![]()
What is the problem you are having with rclone?
Fatal error: failed to umount FUSE fs: exit status 1: fusermount: failed to unmount /mnt/gdrive: Invalid argument
What is your rclone version (output from rclone version)
rclone v1.48.0
- os/arch: linux/amd64
- go version: go1.12.6
Which OS you are using and how many bits (eg Windows 7, 64 bit)
Ubuntu 18.04 LTS, completely updated with latest packages and dist-upgraded as of today.
Which cloud storage system are you using? (eg Google Drive)
GDrive/TDrive
The command you were trying to run (eg rclone copy /tmp remote:tmp)
#!/bin/bash
[Unit]
Description=tdrive Daemon
After=multi-user.target
[Service]
Type=Type=notify
User=0
Group=0
ExecStart=/usr/bin/rclone mount tdrive: /mnt/tdrive
--config=/opt/appdata/plexguide/rclone.conf
--uid=1000 --gid=1000 --umask=002
--log-file=/var/plexguide/logs/rclone-tdrive.log
--log-level=NOTICE
--allow-other
--timeout=1h
--user-agent="myuserappagent"
--dir-cache-time=7620m
--vfs-cache-mode=writes
--vfs-cache-max-age=1h
--vfs-cache-max-size=off
--vfs-read-chunk-size-limit=1024M
--vfs-read-chunk-size=64M
--buffer-size=256M
ExecStop=/bin/fusermount -uz /mnt/tdrive
TimeoutStopSec=60
[Install]
WantedBy=multi-user.target
I’m not sure what causes this, it probably happens during a reboot or when the service is restarted. I also tried /bin/fusermount -uz /mnt/tdrive and /bin/fusermount -uzq /mnt/tdrive
It doesn’t seem to prevent things from mounting again, just an error users keep reporting to us.
![]()
I wonder where you are getting those parametes to mount it.
—fast-list does nothing on a mount can can be removed.’
—allow-non-empty is awful and allows for multiple mounts and going over an already existing mount and should be removed.
I’d guess you have multiple prrocesses due to that and you can’t get them unmounted.
You are also running it as root. Is that intended?
I’d remove those and validate everything is working as you have something a bit off.
![]()
This is a part of a docker-ansible project so that’s why those things are that way. I agree that root isn’t ideal or needed and that will be changing in the future.
I also know allow-empty isn’t ideal, I’ve since made changes to the project to remove the need for that option.
This appears to have started happening in v1.48 or possibly one before that.
Do you think it may be the fast-list argument?
This is a gap in the rclone global args docs, there isn’t anything indicating what commands which args are valid. Because of that I assume fast-list would be ok and used on a mount.
![]()
It’s not fast-list as it does nothing on a mount.
If you find something in the docs that needs to be adjusted, feel free to submit a pull request to make something clear as that’s the beauty 
![]()
You seem to know what arguments work with what commands, I don’t. How did you find out fast-list does nothing on a mount?
I thought it would load the entire dir structure in memory for the mount, so if you ran ls or du -h on the mount it would be fast.
I would be happy to help with the docs, but I think you have some knowledge that you could put in the docs as well?
![]()
![]()
https://rclone.org/flags/
«These flags are available for every command.»
That isn’t right since fast-list is listed under that. That page needs updated.
![]()
Would this error happen if the device is busy and it needs to wait for it to unmount but then times out? Still happens with allow empty removed.
![]()
@animosity22 vfs-cache-max-size off
could it be this, should it be 0 instead.
Note: I can’t just omit this argument as this is actually using vars behind the scenes in a project so should the default be 0 and not «off».
![]()
It’s available but not every command works with every backend.
You should fix whatever the upstream is rather than using options that add no value/make things complex.
If you can’t fusermount it, you should work on fixing that error.
Share some output rather than it doesn’t work.
Grab a ps -ef | grep rclone and see what’s running.
Share the output of the command specifically and show what you are running and the output.
![]()
It’s been working just an odd error randomly when unmounting.
These options do have value, this isn’t just for 1 personal system. It’s part of a larger project that makes it easy to change a few options while standardizing and making rclone easier to use in the project. It would be more complex trying to only add the arg if it’s non-default.
It appears to unmount. I thought it could be related to v1.48 as I personally didn’t see it until then. Could you check your logs just to confirm?
@ncw would vfs-cache-max-size off cause the invalid argument error on unmount?
I wouldn’t think so, as this should be an error from fusermount, not rclone. at least right now, the ps grep is clean
![]()
Yeah, but the options you are perpetuating out are not good so that makes it worse for larger groups.
Again, you haven’t shared anything, a log, a command you are running. No output.
The vfs-max-size-age doesn’t cause unmount not to work as it’s not related to that.
Your systemd file is also not quite right.
KillMode=process
RemainAfterExit=yes
If you have it with killmode process, it sends a SIGTERM to the process and you also try to fusermount it.
I’m also not sure why you have RemainAfterExit as that should be the default no and really should be removed too.
You should be using this:
https://rclone.org/commands/rclone_mount/#systemd
Here is an example working systemd that unmounts properly:
[felix@gemini system]$ cat gmedia-rclone.service
[Unit]
Description=RClone Service
Wants=network-online.target
After=network-online.target
[Service]
Type=notify
Environment=RCLONE_CONFIG=/opt/rclone/rclone.conf
ExecStart=/usr/bin/rclone mount gcrypt: /GD
--allow-other
--buffer-size 1G
--dir-cache-time 96h
--log-level INFO
--log-file /opt/rclone/logs/rclone.log
--timeout 1h
--umask 002
--rc
ExecStop=/bin/fusermount -uz /GD
Restart=on-failure
User=felix
Group=felix
[Install]
WantedBy=multi-user.target
![]()
Thank you, so far so good.
I’m pretty sure it was
KillMode=process
RemainAfterExit=yes
and then I tried to fusermount, so it called fusermount and killed the process and sometimes it must have killed it before the unmount causes the invalid arg (like mount wasnt up or didnt exist). thanks for the help.
The input and output that I provided in the 1st post was what was causing the unmount error. It didn’t happen 100% of the time either so it was tricky.
![]()
I take that back, I got it again when running sudo service gdrive stop, does it invoke the ExecStop command when doing that @animosity22
![]()
Dunno, you never share any output / systemd file / error messages so it’s all guessing.
![]()
Did you not see my top post? I shared it all already. It has that in there…. that’s the systemd file with the args, what more do you need?
The logs show: Fatal error: failed to umount FUSE fs: exit status 1: fusermount: failed to unmount /mnt/gdrive: Invalid argument
All I’m doing is running the service and stopping the service and I get that error.
![]()
ghost
reopened this
Jul 14, 2019
![]()
When you edit something, no notification happens. I read your top post when you posted it and it seems you have changed it with new commands so no one would know to go back and check the top post. Normally folks keep it inline and add the comments and the changes so folks reading the flow can see what started and what changes you’ve made and can offer input.
Here is an example test.service:
[root@gemini system]# df -h | grep Test
[root@gemini system]# systemctl start test.service
[root@gemini system]# df -h | grep Test
gcrypt: 1.0P 71T 1.0P 7% /Test
[root@gemini system]# systemctl status test.service
● test.service - RClone Service
Loaded: loaded (/etc/systemd/system/test.service; disabled; vendor preset: disabled)
Active: active (running) since Sun 2019-07-14 10:46:45 EDT; 5s ago
Main PID: 23974 (rclone)
Tasks: 14 (limit: 4915)
Memory: 70.8M
CGroup: /system.slice/test.service
└─23974 /usr/bin/rclone mount gcrypt: /Test --allow-other --buffer-size 1G --dir-cache-time 96h --timeout 1h --umask 002
Jul 14 10:46:44 gemini systemd[1]: Starting RClone Service...
Jul 14 10:46:45 gemini systemd[1]: Started RClone Service.
[root@gemini system]# systemctl stop test.service
[root@gemini system]# df -h | grep Test
and the systemd file.
[root@gemini system]# cat test.service
[Unit]
Description=RClone Service
Wants=network-online.target
After=network-online.target
[Service]
Type=notify
Environment=RCLONE_CONFIG=/opt/rclone/rclone.conf
ExecStart=/usr/bin/rclone mount gcrypt: /Test
--allow-other
--buffer-size 1G
--dir-cache-time 96h
--timeout 1h
--umask 002
ExecStop=/bin/fusermount -uz /Test
Restart=on-failure
User=felix
Group=felix
[Install]
WantedBy=multi-user.target
Example Journal Logs.
[root@gemini system]# journalctl -xe
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- The unit UNIT has successfully entered the 'dead' state.
Jul 14 10:46:54 gemini kernel: audit: type=1131 audit(1563115614.988:1965): pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=test >
Jul 14 10:46:54 gemini audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=test comm="systemd" exe="/usr/lib/s>
Jul 14 10:46:54 gemini systemd[1]: test.service: Succeeded.
-- Subject: Unit succeeded
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- The unit test.service has successfully entered the 'dead' state.
Jul 14 10:46:54 gemini systemd[1]: Stopped RClone Service.
-- Subject: A stop job for unit test.service has finished
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- A stop job for unit test.service has finished.
--
-- The job identifier is 2770 and the job result is done.
Jul 14 10:47:42 gemini mono[1361]: [Info] RssSyncService: Starting RSS Sync
Jul 14 10:47:45 gemini mono[1361]: [Info] DownloadDecisionMaker: Processing 394 releases
Jul 14 10:47:55 gemini mono[1361]: [Info] DownloadService: Report sent to qBittorrent. breakthrough.2019.2160p.uhd.bluray.x265-terminal
Jul 14 10:47:55 gemini mono[1361]: [Info] RssSyncService: RSS Sync Completed. Reports found: 394, Reports grabbed: 1
[root@gemini system]# journctl -u test.service
-bash: journctl: command not found
[root@gemini system]# journalctl -u test.service
-- Logs begin at Tue 2019-06-25 15:14:27 EDT, end at Sun 2019-07-14 10:47:55 EDT. --
Jul 14 10:46:44 gemini systemd[1]: Starting RClone Service...
Jul 14 10:46:45 gemini systemd[1]: Started RClone Service.
Jul 14 10:46:54 gemini systemd[1]: Stopping RClone Service...
Jul 14 10:46:54 gemini systemd[1]: test.service: Succeeded.
Jul 14 10:46:54 gemini systemd[1]: Stopped RClone Service.
Is rclone running still?
![]()
As soon as I unmount or stop the service I check ps -ef | grep rclone and it’s fine, rclone is not running, and /mnt/gdrive is empty,
journalctl -xe
ul 14 07:52:01 systemd[1]: Stopping gdrive Daemon...
-- Subject: Unit gdrive.service has begun shutting down
-- Defined-By: systemd
-- Support: http://www.ubuntu.com/support
--
-- Unit gdrive.service has begun shutting down.
Jul 14 07:52:01 systemd[1]: gdrive.service: Main process exited, code=exited, status=1/FAILURE
Jul 14 07:52:01 systemd[1]: gdrive.service: Failed with result 'exit-code'.
Jul 14 07:52:01 systemd[1]: Stopped gdrive Daemon.
-- Subject: Unit gdrive.service has finished shutting down
-- Defined-By: systemd
-- Support: http://www.ubuntu.com/support
--
-- Unit gdrive.service has finished shutting down.
Jul 14 07:52:01 sudo[38094]: pam_unix(sudo:session): session closed for user root
next i’m going to changing logging to DEBUG to see if that gives me a clue
![]()
gdrive.service: Failed with result ‘exit-code’ This is gotta be a bug in rclone right? why is it ‘exit-code’ and not 0 or 1 or -234 or something like that…
Changing to -vv didn’t give me anything useful.
Perhaps related to this change, which was introduced in v1.48 870b153
![]()
Can you run the same commands without systemd and share the exact output from everything.
[felix@gemini ~]$ sudo su -
[root@gemini ~]# RCLONE_CONFIG=/opt/rclone/rclone.conf
[root@gemini ~]# export RCLONE_CONFIG
[root@gemini ~]# rclone mount gcrypt: /Test
and when I unmounted:
[felix@gemini ~]$ sudo su -
[root@gemini ~]# fusermount -uz /Test
[root@gemini ~]#
![]()
user@server123:~$ sudo su -
root@server123:~# RCLONE_CONFIG=/opt/appdata/plexguide/rclone.conf
root@server123:~# export RCLONE_CONFIG
root@server123:~# rclone mount gdrive: /mnt/gdrive
opened a new term:
root@server123:~# fusermount -uz /mnt/gdrive
root@server123:~#
No errors
![]()
The only time I get this is when I run this with no mount running.
root@server123:~# fusermount -uz /mnt/gdrive
fusermount: failed to unmount /mnt/gdrive: Invalid argument
![]()
Yeah, you can’t unmount something not mounted as it should error out.
Can you:
sudo systemctl daemon-reload
cat rclone.servce and share output
systemctl start rclone.service
systemctl status rclone.service and share the output
systemctl stop rclone.service and share the output.
![]()
root@server123:~# cat /etc/systemd/system/gdrive.service
#!/bin/bash
#
# Title: PGBlitz (Reference Title File)
# Author(s): Admin9705
# URL: https://pgblitz.com - http://github.pgblitz.com
# GNU: General Public License v3.0
################################################################################
[Unit]
Description=gdrive Daemon
After=multi-user.target
[Service]
Type=notify
ExecStart=/usr/bin/rclone mount gdrive: /mnt/gdrive
--config=/opt/appdata/plexguide/rclone.conf
--uid=1000 --gid=1000 --umask=002
--log-file=/var/plexguide/logs/rclone-gdrive.log
--log-level=NOTICE
--allow-other
--timeout=1h
--user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"
--dir-cache-time=7620m
--vfs-cache-mode=writes
--vfs-cache-max-age=1h
--vfs-read-chunk-size-limit=1024M
--vfs-read-chunk-size=64M
--buffer-size=256M
ExecStop=/bin/fusermount -uz /mnt/gdrive
Restart=on-failure
User=0
Group=0
[Install]
WantedBy=multi-user.target
root@server123:~# systemctl start gdrive.service
root@server123:~# systemctl status gdrive.service
● gdrive.service - gdrive Daemon
Loaded: loaded (/etc/systemd/system/gdrive.service; enabled; vendor preset: enabled)
Active: active (running) since Sun 2019-07-14 08:25:41 MST; 2min 15s ago
Main PID: 23123 (rclone)
Tasks: 38 (limit: 6143)
CGroup: /system.slice/gdrive.service
└─23123 /usr/bin/rclone mount gdrive: /mnt/gdrive --config=/opt/appdata/plexguide/rclone.conf --uid=1000 --gid=1000 --umask=002 --log-file=/var/plexgui
Jul 14 08:25:41 server123 systemd[1]: Starting gdrive Daemon...
Jul 14 08:25:41 server123 systemd[1]: Started gdrive Daemon.
root@server123:~# systemctl stop gdrive.service
root@server123:~# systemctl status gdrive.service
● gdrive.service - gdrive Daemon
Loaded: loaded (/etc/systemd/system/gdrive.service; enabled; vendor preset: enabled)
Active: inactive (dead) since Sun 2019-07-14 08:28:11 MST; 3s ago
Process: 27444 ExecStop=/bin/fusermount -uz /mnt/gdrive (code=exited, status=0/SUCCESS)
Process: 23123 ExecStart=/usr/bin/rclone mount gdrive: /mnt/gdrive --config=/opt/appdata/plexguide/rclone.conf --uid=1000 --gid=1000 --umask=002 --log-file=/var
Main PID: 23123 (code=exited, status=0/SUCCESS)
Jul 14 08:25:41 server123 systemd[1]: Starting gdrive Daemon...
Jul 14 08:25:41 server123 systemd[1]: Started gdrive Daemon.
Jul 14 08:28:11 server123 systemd[1]: Stopping gdrive Daemon...
Jul 14 08:28:11 server123 systemd[1]: Stopped gdrive Daemon.
![]()
2019/07/14 08:25:41 Fatal error: failed to umount FUSE fs: exit status 1: fusermount: failed to unmount /mnt/gdrive: Invalid argument
![]()
So that all worked without issue.
root@server123:~# systemctl stop gdrive.service
root@server123:~# systemctl status gdrive.service
● gdrive.service - gdrive Daemon
Loaded: loaded (/etc/systemd/system/gdrive.service; enabled; vendor preset: enabled)
Active: inactive (dead) since Sun 2019-07-14 08:28:11 MST; 3s ago
Process: 27444 ExecStop=/bin/fusermount -uz /mnt/gdrive (code=exited, status=0/SUCCESS)
Process: 23123 ExecStart=/usr/bin/rclone mount gdrive: /mnt/gdrive --config=/opt/appdata/plexguide/rclone.conf --uid=1000 --gid=1000 --umask=002 --log-file=/var
Main PID: 23123 (code=exited, status=0/SUCCESS)
You can see the fusermount exited with 0.
![]()
it seems to be related to when I unmount or restart the service as my sudo user (using sudo)
![]()
It would generate an error if not mounted. Seems to be working fine in the output you shared.
![]()
I rebooted the machine, logged in as my normal user. restarting several times no error reported.
I kept restarting the service. Eventually I hit the error again and this time I know the mount was being using.
That mount must be in use at that time it’s unmounted and I get the error.
I’m being careful not to unmount it twice bc I know that will cause it.
if I take out -z, I get device busy error. So maybe it’s not handling a lazy unmount properly when it’s busy.
For example, I stop the service, reload daemon, restart them. truncate logs, reboot system, check logs, fusermount error.
![]()
So share those logs and the same output as above if you can reproduce it.
![]()
Same output starts and exits fine.
Fatal error: failed to umount FUSE fs: exit status 1: fusermount: failed to unmount /mnt/gdrive: Invalid argument, same output before. everything checks out.
It’s gotta be because the drive is randomly in use. I have another mount (tdrive) which is used by plex. it’s scanning right now. if I restart the service, I get the error every time right now. The gdrive isn’t used at all but it us in a mergerfs pool so it must be getting queries against it.
So it seems like this happens when the mount is in use when running fusermount -uz,
-u will throw a in use error instead like it should.
![]()
What output? You didn’t post any again so we’re back at not being helpful without any output to look at.
![]()
b/c the output isn’t helpful. it’s the same as before.
Side note: I get it. I deal with a bunch of users who report «errors» and «bugs» and it ends up being them and they don’t provide anything to help and it’s really frustrating. I understand the pain of trying to support and help someone. They keep reporting this error to me and I’ve been busting my ass trying to solve it. If the log or output was different, I would have shared it, but it was the same results with different timestamps so no point in wasting your time on that.
Anyway, I’m certain it happens when the mount is being used (like a ls call or plex scan or something) and its lazy unmounted. It seems in this case it’s passing the string ‘error-code’ instead of the actual error code, which may or not be actually erroring at this point. A code search did not find that string.
I’m gonna step back from this for a bit. thanks for the help. I hope @ncw will have some thoughts.
![]()
Same as before? The before you shared worked. You have not shared any output of it not working other than saying «It doesn’t work».
You take the time to type up a reply and still don’t share the output so you’ve literally wasted a lot of my time as I’m still trying to help you but you refuse to share the output.
Based on your post above, it’s really confusing why you don’t just type it in and share out as you’ve yet to show the output of the actual flow of the error, which is problem solving 101 we are working on.
ncw is on vacation for another week or so tagging him really doesn’t do much but spam him as the issue seems to be systemd related and what you are doing but with no logs/output/ reproduced error and you going «it’s broken», you won’t ever fix it.
![]()
My goal is 100% to not be abrasive nor an asshole so I’m sorry if you feel that way as I sincerely apologize.
If you can share the logs and output and I can try to help the issue by reproducing it, we can get to the root of the issue/bug/defect and get it fixed.
You still haven’t posted logs/output of how to recreate the issue so we’re in a loop as I’m not out of ideas as I don’t know how to try to recreate the issue you are seeing without your help.
![]()
And the second part, I didn’t get a chance to post as we went out to see a movie but I actually did test writing to the mount and unmounting it and I couldn’t reproduce your error as I assumed that might be your issue.
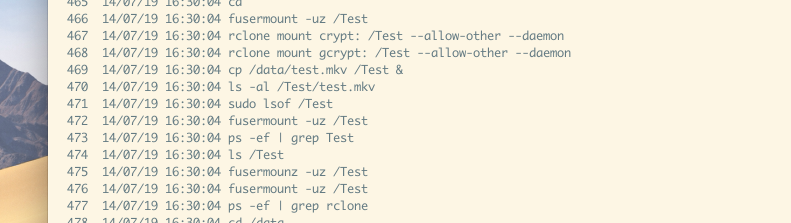
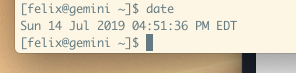
You can see I’m EST so that was a few hours back:
If you can share some screens with the steps and what you are doing, that can help reproduce it and get it fixed regardless if it’s a rclone bug or not.
![]()
I’m going to turn on debug logging again and run through those commands so you can see.
In the meantime, this is how you can try and reproduce. You can the config values I’m using, but I honestly don’t think it matters. The one that matters most is a log file and the loglevel. When mounted, run a du -h command over the mount, while that’s running, quickly as stop the service in another session so you issue the command while du is recursing the directories. Once it’s unmounted, check the logfile. You may need to repeat this a few times. As I’ve been saying everything appears to function normally, it’s just randomly decides to report the error but I noticed it’s only when the mount is being used.
Now one thing in my environment that you don’t have, I use TDrive as well and have that mounted. I only really use TDrive. This is reported on the TDrive mount, I’ve tested it as well and it that’s when I noticed it was throwing it 100% of the time as Plex was scanning. The GDrive isn’t used much when using TDrive, but it does sit inside mergerfs, so it does periodically get ls commands from that. Since it’s not used 99.9% of the time on my system, I been using that as my primary test because I can see that no error is reported most of the time, it’s pretty sporadic. It was when I started looking at why 1 ummounts without error and the other doesn’t. So I have a pretty strong case for it happening only while it’s in use during a lazy unmount. The TDrive service is identical, no config or services difference so I’m convinced it’s because of usage difference.
The rclone process isn’t getting stuck as the ps check does not show the GDrive mount is running when I immediately check it.
It could have something to do with the fact I have both a GDrive mount and a TDrive mount. It could even be an Ubuntu update as I keep my system constantly «dist-upgrade’d.
I’ll get back to you with more log output
![]()
Do you only ever get the fusermount error in systemd though?
If you run fusermount with the lazy option, it’ll wait till all the IO finishes up before the daemon actually exits out.
Are you only seeing the error in systemd? I assume systemd would be timing out and returning the error. Here is an example of the same thing via console:
[felix@gemini ~]$ rclone mount gcrypt: /Test --allow-other -vv --log-file=/tmp/test.log --daemon
[felix@gemini ~]$ cd /Test
[felix@gemini Test]$ date
Sun 14 Jul 2019 05:06:51 PM EDT
[felix@gemini Test]$ date
Sun 14 Jul 2019 05:07:17 PM EDT
[felix@gemini Test]$ du -h >> /dev/null &
[1] 24935
[felix@gemini Test]$
[felix@gemini Test]$
[felix@gemini Test]$ sudo lsof /Test
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
bash 20421 felix cwd DIR 0,63 0 1 /Test
du 24935 felix cwd DIR 0,63 0 1 /Test
du 24935 felix 3r DIR 0,63 0 12461748423268613384 /Test/Movies/A Quiet Passion (2016)
du 24935 felix 4r DIR 0,63 0 1 /Test
du 24935 felix 5r DIR 0,63 0 12334951539984183433 /Test/Movies
du 24935 felix 6r DIR 0,63 0 12461748423268613384 /Test/Movies/A Quiet Passion (2016)
sudo 24938 root cwd DIR 0,63 0 1 /Test
lsof 24939 root cwd DIR 0,63 0 1 /Test
lsof 24940 root cwd DIR 0,63 0 1 /Test
[felix@gemini Test]$ fusermount -uz /Test
[felix@gemini Test]$ ps -ef | grep rclone | grep Test
felix 24874 1 1 17:06 ? 00:00:00 rclone mount gcrypt: /Test --allow-other -vv --log-file=/tmp/test.log --daemon
[felix@gemini Test]$ date
Sun 14 Jul 2019 05:07:43 PM EDT
[felix@gemini Test]$ date
Sun 14 Jul 2019 05:07:44 PM EDT
[felix@gemini Test]$ ps -ef | grep rclone | grep Test
felix 24874 1 1 17:06 ? 00:00:01 rclone mount gcrypt: /Test --allow-other -vv --log-file=/tmp/test.log --daemon
[felix@gemini Test]$ fusermount -uz /Test
fusermount: entry for /Test not found in /etc/mtab
[felix@gemini Test]$ date
Sun 14 Jul 2019 05:08:02 PM EDT
[felix@gemini Test]$ ps -ef | grep rclone | grep Test
felix 24874 1 1 17:06 ? 00:00:01 rclone mount gcrypt: /Test --allow-other -vv --log-file=/tmp/test.log --daemon
[felix@gemini Test]$ fg
du -h >> /dev/null
^C
[felix@gemini Test]$ cd
[felix@gemini ~]$ date
Sun 14 Jul 2019 05:08:11 PM EDT
[felix@gemini ~]$ ps -ef | grep rclone | grep Test
[felix@gemini ~]$
![]()
Putting systemd into debug mode:
Jul 14 17:24:25 gemini systemd[1]: Stopping RClone Service...
Jul 14 17:24:25 gemini systemd[1]: test.service: User lookup succeeded: uid=1000 gid=1000
Jul 14 17:24:25 gemini systemd[27410]: test.service: Executing: /bin/fusermount -uz /Test
Jul 14 17:24:25 gemini systemd[1]: test.service: Child 27410 belongs to test.service.
Jul 14 17:24:25 gemini systemd[1]: test.service: Control process exited, code=exited, status=0/SUCCESS
Jul 14 17:24:25 gemini systemd[1]: test.service: Got final SIGCHLD for state stop.
Jul 14 17:24:25 gemini systemd[1]: test.service: Changed stop -> stop-sigterm
Jul 14 17:24:25 gemini systemd[1]: test.service: Got notification message from PID 27371 (STOPPING=1)
Jul 14 17:24:25 gemini systemd[1]: test.service: Child 27371 belongs to test.service.
Jul 14 17:24:25 gemini systemd[1]: test.service: Main process exited, code=exited, status=1/FAILURE
Jul 14 17:24:25 gemini systemd[1]: test.service: Failed with result 'exit-code'.
Jul 14 17:24:25 gemini systemd[1]: test.service: Changed stop-sigterm -> failed
Jul 14 17:24:25 gemini systemd[1]: test.service: Job 4186 test.service/stop finished, result=done
Jul 14 17:24:25 gemini systemd[1]: Stopped RClone Service.
Jul 14 17:24:25 gemini systemd[1]: test.service: Unit entered failed state.
When executing the systemctl stop, it terminates the process, which terminates the mount, which makes the lazy unmount return 1 as it got nuked.
![]()
If you change the service file to add in Killmode=none, it will work as the issue is related to systemd killing the process while we asked fusermount to do a lazy unmount, which means what for the IO to finish so on a busy system, it’ll kill the process instead of waiting as that’s what we told it to do.
With test.service.
[root@gemini system]# cat test.service
[Unit]
Description=RClone Service
Wants=network-online.target
After=network-online.target
[Service]
KillMode=none
Type=notify
TimeoutSec=900
Environment=RCLONE_CONFIG=/opt/rclone/rclone.conf
ExecStart=/usr/bin/rclone mount gcrypt: /Test
--allow-other
--buffer-size 1G
--dir-cache-time 96h
--timeout 1h
-vv
--log-file /tmp/test.log
--umask 002
ExecStop=/bin/fusermount -uz /Test
Restart=on-failure
User=felix
Group=felix
[Install]
WantedBy=multi-user.target
So I guess it depends on what you want to do. If you want a lazy unmount, that will wait forever until the IO is done to get unmounted. If your system is constantly hitting it, it’ll go on and on.
![]()
You were able to reproduce it! Thank you for sticking with this. That’s the same behavior I’m seeing.
It makes sense, my service now looks like this:
[Unit]
Description=gdrive Daemon
After=multi-user.target
[Service]
Type=notify
KillMode=none
TimeoutSec=900
ExecStart=/usr/bin/rclone mount gdrive: /mnt/gdrive
--config=/opt/appdata/plexguide/rclone.conf
--uid=1000 --gid=1000 --umask=002
--log-file=/var/plexguide/logs/rclone-gdrive.log
--log-level=NOTICE
--allow-other
--timeout=1h
--user-agent="agent"
--dir-cache-time=7620m
--vfs-cache-mode=writes
--vfs-cache-max-age=1h
--vfs-read-chunk-size-limit=1024M
--vfs-read-chunk-size=64M
--buffer-size=256M
ExecStop=/bin/fusermount -uz /mnt/gdrive
Restart=on-failure
User=0
Group=0
[Install]
WantedBy=multi-user.target
I’m going to close this issue now and will give it some time before submitting a docs PR
![]()
En fait vous devez donner lest autorisations a /mnt en faisant sudo chmod -R 777 /mnt Apres y avoir créer t’es dossiers avec mkdir /mnt/{cryption,encryption} tout dépendant comment tu a appeler ton dossier dans ta config rclone et si tu utilise allow other tu dois enlever le # a la ligne user_allow_other en entrant sudo nano /etc/fuse.conf
FAQ
Can I use my encrypted ACD/GDrive content with Plex and other dockers?
Yes, that’s exactly the purpose of this container.
Can i haz unlimited space on my unRAID setup?
I think 233 TB is the maximum I’ve seen so far with Amazon Cloud Drive.
How do i create the .rclone.conf file?
docker exec -it Rclone-mount rclone —config=»/config/.rclone.conf» config
I already have a .rclone.conf file from the rclone plugin, can I use it rather than creating a new one?
Sure, there are two ways:
- Mount the /config volume so it points to the directory which contains the .rclone.conf file. E.g.: -v «/boot/config/plugins/rclone-beta/»:»/config»:rw
- Copy it to: «/mnt/cache/appdata/rclone-mount/config/»
I cannot see my mounted volume/files outside of the container
- Make sure you have this in extra parameters (advanced view): —cap-add SYS_ADMIN —device /dev/fuse —security-opt apparmor:unconfine -v /mnt/disks/rclone_volume/:/data:shared
- Make sure that this docker container is started before the container you are sharing the volume with.
Can i use the copy/sync features of rclone with this docker?
Use the other docker i made which supports that.
What are the best mount settings for Plex playback / transcoding?
- See this post
- And this discussion on the official rclone forum
- And ajkis wiki on GitHub
I want more verbose logging, so I can see what’s going on
This is not entirely documented yet by rclone, but there is some discussion here.
Summarized, in the RCLONE_MOUNT_OPTIONS variable put:
- -v flag for information logging
- Or -vv for alot verbose logging
Why should I specify the /data mount in the Extra Parameters?
Because the unRAID docker GUI does not support the shared mount propagation options, which is required for the rclone FUSE mount to be shared with other containers. I’ve already opened a feature request to have this option available in the GUI.
This option has been added to the GUI by @bonienl and is no longer necessary.
Can I change the volume mapping of the mount from /mnt/disks/rclone_volume/ to another location?
Yes, in the Extra Parameters change the default value of -v /mnt/disks/rclone_volume/:/data:shared to -v <location>:/data:shared
Edited February 9, 2019 by thomast_88
-
#1
I have an ubuntu CT and trying to mount a rclone S3 bucket.
I can ls all files in the bucket but can’t mount them.
rclone mount dh:delete1 /media/dreamhost/
2021/12/04 09:10:10 mount helper error: fusermount: fuse device not found, try ‘modprobe fuse’ first
2021/12/04 09:10:10 Fatal error: failed to mount FUSE fs: fusermount: exit status 1
sudo modprobe fuse
modprobe: FATAL: Module fuse not found in directory /lib/modules/5.13.19-1-pve
Do I need to do anything maybe on a proxmox host end to make it work?
Thx
Last edited: Dec 8, 2021
![]()
oguz
Proxmox Retired Staff
Retired Staff
-
- Nov 19, 2018
-
- 5,207
-
- 708
-
- 118
-
#2
hi,
have you tried enabling fuse option for that container?
you can do it in the GUI: Container -> Options -> Features -> check the FUSE box
-
#3
hi,
have you tried enabling fuse option for that container?
you can do it in the GUI: Container -> Options -> Features -> check the FUSE box
Yes finally found it and it worked fine.
![]()
oguz
Proxmox Retired Staff
Retired Staff
-
- Nov 19, 2018
-
- 5,207
-
- 708
-
- 118
-
#4
great, you can mark the thread as [SOLVED]
|
View previous topic :: View next topic |
||||||||||||||
| Author | Message | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| drrkc0d3 DD-WRT Novice Joined: 02 Apr 2019 |
|
|||||||||||||
| Back to top |
|
|||||||||||||
| Sponsor | ||||||||||||||
|
Navigation
|
You cannot post new topics in this forum |