Approved: ASR Pro
Speed up your computer’s performance now with this simple download.
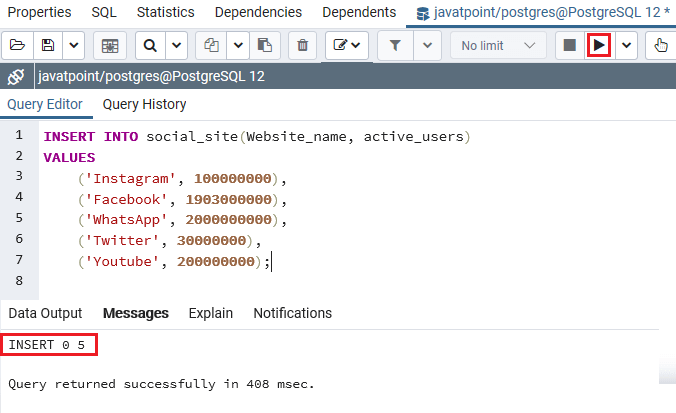
Sometimes your computer may display a message stating that a Postgres error integer is out of range. There can be many reasons for this problem. You tried to insert an integer value into a counter for INSERT that exceeds the range of the underlying integer data type in the specified scope. The simplest example is when you literally put too much valuable content into the database. In such cases, it could be an error in the write stream or the wrong data mode in the database.
CREATE TABLE raw ( SERIAL ID, regtime is NOT NULL, NOT ZERO minute flow rate, Varchar's resource (15), ALL source port, Varchar station (15), exclude INTEGER, logical filling); ... + table of indices and exchanges
I have been successfully using this bank for some time now, and with a sudden rate the next deposit no longer works ..
INSERT INTO raw ( Time, Regtime, Blocked, Destination, Source Port, Source, Destination) VALUES ( 1403184512.2283964, 1403184662.118, false, 2, 3, '192.168.0.1', '192.168.0.2');
I don’t know where to start debugging. Instead of thisth I ran out of space and the error is pretty subtle.
Requested
Visited 15000 times
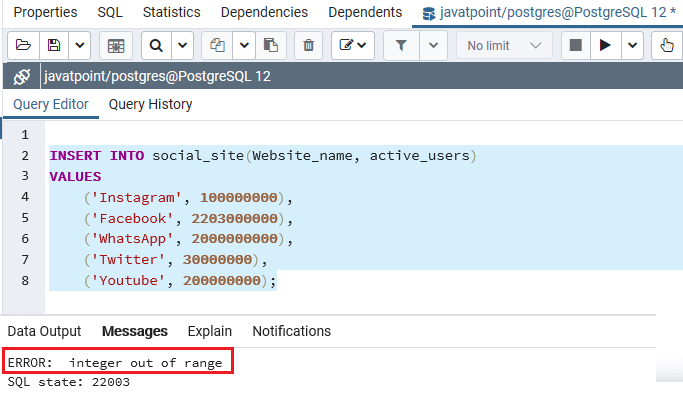
I have two questions. I’m looking for two that insert the same value: 429496729600 , but some don’t work with the error:
db => mount order_detail set amount = 400 * 1024 * 1024 * 1024 where I had = 11;ERROR: integer out of rangedb => update the amount defined for order_detail = 429496729600 only if id = 11;UPDATE 1
UPD
If you forgot to enter the type amount , it will be bigint and
400 * 1024 * 1024 * 1024 == 429496729600

31.8k
asked May 2018 at 22:39

16.5k
Not The Answer You Are Looking For? Check Out Other Questions Tagged Sql Postgresql Type-conversion Or Ask Your Suspect.
To force multiplication to return bigint instead of int, you can convert 1 to bigint and multiply
select cast (1 bigint every time) * 400 * 1024 * 1024 * 1024; ?Pillar?-------------- 429496729600
answered Sep 8 ’18 at 19:50

11.7k
int boA larger value of 2 31 -1, the first update value greater than this, raises a new error.
INT -2147483648 to +2147483647
BIGINT -9223372036854775808 to 9223372036854775807
ALTER TABLE order_detail COLUMN Fine tuning of the amount TYPE BIGINT;
postgresql forces 429496729600 to try to be BIGINT because the value is greater than the int range.
SELECT pg_typeof (429496729600);| pg_typeof --------- || || bigint |
If your website is multiplying by numbers, this will be interpreted as int .
SELECT pg_typeof (1 * 15 * 1);| pg_typeof || --------- || whole |
SELECT 400 * 1024 * 1024 * 1024 :: BIGINT;| ?Pillar? || ------------ || 429496729600 |
answered Sep 8, 2018 at 7:45 pm
Approved: ASR Pro
ASR Pro is the world’s most popular and effective PC repair tool. It is trusted by millions of people to keep their systems running fast, smooth, and error-free. With its simple user interface and powerful scanning engine, ASR Pro quickly finds and fixes a broad range of Windows problems — from system instability and security issues to memory management and performance bottlenecks.

31.8k
Speed up your computer’s performance now with this simple download.
![]() Admin
Admin ![]() 07.06.2020, обновлено: 09.08.2020
07.06.2020, обновлено: 09.08.2020 ![]() Python Errors
Python Errors
Ошибка вида psycopg2.errors.NumericValueOutOfRange: integer out of range.
Ошибка означает, что в таблице колонка в которую пытались сохраниться данные выходит за допустимые границы числа. Надо изменить эту колонку с INT на BIGINT.
Метки:psycopg2
Читайте также
 PyCharm Python не видится модуль psycopg2
PyCharm Python не видится модуль psycopg2 Ошибка в SQLAlchemy — sqlalchemy.orm.exc.StaleDataError
Ошибка в SQLAlchemy — sqlalchemy.orm.exc.StaleDataError- PostgreSQL — как сбросить очередь
 Error on line 35 at column 206: EntityRef: expecting ‘;’
Error on line 35 at column 206: EntityRef: expecting ‘;’

У сайта нет цели самоокупаться, поэтому на сайте нет рекламы. Но если вам пригодилась информация, можете лайкнуть страницу, оставить комментарий или отправить мне подарок на чашечку кофе.
Добавить комментарий
Напишите свой комментарий, если вам есть что добавить/поправить/спросить по теме текущей статьи:
«Что означает psycopg2.errors.NumericValueOutOfRange: integer out of range«
attach_file Добавить файл
Имя *
Email *
Получать новые комментарии по электронной почте. Вы можете подписаться без комментирования.
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and
privacy statement. We’ll occasionally send you account related emails.
Already on GitHub?
Sign in
to your account
Comments
![]()
I think I found a regression related to: #97
When using deltas & rails fixtures with postgresql I get the error: «ERROR: index ‘catalog_edition_core’: sql_range_query: ERROR: integer out of range»
I tracked the problem down to my sphinx.conf:
sql_query = SELECT «catalog_editions».»id» * 4 + 0 AS «id»…..
updating the sql_query to
sql_query = SELECT «catalog_editions».»id»::bigint * 4 + 0 AS «id»…..
fixes the issue. My temporary workaround is to monkey patch thinking sphinx:
ThinkingSphinx::ActiveRecord::SQLBuilder.class_eval do def document_id quoted_alias = quote_column source.primary_key "#{quoted_primary_key}::bigint * #{config.indices.count} + #{source.offset} AS #{quoted_alias}" end end
which obviously breaks mysql.
![]()
Are you finding this change still works for you? I’ve just created a test table which uses bigints for the primary key, and added a record with a very large id. Sphinx is happy indexing up to a point… but if the indices count or offset puts it over the 64 bit limit, then I get the error you mention, and your fix doesn’t stop the error. My understanding is that the calculated value is too big for PostgreSQL, let alone Sphinx.
![]()
![]()
Thanks for the response Igor. Could you share the fixture definition? And how in your test you’re loading the fixture data?
![]()
Just to +1 this, this is definitely a regression from #97.
It can reproduced running rake ts:index on any project using postgres and foxy fixtures.
In 2.1.0:
sql_query = SELECT «articles».»id» * 4::INT8 + 0 AS «id» …
In 3.1.0:
sql_query = SELECT «articles».»id» * 8 + 0 AS «id» …
With an ID like «980190962», which is within the 32 bit integer range, multiplying it causes it to extend outside the bounds of the «integer» type.
pat
added a commit
that referenced
this issue
May 4, 2014
![]()
Set big_document_ids to true either via set_property in specific index definitions, or within config/thinking_sphinx.yml to impact all indices. See #610.
![]()
Just pushed a fix for this to the develop branch. Either in a specific index:
set_property :big_document_ids => true
Or in config/thinking_sphinx.yml to impact all indices:
development: big_document_ids: true
To use the latest in develop:
gem 'thinking-sphinx', '~> 3.1.1', :git => 'git://github.com/pat/thinking-sphinx.git', :branch => 'develop', :ref => '119ee4e1a7'
![]()
Awesome. Can’t wait for this to hit release
![]()
I’ve seen such an error today when someone inserted 20014-12-25 in indexed date field 💣
![]()
@Envek you may want to set 64bit_timestamps to true for each environment in config/thinking_sphinx.yml — and/or have some validation on dates to avoid those massive values 
An Oracle to PostgreSQL migration in the AWS Cloud can be a multistage process with different technologies and skills involved, starting from the assessment stage to the cutover stage. For more information about the migration process, see Database Migration—What Do You Need to Know Before You Start? and the following posts on best practices, including the migration process and infrastructure considerations, source database considerations, and target database considerations for the PostgreSQL environment.
In the migration process, data type conversion from Oracle to PostgreSQL is one of the key stages. Multiple tools are available on the market, such as AWS Schema Conversion Tool (AWS SCT) and Ora2PG, which help you with data type mapping and conversion. However, it’s always recommended that you do an upfront analysis on the source data to determine the target data type, especially when working with data types like NUMBER.
Many tools often convert this data type to NUMERIC in PostgreSQL. Although it looks easy to convert Oracle NUMBER to PostgreSQL NUMERIC, it’s not ideal for performance because calculations on NUMERIC are very slow when compared to an integer type. Unless you have a large value without scale that can’t be stored in BIGINT, you don’t need to choose the column data type NUMERIC. And as long as the column data doesn’t have float values, you don’t need to define the columns as the DOUBLE PRECISION data type. These columns can be INT or BIGINT based on the values stored. Therefore, it’s worth the effort to do an upfront analysis to determine if you should convert the Oracle NUMBER data type to INT, BIGINT, DOUBLE PRECISION, or NUMERIC when migrating to PostgreSQL.
This series is divided into two posts. In this post, we cover two analysis methods to define the target data type column in PostgreSQL depending on how the NUMBER data type is defined in the Oracle database and what values are stored in the columns’ data. In the second post, we cover how to change the data types in the target PostgreSQL database after analysis using the AWS SCT features and map data type using transformation.
Before we suggest which of these data types in PostgreSQL is a suitable match for Oracle NUMBER, it’s important to know the key differences between these INT, BIGINT, DOUBLE PRECISION, and NUMERIC.
Comparing numeric types in PostgreSQL
One of the important differences between INT and BIGINT vs. NUMERIC is storage format. INT and BIGINT have a fixed length: INT has 4 bytes, and BIGINT has 8 bytes. However, the NUMERIC type is of variable length and stores 0–255 bytes as needed. So NUMERIC needs more space to store the data. Let’s look at the following example code (we’re using PostgreSQL 12), which shows the size differences of tables with integer columns and NUMERIC:
postgres=# SELECT pg_column_size('999999999'::NUMERIC) AS "NUMERIC length", pg_column_size('999999999'::INT) AS "INT length";
NUMERIC length | INT length
---------------+------------
12 | 4
(1 row)
postgres=# CREATE TABLE test_int_length(id INT, name VARCHAR);
CREATE TABLE
postgres=# CREATE TABLE test_numeric_length(id NUMERIC, name VARCHAR);
CREATE TABLE
postgres=# INSERT INTO test_int_length VALUES (generate_series(100000,1000000));
INSERT 0 900001
postgres=# INSERT INTO test_numeric_length VALUES (generate_series(100000,1000000));
INSERT 0 900001
postgres=# SELECT sum(pg_column_size(id))/1024 as "INT col size", pg_size_pretty(pg_total_relation_size('test_int_length')) as "Size of table" FROM test_int_length;
INT col size | Size of table
--------------+----------------
3515 | 31 MB
(1 row)
Time: 104.273 ms
postgres=# SELECT sum(pg_column_size(id))/1024 as "NUMERIC col size", pg_size_pretty(pg_total_relation_size('test_numeric_length')) as "Size of table" FROM test_numeric_length;
NUMERIC col size | Size of table
------------------+----------------
6152 | 31 MB
(1 row)From the preceding output, INT occupies 3,515 bytes and NUMERIC occupies 6,152 bytes for the same set of values. However, you see the same table size because PostgreSQL is designed such that its own internal natural alignment is 8 bytes, meaning consecutive fixed-length columns of differing size must be padded with empty bytes in some cases. We can see that with the following code:
SELECT pg_column_size(row()) AS empty,
pg_column_size(row(0::SMALLINT)) AS byte2,
pg_column_size(row(0::BIGINT)) AS byte8,
pg_column_size(row(0::SMALLINT, 0::BIGINT)) AS byte16;
empty | byte2 | byte8 | byte16
-------+-------+-------+--------
24 | 26 | 32 | 40From the preceding output, it’s clear that an empty PostgreSQL row requires 24 bytes of various header elements, a SMALLINT is 2 bytes, and a BIGINT is 8 bytes. However, combining a SMALLINT and BIGINT takes 16 bytes. This is because PostgreSQL is padding the smaller column to match the size of the following column for alignment purposes. Instead of 2 + 8 = 10, the size becomes 8 + 8 = 16.
Integer and floating point values representation and their arithmetic operations are implemented differently. In general, floating point arithmetic is more complex than integer arithmetic. It requires more time for calculations on numeric or floating point values as compared to the integer types.
PostgreSQL BIGINT and INT data types store their own range of values. The BIGINT range (8 bytes) is -9223372036854775808 to 9223372036854775807:
postgres=# select 9223372036854775807::bigint;
int8
---------------------
9223372036854775807
(1 row)
postgres=# select 9223372036854775808::bigint;
ERROR: bigint out of rangeThe INT range (4 bytes) is -2147483648 to 2147483647:
postgres=# select 2147483647::int;
int4
------------
2147483647
(1 row)
postgres=# select 2147483648::int;
ERROR: integer out of rangeFor information about these data types, see Numeric Types.
With the NUMBER data type having precision and scale in Oracle, it can be either DOUBLE PRECISION or NUMERIC in PostgreSQL. One of the main differences between DOUBLE PRECISION and NUMERIC is storage format and total length of precision or scale supported. DOUBLE PRECISION is fixed at 8 bytes of storage and 15-decimal digit precision.
DOUBLE PRECISION offers a similar benefit as compared to the NUMERIC data type as explained for BIGINT and INT in PostgreSQL.
With DOUBLE PRECISION, because its limit is 15 decimals, for any data with higher precision or scale we might be affected by data truncation during data migration from Oracle. See the following code:
postgres=> select 123456789.10111213::double precision as Scale_Truncated, 123456789101112.13::double precision as Whole_Scale_Truncated;
scale_truncated | whole_scale_truncated
------------------+-----------------------
123456789.101112 | 123456789101112When considering data type in PostgreSQL when the NUMBER data type has decimal information, we should check for max precision along with max scale and decide accordingly if the target data type is either DOUBLE PRECISION or NUMERIC.
If you’re planning to store values that require a certain precision or arithmetic accuracy, the DOUBLE PRECISION data type may be the right choice for your needs. For example, if you try to store the result of 2/3, there is some rounding when the 15th digit is reached when you use DOUBLE PRECISION. It’s used for not only rounding the value based on precision limit, but also for the arithmetic accuracy. If you consider the following example, a double precision gives the wrong answer.
postgres=# select 0.1::double precision + 0.2 as value;
value
---------------------
0.30000000000000004
(1 row)
postgres=# select 0.1::numeric + 0.2 as value;
value
-------
0.3
(1 row)
Starting with PostgreSQL 12, performance has been improved by using a new algorithm for output of real and double precision values. In previous versions (older than PostgreSQL 12), displayed floating point values were rounded to 6 (for real) or 15 (for double precision) digits by default, adjusted by the value of the parameter extra_float_digits. Now, whenever extra_float_digits is more than zero (as it is by default from PostgreSQL 12 and newer), only the minimum number of digits required to preserve the exact binary value are output. The behavior is the same as before when extra_float_digits is set to zero or less.
postgres=# set extra_float_digits to 0;
SET
postgres=# select 0.1::double precision + 0.2 as value;
value
-------
0.3
(1 row)Oracle NUMBER and PostgreSQL NUMERIC
In Oracle, the NUMBER data type is defined as NUMBER(precision, scale) and in PostgreSQL, NUMERIC is defined as NUMERIC(precision, scale), with precision and scale defined as follows:
- Precision – Total count of significant digits in the whole number, that is, the number of digits to both sides of the decimal point
- Scale – Count of decimal digits in the fractional part, to the right of the decimal point
Analysis before data type conversion
Data type changes may have some side effects, which we discuss in this post. Before converting data types, you need to check with your service or application team if they have the following:
- Any dependency of these data types (INT and BIGINT) in application SQLs that require type casting
- Any change required in stored procedures or triggers for these data types
- Any dependency in Hibernate-generated code
- If these data type changes have any impact on future data growth
- Any plans in the future for these columns to store any fractional values
Without proper analysis and information on the application code and the database code objects, it’s not recommended to change the data types. If you do so, your application queries may start showing performance issues because they require a type casting internally from NUMERIC to INT or BIGINT. If you have code objects like procedures or triggers with these data types’ dependency, you need to make changes to those objects to avoid performance issues. Future data growth may impact these conversions as well. If you convert it to INT based on the current data, however, it may go beyond INT value in the future. Make sure you don’t have any plans to store fractional values after migration is complete. If that is the requirement, you need to choose a different data type than INT or BIGINT.
For this post, we examine two different methods to analyze the information to recommend INT, BIGINT, DOUBLE PRECISION, or NUMERIC:
- Metadata-based data type conversion
- Actual data-based data type conversion
Analysis method: Metadata-based data type conversion
By looking at the metadata information of Oracle tables with columns of the NUMBER or INTEGER data type, we can come up with the target data type recommendations.
Conversion to PostgreSQL INT or BIGINT
You can covert Oracle tables with columns of the data type NUMBER or INTEGER to PostgreSQL INT or BIGINT if they meet the following criteria:
- The data type is NUMERIC or INTEGER in Oracle
- DATA_PRECISION is NOT NULL (not a variable length NUMERIC)
- DATA_SCALE is 0 (integers and not float values)
- MAX_LENGTH is defined as <=18 (DATA_PRECISION <=18)
- If DATA_PRECISION is < 10, use INT. If DATA_PRECISION is 10–18, use BIGINT.`
You can use the following query on Oracle to find candidate columns of NUMERIC or INTEGER data type that can be converted to BIGINT or INT in PostgreSQL:
SELECT
OWNER
, TABLE_NAME
, COLUMN_NAME
, DATA_TYPE
, DATA_PRECISION
, DATA_SCALE
FROM
dba_tab_columns
WHERE
OWNER in ('owner_name')
and (DATA_TYPE='NUMBER' or DATA_TYPE='INTEGER')
and DATA_PRECISION is NOT NULL
and (DATA_SCALE=0 or DATA_SCALE is NULL)
and DATA_PRECISION <= 18;
The following code is an example output of the preceding query, which shows precision and scale of NUMBER data types for a particular user:
OWNER TABLE_NAME COLUMN_NAME DATA_TYPE DATA_PRECISION DATA_SCALE
---------- -------------------- -------------------- ---------- -------------- ----------
DEMO COUNTRIES REGION_ID NUMBER 10 0
DEMO CUSTOMER CUSTOMER_ID NUMBER 15 0
DEMO DEPARTMENTS DEPARTMENT_ID NUMBER 4 0
DEMO EMPLOYEES EMPLOYEE_ID NUMBER 6 0
DEMO EMPLOYEES MANAGER_ID NUMBER 6 0
DEMO EMPLOYEES DEPARTMENT_ID NUMBER 4 0
DEMO ORDERS ORDER_ID NUMBER 19 0
DEMO ORDERS VALUE NUMBER 14 0
DEMO PERSON PERSON_ID NUMBER 5 0
The output shows four columns (REGION_ID of the COUNTRIES table, CUSTOMER_ID of the CUSTOMER table, and ORDER_ID and VALUE of the ORDERS table) that have precision between 10–18, which can be converted to BIGINT in PostgreSQL. The remaining columns can be converted to INT.
Conversion to PostgreSQL DOUBLE PRECISION or NUMERIC
You can convert Oracle tables with columns of the data type NUMBER or INTEGER to PostgreSQL DOUBLE PRECISION or NUMERIC if they meet the following criteria:
- The data type is NUMERIC or NUMBER in Oracle
- DATA_PRECISION is NOT NULL
- DATA_SCALE is > 0 (float values)
If DATA_PRECISION + DATA_SCALE <= 15, choose DOUBLE PRECISION. If DATA_PRECISION + DATA_SCALE > 15, choose NUMERIC.
You can use the following query on Oracle to find candidate columns of NUMERIC or INTEGER data type that can be converted to DOUBLE PRECISION or NUMERIC in PostgreSQL:
SELECT
OWNER
, TABLE_NAME
, COLUMN_NAME
, DATA_TYPE
, DATA_PRECISION
, DATA_SCALE
FROM
dba_tab_columns
WHERE
OWNER in ('owner_name')
and (DATA_TYPE='NUMBER' or DATA_TYPE='INTEGER')
and DATA_PRECISION is NOT NULL
and DATA_SCALE >0;
The following is an example output of the query:
OWNER TABLE_NAME COLUMN_NAME DATA_TYPE DATA_PRECISION DATA_SCALE
------- ------------ -------------------- -------------- -------------- ----------
DEMO COORDINATES LONGI NUMBER 10 10
DEMO COORDINATES LATTI NUMBER 10 10
DEMO EMPLOYEES COMMISSION_PCT NUMBER 2 2
The output contains the column COMMISSION_PCT from the EMPLOYEES table, which can be converted as DOUBLE PRECISION. The output also contains two columns (LONGI and LATTI) that can be NUMERIC because they have (precision + scale) > 15.
Changing the data type for all candidate columns may not have the same impact or performance gain. Most columns that are part of the key or index appear in joining conditions or in lookup, so changing the data type for those columns may have a big impact. The following are guidelines for converting the column data type in PostgreSQL, in order of priority:
- Consider changing the data type for columns that are part of a key (primary, unique, or reference)
- Consider changing the data type for columns that are part of an index
- Consider changing the data type for all candidate columns
Analysis method: Actual data-based data type conversion
In Oracle, the NUMBER data type is often defined with no scale, and those columns are used for storing integer value only. But because scale isn’t defined, the metadata doesn’t show if these columns store only integer values. In this case, we need to perform a full table scan for those columns to identify if the columns can be converted to BIGINT or INT in PostgreSQL.
A NUMERIC column may be defined with DATA_PRECISION higher than 18, but all column values fit well in the BIGINT or INT range of PostgreSQL.
You can use the following SQL code in an Oracle database to find if the actual DATA_PRECISION and DATA_SCALE is in use. This code performs a full table scan, so you need to do it in batches for some tables, and if possible run it during low peak hours in an active standby database (ADG):
select /*+ PARALLEL(tab 4) */
max(length(trunc(num_col))) MAX_DATA_PRECISION,
min(length(trunc(num_col))) MIN_DATA_PRECISION,
max(length(num_col - trunc(num_col)) -1 ) MAX_DATA_SCALE
from <<your-table-name>> tab;Based on the result of the preceding code, use the following transform rules:
- If MAX_DATA_PRECISION < 10 and MAX_DATA_SCALE = 0, convert to INT
- If DATA_PRECISION is 10–18 and MAX_DATA_SCALE = 0, convert to BIGINT
- if MAX_DATA_SCALE > 0 and MAX_DATA_PRECISION + MAX_DATA_SCALE <= 15, convert to DOUBLE PRECISION
- if MAX_DATA_SCALE > 0 and MAX_DATA_PRECISION + MAX_DATA_SCALE > 15, convert to NUMERIC
Let’s look at the following example. In Oracle, create the table number_col_test with four columns defined and a couple of rows inserted:
SQL> CREATE TABLE DEMO.number_col_test (
col_canbe_int NUMBER(8,2),
col_canbe_bigint NUMBER(19,2),
col_canbe_doubleprecision NUMBER(15,2),
col_should_be_number NUMBER(20,10)
);
Table created.
SQL> INSERT INTO demo.number_col_test VALUES (1234, 12345678900, 12345.12, 123456.123456);
1 row created.
SQL> INSERT INTO demo.number_col_test VALUES (567890, 1234567890012345, 12345678.12, 1234567890.1234567890);
1 row created.
SQL> set numwidth 25
SQL> select * from demo.number_col_test;
COL_CANBE_INT COL_CANBE_BIGINT COL_CANBE_DOUBLEPRECISION COL_SHOULD_BE_NUMBER
-------------- -------------- ------------------------- --------------------
1234 12345678900 12345.12 123456.123456
567890 1234567890012345 12345678.12 1234567890.123456789
We next run a query to look at the data to find the actual precision and scale. From the following example, can_be_int has precision as 6 and scale as 0 even though it’s defined as NUMBER(8,4). So we can define this column as INT in PostgreSQL.
SQL> select /*+ PARALLEL(tab 4) */
max(length(trunc(COL_CANBE_INT))) MAX_DATA_PRECISION,
min(length(trunc(COL_CANBE_INT))) MIN_DATA_PRECISION,
max(length(COL_CANBE_INT - trunc(COL_CANBE_INT)) -1 ) MAX_DATA_SCALE
from demo.number_col_test;
MAX_DATA_PRECISION MIN_DATA_PRECISION MAX_DATA_SCALE
------------------------- ------------------------- -------------------------
6 4 0In the following output, can_be_bigint has precision as 16 and scale as 0 even though it’s defined as NUMBER(19,2). So we can define this column as BIGINT in PostgreSQL.
SQL> select /*+ PARALLEL(tab 4) */
max(length(trunc(COL_CANBE_BIGINT))) MAX_DATA_PRECISION,
min(length(trunc(COL_CANBE_BIGINT))) MIN_DATA_PRECISION,
max(length(COL_CANBE_BIGINT - trunc(COL_CANBE_BIGINT)) -1 ) MAX_DATA_SCALE
from demo.number_col_test;
MAX_DATA_PRECISION MIN_DATA_PRECISION MAX_DATA_SCALE
------------------------- ------------------------- -------------------------
16 11 0In the following output, can_be_doubleprecision has precision as 8 and scale as 2 even though it’s defined as NUMBER(15,2). We can define this column as DOUBLE PRECISION in PostgreSQL.
SQL> select /*+ PARALLEL(tab 4) */
max(length(trunc(COL_CANBE_DOUBLEPRECISION))) MAX_DATA_PRECISION,
min(length(trunc(COL_CANBE_DOUBLEPRECISION))) MIN_DATA_PRECISION,
max(length(COL_CANBE_DOUBLEPRECISION - trunc(COL_CANBE_DOUBLEPRECISION)) -1 ) MAX_DATA_SCALE
from demo.number_col_test;
MAX_DATA_PRECISION MIN_DATA_PRECISION MAX_DATA_SCALE
------------------------- ------------------------- -------------------------
8 5 2In the following output, should_be_numeric has precision as 10 and scale as 9 even though it’s defined as NUMBER(20,10). We can define this column as NUMERIC in PostgreSQL.
SQL> select /*+ PARALLEL(tab 4) */
max(length(trunc(COL_SHOULD_BE_NUMBER))) MAX_DATA_PRECISION,
min(length(trunc(COL_SHOULD_BE_NUMBER))) MIN_DATA_PRECISION,
max(length(COL_SHOULD_BE_NUMBER - trunc(COL_SHOULD_BE_NUMBER)) -1 ) MAX_DATA_SCALE
from demo.number_col_test;
MAX_DATA_PRECISION MIN_DATA_PRECISION MAX_DATA_SCALE
------------------------- ------------------------- -------------------------
10 6 9Summary
Converting the NUMBER data type from Oracle to PostgreSQL is always tricky. It’s not recommended to convert all NUMBER data type columns to NUMERIC or DOUBLE PRECISION in PostgreSQL without a proper analysis of the source data. Having the appropriate data types helps improve performance. It pays long-term dividends by spending time upfront to determine the right data type for application performance. From the Oracle system tables, you get precision and scale of all the columns of all the tables for a user. With this metadata information, you can choose the target data type in PostgreSQL as INT, BIGINT, DOUBLE PRECISION, or NUMERIC.
However, you can’t always depend on this information. Although this metadata shows the scale of some columns as >0, the actual data might not have floating values. Look at the actual data in every table’s NUMBER columns (which are scale >0), and decide on the target columns’ data types.
| Precision(m) | Scale(n) | Oracle | PostgreSQL |
| <= 9 | 0 | NUMBER(m,n) | INT |
| 9 > m <=18 | 0 | NUMBER(m,n) | BIGINT |
| m+n <= 15 | n>0 | NUMBER(m,n) | DOUBLE PRECISION |
| m+n > 15 | n>0 | NUMBER(m,n) | NUMERIC |
In the next post in this series, we cover methods to convert the data type in PostgreSQL after analysis is complete, and we discuss data types for the source Oracle NUMBER data type.
About the authors
 Baji Shaik is a Consultant with AWS ProServe, GCC India. His background spans a wide depth and breadth of expertise and experience in SQL/NoSQL database technologies. He is a Database Migration Expert and has developed many successful database solutions addressing challenging business requirements for moving databases from on-premises to Amazon RDS and Aurora PostgreSQL/MySQL. He is an eminent author, having written several books on PostgreSQL. A few of his recent works include “PostgreSQL Configuration“, “Beginning PostgreSQL on the Cloud”, and “PostgreSQL Development Essentials“. Furthermore, he has delivered several conference and workshop sessions.
Baji Shaik is a Consultant with AWS ProServe, GCC India. His background spans a wide depth and breadth of expertise and experience in SQL/NoSQL database technologies. He is a Database Migration Expert and has developed many successful database solutions addressing challenging business requirements for moving databases from on-premises to Amazon RDS and Aurora PostgreSQL/MySQL. He is an eminent author, having written several books on PostgreSQL. A few of his recent works include “PostgreSQL Configuration“, “Beginning PostgreSQL on the Cloud”, and “PostgreSQL Development Essentials“. Furthermore, he has delivered several conference and workshop sessions.
 Sudip Acharya is a Sr. Consultant with the AWS ProServe team in India. He works with internal and external Amazon customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.
Sudip Acharya is a Sr. Consultant with the AWS ProServe team in India. He works with internal and external Amazon customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.
 Deepak Mahto is a Consultant with the AWS Proserve Team in India. He has been working as Database Migration Lead, helping and enabling customers to migrate from commercial engines to Amazon RDS.His passion is automation and has designed and implemented multiple database or migration related tools.
Deepak Mahto is a Consultant with the AWS Proserve Team in India. He has been working as Database Migration Lead, helping and enabling customers to migrate from commercial engines to Amazon RDS.His passion is automation and has designed and implemented multiple database or migration related tools.