Содержание
- Stack in Python
- Implementation:
- Implementation using list:
- Python3
- Implementation using collections.deque:
- Python3
- Implementation using queue module
- How to Solve Python Coding Questions using Stack
- An essential data type for Data Scientists and Soft Engineers in 2021
- Stack it up
- Question 1: Remove All Adjacent Duplicates In String, by Facebook, Amazon, Bloomberg, Oracle
- Walk Through My Thinking
- Solution
- # Question 2: Make The String Great, by Google
- Solution 1
- Solution 2
- # Question 3: Build an Array With Stack Operations, by Google
- Walk Through My Thinking
- Solution
- # Question 4: Baseball Game, by Amazon
- Walk Through My Thinking
- Solution
- # Question 5: Next Greater Element I, by Amazon and Bloomberg
- Walk Through My Thinking
- Solution 1
- Solution 2
- Takeaways
Stack in Python
A stack is a linear data structure that stores items in a Last-In/First-Out (LIFO) or First-In/Last-Out (FILO) manner. In stack, a new element is added at one end and an element is removed from that end only. The insert and delete operations are often called push and pop.
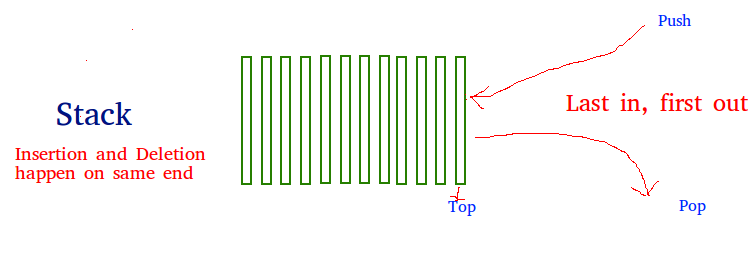
The functions associated with stack are:
- empty() – Returns whether the stack is empty – Time Complexity: O(1)
- size() – Returns the size of the stack – Time Complexity: O(1)
- top() / peek() – Returns a reference to the topmost element of the stack – Time Complexity: O(1)
- push(a) – Inserts the element ‘a’ at the top of the stack – Time Complexity: O(1)
- pop() – Deletes the topmost element of the stack – Time Complexity: O(1)
Implementation:
There are various ways from which a stack can be implemented in Python. This article covers the implementation of a stack using data structures and modules from the Python library.
Stack in Python can be implemented using the following ways:
- list
- Collections.deque
- queue.LifoQueue
Implementation using list:
Python’s built-in data structure list can be used as a stack. Instead of push(), append() is used to add elements to the top of the stack while pop() removes the element in LIFO order.
Unfortunately, the list has a few shortcomings. The biggest issue is that it can run into speed issues as it grows. The items in the list are stored next to each other in memory, if the stack grows bigger than the block of memory that currently holds it, then Python needs to do some memory allocations. This can lead to some append() calls taking much longer than other ones.
Python3
Implementation using collections.deque:
Python stack can be implemented using the deque class from the collections module. Deque is preferred over the list in the cases where we need quicker append and pop operations from both the ends of the container, as deque provides an O(1) time complexity for append and pop operations as compared to list which provides O(n) time complexity.

The same methods on deque as seen in the list are used, append() and pop().
Python3
Implementation using queue module
Queue module also has a LIFO Queue, which is basically a Stack. Data is inserted into Queue using the put() function and get() takes data out from the Queue.
There are various functions available in this module:
- maxsize – Number of items allowed in the queue.
- empty() – Return True if the queue is empty, False otherwise.
- full() – Return True if there are maxsize items in the queue. If the queue was initialized with maxsize=0 (the default), then full() never returns True.
- get() – Remove and return an item from the queue. If the queue is empty, wait until an item is available.
- get_nowait() – Return an item if one is immediately available, else raise QueueEmpty.
- put(item) – Put an item into the queue. If the queue is full, wait until a free slot is available before adding the item.
- put_nowait(item) – Put an item into the queue without blocking. If no free slot is immediately available, raise QueueFull.
- qsize() – Return the number of items in the queue.
Источник
How to Solve Python Coding Questions using Stack
An essential data type for Data Scientists and Soft Engineers in 2021
Python is a versatile script-based programming language with a wide application in Artificial Intelligence, Machine Learning, Deep Learning, and Soft Engineering. Its popularity benefits from the various Data Types that Python stores.
Dictionary is the natural choice if we have to store key and value pairs, as in today’s Question 5. String and list are a pair of twin sisters that come together and solve string manipulation questions. Set holds a unique position as it does not allow duplicates, a unique feature that allows us to identify the repetitive and non-repetitive items. Well, tuple is the least frequently asked data type in technical interviews. Last week, a senior Data Scientist posted a coding question on Twitter, which can be easily solved via tuple. However, a lot of candidates got tripped over. I’ll write another post on the topic soon.
Data Types play an essential part in Python programming! Being able to differentiate one from another is super important for solving interview questions. In today’s post, let’s shift gears to another essential data type called Stack.
In writing this blog post, I have spent countless hours selecting the following questions and rank them in a way that is easily understandable to new programmers. Each question builds up upon the previous ones. If possible, please solve the problems in sequence.
Stack it up
A stack is a linear data structure that keeps elements in a Last-In/First-Out (LIFO) or First-In/Last-Out (FILO) manner (GeeksForGeeks ). It means that elements last added will be popped from the stack first. We can picture a stack of plates: we always use the plate on the top that last added to the pile. Push and pop are the most fundamental operations of a stack, laying the ground for other more advanced adoptions.
In Python, there are three ways of implementing a stack: using a list, collections.deque, and linked list. To prepare for Data Science Interviews, the first approach is sufficiently good enough. In case you are interested in the other two, please check this post (link).
In Python, we can simply use a list to represent a stack. So, it has the same attributes as a list. It has two basic operations: push() and pop(). To push, or add, an element to a stack, we use the append() method. To pop, or delete, the last element, we use the pop() method, as follows.
Question 1: Remove All Adjacent Duplicates In String, by Facebook, Amazon, Bloomberg, Oracle
— Given a string S of lowercase letters, a duplicate removal consists of choosing two adjacent and equal letters, and removing them.
— We repeatedly make duplicate removals on S until we no longer can.
— Return the final string after all such duplicate removals have been made. It is guaranteed the answer is unique.
— https://leetcode.com/problems/remove-all-adjacent-duplicates-in-string/
Walk Through My Thinking
Facebook, Amazon, Bloomberg, and Oracle included this question. While reading the question prompt, I find the following keywords worth noting: duplicate removal, two adjacent and equal, and duplicate removals. Simply put, the question translates into removing the adjacent equal letters. The translation process is crucial to simplify the question, as a lot of times, the prompt contains too much trivial information that distracts us from solving the problem. Also, identifying the key points and speaking them out loud keep the interviewer engaged.
To check if two letters are equal, the first thing that comes to my mind is to adopt brutal force and check for the same element at two consecutive positions. However, this method does not work as the removal process is dynamic.
Let’s say the test case is ‘ abbaca.’ If using the brutal force, we would only be able to remove ‘ bb’ the string but not the new combination ‘ aa’ created after deleting ‘ bb.’
We need a dynamic solution that checks if the newly created consecutive positions have the same element.
Fortunately, the universe offers stack!
We can create an empty stack (list) to store new elements. If the element is equal to the last element in the stack, we pop it out from the stack and don’t add the new element to the list. In other words, the simple pop operation removes two neighboring identical letters. Pretty neat! In the end, we rejoin the list to an empty string, a common transformation tactic.
Solution
As a warm-up, I intentionally choose this question for its simplicity. The following questions may look slightly challenging but totally solvable following the same process.
# Question 2: Make The String Great, by Google
— Given a string s of lower and upper case English letters.
— A good string is a string which doesn’t have two adjacent characters s[i] and s[i + 1] where: 0 Google asked this question. Let’s scan the prompt again and retrieve the key information. Here are the eye-catching keywords: two adjacent characters, one in lower-case and the next is in upper-case (vice-versa), remove two adjacent characters of different cases. Simply, the question wants us to remove two adjacent characters of different cases (one upper and one lower, regardless of positions).
Remember to speak out your mind and let your interviewer know you have captured the key information. If you don’t, your interviewer will ask for justifications why you decide to adopt stack but not other data types.
Following the same logic as Question 1, we create an empty stack to store elements and check if the to-be-added letter is the same but of a different case. In Python, there are different ways of checking cases. If you don’t know any built-in method/function, like me, we can follow the following steps: first make sure these two letters are not the same ( stack[-1] != i) and second they become the same after using the lower method ( stack[-1].lower() ==i.lower()).
Here is a catch. We can’t pop an element from an empty stack. It would generate an index error. Like the following:
To avoid the error message, we have to ensure the stack is not empty using if stack in line 4. This is one of the most common mistakes that Python programmers make while using a stack.
Solution 1
Solution 2
As it turns out, Python has a built-in method, swapcase(), that switches letters from upper case to lower case, vice versa. Also, you may want to check with the interviewer if you can use any built-in method. Keep communicating!
# Question 3: Build an Array With Stack Operations, by Google
— Given an array target and an integer n. In each iteration, you will read a number from list = <1,2,3…, n>.
— Build the target array using the following operations:
— Push: Read a new element from the beginning list, and push it in the array.
— Pop: delete the last element of the array.
— If the target array is already built, stop reading more elements.
— Return the operations to build the target array. You are guaranteed that the answer is unique.
— https://leetcode.com/problems/build-an-array-with-stack-operations/
Walk Through My Thinking
Google asked this question. This question is so user-friendly, and it explicitly tells you to push and pop elements. A stack is in order!
Creating an empty stack and iterate over the list: pushing elements to the new stack and popping the last element. Lastly, check if the constructed array is the same as the target array. If so, stop the iteration.
The only catch is to break the for loop if we have obtained the target array. To do so, keep the indentation block of stack==target (line 16 & 17) in line with the if-else statement. Interviewers may likely ask follow-up questions about why you keep the indentation inside the for loop rather than outside.
Solution
# Question 4: Baseball Game, by Amazon
— You are keeping score for a baseball game with strange rules. The game consists of several rounds, where the scores of past rounds may affect future rounds’ scores.
— At the beginning of the game, you start with an empty record. You are given a list of strings ops, where ops[i] is the ith operation you must apply to the record and is one of the following:
— An integer x — Record a new score of x.
— “+” — Record a new score that is the sum of the previous two scores. It is guaranteed there will always be two previous scores.
— “D” — Record a new score that is double the previous score. It is guaranteed there will always be a previous score.
— “C” — Invalidate the previous score, removing it from the record. It is guaranteed there will always be a previous score.
— Return the sum of all the scores on the record.
— https://leetcode.com/problems/baseball-game/
Walk Through My Thinking
Amazon picked this question. This is another interviewee-friendly question as it tells you to push and pop elements. Also, we need to use a control flow using multiple if statements. The procedure of building a stack and adding/removing elements is the same as the above questions. Here, I focus on the unique attribute of this question that needs special attention.
Usually, we have to check if a stack is empty or not before popping elements, as in Question 2. However, we don’t have to check for this question because the prompt tells us that there will always be a previous score. Without the extra condition, the question becomes slightly messier. In the end, we use a sum() function to return the sum of all the scores.
Solution
# Question 5: Next Greater Element I, by Amazon and Bloomberg
— You are given two integer arrays nums1 and nums2 both of unique elements, where nums1 is a subset of nums2.
— Find all the next greater numbers for nums1’s elements in the corresponding places of nums2.
— The Next Greater Number of a number x in nums1 is the first greater number to its right in nums2. If it does not exist, return -1 for this number.
— https://leetcode.com/problems/next-greater-element-i/
Walk Through My Thinking
Amazon and Blooomberg picked this question. Question 5 requires more than a 2-step solution. But first, the eye-catching keywords include: nums1 is a subset of nums2, find the next greater numbers for nums1 in nums2, and return -1 for none.
In my mind, here is the translation process:
Taken together, we have to find a way of identifying the position and value of an element and use if-else statements to compare values.
To find the position and value of an element, the natural choice is to use the enumerate() function. Also, we want to use a dictionary to keep records of the key-value pairs.
Next, we iterate over the array nums2 and find the next greater item. If there is such an item, we break the for loop; otherwise, return -1. The complete code is in Solution 1.
Solution 1
This approach makes intuitive sense, and it’s easy to follow.
Solution 2
Disclaimer: Solution 2 is not my original code, and special credits go to aditya baurai ’s post .
As it turns out, we can adopt a stack and a dictionary. First, we create an empty stack/dictionary and iterate over nums2:
To clarify, the for loop iterates over all of the elements in nums2, and the while loop is to find the next greater element in nums2 compared to the stack. To better help us understand, we can loop over the first 2 elements of nums2.
In brief, the above code finds all of the greater elements in nums2, and then we find the corresponding value for elements in nums1 in the end.
The complete Python code is available on my Github .
Takeaways
- Stack has two operations: push() and pop().
- Identify the keywords and communicate with your interviewer.
- Stack often teams up with the following keywords: two consecutive identical letters/numbers/words, push and pop an element if it is related somehow to the previous position.
- Check if it is an empty stack before popping.
- Indentation is crucial for loops. Understand the question well and decide its position (inside or outside the loop).
- Complicated coding questions can be disaggregated into multiple smaller pieces.
Medium recently evolved its Writer Partner Program , which supports ordinary writers like myself. If you are not a subscriber yet and sign up via the following link, I’ll receive a portion of the membership fees.
Источник
Array-Based Stack Implementation.
This utilizes the built-in Python list type, and wraps it with a Stack ADT interface.
Contents
- 1 Class description
- 2 Class test
- 3 Exceptions and error handling
- 4 Class implementation
- 5 Flags
Class description
Recap: Definition of stack abstract data type (Stack ADT):
A stack is an abstract data type (ADT) such that an instance S supports the following two methods:
- S.push(e): add element e to the top of the stack S
- S.pop: remove and return the top element from the stack S; an error occurs if the stack is empty.
Additionally, accessor methods for convenience:
- S.peek(): get reference to top element without removing it; an error occurs if the stack is empty.
- S.is_empty(): return True if stack S contains no elements
- len(S): implemented via builtin __len__
The ArrayStack class implements the above abstraction using an array-based structure (a list).
Link: https://git.charlesreid1.com/cs/python/src/master/stacks-queues-deques/stacks/ArrayStack.py
Class test
Taking a look first at our test, we should be able to run the following code after implementing the above methods:
if __name__=="__main__":
a = ArrayStack()
a.push(5)
a.push(15)
a.push(17)
a.push(28)
print("Peeking: {0}".format(a.peek()))
print("Length of stack: {0}".format(len(a)))
a.pop()
a.pop()
a.push(100)
a.push(200)
a.push(300)
a.push(400)
while(not a.is_empty()):
a.pop()
print("Popping... {0}".format(len(a)))
print("Done testing ArrayStack.")
Exceptions and error handling
The specification of the ADT mentions two cases where errors should be thrown — both occurring if the stack is empty.
Create our own Empty exception:
class Empty(Exception):
pass
Class implementation
"""
Stack ADT: ArrayStack
This class implements the following methods:
S.push(e)
S.pop()
S.peek()
S.is_empty()
len(S)
This class utilizes an array-based data structure,
a list, to store its data under the hood.
It only needs to keep track of that list.
This makes it an adapter class for the list,
since it adheres to the Stack ADT but does not change
the implementation of the underlying list type.
"""
class ArrayStack:
"""
Implement the Stack ADT using an array-based data structure (list).
"""
def __init__(self):
self._data = []
def __len__(self):
return len(self._data)
def __str__(self):
return str(self._data)
def is_empty(self):
"""
Check if empty. Don't bother calling our own __len__.
Just do what is sensible.
"""
return (len(self._data)==0)
def push(self,o):
"""
Add an element to the top of the stack
"""
self._data.append(o)
def pop(self):
"""
Pop the next item.
This should handle an empty stack.
"""
if( self.is_empty() ):
raise Empty("Stack is empty")
return self._data.pop()
def peek(self):
"""
Peek at the next item.
This should handle an empty stack.
"""
if( self.is_empty() ):
raise Empty("Stack is empty")
return self._data[-1]
This is an adapter pattern for the list class.
Flags

Do you want to learn more about Computer Science fundamentals? Do you want to gain deeper knowledge to help you pass your interviews? Then it’s vital that you study data structures. I always say that Python is the perfect first language to learn: it has a straightforward, English-like syntax that makes reading it a breeze; but it’s also extremely powerful and can be used in a multitude of ways.
In this article, I will be showing you some of the most common Data Structures using Python. I will be teaching you Stacks, Queues, Linked Lists, and Trees. You don’t need to be an expert in Python to follow along, but it is recommended that you at least understand how classes and functions in Python work.
ADTs vs Data Structures
Before moving on, it’s important you know the difference between two similar (but very different) words: ADT and Data Structure.
- ADT (Abstract Data Type) – a ‘model’ or a ‘blueprint’ for a data structure. It defines which functions or operations a data structure must have to be considered as such. The benefits of ADTs are that it is much easier to understand since you are seeing a “high-level” overview, instead of getting bogged down in the “low-level” code.
- Data Structure – the implementation of an Abstract Data Type. They are the building blocks of any piece of software. It can be defined as a group of data elements that provide a structured way of storing and organizing data so that it can be used efficiently. Different data structures serve different purposes, and as a computer scientist, it is your job to know the pros and cons and ins and outs of each data structure (so that you may pick the right one for the job). This blog article should be seen as an intro to the subject and not a complete essay regarding each data type. For that, I recommend Mosh’s “Ultimate Data Structures and Algorithms Course”.
“Data Structures” (at University) is known as a ‘weed-out’ class, and that’s not without good reason. For many, it is very difficult to visualize something that isn’t there. But I say anyone can do it. That’s right, anyone! All it takes is practice, practice, practice. Are you getting it yet? PRACTICE! Without further adieu, let’s get into it!
Stacks
- Stacks -the simplest of all data structures, but also the most important. A stack is a collection of objects that are inserted and removed using the LIFO principle. LIFO stands for “Last In First Out”. Because of the way stacks are structured, the last item added is the first to be removed, and vice-versa: the first item added is the last to be removed.
You can think of Stacks like a PEZ candy dispenser. You put the candy into the dispenser, and once it is full, you start taking the candy back out. BUT, the last piece added is the first piece that comes back out. That is the perfect example of LIFO.
Figure 1.1: PEZ Candy Dispensers are LIFO


Stack’s ADT Operations:
A ‘Stack‘ is an ADT such that S (stack) supports the following methods:
- S.push(e): Adds an element to the top of stack S.
- S.pop(): Removes and returns the element from the top of stack S. Error occurs if empty.
- S.peek(): Returns a reference to the top of stack S without removing it. Error occurs if empty.
- S.is_empty(): Returns True if no elements found in stack S, else returns False
- S.size(): Returns the number of elements in stack S.
Figure 1.2: The following table shows the previously discussed stack operations performed on an empty stack

Figure 1.3: Operations Applied to a Stack

Adapter Pattern
Though some would assume that a list in Python is synonymous with a Stack Data Structure, it is not the case. The python list includes behaviors that are not included in the Stack ADT. Also, much of the terminology for the function names are different.
When we want to modify an existing class so that its methods match those of a related but different class or interface, we can use the adapter design pattern. Let’s code a class called StackADT that extends the Python list class. Its underlying data will use a list, but the method names that use the list class will all be named after the methods in the Stack ADT.
Stack Data Structure
Are you following me so far? I know it’s a lot to take in, but bear with me! You’ll be using Data Structures in no time. As we talked about before, a Data Structure is the implementation of an ADT in code.
Here is the code for a stack with the functions from its ADT:
# LIFO Stack implementation using a Python list as
# its underlying storage.
class StackADT:
# Create an empty stack.
def __init__(self):
self.data = []
# Add element e to the top of the stack
def push(self, e):
self.data.append(e)
# Remove and return the element from the top of the stack
# (i.e., LIFO). Raise exception if the stack is empty.
def pop(self):
if self.is_empty():
raise IndexError('Stack is empty')
else:
return self.data.pop()
# Return (but do not remove) the element at the top of
# the stack. Raise Empty exception if the stack is empty.
def peek(self):
if self.is_empty():
raise IndexError('Stack is empty')
else:
return self.data[-1]
# Return True if the stack is empty.
def is_empty(self):
return len(self.data) == 0
# Return the number of elements in the stack.
def size(self):
return len(self.data)
S = StackADT()
S.push("S")
S.push("T")
S.push("A")
S.push("C")
S.push("K")
S.peek() # K
S.size() # 5
S.is_empty() # False
S.pop() # K
S.pop() # C
S.pop() # A
S.pop() # T
S.pop() # S
S.is_empty() # True
S.size() # 0
S.peek() # IndexError: Stack is empty
I’m sure you noticed that when we pushed an item onto the stack, then pushed another, the original item got buried deeper and deeper. Then, when we popped an item off the top of the stack, the most recent item that we added was the first to be returned. That’s because it follows the LIFO (Last In First Out) pattern.
Queues
- Queues – essentially a modified stack. It is a collection of objects that are inserted and removed according to the FIFO (First In First Out) principle. Queues are analogous to a line at the grocery store: people are added to the line from the back, and the first in line is the first that gets checked out – BOOM, FIFO!
- Items are added to the back and removed from the front. Simple, right? A queue would be a great data structure to handle incoming calls to a business, or an online shopping store!
Figure 2.1: A Checkout Line Is FIFO

Queue’s ADT Operations:
A queue is a collection of objects where access and deletion are limited to the first element and where insertion is limited to the back of the queue. This rule enforces the FIFO principle.
A ‘Queue‘ is an ADT such that Q (queue) supports the following methods:
- S.enqueue(e): Adds an element to the back of queue Q..
- S.dequeue(): Removes and returns the first element from queue Q. Error occurs if empty.
- S.peek(): Returns a reference to the first element of queue Q without removing it. Error occurs if empty.
- S.is_empty(): Returns True if no elements found in queue Q, else returns False
- S.size(): Returns the number of elements in queue Q.
Figure 2.2: The following table shows the previously discussed queue operations performed on an empty queue

Figure 2.3: Operations Applied to a Queue

Queue’s Data Structure
Now that we’ve covered the methods that a queue must possess, let’s get into writing some code! If you’ve made it this far, pat yourself on the back because you’re one step closer to mastering data structures – the backbone of computer science.
Here is the code for a queue with the functions from its ADT:
# FIFO Queue implementation using a Python list as
# its underlying storage.
class QueueADT:
# Create an empty queue.
def __init__(self):
self.data = []
# Add element e to the back of the queue
def enqueue(self, e):
self.data.insert(0, e)
# Remove and return the element from the front of the queue
# (i.e., FIFO). Raise exception if the queue is empty.
def dequeue(self):
if self.is_empty():
raise IndexError('Queue is empty')
else:
return self.data.pop()
# Return (but do not remove) the first element of the
# queue. Raise exception if the queue is empty.
def peek(self):
if self.is_empty():
raise IndexError('Queue is empty')
else:
return self.data[-1]
# Return True if the queue is empty.
def is_empty(self):
return len(self.data) == 0
# Return the number of elements in the queue.
def size(self):
return len(self.data)
Q = QueueADT()
Q.enqueue("Q")
Q.enqueue("U")
Q.enqueue("E")
Q.enqueue("U")
Q.enqueue("E")
Q.peek() # Q
Q.size() # 5
Q.is_empty() # False
Q.dequeue() # Q
Q.dequeue() # U
Q.dequeue() # E
Q.dequeue() # U
Q.dequeue() # E
Q.is_empty() # True
Q.size() # 0
Q.peek() # IndexError: Queue is empty
- Notice how in the enqueue method, I didn’t just append the item to the end of the list? That would have merely added the item to the end of the queue, defeating its entire purpose. Instead, we insert the item at the first position in the list. This follows the queue Abstract Data Type and ensures that it follows the FIFO (first in first out) pattern.
- Then in the dequeue method, the item is removed and returned from the front of the list, just like a line at the grocery store. See! It’s not that bad once we chunk it down and use analogies! The key to mastering any subject is to have a firm grasp on the fundamentals, and programming is NO different.
Linked Lists
The Stack and Queue representations I just shared with you employ the python-based list to store their elements. A python list is nothing more than a dynamic array, which has some disadvantages.
- The length of the dynamic array may be longer than the number of elements it stores, taking up precious free space.
- Insertion and deletion from arrays are expensive since you must move the items next to them over
Using Linked Lists to implement a stack and a queue (instead of a dynamic array) solve both of these issues; addition and removal from both of these data structures (when implemented with a linked list) can be accomplished in constant O(1) time. This is a HUGE advantage when dealing with lists of millions of items.
- Linked Lists – comprised of ‘Nodes’. Each node stores a piece of data and a reference to its next and/or previous node. This builds a linear sequence of nodes. All Linked Lists store a head, which is a reference to the first node. Some Linked Lists also store a tail, a reference to the last node in the list.
*Note: Linked Lists do not have a “set-in-stone” set of operations. Linked Lists are merely data structures used to create other ADTs/data structures, such as Stacks or Queues.
Stack: Implemented From a Linked List
The operations for a stack made from a linked list are the same as the operations from a stack made from an array.
Figure 3.1: Linked List Implemented as a Stack

The Code
# LIFO Stack implementation using a linked list
# as its underlying storage
class LinkedListStack:
# ----------------------Nested Node Class ----------------------
# This Node class stores a piece of data (element) and
# a reference to the Next node in the Linked List
class Node:
def __init__(self, e):
self.element = e
self.next = None # reference to the next Node
# ---------------------- stack methods -------------------------
# Create an empty stack
def __init__(self):
self._size = 0
# reference to head node (top of stack)
self.head = None
# Add element e to the top of the stack.
def push(self, e):
# New node inserted at Head
newest = self.Node(e)
newest.next = self.head
self.head = newest
self._size += 1
# Remove and return the element from the top of the stack
# (i.e., LIFO). Raise exception if the stack is empty.
def pop(self):
if self.is_empty():
raise IndexError('Stack is empty')
elementToReturn = self.head.element
self.head = self.head.next
self._size -= 1
return elementToReturn
# Return (but do not remove) the element at the top of
# the stack. Raise Empty exception if the stack is empty.
def peek(self):
if self.is_empty():
raise IndexError('Stack is empty')
return self.head.element
# Return True if the stack is empty.
def is_empty(self):
return self._size == 0
# Return the number of elements in the stack.
def size(self):
return self._size
LLS = LinkedListStack()
LLS.push("L")
LLS.push("L")
LLS.push("S")
LLS.push("T")
LLS.push("A")
LLS.push("C")
LLS.push("K")
LLS.peek() # K
LLS.size() # 7
LLS.is_empty() # False
LLS.pop() # K
LLS.pop() # C
LLS.pop() # A
LLS.pop() # T
LLS.pop() # S
LLS.pop() # L
LLS.pop() # L
LLS.is_empty() # True
LLS.size() # 0
LLS.peek() # IndexError: Stack is empty
Queue: Implemented From a Linked List
The operations for a queue made from a linked list are the same as the operations for a queue made from an array.
Figure 3.2: Linked List Implemented as a Queue

The Code
# FIFO Queue implementation using a linked list
# as its underlying storage
class LinkedListQueue:
# ----------------------Nested Node Class ----------------------
# This Node class stores a piece of data (element) and
# a reference to the Next node in the Linked List
class Node:
def __init__(self, e):
self.element = e
self.next = None # reference to the next Node
# ---------------------- queue methods -------------------------
# create an empty queue
def __init__(self):
self._size = 0
self.head = None
self.tail = None
# Add element e to the back of the queue.
def enqueue(self, e):
newest = self.Node(e)
if self.is_empty():
self.head = newest
else:
self.tail.next = newest
self.tail = newest
self._size += 1
# Remove and return the first element from the queue
# (i.e., FIFO). Raise exception if the queue is empty.
def dequeue(self):
if self.is_empty():
raise IndexError('Queue is empty')
elementToReturn = self.head.element
self.head = self.head.next
self._size -= 1
if self.is_empty():
self.tail = None
return elementToReturn
# Return (but do not remove) the element at the front of
# the queue. Raise exception if the queue is empty.
def peek(self):
if self.is_empty():
raise IndexError('Queue is empty')
return self.head.element
# Return True if the queue is empty.
def is_empty(self):
return self._size == 0
# Return the number of elements in the queue.
def size(self):
return self._size
LLQ = LinkedListQueue()
LLQ.enqueue("L")
LLQ.enqueue("L")
LLQ.enqueue("Q")
LLQ.enqueue("U")
LLQ.enqueue("E")
LLQ.enqueue("U")
LLQ.enqueue("E")
LLQ.peek() # L
LLQ.size() # 7
LLQ.is_empty() # False
LLQ.dequeue() # L
LLQ.dequeue() # L
LLQ.dequeue() # Q
LLQ.dequeue() # U
LLQ.dequeue() # E
LLQ.dequeue() # U
LLQ.dequeue() # E
LLQ.is_empty() # True
LLQ.size() # 0
LLQ.peek() # IndexError: Queue is empty
Trees
- Trees are a bit more advanced than the previous Data Structures. Though they still use Nodes, they are “hierarchical” as opposed to “linear” in nature. “Hierarchical” means that some objects are below, and some are above others.
- In fact, the exact terminology comes from the terminology from family trees – with the terms “parent”, “child”, “ancestor”, and “descendant” being used to describe the relationships.
- Binary Trees are what most developers usually learn and get comfortable with first, so that’s what we’re going to focus on. A binary tree has a root node, which can have a left child node and a right child node. BSTs are usually comprised of integers, because every left child and subtree is less than the value of its parent, and every right child and subtree is greater than the value of its parent.
- Edge – each path connecting the nodes
- Leaf Nodes – nodes that do not have any children.
Binary Search Tree ADT Operations:
A ‘Binary Search Tree‘ is an ADT such that T (tree) supports the following methods:
- T.add_node(e): Adds a node with element e to tree T.
- T.height(): Returns the largest number of edges in a path from root node of tree T to a leaf node.
- T.traverse_in_order(): Recursively prints the values in tree T in ascending order.
- T.is_empty(): Returns True if no elements found in tree T, else returns False
- T.size(): Returns the number of elements in tree T.
Figure 4.1: The following table shows the previously discussed Tree operations performed on an empty Tree

Figure 4.2: Operations Applied to a Tree

The Code
# Binary Search Tree Python implementation
class BinarySearchTree:
# ----------------------Nested Node Class ----------------------
# This Node class stores a piece of data (element) and
# a reference to it's left and right children
class Node:
__slots__ = 'element', 'left', 'right'
def __init__(self, e):
self.element = e
self.left = None # reference to the left Child
self.right = None # reference to the right Child
# ---------------------- BST methods -------------------------
# create an empty BST
def __init__(self):
self.root = None
self._size = 0
# Recursively add element e to the tree
def add_node(self, root, e):
# If no root exists, set new Node as root
if self.root == None:
self.root = self.Node(e)
self._size += 1
return
if e < root.element:
if root.left == None:
root.left = self.Node(e)
self._size += 1
else:
self.add_node(root.left, e)
else:
if root.right == None:
root.right = self.Node(e)
self._size += 1
else:
self.add_node(root.right, e)
# Recursively prints the values in tree in
# ascending order.
def traverse_in_order(self, root):
if root != None:
self.traverse_in_order(root.left)
print(root.element, end=" ")
self.traverse_in_order(root.right)
# Returns the largest number of edges in a path from
# root node of tree to a leaf node.
def height(self, root):
if root == None:
return 0
return max(self.height(root.left),
self.height(root.right)) + 1
# Returns True if no elements found in tree,
# else returns False
def is_empty(self):
return self._size == 0
# Returns the number of elements in tree
def size(self):
return self._size
t = BinarySearchTree()
t.is_empty() # True
t.add_node(t.root, 56)
t.add_node(t.root, 13)
t.add_node(t.root, 1)
t.add_node(t.root, 6)
t.add_node(t.root, 3)
t.add_node(t.root, 67)
t.add_node(t.root, 3)
t.add_node(t.root, 45)
t.add_node(t.root, 99)
t.add_node(t.root, 2)
t.is_empty() # False
t.size() # 10
t.height(t.root) # 6
t.traverse_in_order(t.root) # 1 2 3 3 6 13 45 56 67 99
- As I’m sure you noticed, the add_node(), traverse_in_order(), and height() methods all use recursion (functions that call themselves). This is a common paradigm used in trees, as the code is MUCH less verbose than writing their iterative counterparts.
Let’s walk through the add_node() method together. We start with an empty tree and call add_node() four times.
t = BinarySearchTree() t.add_node(t.root, 56) t.add_node(t.root, 18) t.add_node(t.root, 99) t.add_node(t.root, 21)
Now we should have a tree that looks like this:
Figure 4.3: Tree after addition of nodes 56, 18, 99, & 21

Adding the Root
if self.root == None:
self.root = self.Node(e)
self._size += 1
return
- The first block of the add_node method checks for the existence of a root.
- When we add the first element (56) we don’t yet have a root, so the code if self.root == None resolves to true and the code block is triggered.
- Next, a node with element 56 is created and set as the Binary Search Tree’s root.
- Finally, increase the size of the tree by 1 and return.
Let’s skip the addition of nodes 18, 99, and 21. We’ll jump straight to adding node 19:
t.add_node(t.root, 19)
Call 1
- It checks for the existence of a root. There IS a root, so it skips that code block.
- Next, it checks if 19 is less or greater than the passed root (56) —> 19 is less than 56.
- Is the left subtree empty? NO.
- add_node calls itself with the left subtree as the root – add_node(root.left, 19)
Call 2
- It checks for the existence of a root. There IS a root, so it skips that code block.
- Next, it checks if 19 is less or greater than the passed root (18) —> 19 is greater than 18.
- Is the right subtree empty? NO.
- add_node calls itself with the right subtree as the root – add_node(root.right, 19)
Call 3
- It checks for the existence of a root. There IS a root, so it skips that code block.
- Next, it checks if 19 is less or greater than the passed root (21) —> 19 is less than 21.
- Is the left subtree empty? YES.
- A node with element 19 is created and inserted as node 21’s left child.
- Increase the size of the tree by 1.
Figure 4.4: Tree showing recursive addition of node 19

Recap
Let’s recap what you’ve learned in this article:
- ADTs (Abstract Data Types) – ‘models’ or ‘blueprints’ for data structures. It defines which functions or operations a data structure must have to be considered as such.
- Data Structures – the implementation of Abstract Data Types. They are the building blocks of any piece of software and crucial knowledge for a computer scientist.
- Stack – a collection of objects that are inserted and removed using the LIFO (Last In First Out) principle. The last item added to a stack is the first to be removed and vice versa.
- Queue – a collection of objects that are inserted and removed according to the FIFO (First In First Out) principle. Items are added to the back of a queue and removed from the front, and the first item added is the first to be removed (and vice versa)
- Linked Lists – comprised of ‘Nodes’. Each node stores a piece of data and a reference to its next and/or previous node. This builds a linear sequence of nodes.
- Linked Lists can be programmed to implement a Stack, a Queue, or any other number of linear Data Structures.
- Trees – hierarchical data structures that are comprised of nodes. Binary Search Trees are a type of tree in which each node has a reference to left and right “children” nodes. Every left child/subtree is less than the value of its parent, and every right child/subtree is greater than the value of its parent.
- BSTs – implement many of their methods recursively since its much less verbose than their iterative alternative
Wheeeeww!! That was a long one. I hope you enjoyed reading this article as much as I enjoyed writing it. Remember, data structures come up all the time in interviews. So the more you study and understand how they work, the better you’ll be able to answer their questions. Be a padawan now, so you can show off your Jedi skills later 🙂
Do you want to become a React master? If so, check out Mosh’s React course. It’s the best React course out there! And if you liked this article, share it with others as well!

As a graduate of the University of Florida Herbert Wertheim College of Engineering, I immersed myself in the world of Computer Science. My passions extend beyond the realm of technology, however. I have an affinity for music composition, film-making, and gaming. I currently reside in Palm Beach, Florida, with my wife Estefania and our teacup Shih Tzu, Molly.
Tags: data structure, linked list, python, queue, stack, tree
In this tutorial we will create a stack in Python step-by-step. The stack is a LIFO (Last-in First-out) data structure.
To create a stack in Python you can use a class with a single attribute of type list. The elements of the stack are stored in the list using the push method and are retrieved using the pop method. Additional methods allow to get the size of the stack and the value of the element at the top of the stack.
We will build a custom class that implements the common operations provided by a stack data structure.
Let’s start building it!
How to Start Building the Class For the Stack
The data structure we will use inside our class to create a Python stack is a list.
The class will restrict the type of operations that can be performed against the list considering that a stack doesn’t allow all the operations that are possible with a Python list.
When working with a list you have the freedom to add and remove elements at the beginning in the middle and at the end of the list. The same doesn’t apply to a stack.
When working with a stack you can only add an element to the top of the stack and remove the element from the top of the stack. That’s because by definition a stack is a Last-in First-Out data structure.
Let’s start by creating a class called Stack that has a list attribute called elements.
The constructor of the stack class initialises the attribute elements to an empty list.
class Stack:
def __init__(self):
self.elements = []The first two operations we want to support in our stack are push and pop:
- Push adds an element to the top of the stack.
- Pop removes the last element from the top of the stack.
Add two methods to our class to support the push and pop operations:
def push(self, data):
self.elements.append(data)To push data to the top of the stack we use the list append method.
def pop(self):
return self.elements.pop()To retrieve the last element from the top of the stack we use the list pop method.
Using the Push and Pop Operations on our Stack
Let’s test the class we have created so far.
class Stack:
def __init__(self):
self.elements = []
def push(self, data):
self.elements.append(data)
def pop(self):
return self.elements.pop()Create an instance of stack and use __dict__ to view the instance attributes.
stack = Stack()
print(stack.__dict__)
[output]
{'elements': []}As expected the only instance attribute is the empty list elements.
Then call the push method followed by the pop method.
stack.push(3)
stack.push('test')
print(stack.pop())
print(stack.pop())
[output]
test
3You can see that after calling the pop method twice we get back the two elements we have pushed to the top of the stack using the push operation.
Note: notice that the first element returned by pop() is the string “test” that is the second element we have pushed to the stack. That’s because of the LIFO nature of the stack.
Handling Errors When Using Pop on an Empty Stack
After calling the pop method twice in the previous section our stack is empty.
I wonder what happens if we call the pop operation again:
print(stack.pop())We get back the following exception:
Traceback (most recent call last):
File "/opt/Python/Tutorials/create_stack.py", line 17, in
print(stack.pop())
File "/opt/Python/Tutorials/create_stack.py", line 9, in pop
return self.elements.pop()
IndexError: pop from empty listThis exception doesn’t fully make sense…
The reference to pop in the error message is correct but a list is mentioned in the error because our class uses a list as instance attribute.
This could be confusing for a user that would be using our class as a way to work with a stack and not with a list.
Let’s handle this error better…
We will check if the internal list is empty before trying to “pop” an element from it:
def pop(self):
if self.elements:
return self.elements.pop()
else:
return NoneIf the list is empty the pop operation performed against the stack object will return None.
stack = Stack()
print(stack.pop())Confirm that the print statement above returns None.
Retrieve the Number of Elements in a Python Stack
At the moment we are not able to determine the number of elements in the stack.
Let’s add another method that returns the number of elements in the stack.
def size(self):
return len(self.elements)The new method simply returns the length of the internal list elements using the len() function. Let’s test it…
stack = Stack()
stack.push(3)
stack.push('test')
print("Number of elements in the stack: {}".format(stack.size()))
[output]
Number of elements in the stack: 2Looks good 🙂
I would also like to be able to know if the stack is empty. Here is a new method that does that:
def empty(self):
return True if self.size() == 0 else FalseThis is an example of how you can call a class method from another method within the same class.
Notice how the empty() method calls the size() method.
Let’s test the new method:
stack = Stack()
print(stack.empty())
stack.push(3)
print(stack.empty())
[output]
True
FalseWe are getting back the correct response from the empty() method.
Retrieve the Value of the Element at the Top of the Stack
Before completing this tutorial I would also like to implement a method that retrieves the value of the element at the top of the stack without removing it from the stack.
Considering that the internal attribute of the class is a list we can use an index to retrieve the last element.
The operation of retrieving the element at the top of the stack is called peek.
def peek(self):
return self.elements[-1]This method is super simple. We are using a negative index to get the last element in the elements list that is basically the element at the top of our stack.
stack = Stack()
stack.push('cat')
stack.push(3)
stack.push(1.2)
print(stack.peek())
[output]
1.2The method does exactly what we wanted to do.
Conclusion
In this tutorial we have seen how to implement a stack in Python step-by-step using a custom class.
We have implemented five operations for our custom stack:
- Push: to add an element to the top of the stack.
- Pop: to retrieve the element at the top of the stack.
- Size: to get the size of the stack.
- Empty: to check if the stack is empty.
- Peek: to get the value of the element at the top of the stack.
I hope you found it useful 🙂
Related posts:
![]()
I’m a Tech Lead, Software Engineer and Programming Coach. I want to help you in your journey to become a Super Developer!
Video: errors and exceptions.
Imperial students can also watch this video on Panopto.
It is a sight familiar to every programmer: instead of producing the
desired result, the screen is filled with seemingly unintelligible
garbage because an error has occurred. Producing errors is an
unavoidable part of programming, so learning to understand and correct
them is an essential part of learning to program.
6.1. What is an error?¶
In mathematics, we are used to the idea that an expression might not
be defined. For example, in the absence of further information,
(0/0) does not have a well-defined value. Similarly, the string
of symbols (3 times %) does not have a mathematical
meaning. It is likewise very easy to create statements or expressions
in a programming language which either don’t have a well-defined
meaning, or which just don’t amount to a meaningful statement within
the rules of the language. A mathematician confronting an undefined
mathematical expression can do little else than throw up their hands
and ask the author what they meant. The Python interpreter, upon
encountering code which has no defined meaning, responds similarly;
though rather than raising its non-existent hands, it raises an
exception. It is then up to the programmer to divine what to do next.
Let’s take a look at what Python does in response to a simple
error:
In [3]: 0./0. -------------------------------------------------------------------------- ZeroDivisionError Traceback (most recent call last) Cell In [3], line 1 ----> 1 0./0. ZeroDivisionError: float division by zero
An important rule in interpreting Python errors, the reasons for which we will
return to, is to always read the error message from the bottom up. In
this case, the last line contains the name of the exception which has
been raised, ZeroDivisionError, followed by a colon, followed by
a descriptive string providing more information about what has gone
wrong. In this case, that more or less says the same as the exception
name, but that won’t be the case for all exceptions. The four lines
above the exception are called a traceback. We’ll return to
interpreting tracebacks presently. In this case the error is easy to interpret
and understand: the code divided the float value 0. by another zero,
and this does not have a well-defined result in Python’s arithmetic system.
6.1.1. Syntax errors¶
Now consider the case of an expression that doesn’t make mathematical sense:
In [5]: 3 * % Cell In [5], line 1 3 * % ^ SyntaxError: invalid syntax
This creates a syntax error, signified by a SyntaxError exception. In
programming languages, as with human languages, the syntax is the set of rules
which defines which expressions are well-formed. Notice that the earlier lines
of a syntax error appear somewhat different to those of the previous exception.
Almost all exceptions occur because the Python interpreter attempts to
evaluate a statement or expression and encounters a problem. Syntax errors are
a special case: when a syntax error occurs, the interpreter can’t even get as
far as attempting to evaluate because the sequence of characters it has been
asked to execute do not make sense in Python. This time, the error message
shows the precise point in the line at which the Python interpreter found a
problem. This is indicated by the caret symbol (^). In this case, the reason
that the expression doesn’t make any sense is that the modulo operator (%) is
not a permissible second operand to multiplication (*), so the Python
interpreter places the caret under the modulo operator.
Even though the Python interpreter will highlight the point at which
the syntax doesn’t make sense, this might not quite actually be the
point at which you made the mistake. In particular, failing to finish
a line of code will often result in the interpreter assuming that the
expression continues on the next line of program text, resulting in
the syntax error appearing to be one line later than it really
occurs. Consider the following code:
The error here is a missing closing bracket on the first line, however
the error message which the Python interpreter prints when this code is run is:
File "syntax_error.py", line 2 print(a) ^ SyntaxError: invalid syntax
To understand why Python reports the error on the line following the
actual problem, we need to understand that the missing closing bracket
was not by itself an error. The user could, after all, validly
continue the tuple constructor on the next line. For example,
the following code would be completely valid:
This means that the Python interpreter can only know that something is
wrong when it sees print, because print cannot follow 2 in a
tuple constructor. The interpreter, therefore, reports that the print
is a syntax error.
Hint
If the Python interpreter reports a syntax error at the start of a
line, always check to see if the actual error is on the previous
line.
6.2. Exceptions¶
Aside from syntax errors, which are handled directly by the
interpreter, errors occur when Python code is executed and something
goes wrong. In these cases the Python code in which the problem is
encountered must signal this to the interpreter. It does this using a
special kind of object called an exception. When an exception
occurs, the interpreter stops executing the usual sequence of Python
commands. Unless the programmer has taken special measures, to which
we will return in Section 6.5, the execution will
cease and an error message will result.
Because there are many things that can go wrong, Python has many types
of exception built in. For example, if we attempt to access the number
2 position in a tuple with only two entries, then an
IndexError exception occurs:
In [1]: (0, 1)[2] -------------------------------------------------------------------------- IndexError Traceback (most recent call last) Cell In [1], line 1 ----> 1 (0, 1)[2] IndexError: tuple index out of range
The exception type provides some indication as
to what has gone wrong, and there is usually also an error message and
sometimes more data to help diagnose the problem. The full list
of built-in exceptions is available in the
Python documentation. Python developers can define their own
exceptions so there are many more defined in third-party packages. We will
turn to the subject of defining new exception classes in
Section 7.4.
6.3. Tracebacks: finding errors¶
Video: tracebacks.
Imperial students can also watch this video on Panopto.
The errors we have looked at so far have all been located in the top
level of code either typed directly into iPython or executed in a
script. However, what happens if an error occurs in a function call or
even several functions down? Consider the following code, which uses
the Polynomial class from
Chapter 3:
In [1]: from example_code.polynomial import Polynomial In [2]: p = Polynomial(("a", "b")) In [3]: print(p) bx + a
Perhaps surprisingly, it turns out that we are able to define a polynomial
whose coefficients are letters, and we can even print the resulting object.
However, if we attempt to add this polynomial to the number 1, we are in
trouble:
In [4]: print(1 + p) -------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In [4], line 1 ----> 1 print(1 + p) File ~/docs/principles_of_programming/object-oriented-programming/example_code/polynomial.py:59, in Polynomial.__radd__(self, other) 58 def __radd__(self, other): ---> 59 return self + other File ~/docs/principles_of_programming/object-oriented-programming/example_code/polynomial.py:38, in Polynomial.__add__(self, other) 36 def __add__(self, other): 37 if isinstance(other, Number): ---> 38 return Polynomial((self.coefficients[0] + other,) 39 + self.coefficients[1:]) 41 elif isinstance(other, Polynomial): 42 # Work out how many coefficient places the two polynomials have in 43 # common. 44 common = min(self.degree(), other.degree()) + 1 TypeError: can only concatenate str (not "int") to str
This is a much larger error message than those we have previously
encountered, however, the same principles apply. We start by reading
the last line. This tells us that the error was a TypeError
caused by attempting to concatenate (add) an integer to a
string. Where did this error occur? This is a more involved question
than it may first appear, and the rest of the error message above is
designed to help us answer this question. This type of error message
is called a traceback, as the second line of the error message
suggests. In order to understand this message, we need to understand a
little about how a Python program is executed, and in particular about
the call stack.
6.3.1. The call stack¶
Video: the call stack.
Imperial students can also watch this video on Panopto.
A Python program is a sequence of Python statements, which are
executed in a sequence determined by the flow control logic of the
program itself. Each statement contains zero or more function calls 1,
which are executed in the course of evaluating that statement.
One of the most basic features of a function call is that the contents
of the function execute, and then the code which called the function
continues on from the point of the function call, using the return
value of the function in place of the call. Let’s think about what
happens when this occurs. Before calling the function, there is a
large amount of information which describes the context of the current
program execution. For example, there are all of the module, function,
and variable names which are in scope, and there is the record of
which instruction is next to be executed. This collection of
information about the current execution context is called a
stack frame. We learned about stacks in
Section 5.1, and the term “stack frame” is not a coincidence. The
Python interpreter maintains a stack of stack frames called
the call stack. It is also sometimes called the
execution stack or interpreter stack.
The first frame on the stack contains the execution context for the
Python script that the user ran or, in the case where the user worked
interactively, for the iPython shell or Jupyter notebook into which
the user was typing. When a function is called, the Python interpreter
creates a new stack frame containing the local execution context of
that function and pushes it onto the call stack. When that function
returns, its stack frame is popped from the call stack, leaving the
interpreter to continue at the next instruction in the stack frame
from which the function was called. Because functions can call
functions which call functions and so on in a nearly limitless
sequence, there can be a number of stack frames in existence at any
time.
6.3.2. Interpreting tracebacks¶
Let’s return to the traceback for our erroneous polynomial addition:
In [4]: print(1 + p) -------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In [4], line 1 ----> 1 print(1 + p) File ~/docs/principles_of_programming/object-oriented-programming/example_code/polynomial.py:59, in Polynomial.__radd__(self, other) 58 def __radd__(self, other): ---> 59 return self + other File ~/docs/principles_of_programming/object-oriented-programming/example_code/polynomial.py:38, in Polynomial.__add__(self, other) 36 def __add__(self, other): 37 if isinstance(other, Number): ---> 38 return Polynomial((self.coefficients[0] + other,) 39 + self.coefficients[1:]) 41 elif isinstance(other, Polynomial): 42 # Work out how many coefficient places the two polynomials have in 43 # common. 44 common = min(self.degree(), other.degree()) + 1 TypeError: can only concatenate str (not "int") to str
This shows information about a call stack comprising three
stack frames. Look first at the bottom-most
frame, which corresponds to the function in which the exception
occurred. The traceback for this frame starts:
File ~/docs/principles_of_programming/object-oriented-programming/example_code/polynomial.py:38, in Polynomial.__add__(self, other)
This indicates that the frame describes code in the file polynomial.py
(which, on the author’s computer, is located in the folder
~/principles_of_programming/object-oriented-programming/example_code/).
Specifically, the stack frame describes the execution of the __add__()
method, which is the special method responsible for polynomial
addition. The lines below this show the line on which execution stopped (line
38, in this case) and a couple of lines on either side, for context.
The stack frame above this shows the function from which the __add__()
method was called. In this case, this is the reverse addition special
method, __radd__(). On line 59 __radd__() calls __add__()
through the addition of self and other.
Finally, the top stack frame corresponds to the command that the user typed in
iPython. This stack frame looks a little different from the others. Instead of
a file name there and a function name there is Cell In [4], line 1. This
indicates that the exception was raised on line 1 of the IPython cell In [4].
Hint
Older versions of Python display less helpful location information for the
top stack frame, so in that case you might see something like
<ipython-input-2-c3aeb16193d4> in rather than
Cell In [4], line 1.
Hint
The proximate cause of the error will be in the last stack
frame printed, so always read the traceback from the
bottom up. However, the ultimate cause of the problem may
be further up the call stack, so don’t stop reading at the
bottom frame!
6.4. Raising exceptions¶
Video: raising an exception.
Imperial students can also watch this video on Panopto.
Thus far we’ve noticed that an exception occurs when something goes
wrong in a program, and that the Python interpreter will stop
at that point and print out a traceback. We’ll now examine the
process by which an exception occurs.
An exception is triggered using the raise keyword. For
example, suppose we want to ensure that the input to our Fibonacci
function is an integer. All Python integers are instances of numbers.Integral, so we can check this. If we
find a non-integer type then the consequence should be a
TypeError. This is achieved by raising the appropriate
exception, using the raise statement. The keyword
raise is followed by the exception. Almost all exceptions
take a string argument, which is the error message to be printed. In
Listing 6.1, we inform the user that we were expecting an
integer rather than the type actually provided.
Listing 6.1 A version of the Fibonacci function which raises an
exception if a non-integer type is passed as the
argument.¶
1from numbers import Integral 2 3 4def typesafe_fib(n): 5 """Return the n-th Fibonacci number, raising an exception if a 6 non-integer is passed as n.""" 7 if not isinstance(n, Integral): 8 raise TypeError( 9 f"fib expects an integer, not a {type(n).__name__}" 10 ) 11 if n == 0: 12 return 0 13 elif n == 1: 14 return 1 15 else: 16 return fib(n-2) + fib(n-1)
If we now pass a non-integer value to this function, we observe the following:
In [1]: from fibonacci.typesafe_fibonacci import typesafe_fib In [2]: typesafe_fib(1.5) -------------------------------------------------------------------------- TypeError Traceback (most recent call last) Cell In [2], line 1 ----> 1 typesafe_fib(1.5) File ~/docs/principles_of_programming/object-oriented-programming/fibonacci/typesafe_fibonacci.py:8, in typesafe_fib(n) 5 """Return the n-th Fibonacci number, raising an exception if a 6 non-integer is passed as n.""" 7 if not isinstance(n, Integral): ----> 8 raise TypeError( 9 f"fib expects an integer, not a {type(n).__name__}" 10 ) 11 if n == 0: 12 return 0 TypeError: fib expects an integer, not a float
This is exactly what we have come to expect: execution has stopped and
we see a traceback. Notice that the final line is the error
message that we passed to TypeError. The only difference
between this and the previous errors we have seen is that the bottom
stack frame explicitly shows the exception being raised, while
previously the stack showed a piece of code where an error had
occurred. This minor difference has to do with whether the particular
piece of code where the exception occurred is written in Python, or is
written in a language such as C and called from Python. This
distinction is of negligible importance for our current purposes.
Note
An exceptionally common mistake that programmers make when first
trying to work with exceptions is to write:
instead of:
This mistake is the result of a confusion about what
return and raise do. return means
“the function is finished, here is the result”. raise
means “something exceptional happened, execution is stopping
without a result”.
6.5. Handling exceptions¶
Video: handling exceptions.
Imperial students can also watch this video on Panopto.
So far we have seen several different sorts of exception, how to raise them,
and how to understand the resulting traceback. The traceback is
very helpful if the exception was caused by a bug in our code, as it is a rich
source of the information needed to understand and correct the error. However,
sometimes an exception is a valid result of a valid input, and we just need the
program to do something out of the ordinary to deal with the situation. For
example, Euclid’s algorithm for finding the greatest common divisor of
(a) and (b) can very nearly be written recursively as:
def gcd(a, b): return gcd(b, a % b)
This works right up to the point where b becomes zero, at which
point we should stop the recursion and return a. What actually
happens if we run this code? Let’s try:
In [2]: gcd(10, 12) -------------------------------------------------------------------------- ZeroDivisionError Traceback (most recent call last) Cell In[2], line 1 ----> 1 gcd(10, 12) Cell In[1], line 2, in gcd(a, b) 1 def gcd(a, b): ----> 2 return gcd(b, a % b) Cell In[1], line 2, in gcd(a, b) 1 def gcd(a, b): ----> 2 return gcd(b, a % b) [... skipping similar frames: gcd at line 2 (1 times)] Cell In[1], line 2, in gcd(a, b) 1 def gcd(a, b): ----> 2 return gcd(b, a % b) ZeroDivisionError: integer modulo by zero
Notice how the recursive call to gcd() causes several
stack frames that look the same. Indeed, the Python
interpreter even notices the similarity and skips over one. That makes
sense: gcd() calls itself until b is zero, and then we get a
ZeroDivisionError because modulo zero is undefined. To
complete this function, what we need to do is to tell Python to stop
at the ZeroDivisionError and return a
instead. Listing 6.2 illustrates how this can be achieved.
Listing 6.2 A recursive implementation of Euclid’s algorithm which
catches the ZeroDivisionError to implement the
base case.¶
1def gcd(a, b): 2 try: 3 return gcd(b, a % b) 4 except ZeroDivisionError: 5 return a
The new structure here is the try… except
block. The try keyword defines a block of code, in this
case just containing return gcd(b, a % b). The except is
optionally followed by an exception class, or a tuple of exception
classes. This case, the except is only followed by the
ZeroDivisionError class. What this means is that if a
ZeroDivisionError is raised by any of the code inside the
try block then, instead of execution halting and a
traceback being printed, the code inside the except
block is run.
In the example here, this means that once b is zero, instead of
gcd being called a further time, a is returned. If we run this
version of gcd() then we have, as we might expect:
In [2]: gcd(10, 12) Out[2]: 2
6.5.1. Except clauses¶
Video: further exception handling.
Imperial students can also watch this video on Panopto.
Let’s look in a little more detail at how except works. The full
version of the except statement takes a tuple of exception classes. If an
exception is raised matching any of the exceptions in that tuple then the code
in the except block is executed.
It’s also possible to have more than one except block following a
single try statement. In this case, the first except block for which
the exception matches the list of exceptions is executed. For example:
In [1]: try: ...: 0./0 ...: except TypeError, KeyError: ...: print("Type or key error") ...: except ZeroDivisionError: ...: print("Zero division error") ...: Zero division error
Note
It is also possible to omit the list of exceptions after except.
In this case, the except block will match any exception which is raised in
the corresponding try block. Using unconstrained except blocks like this is
a somewhat dangerous strategy. Usually, the except block will be designed
to deal with a particular type of exceptional circumstance. However, an
except block that catches any exception may well be triggered by a completely
different exception, in which case it will just make the error more
confusing by obscuring where the issue actually occurred.
6.5.2. Else and finally¶
It can also be useful to execute some code only if an exception is not raised.
This can be achieved using an else clause. An else clause after a try block is caused only if no exception was
raised.
It is also sometimes useful to be able to execute some code no matter what
happened in the try block. If there is a finally clause
then the code it contains will be executed if either an exception is raised and
handled by an except block, or no exception occurred. This
plethora of variants on the try block can get a little confusing, so
a practical example may help. Listing 6.3 prints out a different
message for each type of clause.
Listing 6.3 A demonstration of all the clauses of the try block.¶
1def except_demo(n): 2 """Demonstrate all the clauses of a `try` block.""" 3 4 print(f"Attempting division by {n}") 5 try: 6 print(0./n) 7 except ZeroDivisionError: 8 print("Zero division") 9 except TypeError: 10 print(f"Can't divide by a {type(n).__name__}.") 11 else: 12 print("Division successful.") 13 finally: 14 print("Finishing up.")
If we execute except_demo() for a variety of
arguments, we can observe this complete try block in action. First,
we provide an input which is a valid divisor:
In [1]: from example_code.try_except import except_demo In [2]: except_demo(1) Attempting division by 1 0.0 Division successful. Finishing up.
Here we can see the output of the division, the else block, and
the finally block. Next we divide by zero:
In [3]: except_demo(0) Attempting division by 0 Zero division Finishing up.
This caused a ZeroDivisionError, which was caught by the first
except clause. Since an exception was raised, the the else block is not executed, but the finally block still executes.
Similarly, if we attempt to divide by a string, we are caught by the second
except clause:
In [4]: except_demo("frog") Attempting division by frog Can't divide by a str. Finishing up.
6.5.3. Exception handling and the call stack¶
An except block will handle any matching exception raised in the
preceding try block. The try block can, of
course, contain any code at all. In particular it might contain
function calls which themselves may well call further functions. This
means that an exception might occur several stack frames down the call stack from the try
clause. Indeed, some of the functions called might themselves contain
try blocks with the result that an exception is raised at a
point which is ultimately inside several try blocks.
The Python interpreter deals with this situation by starting from the
current stack frame and working upwards, a process known as unwinding
the stack. Listing 6.4 shows pseudocode for this process.
Listing 6.4 Pseudocode for the process of unwinding the stack, in which the
interpreter successively looks through higher stack frames to search
for an except clause matching the exception that has just
been raised.¶
while call stack not empty: if current execution point is in a try block with an except matching the current exception: execution continues in the except block else: pop the current stack frame off the call stack # Call stack is now empty print traceback and exit
6.6. Exceptions are not always errors¶
This chapter is called “Errors and exceptions”, so it is appropriate
to finish by drawing attention to the distinction between these two
concepts. While user errors and bugs in programs typically result in
an exception being raised, it is not the case that all exceptions
result from errors. The name “exception” means what it says, it is an
event whose occurrence requires an exception to the normal sequence of
execution.
The StopIteration exception which we encountered in
Section 5.6 is a good example of an exception
which does not indicate an error. The end of the set of things to be
iterated over does not indicate that something has gone wrong, but it
is an exception to the usual behaviour of __next__(),
which Python needs to handle in a different way from simply returning
the next item.
6.7. Glossary¶
- call stack¶
- execution stack¶
- interpreter stack¶
The stack of stack frames in existence. The
current item on the stack is the currently executing function,
while the deepest item is the stack frame corresponding to the
user script or interpreter.- exception¶
An object representing an out of the ordinary event which has
occurred during the execution of some Python code. When an
exception is raised the
Python interpreter doesn’t continue to execute the
following line of code. Instead, the exception is either
handled or execution stops and a
traceback is printed.- stack frame¶
An object encapsulating the set of variables which define the
execution of a Python script or function. This information
includes the code being executed, all the local and global
names which are visible, the last instruction that was
executed, and a reference to the stack frame which called this
function.- syntax¶
The set of rules which define what is a well-formed Python
statement. For example the rule that statements which start
blocks must end with a colon (:) is a syntax rule.- syntax error¶
The exception which occurs when a statement violates
the syntax rules of Python. Mismatched brackets,
missing commas, and incorrect indentation are all examples of
syntax errors.- traceback¶
- stack trace¶
- back trace¶
A text representation of the call stack. A traceback
shows a few lines of code around the current execution point
in each stack frame, with the current frame at the
bottom and the outermost frame at the top.
6.8. Exercises¶
Using the information on the book website
obtain the skeleton code for these exercises.
Exercise 6.1
The Newton-Raphson method is an iterative method for approximately solving
equations of the form (f(x)=0). Starting from an initial guess, a
series of (hopefully convergent) approximations to the solution is computed:
[x_{n+1} = x_n — frac{f(x_n)}{f'(x_n)}]
The iteration concludes successfully if (|f(x_{n+1})| < epsilon) for some
user-specified tolerance (epsilon>0). The sequence is not guaranteed
to converge for all combinations of function and starting point, so the
iteration should fail if (n) exceeds a user-specified number of
iterations.
The skeleton code for this chapter contains a function
nonlinear_solvers.solvers.newton_raphson() which takes as arguments a
function, its derivative and a starting point for the iteration. It can also
optionally be passed a value for (epsilon) and a maximum number of
iterations to execute. Implement this function. If the iteration succeeds
then the last iterate, (x_{n+1}), should be returned.
nonlinear_solvers.solvers also defines an exception,
ConvergenceError. If the Newton-Raphson iteration exceeds the
number of iterations allowed then this exception should be raised, with an
appropriate error message.
Exercise 6.2
The bisection method is a slower but more robust iterative solver. It requires a
function (f) and two starting points (x_0) and (x_1) such
that (f(x_0)) and (f(x_1)) differ in sign. At each stage of the
iteration, the function is evaluated at the midpoint of the current points
(x^* = (x_0 + x_1)/2). If (|,f(x^*)|<epsilon) then the iteration
terminates successfully. Otherwise, (x^*) replaces (x_0) if
(f(x_0)) and (f(x^*)) have the same sign, and replaces
(x_1) otherwise.
Implement nonlinear_solvers.solvers.bisection(). As before, if the
iteration succeeds then return the last value of (x). If the maximum
number of iterations is exceeded, raise ConvergenceError with a
suitable error message. The bisection method has a further failure mode. If
(f(x_0)) and (f(x_1)) do not differ in sign then your code
should raise ValueError with a suitable message.
Exercise 6.3
Implement the function nonlinear_solvers.solvers.solve(). This code
should first attempt to solve (f(x)=0) using your Newton-Raphson
function. If that fails it should catch the exception and instead try using
your bisection function.
Footnotes
- 1
-
“Function call” here includes method calls and
operations implemented using a special method. - 2
-
https://object-oriented-python.github.io/edition2/exercises.html
A stack is a linear data structure that stores items in a Last-In/First-Out (LIFO) or First-In/Last-Out (FILO) manner. In stack, a new element is added at one end and an element is removed from that end only. The insert and delete operations are often called push and pop.
The functions associated with stack are:
- empty() – Returns whether the stack is empty – Time Complexity: O(1)
- size() – Returns the size of the stack – Time Complexity: O(1)
- top() / peek() – Returns a reference to the topmost element of the stack – Time Complexity: O(1)
- push(a) – Inserts the element ‘a’ at the top of the stack – Time Complexity: O(1)
- pop() – Deletes the topmost element of the stack – Time Complexity: O(1)
Implementation:
There are various ways from which a stack can be implemented in Python. This article covers the implementation of a stack using data structures and modules from the Python library.
Stack in Python can be implemented using the following ways:
- list
- Collections.deque
- queue.LifoQueue
Implementation using list:
Python’s built-in data structure list can be used as a stack. Instead of push(), append() is used to add elements to the top of the stack while pop() removes the element in LIFO order.
Unfortunately, the list has a few shortcomings. The biggest issue is that it can run into speed issues as it grows. The items in the list are stored next to each other in memory, if the stack grows bigger than the block of memory that currently holds it, then Python needs to do some memory allocations. This can lead to some append() calls taking much longer than other ones.
Python3
stack = []
stack.append('a')
stack.append('b')
stack.append('c')
print('Initial stack')
print(stack)
print('nElements popped from stack:')
print(stack.pop())
print(stack.pop())
print(stack.pop())
print('nStack after elements are popped:')
print(stack)
Output
Initial stack ['a', 'b', 'c'] Elements popped from stack: c b a Stack after elements are popped: []
Implementation using collections.deque:
Python stack can be implemented using the deque class from the collections module. Deque is preferred over the list in the cases where we need quicker append and pop operations from both the ends of the container, as deque provides an O(1) time complexity for append and pop operations as compared to list which provides O(n) time complexity.
The same methods on deque as seen in the list are used, append() and pop().
Python3
from collections import deque
stack = deque()
stack.append('a')
stack.append('b')
stack.append('c')
print('Initial stack:')
print(stack)
print('nElements popped from stack:')
print(stack.pop())
print(stack.pop())
print(stack.pop())
print('nStack after elements are popped:')
print(stack)
Output
Initial stack: deque(['a', 'b', 'c']) Elements popped from stack: c b a Stack after elements are popped: deque([])
Implementation using queue module
Queue module also has a LIFO Queue, which is basically a Stack. Data is inserted into Queue using the put() function and get() takes data out from the Queue.
There are various functions available in this module:
- maxsize – Number of items allowed in the queue.
- empty() – Return True if the queue is empty, False otherwise.
- full() – Return True if there are maxsize items in the queue. If the queue was initialized with maxsize=0 (the default), then full() never returns True.
- get() – Remove and return an item from the queue. If the queue is empty, wait until an item is available.
- get_nowait() – Return an item if one is immediately available, else raise QueueEmpty.
- put(item) – Put an item into the queue. If the queue is full, wait until a free slot is available before adding the item.
- put_nowait(item) – Put an item into the queue without blocking. If no free slot is immediately available, raise QueueFull.
- qsize() – Return the number of items in the queue.
Python3
from queue import LifoQueue
stack = LifoQueue(maxsize=3)
print(stack.qsize())
stack.put('a')
stack.put('b')
stack.put('c')
print("Full: ", stack.full())
print("Size: ", stack.qsize())
print('nElements popped from the stack')
print(stack.get())
print(stack.get())
print(stack.get())
print("nEmpty: ", stack.empty())
Output
0 Full: True Size: 3 Elements popped from the stack c b a Empty: True
Implementation using a singly linked list:
The linked list has two methods addHead(item) and removeHead() that run in constant time. These two methods are suitable to implement a stack.
- getSize()– Get the number of items in the stack.
- isEmpty() – Return True if the stack is empty, False otherwise.
- peek() – Return the top item in the stack. If the stack is empty, raise an exception.
- push(value) – Push a value into the head of the stack.
- pop() – Remove and return a value in the head of the stack. If the stack is empty, raise an exception.
Below is the implementation of the above approach:
Python3
class Node:
def __init__(self, value):
self.value = value
self.next = None
class Stack:
def __init__(self):
self.head = Node("head")
self.size = 0
def __str__(self):
cur = self.head.next
out = ""
while cur:
out += str(cur.value) + "->"
cur = cur.next
return out[:-3]
def getSize(self):
return self.size
def isEmpty(self):
return self.size == 0
def peek(self):
if self.isEmpty():
raise Exception("Peeking from an empty stack")
return self.head.next.value
def push(self, value):
node = Node(value)
node.next = self.head.next
self.head.next = node
self.size += 1
def pop(self):
if self.isEmpty():
raise Exception("Popping from an empty stack")
remove = self.head.next
self.head.next = self.head.next.next
self.size -= 1
return remove.value
if __name__ == "__main__":
stack = Stack()
for i in range(1, 11):
stack.push(i)
print(f"Stack: {stack}")
for _ in range(1, 6):
remove = stack.pop()
print(f"Pop: {remove}")
print(f"Stack: {stack}")
Output
Stack: 10->9->8->7->6->5->4->3->2-> Pop: 10 Pop: 9 Pop: 8 Pop: 7 Pop: 6 Stack: 5->4->3->2->
Advantages of Stack:
- Stacks are simple data structures with a well-defined set of operations, which makes them easy to understand and use.
- Stacks are efficient for adding and removing elements, as these operations have a time complexity of O(1).
- In order to reverse the order of elements we use the stack data structure.
- Stacks can be used to implement undo/redo functions in applications.
Drawbacks of Stack:
- Restriction of size in Stack is a drawback and if they are full, you cannot add any more elements to the stack.
- Stacks do not provide fast access to elements other than the top element.
- Stacks do not support efficient searching, as you have to pop elements one by one until you find the element you are looking for.