458-3.
- Роберт М. Быстрая разработка программ: принципы, примеры, практика [текст] / М. Роберт, Д. Ньюкирк; — Вильямс, 2004, 752 с. ISBN 5-8459-0558-3.
- Фолк Д. Тестирование программного обеспечения [текст] / Д. Фолк, Е. К. Нгуен, С. Канер; — Диасофт, 2003 , 400 с. ISBN 966-7393-87-9.
- Элфрид Д. Автоматизированное тестирование программного обеспечения. Внедрение, управление и эксплуатация [текст] / Элфрид Д., Джефф Р., Джон П.;- Лори, 2003, ISBN 5-85582-186-2.

- Особенности алгоритмизации при разработке WEB-приложений
- Характеристика предприятия
- Понятие и сущность валютной системы и валютного курса
- Теоретические аспекты формирования налоговой системы РФ
- Анализ структуры торгового ассортимента (на примере обувного магазина «Шаг за шагом»
- Управление каналами сбыта в системе товародвижения реально существующей организации (Сбытовая политика в организации)
- Исследование сетевых операционных систем
- Формирование ассортимента товаров на предприятиях торговли на примере ООО «ТТ-ОБУВЬ»
- Теоретические основы коммерческой деятельности предприятия розничной торговли
- Юридическая сущность предпринимательского права (Субъекты предпринимательского права, порядок создания, реорганизации и ликвидации)
- Общая характеристика физических лиц, как субъекта гражданского права
- Разработка конфигурации Взаиморасчеты с клиентами в среде 1С:Предприятие
Библиографическое описание:
Пивоваров, Д. О. Отладка и тестирование программного обеспечения / Д. О. Пивоваров. — Текст : непосредственный // Молодой ученый. — 2022. — № 25 (420). — С. 14-15. — URL: https://moluch.ru/archive/420/93470/ (дата обращения: 10.02.2023).
В статье описываются способы отладки и тестирования программного обеспечения.
Ключевые слова:
программное обеспечение, тестирование, функциональное тестирование, тип тестирования.
Отладка — это процесс поиска ошибок, т. е. ошибок в программном обеспечении или приложении, и их исправления. Любое программное обеспечение или продукт, который разрабатывается, проходит через различные этапы — тестирование, устранение неполадок, обслуживание в другой среде. Эти программные продукты содержат некоторые ошибки. Эти ошибки должны быть устранены из программного обеспечения. Отладка — это не что иное, как процесс, который многие тестировщики программного обеспечения использовали для поиска и устранения этих ошибок. Отладка — это поиск ошибок, их анализ и исправление. Этот процесс происходит, когда программное обеспечение дает сбой из-за некоторых ошибок или программное обеспечение выполняет нежелательные действия. Отладка выглядит просто, но это сложная задача, поскольку необходимо исправлять все ошибки на каждом этапе отладки [2].
Процесс отладки состоит из нескольких этапов:
– определение ошибки;
– определение местонахождения ошибки;
– анализ ошибки;
– автоматизация тестирования;
– покрытие ущерба.
Выявление ошибок на ранней стадии может сэкономить много времени. Если допускается ошибка при выявлении ошибки, это приведет к большим потерям времени. Определение правильной ошибки — это импорт, чтобы сэкономить время и избежать ошибок на стороне пользователя.
После выявления ошибки необходимо определить точное местоположение в коде, где происходит ошибка. Определение точного местоположения, которое приводит к ошибке, может помочь решить проблему быстрее.
На следующем этапе отладки нужно использовать соответствующий подход для анализа ошибки. Это поможет понять проблему. Этот этап очень важен, так как решение одной ошибки может привести к другой ошибке.
После того, как выявленная ошибка была проанализирована, необходимо сосредоточиться на других ошибках программного обеспечения. Этот процесс включает в себя автоматизацию тестирования, когда требуется написать тестовые примеры через тестовую среду.
На последнем этапе необходимо выполнить модульное тестирование всего кода, в котором вносятся изменения. Если не все тестовые примеры проходят тестирование, следует решить тестовый пример, который не прошел тест.
Ниже приведен список преимуществ отладки:
– экономия времени;
– создание отчетов об ошибках;
– простая интерпретация.
Для выявления и исправления ошибок использовались различные инструменты, отладочные средства — это программное обеспечение, которое используется для тестирования и отладки других программ. На рынке доступно множество инструментов отладки с открытым исходным кодом.
Существуют различные стратегии отладки:
– стратегия обучения;
– опыт;
– форвардный анализ;
– обратный анализ.
Перед обнаружением ошибки в программном обеспечении или продукте очень важно изучить его очень тщательно. Потому что без каких-либо знаний сложно найти ошибки. В этом заключается стратегия обучения.
Предыдущий опыт может помочь найти похожие типы ошибок, а также решение для устранения ошибок.
Прямой анализ программ включает в себя отслеживание программ вперед с использованием операторов печати или точек останова в разных точках. Это больше касается места, где получены неправильные результаты.
Обратный анализ программы включает в себя отслеживание программы назад от места, где происходят ошибки, чтобы идентифицировать область неисправного кода.
Тестирование — немаловажная часть разработки ПО, так как от него зависит, будут ли возникать ошибки в работе программы. Поэтому необходимо рассмотреть доступные варианты средств тестирования и выбрать подходящие.
Типы тестирования, зависящие от объекта тестирования:
– модульное/unit-тестирование — проверка корректной работы отдельных модулей;
– интеграционное тестирование — проверка взаимодействия между несколькими модулями;
– системное — проверка работы программного обеспечения целиком;
– приемное — оценка соответствия требованиям, указанным в техническом задании.
Все эти типы необходимы и используются в тестировании ПМ ОО.
В зависимости от цели тестирование делится на два типа: функциональное и нефункциональное. Функциональное тестирование направлено на проверку реализуемости функциональных требований. Такие тесты могут проводиться на всех уровнях тестирования. Преимуществом этого типа тестирования является имитация фактического пользования программой.
Нефункциональное тестирование — это тип тестирования программного обеспечения для проверки нефункциональных аспектов программного приложения: производительность, удобство использования, надежность и т. д. Он предназначен для проверки готовности системы по нефункциональным параметрам, которые никогда не учитываются при функциональном тестировании. Нефункциональное тестирование включает в себя:
– тестирование производительности — работа ПОпод сильной нагрузкой;
– тестирование пользовательского интерфейса — удобство пользователя при взаимодействии с разными параметрами интерфейса;
– тестирование UX — правильность логики использования;
– тестирование защищенности — определение безопасности ПО;
– инсталляционное тестирование — поиск возникновения проблем при установке;
– тестирование совместимости — тестирование работы ПО в определенном окружении;
– тестирование надежности — работа программы при длительной нагрузке;
– тестирование локализации — оценка правильности версии.
В зависимости от доступа к коду программы при тестировании различают:
– тестирование белого ящика;
– тестирование черного ящика;
– тестирование серого ящика.
Главная цель тестирования белого ящика — проверка кода, тестирование внутренней структуры и дизайна. Эта стратегия предполагает поиск и улучшение таких случаев как:
– нерабочие и неоптимизированные участки кода;
– безопасность;
– ввод данных;
– условные процессы;
– неправильная работа объектов;
– некорректное отображение информации.
Основным подходом в этой стратегии является анализ кода программы.
Во время тестирования черного ящика тестировщик не знает, что за программу он тестирует. Как правило, этот метод используется для функционального тестирования по техническому заданию.
Стратегия серого ящика — это комбинация подходов белого и черного ящиков. Суть этого подхода — найти все проблемы функционирования и ошибки в коде.
Литература:
- Гленфорд Майерс. Тестирование программного обеспечения. Базовый курс / Майерс Гленфорд, Баджетт Том, Сандлер Кори. — 3-е изд., 2022. — 298 c. — Текст: непосредственный.
- Отладка (debugging): что это. — Текст: электронный // Skillfactory: [сайт]. — URL: https://blog.skillfactory.ru/glossary/otladka-debugging/ (дата обращения: 22.06.2022).
Основные термины (генерируются автоматически): программное обеспечение, ошибка, тестирование, тип тестирования, функциональное тестирование, черный ящик, белый ящик, нефункциональное тестирование, серый ящик, техническое задание.
From Wikipedia, the free encyclopedia
In computer programming and software development, debugging is the process of finding and resolving bugs (defects or problems that prevent correct operation) within computer programs, software, or systems.
Debugging tactics can involve interactive debugging, control flow analysis, unit testing, integration testing, log file analysis, monitoring at the application or system level, memory dumps, and profiling. Many programming languages and software development tools also offer programs to aid in debugging, known as debuggers.
Etymology[edit]

A computer log entry from the Mark II, with a moth taped to the page
The terms «bug» and «debugging» are popularly attributed to Admiral Grace Hopper in the 1940s.[1] While she was working on a Mark II computer at Harvard University, her associates discovered a moth stuck in a relay and thereby impeding operation, whereupon she remarked that they were «debugging» the system. However, the term «bug», in the sense of «technical error», dates back at least to 1878 and Thomas Edison who describes the «little faults and difficulties» of mechanical engineering as «Bugs».
Similarly, the term «debugging» seems to have been used as a term in aeronautics before entering the world of computers. In an interview Grace Hopper remarked that she was not coining the term.[citation needed] The moth fit the already existing terminology, so it was saved. A letter from J. Robert Oppenheimer (director of the WWII atomic bomb Manhattan Project at Los Alamos, New Mexico) used the term in a letter to Dr. Ernest Lawrence at UC Berkeley, dated October 27, 1944,[2] regarding the recruitment of additional technical staff.
The Oxford English Dictionary entry for «debug» quotes the term «debugging» used in reference to airplane engine testing in a 1945 article in the Journal of the Royal Aeronautical Society. An article in «Airforce» (June 1945 p. 50) also refers to debugging, this time of aircraft cameras. Hopper’s bug was found on September 9, 1947. Computer programmers did not adopt the term until the early 1950s.
The seminal article by Gill[3] in 1951 is the earliest in-depth discussion of programming errors, but it does not use the term «bug» or «debugging».
In the ACM’s digital library, the term «debugging» is first used in three papers from 1952 ACM National Meetings.[4][5][6] Two of the three use the term in quotation marks.
By 1963 «debugging» was a common-enough term to be mentioned in passing without explanation on page 1 of the CTSS manual.[7]
Scope[edit]
As software and electronic systems have become generally more complex, the various common debugging techniques have expanded with more methods to detect anomalies, assess impact, and schedule software patches or full updates to a system. The words «anomaly» and «discrepancy» can be used, as being more neutral terms, to avoid the words «error» and «defect» or «bug» where there might be an implication that all so-called errors, defects or bugs must be fixed (at all costs). Instead, an impact assessment can be made to determine if changes to remove an anomaly (or discrepancy) would be cost-effective for the system, or perhaps a scheduled new release might render the change(s) unnecessary. Not all issues are safety-critical or mission-critical in a system. Also, it is important to avoid the situation where a change might be more upsetting to users, long-term, than living with the known problem(s) (where the «cure would be worse than the disease»). Basing decisions of the acceptability of some anomalies can avoid a culture of a «zero-defects» mandate, where people might be tempted to deny the existence of problems so that the result would appear as zero defects. Considering the collateral issues, such as the cost-versus-benefit impact assessment, then broader debugging techniques will expand to determine the frequency of anomalies (how often the same «bugs» occur) to help assess their impact to the overall system.
Tools[edit]

Debugging on video game consoles is usually done with special hardware such as this Xbox debug unit intended for developers.
Debugging ranges in complexity from fixing simple errors to performing lengthy and tiresome tasks of data collection, analysis, and scheduling updates. The debugging skill of the programmer can be a major factor in the ability to debug a problem, but the difficulty of software debugging varies greatly with the complexity of the system, and also depends, to some extent, on the programming language(s) used and the available tools, such as debuggers. Debuggers are software tools which enable the programmer to monitor the execution of a program, stop it, restart it, set breakpoints, and change values in memory. The term debugger can also refer to the person who is doing the debugging.
Generally, high-level programming languages, such as Java, make debugging easier, because they have features such as exception handling and type checking that make real sources of erratic behaviour easier to spot. In programming languages such as C or assembly, bugs may cause silent problems such as memory corruption, and it is often difficult to see where the initial problem happened. In those cases, memory debugger tools may be needed.
In certain situations, general purpose software tools that are language specific in nature can be very useful. These take the form of static code analysis tools. These tools look for a very specific set of known problems, some common and some rare, within the source code, concentrating more on the semantics (e.g. data flow) rather than the syntax, as compilers and interpreters do.
Both commercial and free tools exist for various languages; some claim to be able to detect hundreds of different problems. These tools can be extremely useful when checking very large source trees, where it is impractical to do code walk-throughs. A typical example of a problem detected would be a variable dereference that occurs before the variable is assigned a value. As another example, some such tools perform strong type checking when the language does not require it. Thus, they are better at locating likely errors in code that is syntactically correct. But these tools have a reputation of false positives, where correct code is flagged as dubious. The old Unix lint program is an early example.
For debugging electronic hardware (e.g., computer hardware) as well as low-level software (e.g., BIOSes, device drivers) and firmware, instruments such as oscilloscopes, logic analyzers, or in-circuit emulators (ICEs) are often used, alone or in combination. An ICE may perform many of the typical software debugger’s tasks on low-level software and firmware.
Debugging process[edit]
The debugging process normally begins with identifying the steps to reproduce the problem. This can be a non-trivial task, particularly with parallel processes and some Heisenbugs for example. The specific user environment and usage history can also make it difficult to reproduce the problem.
After the bug is reproduced, the input of the program may need to be simplified to make it easier to debug. For example, a bug in a compiler can make it crash when parsing a large source file. However, after simplification of the test case, only few lines from the original source file can be sufficient to reproduce the same crash. Simplification may be done manually using a divide-and-conquer approach, in which the programmer attempts to remove some parts of original test case then checks if the problem still occurs. When debugging in a GUI, the programmer can try skipping some user interaction from the original problem description to check if the remaining actions are sufficient for causing the bug to occur.
After the test case is sufficiently simplified, a programmer can use a debugger tool to examine program states (values of variables, plus the call stack) and track down the origin of the problem(s). Alternatively, tracing can be used. In simple cases, tracing is just a few print statements which output the values of variables at particular points during the execution of the program.[citation needed]
Techniques[edit]
- Interactive debugging uses debugger tools which allow an application’s code execution to be processed one step at a time and to be paused to inspect or alter application state. These tools commonly support watchpoints, where execution can proceed until a particular variable changes, and catchpoints which cause the debugger to stop for certain kinds of program events, such as exceptions or the loading of a shared library.
- Print debugging or tracing is the act of watching (live or recorded) trace statements, or print statements, that indicate the flow of execution of a process and the data progression. Tracing can be done with specialized tools (like with GDB’s trace) or by insertion of trace statements into the source code. The latter is sometimes called printf debugging, due to the use of the printf function in C. This kind of debugging was turned on by the command TRON in the original versions of the novice-oriented BASIC programming language. TRON stood for, «Trace On.» TRON caused the line numbers of each BASIC command line to print as the program ran.
- Remote debugging is the process of debugging a program running on a system different from the debugger. To start remote debugging, a debugger connects to a remote system over a communications link such as a local area network. The debugger can then control the execution of the program on the remote system and retrieve information about its state.
- Post-mortem debugging is debugging of the program after it has already crashed. Related techniques often include various tracing techniques like examining log files, outputting a call stack on crash,[8] and analysis of memory dump (or core dump) of the crashed process. The dump of the process could be obtained automatically by the system (for example, when the process has terminated due to an unhandled exception), or by a programmer-inserted instruction, or manually by the interactive user.
- «Wolf fence» algorithm: Edward Gauss described this simple but very useful and now famous algorithm in a 1982 article for Communications of the ACM as follows: «There’s one wolf in Alaska; how do you find it? First build a fence down the middle of the state, wait for the wolf to howl, determine which side of the fence it is on. Repeat process on that side only, until you get to the point where you can see the wolf.»[9] This is implemented e.g. in the Git version control system as the command git bisect, which uses the above algorithm to determine which commit introduced a particular bug.
- Record and replay debugging is the technique of creating a program execution recording (e.g. using Mozilla’s free rr debugging tool; enabling reversible debugging/execution), which can be replayed and interactively debugged. Useful for remote debugging and debugging intermittent, non-determinstic, and other hard-to-reproduce defects.
- Time travel debugging is the process of stepping back in time through source code (e.g. using Undo LiveRecorder) to understand what is happening during execution of a computer program; to allow users to interact with the program; to change the history if desired and to watch how the program responds.
- Delta Debugging – a technique of automating test case simplification.[10]: p.123
- Saff Squeeze – a technique of isolating failure within the test using progressive inlining of parts of the failing test.[11][12]
- Causality tracking: There are techniques to track the cause effect chains in the computation.[13] Those techniques can be tailored for specific bugs, such as null pointer dereferences.[14]
Debugging for embedded systems[edit]
In contrast to the general purpose computer software design environment, a primary characteristic of embedded environments is the sheer number of different platforms available to the developers (CPU architectures, vendors, operating systems, and their variants). Embedded systems are, by definition, not general-purpose designs: they are typically developed for a single task (or small range of tasks), and the platform is chosen specifically to optimize that application. Not only does this fact make life tough for embedded system developers, it also makes debugging and testing of these systems harder as well, since different debugging tools are needed for different platforms.
Despite the challenge of heterogeneity mentioned above, some debuggers have been developed commercially as well as research prototypes. Examples of commercial solutions come from Green Hills Software,[15] Lauterbach GmbH[16] and Microchip’s MPLAB-ICD (for in-circuit debugger). Two examples of research prototype tools are Aveksha[17] and Flocklab.[18] They all leverage a functionality available on low-cost embedded processors, an On-Chip Debug Module (OCDM), whose signals are exposed through a standard JTAG interface. They are benchmarked based on how much change to the application is needed and the rate of events that they can keep up with.
In addition to the typical task of identifying bugs in the system, embedded system debugging also seeks to collect information about the operating states of the system that may then be used to analyze the system: to find ways to boost its performance or to optimize other important characteristics (e.g. energy consumption, reliability, real-time response, etc.).
Anti-debugging[edit]
Anti-debugging is «the implementation of one or more techniques within computer code that hinders attempts at reverse engineering or debugging a target process».[19] It is actively used by recognized publishers in copy-protection schemas, but is also used by malware to complicate its detection and elimination.[20] Techniques used in anti-debugging include:
- API-based: check for the existence of a debugger using system information
- Exception-based: check to see if exceptions are interfered with
- Process and thread blocks: check whether process and thread blocks have been manipulated
- Modified code: check for code modifications made by a debugger handling software breakpoints
- Hardware- and register-based: check for hardware breakpoints and CPU registers
- Timing and latency: check the time taken for the execution of instructions
- Detecting and penalizing debugger[20]
An early example of anti-debugging existed in early versions of Microsoft Word which, if a debugger was detected, produced a message that said, «The tree of evil bears bitter fruit. Now trashing program disk.», after which it caused the floppy disk drive to emit alarming noises with the intent of scaring the user away from attempting it again.[21][22]
See also[edit]
- Assertion (software development)
- Automatic bug fixing
- Debugging pattern
- Magic debug values
- Shotgun debugging
- Software bug
- Software testing
- Time travel debugging
- Trace table
- Troubleshooting
References[edit]
- ^ «InfoWorld Oct 5, 1981». 5 October 1981. Archived from the original on September 18, 2019. Retrieved July 17, 2019.
- ^ «Archived copy». Archived from the original on 2019-11-21. Retrieved 2019-12-17.
{{cite web}}: CS1 maint: archived copy as title (link) - ^ S. Gill, The Diagnosis of Mistakes in Programmes on the EDSAC Archived 2020-03-06 at the Wayback Machine, Proceedings of the Royal Society of London. Series A, Mathematical and Physical Sciences, Vol. 206, No. 1087 (May 22, 1951), pp. 538-554
- ^ Robert V. D. Campbell, Evolution of automatic computation Archived 2019-09-18 at the Wayback Machine, Proceedings of the 1952 ACM national meeting (Pittsburgh), p 29-32, 1952.
- ^ Alex Orden, Solution of systems of linear inequalities on a digital computer, Proceedings of the 1952 ACM national meeting (Pittsburgh), p. 91-95, 1952.
- ^ Howard B. Demuth, John B. Jackson, Edmund Klein, N. Metropolis, Walter Orvedahl, James H. Richardson, MANIAC doi=10.1145/800259.808982, Proceedings of the 1952 ACM national meeting (Toronto), p. 13-16
- ^ The Compatible Time-Sharing System Archived 2012-05-27 at the Wayback Machine, M.I.T. Press, 1963
- ^ «Postmortem Debugging». Archived from the original on 2019-12-17. Retrieved 2019-12-17.
- ^ E. J. Gauss (1982). «Pracniques: The ‘Wolf Fence’ Algorithm for Debugging». Communications of the ACM. 25 (11): 780. doi:10.1145/358690.358695. S2CID 672811.
- ^ Zeller, Andreas (2005). Why Programs Fail: A Guide to Systematic Debugging. Morgan Kaufmann. ISBN 1-55860-866-4.
- ^ «Kent Beck, Hit ’em High, Hit ’em Low: Regression Testing and the Saff Squeeze». Archived from the original on 2012-03-11.
- ^ Rainsberger, J.B. «The Saff Squeeze». The Code Whisperer. Retrieved 28 March 2022.
- ^ Zeller, Andreas (2002-11-01). «Isolating cause-effect chains from computer programs». ACM SIGSOFT Software Engineering Notes. 27 (6): 1–10. doi:10.1145/605466.605468. ISSN 0163-5948. S2CID 12098165.
- ^ Bond, Michael D.; Nethercote, Nicholas; Kent, Stephen W.; Guyer, Samuel Z.; McKinley, Kathryn S. (2007). «Tracking bad apples». Proceedings of the 22nd annual ACM SIGPLAN conference on Object oriented programming systems and applications — OOPSLA ’07. p. 405. doi:10.1145/1297027.1297057. ISBN 9781595937865. S2CID 2832749.
- ^ «SuperTrace Probe hardware debugger». www.ghs.com. Archived from the original on 2017-12-01. Retrieved 2017-11-25.
- ^ «Debugger and real-time trace tools». www.lauterbach.com. Archived from the original on 2022-01-25. Retrieved 2020-06-05.
- ^ Tancreti, Matthew; Hossain, Mohammad Sajjad; Bagchi, Saurabh; Raghunathan, Vijay (2011). «Aveksha: A Hardware-software Approach for Non-intrusive Tracing and Profiling of Wireless Embedded Systems». Proceedings of the 9th ACM Conference on Embedded Networked Sensor Systems. SenSys ’11. New York, NY, USA: ACM: 288–301. doi:10.1145/2070942.2070972. ISBN 9781450307185. S2CID 14769602.
- ^ Lim, Roman; Ferrari, Federico; Zimmerling, Marco; Walser, Christoph; Sommer, Philipp; Beutel, Jan (2013). «FlockLab: A Testbed for Distributed, Synchronized Tracing and Profiling of Wireless Embedded Systems». Proceedings of the 12th International Conference on Information Processing in Sensor Networks. IPSN ’13. New York, NY, USA: ACM: 153–166. doi:10.1145/2461381.2461402. ISBN 9781450319591. S2CID 447045.
- ^ Shields, Tyler (2008-12-02). «Anti-Debugging Series – Part I». Veracode. Archived from the original on 2016-10-19. Retrieved 2009-03-17.
- ^ a b «Software Protection through Anti-Debugging Michael N Gagnon, Stephen Taylor, Anup Ghosh» (PDF). Archived from the original (PDF) on 2011-10-01. Retrieved 2010-10-25.
- ^ Ross J. Anderson (2001-03-23). Security Engineering. p. 684. ISBN 0-471-38922-6.
- ^ «Microsoft Word for DOS 1.15». Archived from the original on 2013-05-14. Retrieved 2013-06-22.
Further reading[edit]
- Agans, David J. (2002). Debugging: The Nine Indispensable Rules for Finding Even the Most Elusive Software and Hardware Problems. AMACOM. ISBN 0-8144-7168-4.
- Blunden, Bill (2003). Software Exorcism: A Handbook for Debugging and Optimizing Legacy Code. APress. ISBN 1-59059-234-4.
- Ford, Ann R.; Teorey, Toby J. (2002). Practical Debugging in C++. Prentice Hall. ISBN 0-13-065394-2.
- Grötker, Thorsten; Holtmann, Ulrich; Keding, Holger; Wloka, Markus (2012). The Developer’s Guide to Debugging, Second Edition. Createspace. ISBN 978-1-4701-8552-7.
- Metzger, Robert C. (2003). Debugging by Thinking: A Multidisciplinary Approach. Digital Press. ISBN 1-55558-307-5.
- Myers, Glenford J (2004). The Art of Software Testing. John Wiley & Sons Inc. ISBN 0-471-04328-1.
- Robbins, John (2000). Debugging Applications. Microsoft Press. ISBN 0-7356-0886-5.
- Telles, Matthew A.; Hsieh, Yuan (2001). The Science of Debugging. The Coriolis Group. ISBN 1-57610-917-8.
- Vostokov, Dmitry (2008). Memory Dump Analysis Anthology Volume 1. OpenTask. ISBN 978-0-9558328-0-2.
- Zeller, Andreas (2009). Why Programs Fail, Second Edition: A Guide to Systematic Debugging. Morgan Kaufmann. ISBN 978-0-1237-4515-6.
- Peggy Aldrich Kidwell, Stalking the Elusive Computer Bug, IEEE Annals of the History of Computing, 1998.
External links[edit]
![]()
Wikiquote has quotations related to Debugging.
- Crash dump analysis patterns – in-depth articles on analyzing and finding bugs in crash dumps
- Learn the essentials of debugging – how to improve your debugging skills, a good article at IBM developerWorks (archived from the original on February 18, 2007)
- Plug-in Based Debugging For Embedded Systems
- Embedded Systems test and debug – about digital input generation – results of a survey about embedded system test and debug, Byte Paradigm (archived from the original on January 12, 2012)