Like all of us, you are another victim of asynchronous I/O. With asynchronous calls, if you loop around a lot of files, Node.js will start to open a file descriptor for each file to read and then will wait for action until you close it.
File descriptor remains open until resource is available on your server to read it. Even if your files are small and reading or updating is fast, it takes some time, but in the same time your loop don’t stop to open new files descriptor. So if you have too many files, the limit will be soon reached and you get a beautiful EMFILE.
There is one solution, creating a queue to avoid this effect.
Thanks to people who wrote Async, there is a very useful function for that. There is a method called Async.queue, you create a new queue with a limit and then add filenames to the queue.
Note: If you have to open many files, it would be a good idea to store which files are currently open and don’t reopen them infinitely.
const fs = require('fs')
const async = require("async")
var q = async.queue(function(task, callback) {
console.log(task.filename);
fs.readFile(task.filename,"utf-8",function (err, data_read) {
callback(err,task.filename,data_read);
}
);
}, 4);
var files = [1,2,3,4,5,6,7,8,9,10]
for (var file in files) {
q.push({filename:file+".txt"}, function (err,filename,res) {
console.log(filename + " read");
});
}
You can see that each file is added to the queue (console.log filename), but only when the current queue is under the limit you set previously.
async.queue get information about availability of the queue through a callback, this callback is called only when data file is read and any action you have to do is achieved. (see fileRead method)
So you cannot be overwhelmed by files descriptor.
> node ./queue.js
0.txt
1.txt
2.txt
0.txt read
3.txt
3.txt read
4.txt
2.txt read
5.txt
4.txt read
6.txt
5.txt read
7.txt
1.txt read (biggest file than other)
8.txt
6.txt read
9.txt
7.txt read
8.txt read
9.txt read
Like all of us, you are another victim of asynchronous I/O. With asynchronous calls, if you loop around a lot of files, Node.js will start to open a file descriptor for each file to read and then will wait for action until you close it.
File descriptor remains open until resource is available on your server to read it. Even if your files are small and reading or updating is fast, it takes some time, but in the same time your loop don’t stop to open new files descriptor. So if you have too many files, the limit will be soon reached and you get a beautiful EMFILE.
There is one solution, creating a queue to avoid this effect.
Thanks to people who wrote Async, there is a very useful function for that. There is a method called Async.queue, you create a new queue with a limit and then add filenames to the queue.
Note: If you have to open many files, it would be a good idea to store which files are currently open and don’t reopen them infinitely.
const fs = require('fs')
const async = require("async")
var q = async.queue(function(task, callback) {
console.log(task.filename);
fs.readFile(task.filename,"utf-8",function (err, data_read) {
callback(err,task.filename,data_read);
}
);
}, 4);
var files = [1,2,3,4,5,6,7,8,9,10]
for (var file in files) {
q.push({filename:file+".txt"}, function (err,filename,res) {
console.log(filename + " read");
});
}
You can see that each file is added to the queue (console.log filename), but only when the current queue is under the limit you set previously.
async.queue get information about availability of the queue through a callback, this callback is called only when data file is read and any action you have to do is achieved. (see fileRead method)
So you cannot be overwhelmed by files descriptor.
> node ./queue.js
0.txt
1.txt
2.txt
0.txt read
3.txt
3.txt read
4.txt
2.txt read
5.txt
4.txt read
6.txt
5.txt read
7.txt
1.txt read (biggest file than other)
8.txt
6.txt read
9.txt
7.txt read
8.txt read
9.txt read
@kevlened i have same issues,i already monkey-patch fs,below is my code:
var fs = require('fs');
var gracefulFs = require('graceful-fs');
gracefulFs.gracefulify(fs);
const webpackMerge = require('webpack-merge');
const ExtractTextPlugin = require('extract-text-webpack-plugin');
const CopyWebpackPlugin = require('copy-webpack-plugin');
const commonConfig = require('./webpack.common.js');
const helpers = require('./helpers');
module.exports = webpackMerge(commonConfig, {
......
plugins: [
new CopyWebpackPlugin([
{ from: helpers.root('node_modules/ckeditor/ckeditor.js'), to: 'node_modules/ckeditor' },
{ from: helpers.root('node_modules/ckeditor/config.js'), to: 'node_modules/ckeditor' },
{ from: helpers.root('node_modules/ckeditor/styles.js'), to: 'node_modules/ckeditor' },
{ from: helpers.root('node_modules/ckeditor/contents.css'), to: 'node_modules/ckeditor' },
{ from: helpers.root('node_modules/ckeditor/skins/moono'), to: 'node_modules/ckeditor/skins/moono' },
{ from: helpers.root('node_modules/ckeditor/lang/zh-cn.js'), to: 'node_modules/ckeditor/lang' },
{ from: helpers.root('node_modules/ckeditor/plugins'), to: 'node_modules/ckeditor/plugins' },
{ from: helpers.root('node_modules/ckeditor/adapters'), to: 'node_modules/ckeditor/adapters' },
])
]
}
error msg:
95% emittingfs.js:634
return binding.open(pathModule._makeLong(path), stringToFlags(flags), mode);
^
Error: EMFILE: too many open files, open 'D:worknodejsangularangular2-electronnode_modulesckeditorpluginssourcedialoglangar.js'
at Error (native)
at Object.fs.openSync (fs.js:634:18)
at Object.fs.readFileSync (fs.js:502:33)
at Object.source (D:worknodejsangularangular2-electronnode_modules.npminstallcopy-webpack-plugin3.0.1copy-webpack-plugindistwriteFileToAssets.js:45:31)
at Compiler.writeOut (D:worknodejsangularangular2-electronnode_modules.npminstallwebpack2.1.0-beta.15webpacklibCompiler.js:290:26)
at D:worknodejsangularangular2-electronnode_modules.npminstallmkdirp.5.1mkdirpindex.js:48:26
at FSReqWrap.oncomplete (fs.js:117:15)
Добрый день.
Складывать в отдельный лог-файл сообщения об ошибках 404 — настолько обычное дело, что, казалось бы, и сложностей с этим быть не может. По крайней мере, так думал я, пока за одну секунду клиент не запросил полторы тысячи отсутствующих файлов.
Node.js-сервер выругался «EMFILE, too many open files» и отключился.
(В дебаг-режиме я специально не отлавливаю ошибки, попавшие в основной цикл)
Итак, что представляла собой ф-ия сохранения в файл:
log: function (filename, text) {
// запись в конец файла filename строки now() + text
var s = utils.digitime() + ' ' + text + 'n';
// utils.digitime() - возвращает текущую дату-время в виде строки в формате ДД.ММ.ГГГГ чч:мм:сс
fs.open(LOG_PATH + filename, "a", 0x1a4, function (error, file_handle) {
if (!error) {
fs.write(file_handle, s, null, 'utf8', function (err) {
if (err) {
console.log(ERR_UTILS_FILE_WRITE + filename + ' ' + err);
}
fs.close(file_handle, function () {
callback();
});
});
}
else {
console.log(ERR_UTILS_FILE_OPEN + filename + ' ' + error);
callback();
}
});
}Ну то есть всё прямо «в лоб» — открываем, записываем, если какие ошибки — выводим на консоль. Однако, как говорилось выше, если вызывать её слишком часто, файлы просто не успевают закрываться. В линуксе, например, упираемся в значение kern.maxfiles со всеми неприятными вытекающими.
Самое интересное
Для решения я выбрал библиотеку async, без которой уже не представляю жизни.
Саму функцию log перенёс в «private» область видимости модуля, переименовав в __log и слегка модифицировав: теперь у неё появился коллбек:
__log = function (filename, text) {
return function (callback) {
var s = utils.digitime() + ' ' + text + 'n';
fs.open(LOG_PATH + filename, "a", 0x1a4, function (error, file_handle) {
if (!error) {
fs.write(file_handle, s, null, 'utf8', function (err) {
if (err) {
console.log(ERR_UTILS_FILE_WRITE + filename + ' ' + err);
}
fs.close(file_handle, function () {
callback();
});
});
}
else {
console.log(ERR_UTILS_FILE_OPEN + filename + ' ' + error);
callback();
}
});
};
};
Самое главное: в private создаём переменную __writeQueue:
__writeQueue = async.queue(function (task, callback) {
task(callback);
}, MAX_OPEN_FILES);
а в public-части модуля log выглядит теперь совсем просто:
log: function (filename, text) {
__writeQueue.push(__log(filename, text));
},
И всё?!
Именно. Другие модули по-прежнему вызывают эту ф-ию примерно как
function errorNotFound (req, res) {
utils.log(LOG_404, '' + req.method + 't' + req.url + 't(' + (accepts) + ')t requested from ' + utils.getClientAddress(req));
..
и при этом никаких ошибок.
Механизм прост: задаём константе MAX_OPEN_FILES разумное число, меньшее чем максимально допустимое количество открытых файловых дескрипторов (например 256). Далее все попытки записи будут распараллеливаться, но только до тех пор, пока их количество не достигнет указанного предела. Все свежеприбывающие будут становиться в очередь и запускаться только после завершения предыдущих попыток (помните, мы добавляли callback? Как раз для этого!).
Надеюсь, данная статья поможет решить эту проблему тем, кто с ней столкнулся. Либо — что ещё лучше — послужит превентивной мерой.
Удачи.
03 Jun 2021
tl;dr: Move initialization logic outside of request handlers.
My team is building a new application, and I used CloudWatch alarms to
understand what latency promises we could make without triggering the alarms too often. I set these alarms to fire when 3/3 datapoints breach the alarm’s threshold, and
noticed an interesting pattern from multiple triggered alarms: A sharp increase in latency (hundreds of ms to multiple seconds), followed by a function timeout (30 seconds), again followed by a cold start.
Our application consists of a couple AWS Lambda functions and other serverless infrastructure, with a NodeJS 12 environment. One monolithic function backs an API Gateway endpoint.
The Lambda function uses aws-serverless-koa for routing requests to the right handler, and the AWS SDK for JavaScript to call other AWS services like DynamoDB.
Prerequisites
This article assumes that you’ve already built a NodeJS application on AWS Lambda, and have some experience with the AWS CloudWatch service.
How To Analyse The Logs
As the latency spike and timeouts happened somewhat regularly, I checked the logs of the function in question.
With CloudWatch Logs Insights we can pick a timeframe, a
function’s log group, and a query that
we modify as we narrow down to the problem.
I used the query below to find the latest 50 errors that caused the Lambda function to fail.
fields @timestamp, @message
| filter @message like /ERROR/
| sort by @timestamp desc
| limit 50
In the resulting logs I saw an error with the message EMFILE: too many files open. To understand what happened leading up to this error, I filtered for
the @requestId to let CloudWatch show me all logs for that particular request. You can find the value field in the @message field from the previous query.
fields @timestamp, @message
| filter @requestId == "my-request-id"
| sort by @timestamp desc
Unfortunately this didn’t yield any new insights, so I defaulted to googling around a bit. I stumbled upon a few articles that explain how one can show the
open file descriptors on a unix server. With Lambda that’s not possible though, as you can’t SSH into your Lambda instance.
However one of the articles mentioned in its footnotes
that Lambda Insights supported file descriptor metrics since late 2020.
I also saw mentions of the environment variable AWS_NODEJS_CONNECTION_REUSE_ENABLED, but I didn’t feel like I had enough data to support this change apart from “let’s see if it works or breaks”.
How To Get Lambda System Metrics
Lambda Insights uses Lambda Extensions to
gather system metrics such as CPU and RAM usage from our Lambda functions. If you want to try out Lambda Insights yourself, go
checkout this section in the AWS Observability Workshop.
Lambda Insights collects a bunch of metrics and one of them is the file descriptor usage fd_use.
These metrics are not automatically collected. Instead, you have to navigate to your Lambda function’s configuration, enable Enhanced Monitoring, and wait until some data has been gathered.
To enable Enhanced Monitoring go to your Lambda function’s configuration, then to Monitoring and Tools, click on Edit, and toggle the switch for CloudWatch Lambda Insights.
This will add a layer to your Lambda function, through which CloudWatch gathers system metrics by
using the CloudWatch EMF logging format.
Some metrics are directly visualized in the Lambda Insights section, but not the file descriptor usage. Through EMF it’s however available in the CloudWatch metrics, from which we can create graphs ourselves.
Lambda Insights uses the metrics namespace /aws/lambda-insights.
To visualize the file descriptor usage, navigate to CloudWatch Metrics, pick the namespace /aws/lambda-insights and select the metricfd_use. When you select Maximum for statistics, and an aggregation
range of 1 minute, you should see a graph like below (if you use up file descriptors without releasing them).
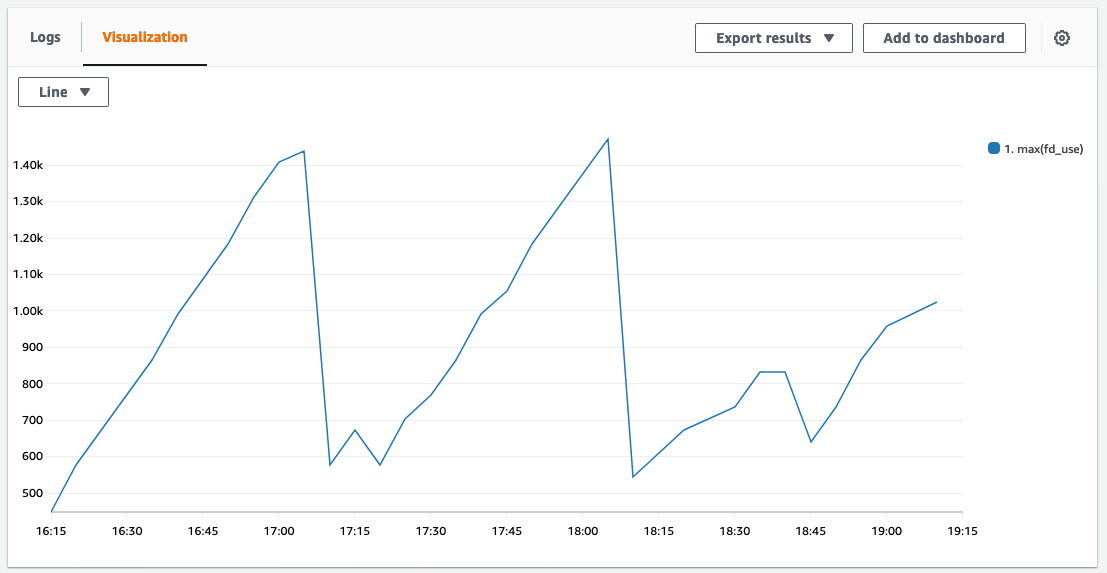
Notice the drops? They happen at exactly the same moment when the function times out and the EMFILE errors appear. Looks like we have a match! Let’s have a look into the details of the file descriptor
usage with the NPM package wtfnode.
How To Get More Details About File Descriptor Usage
My teammate Pieter found an NPM package called wtfnode which helps us better understand what’s going on in Node’s active handles.
Here’s an example of how the result of using wtfnode looks like:
[i] app/24191 on devbox: Server listening on 0.0.0.0:9001 in development mode
^C[WTF Node?] open handles:
- Sockets:
- 10.21.1.16:37696 -> 10.21.2.213:5432
- Listeners:
- connect: anonymous @ /home/me/app/node_modules/pg/lib/connection.js:49
With the information from wtfnode were able to pinpoint which piece of our code created the most sockets: Our code created a new app with custom routing logic on each request, which led to unclosed file handles.
Fix 1: Move Initialization Logic Out Of The Request Handlers
Below you can see the code, where we created a new server on each request. With this approach we create a new file handle, and eventually run out of available handles.
import { createServer, proxy } from "aws-serverless-express";
const app = initApp(); // some custom logic
export const handler = async (event, context) => {
// this was causing the file descriptor usage to go up
return proxy(
createServer(app.callback(), event, context, "PROMISE")
).promise;
}
By refactoring our code to call createServer() outside of the request handler, the method will only be called when AWS Lambda initializes our function.
import { createServer, proxy } from "aws-serverless-express";
const app = initApp(); // some custom logic
const server = createServer(app.callback()); // this is now only called during lambda initialization
export const handler = async (event, context) => {
return proxy(server, event, context, "PROMISE").promise;
}
Fix 2: Enable SDK Connection Reuse
While not required for fixing the EMFILE error, we also enabled connection reuse for the AWS SDK in NodeJS runtimes. To enable this set the
environment variable AWS_NODEJS_CONNECTION_REUSE_ENABLED to 1. This should improve execution times a bit, as our Lambda function doesn’t need to open a new connection for each request.
You can change environment variables through the console, but to keep your changes over multiple deployments, you should use infrastructure as code.
My team uses the CDK. With the CDK you can use the environment field to
set environment variables for Lambda functions.
Verifying The Fix
To verify if the change worked, we compared the metrics from before and after. We also checked the logs if EMFILE errors still appear.
Below you can see a graph that visualizes the file descriptor usage. It’s now constantly below 500, which is a good sign. The graph looks a bit bumpy because it doesn’t start at 0.
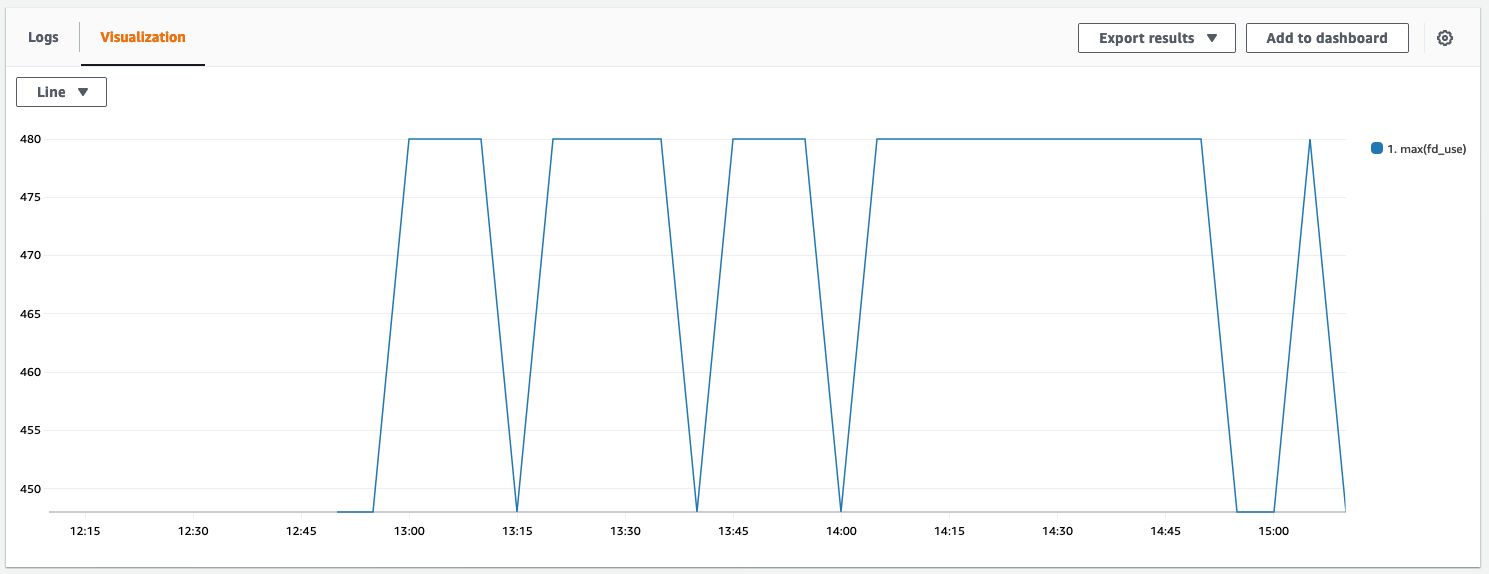
In the logs we didn’t find EMFILE errors anymore. Problem solved o/
Conclusion
Initialize as much as possible outside of request handlers. Try not to do custom routing with servers created in Lambda, but let API Gateway do the job for you.
Lambda Insights and wtfnode are good tools to debug errors that are closer to the runtime/system than normal application level error messages.
It would be nice if AWS would enable Lambda Insights and connection reuse by default. We haven’t seen any downsides to using them.
Enjoyed this article? I publish a new article every month. Connect with me on Twitter and sign up for new articles to your inbox!
Вопрос:
В течение нескольких дней я искал рабочее решение для ошибки
Error: EMFILE, too many open files
Кажется, что у многих людей такая же проблема. Обычный ответ предполагает увеличение количества дескрипторов файлов. Итак, я пробовал это:
sysctl -w kern.maxfiles=20480,
Значение по умолчанию – 10240. Это немного странно в моих глазах, потому что количество файлов, которые я обрабатываю в каталоге, составляет 10240. Даже незнакомец, я все равно получаю ту же ошибку после того, как увеличил число дескрипторов файлов.
Второй вопрос:
После нескольких поисков я нашел работу для проблемы “слишком много открытых файлов”:
var requestBatches = {};
function batchingReadFile(filename, callback) {
// First check to see if there is already a batch
if (requestBatches.hasOwnProperty(filename)) {
requestBatches[filename].push(callback);
return;
}
// Otherwise start a new one and make a real request
var batch = requestBatches[filename] = [callback];
FS.readFile(filename, onRealRead);
// Flush out the batch on complete
function onRealRead() {
delete requestBatches[filename];
for (var i = 0, l = batch.length; i < l; i++) {
batch[i].apply(null, arguments);
}
}
}
function printFile(file){
console.log(file);
}
dir = "/Users/xaver/Downloads/xaver/xxx/xxx/"
var files = fs.readdirSync(dir);
for (i in files){
filename = dir + files[i];
console.log(filename);
batchingReadFile(filename, printFile);
К сожалению, я все же получаю ту же ошибку.
Что не так с этим кодом?
Последний вопрос (я новичок в javascript и node), я занимаюсь разработкой сети
приложение с большим количеством запросов для около 5000 ежедневных пользователей. У меня многолетний опыт работы в
программирование на других языках, таких как python и java. поэтому изначально я решил разработать это приложение с помощью django или play framework. Затем я обнаружил node, и я должен сказать, что идея неблокирующей модели ввода-вывода действительно хорошая, соблазнительная и, самое главное, очень быстро!
Но какие проблемы я должен ожидать от node? Является ли это проверенным продуктом веб-сервером? Каковы ваши впечатления?
Ответ №1
Если graceful-fs не работает… или вы просто хотите понять, откуда вытекает утечка. Следуйте этому процессу.
(например, изящные fs не собираются исправлять ваш вагон, если ваша проблема связана с сокетами.)
Из статьи моего блога: http://www.blakerobertson.com/devlog/2014/1/11/how-to-determine-whats-causing-error-connect-emfile-nodejs.html
Содержание
- Как изолировать
- Справочник по командам
- Чтобы получить количество открытых файлов для определенного pid
- Каков ваш лимит процесса?
- Постоянное изменение лимита:
Как изолировать
Эта команда выдаст количество открытых дескрипторов для процессов nodejs:
lsof -i -n -P | grep nodejs
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
...
nodejs 12211 root 1012u IPv4 151317015 0t0 TCP 10.101.42.209:40371->54.236.3.170:80 (ESTABLISHED)
nodejs 12211 root 1013u IPv4 151279902 0t0 TCP 10.101.42.209:43656->54.236.3.172:80 (ESTABLISHED)
nodejs 12211 root 1014u IPv4 151317016 0t0 TCP 10.101.42.209:34450->54.236.3.168:80 (ESTABLISHED)
nodejs 12211 root 1015u IPv4 151289728 0t0 TCP 10.101.42.209:52691->54.236.3.173:80 (ESTABLISHED)
nodejs 12211 root 1016u IPv4 151305607 0t0 TCP 10.101.42.209:47707->54.236.3.172:80 (ESTABLISHED)
nodejs 12211 root 1017u IPv4 151289730 0t0 TCP 10.101.42.209:45423->54.236.3.171:80 (ESTABLISHED)
nodejs 12211 root 1018u IPv4 151289731 0t0 TCP 10.101.42.209:36090->54.236.3.170:80 (ESTABLISHED)
nodejs 12211 root 1019u IPv4 151314874 0t0 TCP 10.101.42.209:49176->54.236.3.172:80 (ESTABLISHED)
nodejs 12211 root 1020u IPv4 151289768 0t0 TCP 10.101.42.209:45427->54.236.3.171:80 (ESTABLISHED)
nodejs 12211 root 1021u IPv4 151289769 0t0 TCP 10.101.42.209:36094->54.236.3.170:80 (ESTABLISHED)
nodejs 12211 root 1022u IPv4 151279903 0t0 TCP 10.101.42.209:43836->54.236.3.171:80 (ESTABLISHED)
nodejs 12211 root 1023u IPv4 151281403 0t0 TCP 10.101.42.209:43930->54.236.3.172:80 (ESTABLISHED)
....
Обратите внимание: 1023u (последняя строка) – это дескриптор 1024-го файла, который является максимальным по умолчанию.
Теперь посмотрим на последний столбец. Это указывает, какой ресурс открыт. Вероятно, вы увидите несколько строк с одинаковым именем ресурса. Надеюсь, теперь это говорит вам, где искать в своем коде для утечки.
Если вы не знаете несколько процессов node, сначала посмотрите, какой процесс имеет pid 12211. Это скажет вам процесс.
В моем случае выше, я заметил, что существует куча очень похожих IP-адресов. Все они были 54.236.3.### Выполняя поиск по ip-адресам, я смог определить, в моем случае это было связано с pubnub.
Справочник по командам
Используйте этот синтаксис, чтобы определить, сколько открытых дескрипторов процесса открыто…
Чтобы получить количество открытых файлов для определенного pid
Я использовал эту команду для проверки количества файлов, открытых после выполнения различных событий в моем приложении.
lsof -i -n -P | grep "8465" | wc -l
# lsof -i -n -P | grep "nodejs.*8465" | wc -l
28
# lsof -i -n -P | grep "nodejs.*8465" | wc -l
31
# lsof -i -n -P | grep "nodejs.*8465" | wc -l
34
Каков ваш лимит процесса?
ulimit -a
Строка, которую вы хотите, будет выглядеть так:
open files (-n) 1024
Постоянное изменение лимита:
- проверено на Ubuntu 14.04, nodejs v. 7.9
В случае, если вы ожидаете открыть много соединений (например, веб-сокеты), вы можете постоянно увеличить лимит:
-
file:/etc/pam.d/common-session (добавить в конец)
session required pam_limits.so -
file:/etc/security/limits.conf(добавьте в конец или отредактируйте, если он уже существует)
root soft nofile 40000 root hard nofile 100000 -
перезапустите ваши узлы и выйдите из системы ssh.
- это может не работать для более старого узла NodeJS, вам необходимо перезагрузить сервер.
- а не если ваш node работает с другим uid.
Ответ №2
Использование модуля graceful-fs Исаака Шлютера (node.js supporter), вероятно, является наиболее подходящим решением. При возникновении EMFILE происходит постепенное отключение. Его можно использовать как замену для встроенного модуля fs.
Ответ №3
Сегодня я столкнулся с этой проблемой и не нашел хороших решений для этого, я создал модуль для его решения. Я был вдохновлен фрагментом @fbartho, но хотел избежать перезаписи модуля fs.
Модуль, который я написал, Filequeue, и вы используете его точно так же, как fs:
var Filequeue = require('filequeue');
var fq = new Filequeue(200); // max number of files to open at once
fq.readdir('/Users/xaver/Downloads/xaver/xxx/xxx/', function(err, files) {
if(err) {
throw err;
}
files.forEach(function(file) {
fq.readFile('/Users/xaver/Downloads/xaver/xxx/xxx/' + file, function(err, data) {
// do something here
}
});
});
Ответ №4
Вы читаете слишком много файлов. Узел читает файлы асинхронно, он будет читать все файлы одновременно. Итак, вы, вероятно, читаете предел 10240.
Посмотрите, работает ли это:
var fs = require('fs')
var events = require('events')
var util = require('util')
var path = require('path')
var FsPool = module.exports = function(dir) {
events.EventEmitter.call(this)
this.dir = dir;
this.files = [];
this.active = [];
this.threads = 1;
this.on('run', this.runQuta.bind(this))
};
// So will act like an event emitter
util.inherits(FsPool, events.EventEmitter);
FsPool.prototype.runQuta = function() {
if(this.files.length === 0 && this.active.length === 0) {
return this.emit('done');
}
if(this.active.length < this.threads) {
var name = this.files.shift()
this.active.push(name)
var fileName = path.join(this.dir, name);
var self = this;
fs.stat(fileName, function(err, stats) {
if(err)
throw err;
if(stats.isFile()) {
fs.readFile(fileName, function(err, data) {
if(err)
throw err;
self.active.splice(self.active.indexOf(name), 1)
self.emit('file', name, data);
self.emit('run');
});
} else {
self.active.splice(self.active.indexOf(name), 1)
self.emit('dir', name);
self.emit('run');
}
});
}
return this
};
FsPool.prototype.init = function() {
var dir = this.dir;
var self = this;
fs.readdir(dir, function(err, files) {
if(err)
throw err;
self.files = files
self.emit('run');
})
return this
};
var fsPool = new FsPool(__dirname)
fsPool.on('file', function(fileName, fileData) {
console.log('file name: ' + fileName)
console.log('file data: ', fileData.toString('utf8'))
})
fsPool.on('dir', function(dirName) {
console.log('dir name: ' + dirName)
})
fsPool.on('done', function() {
console.log('done')
});
fsPool.init()
Ответ №5
Я только что закончил писать небольшой фрагмент кода для решения этой проблемы самостоятельно, все другие решения выглядят слишком тяжело и требуют изменения вашей структуры программы.
Это решение просто останавливает любые вызовы fs.readFile или fs.writeFile, так что в любой момент времени в полете может быть не больше установленного числа.
// Queuing reads and writes, so your nodejs script doesn't overwhelm system limits catastrophically
global.maxFilesInFlight = 100; // Set this value to some number safeish for your system
var origRead = fs.readFile;
var origWrite = fs.writeFile;
var activeCount = 0;
var pending = [];
var wrapCallback = function(cb){
return function(){
activeCount--;
cb.apply(this,Array.prototype.slice.call(arguments));
if (activeCount < global.maxFilesInFlight && pending.length){
console.log("Processing Pending read/write");
pending.shift()();
}
};
};
fs.readFile = function(){
var args = Array.prototype.slice.call(arguments);
if (activeCount < global.maxFilesInFlight){
if (args[1] instanceof Function){
args[1] = wrapCallback(args[1]);
} else if (args[2] instanceof Function) {
args[2] = wrapCallback(args[2]);
}
activeCount++;
origRead.apply(fs,args);
} else {
console.log("Delaying read:",args[0]);
pending.push(function(){
fs.readFile.apply(fs,args);
});
}
};
fs.writeFile = function(){
var args = Array.prototype.slice.call(arguments);
if (activeCount < global.maxFilesInFlight){
if (args[1] instanceof Function){
args[1] = wrapCallback(args[1]);
} else if (args[2] instanceof Function) {
args[2] = wrapCallback(args[2]);
}
activeCount++;
origWrite.apply(fs,args);
} else {
console.log("Delaying write:",args[0]);
pending.push(function(){
fs.writeFile.apply(fs,args);
});
}
};
Ответ №6
Я не уверен, поможет ли это кому-нибудь, я начал работать над большим проектом с большим количеством зависимостей, который выдал мне ту же ошибку. Мой коллега предложил мне установить watchman используя brew, и это решило эту проблему для меня.
brew update
brew install watchman
Редактировать 26 июня 2019 года: Github ссылка на сторожа
Ответ №7
С волынкой вам просто нужно изменить
FS.readFile(filename, onRealRead);
= >
var bagpipe = new Bagpipe(10);
bagpipe.push(FS.readFile, filename, onRealRead))
Волынка помогает вам ограничить параллель. подробнее: https://github.com/JacksonTian/bagpipe
Ответ №8
Имела ту же проблему при запуске команды nodemon, поэтому я уменьшил имя файлов, открытых в возвышенном тексте, и ошибка исчезла.
Ответ №9
Как и все мы, вы являетесь еще одной жертвой асинхронного ввода-вывода. При асинхронных вызовах, если вы зациклились на большом количестве файлов, Node.js начнет открывать файловый дескриптор для каждого файла для чтения, а затем будет ждать действия, пока вы его не закроете.
Файловый дескриптор остается открытым, пока на вашем сервере не появится ресурс для его чтения. Даже если ваши файлы небольшие, а чтение или обновление выполняется быстро, это займет некоторое время, но в то же время ваш цикл не останавливается, чтобы открыть дескриптор новых файлов. Так что, если у вас слишком много файлов, предел будет скоро достигнут, и вы получите красивый ЭМФИЛЬ.
Есть одно решение – создать очередь, чтобы избежать этого эффекта.
Спасибо людям, которые написали Async, для этого есть очень полезная функция. Существует метод Async.queue, вы создаете новую очередь с ограничением, а затем добавляете имена файлов в очередь.
Примечание: если вам нужно открыть много файлов, было бы неплохо сохранить, какие файлы открыты в данный момент, и не открывать их бесконечно.
const fs = require('fs')
const async = require("async")
var q = async.queue(function(task, callback) {
console.log(task.filename);
fs.readFile(task.filename,"utf-8",function (err, data_read) {
callback(err,task.filename,data_read);
}
);
}, 4);
var files = [1,2,3,4,5,6,7,8,9,10]
for (var file in files) {
q.push({filename:file+".txt"}, function (err,filename,res) {
console.log(filename + " read");
});
}
Вы можете видеть, что каждый файл добавляется в очередь (имя файла console.log), но только тогда, когда текущая очередь находится ниже предела, установленного ранее.
async.queue получает информацию о доступности очереди через обратный вызов, этот обратный вызов вызывается только тогда, когда файл данных читается, и любое действие, которое вам нужно сделать, выполнено. (см. метод fileRead)
Таким образом, вы не можете быть перегружены дескриптором файлов.
> node ./queue.js
0.txt
1.txt
2.txt
0.txt read
3.txt
3.txt read
4.txt
2.txt read
5.txt
4.txt read
6.txt
5.txt read
7.txt
1.txt read (biggest file than other)
8.txt
6.txt read
9.txt
7.txt read
8.txt read
9.txt read
Ответ №10
cwait является общим решением для ограничения одновременных исполнений любых функций, возвращающих promises.
В вашем случае код может выглядеть примерно так:
var Promise = require('bluebird');
var cwait = require('cwait');
// Allow max. 10 concurrent file reads.
var queue = new cwait.TaskQueue(Promise, 10);
var read = queue.wrap(Promise.promisify(batchingReadFile));
Promise.map(files, function(filename) {
console.log(filename);
return(read(filename));
})
Ответ №11
Опираясь на ответ @blak3r, я приведу здесь несколько сокращений, которые помогут другим диагностировать:
Если вы пытаетесь отладить скрипт Node.js, в котором заканчиваются файловые дескрипторы, то здесь есть строка, чтобы дать вам вывод lsof используемый рассматриваемым процессом узла:
openFiles = child_process.execSync('lsof -p ${process.pid}');
Это синхронно запустит lsof отфильтрованный текущим запущенным процессом Node.js, и вернет результаты через буфер.
Затем используйте console.log(openFiles.toString()) чтобы преобразовать буфер в строку и записать результаты.
In case you’re experiencing problems with using Hexo, here is a list of solutions to some frequently encountered issues. If this page doesn’t help you solve your problem, try doing a search on GitHub or our Google Group.
YAML Parsing Error
JS-YAML: incomplete explicit mapping pair; a key node is missed at line 18, column 29:
last_updated: Last updated: %s
Wrap the string with quotations if it contains colons.
JS-YAML: bad indentation of a mapping entry at line 18, column 31:
last_updated:"Last updated: %s"
Make sure you are using soft tabs and add a space after colons.
You can see YAML Spec for more info.
EMFILE Error
Error: EMFILE, too many open files
Though Node.js has non-blocking I/O, the maximum number of synchronous I/O is still limited by the system. You may come across an EMFILE error when trying to generate a large number of files. You can try to run the following command to increase the number of allowed synchronous I/O operations.
$ ulimit -n 10000
Error: cannot modify limit
If you encounter the following error:
$ ulimit -n 10000
ulimit: open files: cannot modify limit: Operation not permitted
It means some system-wide configurations are preventing ulimit to being increased to a certain limit.
To override the limit:
- Add the following line to “/etc/security/limits.conf”:
* - nofile 10000
# '*' applies to all users and '-' set both soft and hard limits
- The above setting may not apply in some cases, ensure “/etc/pam.d/login” and “/etc/pam.d/lightdm” have the following line. (Ignore this step if those files do not exist)
session required pam_limits.so
- If you are on a systemd-based distribution, systemd may override “limits.conf”. To set the limit in systemd, add the following line in “/etc/systemd/system.conf” and “/etc/systemd/user.conf”:
DefaultLimitNOFILE=10000
- Reboot
Process Out of Memory
When you encounter this error during generation:
FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - process out of memory
Increase Node.js heap memory size by changing the first line of hexo-cli (which hexo to look for the file).
#!/usr/bin/env node --max_old_space_size=8192
Out of memory while generating a huge blog · Issue #1735 · hexojs/hexo
Git Deployment Problems
RPC failed
error: RPC failed; result=22, HTTP code = 403
fatal: 'username.github.io' does not appear to be a git repository
Make sure you have set up git on your computer properly or try to use HTTPS repository URL instead.
Error: ENOENT: no such file or directory
If you get an error like Error: ENOENT: no such file or directory it’s probably due to to mixing uppercase and lowercase letters in your tags, categories, or filenames. Git cannot automatically merge this change so it breaks the automatic branching.
To fix this, try
- Check every tag’s and category’s case and make sure they are the same.
- Commit
- Clean and build:
./node_modules/.bin/hexo clean && ./node_modules/.bin/hexo generate - Manually copy the public folder to your desktop
- Switch branch from your master branch to your deployment branch locally
- Copy the contents of the public folder from your desktop into the deployment branch
- Commit. You should see any merge conflicts appear that you can manually resolve.
- Switch back to your master branch and deploy normally:
./node_modules/.bin/hexo deploy
Server Problems
Error: listen EADDRINUSE
You may have started two Hexo servers at the same time or there might be another application using the same port. Try to modify the port setting or start the Hexo server with the -p flag.
$ hexo server -p 5000
Plugin Installation Problems
npm ERR! node-waf configure build
This error may occur when trying to install a plugin written in C, C++ or other non-JavaScript languages. Make sure you have installed the right compiler on your computer.
Error with DTrace (Mac OS X)
{ [Error: Cannot find module './build/Release/DTraceProviderBindings'] code: 'MODULE_NOT_FOUND' }
{ [Error: Cannot find module './build/default/DTraceProviderBindings'] code: 'MODULE_NOT_FOUND' }
{ [Error: Cannot find module './build/Debug/DTraceProviderBindings'] code: 'MODULE_NOT_FOUND' }
DTrace install may have issue, use this:
$ npm install hexo --no-optional
See #1326
Iterate Data Model on Jade or Swig
Hexo uses Warehouse for its data model. It’s not an array so you may have to transform objects into iterables.
{% for post in site.posts.toArray() %}
{% endfor %}
Data Not Updated
Some data cannot be updated, or the newly generated files are identical to those of the last version. Clean the cache and try again.
$ hexo clean
No command is executed
When you can’t get any command except help, init and version to work and you keep getting content of hexo help, it could be caused by a missing hexo in package.json:
{
"hexo": {
"version": "3.2.2"
}
}
Escape Contents
Hexo uses Nunjucks to render posts (Swig was used in older version, which share a similar syntax). Content wrapped with {{ }} or {% %} will get parsed and may cause problems. You can skip the parsing by wrapping it with the raw tag plugin, single backtick `{{ }}` or triple backtick.
Alternatively, Nunjucks tags can be disabled through the renderer’s option (if supported), API or front-matter.
{% raw %}
Hello {{ world }}
{% endraw %}
```
Hello {{ world }}
```
ENOSPC Error (Linux)
Sometimes when running the command $ hexo server it returns an error:
Error: watch ENOSPC ...
It can be fixed by running $ npm dedupe or, if that doesn’t help, try the following in the Linux console:
$ echo fs.inotify.max_user_watches=524288 | sudo tee -a /etc/sysctl.conf && sudo sysctl -p
This will increase the limit for the number of files you can watch.
EMPERM Error (Windows Subsystem for Linux)
When running $ hexo server in a BashOnWindows environment, it returns the following error:
Error: watch /path/to/hexo/theme/ EMPERM
Unfortunately, WSL does not currently support filesystem watchers. Therefore, the live updating feature of hexo’s server is currently unavailable. You can still run the server from a WSL environment by first generating the files and then running it as a static server:
$ hexo generate
$ hexo server -s
This is a known BashOnWindows issue, and on 15 Aug 2016, the Windows team said they would work on it. You can get progress updates and encourage them to prioritize it on the issue’s UserVoice suggestion page.
Template render error
Sometimes when running the command $ hexo generate it returns an error:
FATAL Something's wrong. Maybe you can find the solution here: http://hexo.io/docs/troubleshooting.html
Template render error: (unknown path)
One possible reason is that there are some unrecognizable words in your file, e.g. invisible zero width characters.
YAMLException (Issue #4917)
Upgrading to hexo^6.1.0 from an older version may cause the following error when running $ hexo generate:
YAMLException: Specified list of YAML types (or a single Type object) contains a non-Type object.
at ...
This may be caused by an incorrect dependency(i.e. js-yaml) setting that can’t be solved automatically by the package manager, and you may have to update it manually running:
$ npm install js-yaml@latest
or
$ yarn add js-yaml@latest
if you use yarn.