 В связи с тем, что довольно много людей обращается с просьбой помочь исправить проблему с кодировками MySQL, решил написать статью с описанием, как «лечить» наиболее часто встречающиеся случаи.
В связи с тем, что довольно много людей обращается с просьбой помочь исправить проблему с кодировками MySQL, решил написать статью с описанием, как «лечить» наиболее часто встречающиеся случаи.
В статье описывается не то, как первоначально правильно настроить кодировки MySQL (об этом уже довольно много написано), а о случаях, когда есть довольно большие таблицы с неправильными кодировками и нужно всё исправить.
Самое плохое в неправильно настроенных кодировках — то, что зачастую проблему сложно обнаружить, и с первого взгляда может казаться, что сайт работает правильно, и никаких проблем нет.
Небольшое отступление. Sypex Viewer
В какой-то момент надоело отправлять людей в громоздкий phpMyAdmin, и была написана крошечная утилитка Sypex Viewer. Она представляет собой один PHP-файл, использует современные Web 2.0 технологии AJAX, JSON и другие. Основные задачи, которые ставилась при создании — минимальный вес, и максимальное удобство и скорость работы. В дальнейшем в примерах будут скриншоты из неё, но все те же действия можно сделать и в phpMyAdmin.
Данные в cp1251 таблицы в latin1
Наверное, самая популярная проблема. Когда данные в кодировке cp1251 (Windows-1251), а у таблиц указана кодировка по умолчанию latin1. Такие ситуации возникают в следующих случаях:
- при неграмотном обновлении с версии MySQL меньше 4.1 на более новые;
- очень часто возникает в «буржуйских» скриптах, которых вполне устраивает кодировка по умолчанию, и они «забывают», что неплохо бы указывать кодировку, как таблиц, так и соединения;
- также бывают случаи, когда переезжают с одного сервера (у которого установлена дефолтная кодировка cp1251, в частности, так сделано в Денвере) на другой (у которого стоит стандартная кодировка latin1).
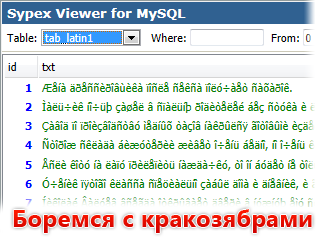
В результате на сайте вроде как всё нормально, но если посмотреть в Sypex Viewer, то русские символы будут выглядеть как «кракозябры» (как их обычно называют пользователи).
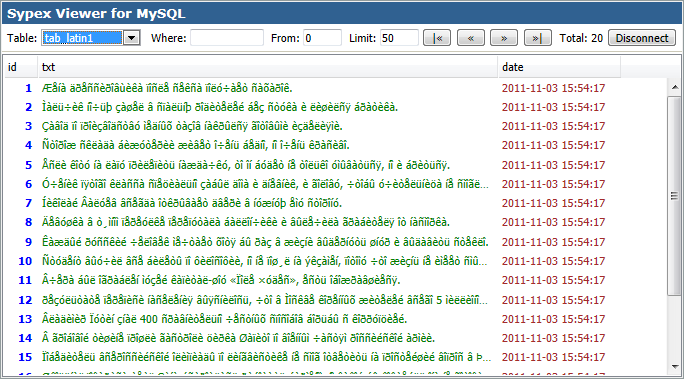
В статье я рассмотрю один из вариантов преобразование кодировок с помощью бесплатного php-скрипта Sypex Dumper, в качестве готового решения.
- На вкладке «Экспорт» выбираем нужные таблицы.
- Кодировка должна быть auto (остальные параметры неважны, можно комментарий добавить, например, «Дамп перед исправлением кодировки»).
- Нажимаем «Выполнить». Теперь у нас есть бэкап (его в любом случае желательно делать при любых преобразованиях базы данных).
- Переходим на вкладку «Импорт»
- Выбираем только что сделанный файл бэкапа.
- Выбираем кодировку cp1251 и помечаем опцию «Коррекция кодировки».
- Нажимаем «Выполнить».
- Вот и всё заходим в Sypex Viewer, чтобы убедиться, что русские символы выводятся корректно.

Данные и таблицы в utf8, но кодировка соединения latin1
Теперь рассмотрим более запущенный случай. Набирающая популярность в последнее время проблема, в связи с повальным увлечением UTF-8. Создатели софта стали переводить свои детища на UTF-8, но и тут не всё так гладко, как хотелось бы.
Возникает проблема в основном в случае, когда у таблиц указана кодировка UTF-8, данные в UTF-8, но кодировка соединения установлена по умолчанию latin1 (типичный пример, vBulletin 4, хоть там и есть в конфигах настройка кодировки соединения, но она закомментирована по умолчанию).
В результате в MySQL присылаются данные в UTF-8, но поскольку указана кодировка соединения latin1, то MySQL пытается преобразовать данные из latin1 в UTF-8. В итоге русские символы выглядят так:
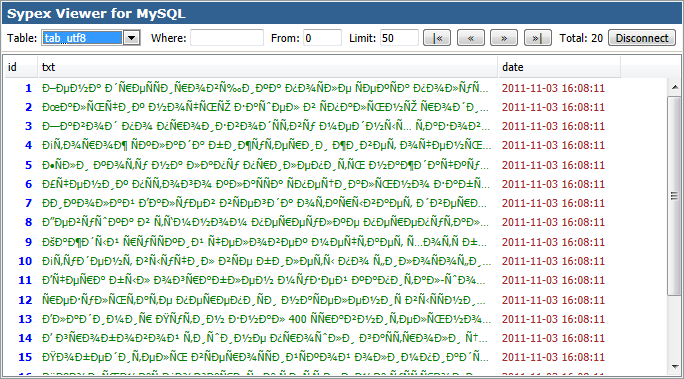
Ситуация более запущенная, но исправляется проблема почти также, как в первом случае, только в пункте 2 нужно выбрать кодировку latin1, а в пункте 6 нужно выбрать utf8 кодировку.
Изменение кодировки
Также часто встречающаяся проблема преобразования кодировки из cp1251 в UTF-8. До выполнения этого шага обязательно убедитесь, что русские символы у вас правильно показываются в Sypex Viewer или phpMyAdmin, если это не так, то предварительно исправьте кодировку.
Итак, опять заходим в Sypex Dumper.
- Во вкладке «Экспорт» выбираем нужные таблицы.
- Устанавливаем кодировку, в которую хотите преобразовать таблицы, в данном случае utf8.
- Нажимаем «Выполнить».
- После чего заходим в «Импорт» и выбираем нужный файл.
- Выставляем кодировку utf8 и опцию «Коррекция кодировки».
- Нажимаем «Выполнить».
- Вот и всё таблицы в UTF-8. Не забываем, что нужно еще установить кодировку соединения, сконвертировать ваши скрипты и шаблоны в UTF-8, выставить правильную кодировку в заголовках.
Кодировка соединения
Не забываем, что после исправлений кодировки, нужно убедиться, что ваши скрипты используют правильную кодировку соединения (в принципе, это будет сразу видно, они будут неправильно показывать русские символы без нужной кодировки соединения). У некоторых она выставляется в настройках, в некоторых придется добавить самостоятельно.
Для чего достаточно пройтись поиском по файлам, и найти где вызывается функция mysql_connect (или mysqli_connect). После этой строки нужно добавить строку которая укажет кодировку соединения.
mysql_query("SET NAMES 'cp1251'");Где вместо cp1251, указать нужную кодировку соединения.
Не забывайте перед преобразованиями кодировок делать бэкап, тут как с презервативами, лучше пусть он будет и не понадобится, чем когда понадобится — его не будет.
P.S. Спасибо Шортикам за веселый контент для примеров.
ZEL-Услуги
»Пресс-центр
»Статьи
»В MySQL знаки вопросов вместо русских букв — решение проблемы с кодировкой
26.04.2019

При переносе дампа или после нескольких манипуляций в базе неожиданно появились знаки вопросов в MySQL вместо русских букв? Это известная и распространённая проблема в MySQL старших версий.
Это руководство поможет предпринять быстрые шаги в исправлении ситуации.
Мы рассмотрим конкретные действия для быстрого решения. Обратите внимание на официальное руководство по кодировке в MySQL, чтобы вы смогли разбираться в сути и выполнять рекомендации осознанно.

Исправляем знаки вопросов в MySQL на русские буквы
Воспользуйтесь этими быстрыми рекомендациями, чтобы отобразить русские буквы без знаков вопросов и «крякозябр». Ниже мы привели некоторые уточнения.
-
Дождитесь выполнения соединения с сервером
-
Введите запрос:
set names кодировка«кодировка» — это параметр кодировки, в которой вы выводите данные страницы на сайте.
То есть запрос для UTF-8 должен выглядеть так:
set names utf8А для Windows-1251 вот так:
set names cp1251 -
Очень часто параметр «Set Names» не помогает решить проблему кодировке при сортировке по имени, хотя буквы отображаются нормально. Как это исправить, читайте далее.
Обратите внимание, что запросы «set names» по факту не влияют на кодировку, которая используется функцией mysql_real_escape_string. Поэтому рекомендуется применять установку кодировки через mysql_set_charset() вместо запроса «set names». Но даже если вы проигнорируете эту рекомендацию, то для Uta8 и других однобайтных кодировок ничего плохого не последует.
Чтобы не задавать кодировку в каждом скрипте, допишите в my.ini
[mysqld]
init-connect=’SET NAMES utf8′

Исправление проблемы кодировки MySQL, если запрос SET NAMES не помог
Перед тем, как изменить кодировку MySQL, вновь выполните запрос «Set Names», но уже с указанием кодировки таблицы (мы должны её выяснить).
-
Причина кроется в том, что для таблиц настройка в одной кодировке, а данные в них — в другой.
-
Попробуйте начать с простого решения — того же запроса «Set Names», но в кодировке таблицы.
-
Для этого задайте запрос для названия вашей таблицы: show create table `table`
-
Используйте полученную кодировку в запросе «Set Names»:
SET NAMES кодировка
«кодировка» — это параметр, который показал результат запроса «Show Create Table» из пункта 3 (DEFAULT CHARSET=кодировка). -
Так вы уберёте «крякозябры» и знаки вопросов из MySQL, настроите правильную отдачу и запись русских букв в данных (главное, чтобы у самой веб-страницы была соответствующая кодировка), но проблему сортировки и поиска пока не решите. Идём дальше.
Теперь, зная кодировку таблицы (например, latin1) и имея данные в той же кодировке, мы должны изменить фактическую кодировку данных.
-
Через mysqldump создайте дамп базы данных.
-
Используйте эту команду, в которой вместо слова «кодировка» вставьте параметр, выясненный из кодировки таблицы:
mysqldump -uUSERNAME -pPASSWORD DB_NAME —allow-keywords —create-options —complete-insert —default-character-set=кодировка —add-drop-table > dump.sql -
Главное не перепутать кодировку таблиц с кодировкой данных.
-
Проверьте дамп на правильное отображение кодировки уже в формате данных таблицы, а не самой таблицы, как в пункте 3 (то есть уже не latin1, а utf8, например). Скопируйте бэкап дампа отдельно.
-
В дампе найдите оператор «Create Database» и проверьте, правильная ли в нём кодировка.
-
Если нет, то исправьте. Тоже самое можно (и лучше сделать) с оператором «Create Table».
-
Используйте эту команду для заливки дампа, где «кодировка» — параметр данных таблицы (utf8, а не latin1 из нашего примера):
mysql -uUSERNAME -pPASSWORD DB_NAME —default-character-set=utf8 < dump.sql -
На веб-странице сайта найдите функцию mysql_connect, затем mysql_select_db и ниже их размещения добавьте строчку, где «кодировка» — это параметр данных таблицы, а не самой таблицы:
mysql_query(«SET NAMES кодировка»)

Ничего не помогает, проблема кодировки MySQL так и осталась
Объёмный wiki-раздел по кодировке MySQL составили белорусские коллеги, где вы можете получить исчерпывающее описание процесса правильного создания баз данных и таблиц. Ведь именно в этом процессе кроются все причины возникновения проблемы со знаками вопросов MySQL и «крякозябрами» вместо русских букв.
Также обратите внимание и на эти моменты при работе с базами данных
- правильная ли задана кодировка при создании таблиц (можно использовать любую, но она должна отражать кодировку данных в таблице);
- правильная ли кодировка у скрипта, работающего с базой данных (кодировка веб-страницы и скрипта должна быть одной);
- правильная ли кодировка у самого сайта (у веб-страницы и заголовка «Content-Type» сайта она должна быть общая);
- в правильной ли кодировке сохраняются данные на веб-странице через редактор (выберите в редакторе нужную кодировку, следите за этим).
![]() Компания ZEL-Услуги
Компания ZEL-Услуги
Не хотите самостоятельно разбираться в настройке MySQL и оптимизировать работу ИТ-инфраструктуры предприятия? Передайте заботы о программном обеспечении в компанию ИТ-аутсорсинга с полноценным ИТ-аудитом и экспертной поддержкой по любым техническим вопросам и задачам.
Читайте также
- Мал бизнес, да удал: какие технологии сейчас помогают автоматизировать повторяющиеся задачи?
- Перестройка бизнес-коммуникаций: технологии, которые влияют на бизнес и приносят пользу прямо сейчас!
- Интернет-технологии в малом бизнесе — страх начинающих предпринимателей
- Интернет в оборот: 5 инсайдерских техносекретов в запуске малого бизнеса [2023]
- Азбука малого бизнеса: кибербезопасность, защита от фишинга, обучение сотрудников
Может быть интересно
- Онлайн конструктор тарифов
- Цены и тарифы на ИТ-аутсорсинг
- Абонентское обслуживание компьютеров
- ИТ-директор
- Настройка и обслуживание серверов
-
Помощь -
Хостинг -
Базы данных -
Как изменить кодировку для всех таблиц в MySQL
Вы установили MySQL, создали таблицы и наполнили их данными, а в ответ отображается «абракадабра»? Дело в неправильно указанной кодировке. Для того чтобы данные отображались корректно, нужно изменить параметр кодировки для каждой таблицы.
В базе данных могут быть сотни таблиц, поэтому воспользуйтесь следующим решением для оперативной смены кодировок:
-
1.
Войдите в phpMyAdmin и выберите необходимую базу данных из списка, кликнув по её названию:
-
2.
В столбце «Сравнение» отображается сопоставление кодировки базы данных:
-
3.
Скопируйте запрос ниже:
SELECT CONCAT('ALTER TABLE `', t.`TABLE_SCHEMA`, '`.`', t.`TABLE_NAME`, '` CONVERT TO CHARACTER SET нужная_кодировка COLLATE сопоставление;') as sqlcode FROM `information_schema`.`TABLES` t WHERE 1 AND t.`TABLE_SCHEMA` = 'имя_базы' ORDER BY 1где:
-
нужная_кодировка — кодировка, которую нужно применить;
-
сопоставление — сопоставление кодировки базы данных (шаг 2 — столбец «Сравнение»);
-
имя_базы — имя базы данных.
-
- 4.
-
5.
Вставьте запрос из шага 3 в окно запроса MySQL и выполните его, нажав Вперёд. В примере ниже мы сформировали список запросов для всех таблиц базы данных, который нужно выполнить, чтобы изменить кодировку на utf8 и на сопоставление кодировки utf8_general_ci.
-
6.
В качестве ответа на запрос появится список запросов для смены кодировки каждой таблицы. Раскройте вкладку Параметры, установите чекбокс напротив пункта Полные тексты и нажмите Вперёд:
- 7.
-
8.
Вернитесь на вкладку SQL. Вставьте запросы в окно запроса MySQL и нажмите Вперёд:
Готово, вы успешно изменили кодировку во всех таблицах базы данных.
Спасибо за оценку!
Как мы можем улучшить статью?
Нужна помощь?
Напишите в службу поддержки!
January 5, 2013
Posted by:
gaHcep
Category:
MySQL, Unicode
Сегодня речь пойдет о MySQL и о настройке UTF8 кодировки по-умолчанию.
Тема заезжена, но как я убедился за прошедшую неделю, мало кто в состоянии нормально пояснить какие параметры и куда надо прописать для полноценной работы с UTF8 в MySQL. К сожалению, ситуация на тематических блогах оставляет желать лучшего. Основной тип ответа — приведение соедржимого конфигурационного файла с комментарием типа “попробуй, у меня это работает”.
Основная цель данного поста — выяснить, какие параметры и с какими значениями следует прописать в конфигурационный файл my.cnf (my.ini) для дальнейшей беспроблемной работы с Юникодом.
Рабочее окружение
UTF8 на данный момент у меня успешно работает в Мастер-Слейв конфигурации:
- MySQL версии 5.1.66
- Два сервера CentOS версии 6.3
- Репликация между серверами Master-Slave на базе SSL
Любой внешний клиент в состоянии корректно работать с UTF8 базой (проверено на EMS Manager for MySQL c Windows 8 x64).
Все опции и настройки я привожу для версии сервера 5.1.x, однако с минимальными (а то и вовсе без оных) изменениями все это будет работать и на версиях 5.5.x и 5.6.x.
Параметры кодировок MySQL
Довольно часто приходится видеть в ответах на вопросы о настройке UTF8 следующее:
[mysqld]
init_connect='SET collation_connection = utf8_general_ci'
init_connect='SET NAMES utf8'
default-character-set=utf8
character-set-server=utf8
collation-server=utf8_general_ci
skip-character-set-client-handshake
Предполагается, что после вставки всего этого добра (тут кстати есть противоречащие друг другу опции) в конфигурационный файл my.cnf (my.ini) магический Юникод начнет работать.
Но давайте забудем о списке и попытаемся разбираться со всеми опциями сами и начнем с самого начала. То есть с документации. Потому как все это прекрасно описано в документации MySQL на официальном сайте. Я лишь постараюсь последовательно рассказать о параметрах сервера и прояснить неясные моменты.
Главный раздел по описанию кодировок (character sets) и их представлений (collations — используется например при сортировке) в контексте сервера, базы, таблиц — это секция 10.1.3. Specifying Character Sets and Collations.
Символьная кодировка может быть задана для:
- сервера,
- базы данных,
- таблицы и
- колонок в таблице.
Сделано это для гибкой настройки баз данных и доступа клиентов с разными кодировками. Однако, последнее не входит в область рассмотрения данного поста, поэтому будем рассматривать вариант с кодировкой UTF8 настроенной для всего по-умолчанию.
Все параметры могут быть переданы серверу тремя разными способами:
- через командную строку mysqld
- через конфигурационный файл my.cnf (my.ini)
- через опции компиляции.
Второй и третий варианты рассматриваться не будут. Тут уместно будет просто прочитать официальные доки — в каждом разделе приведены примеры конфигурации с использованием всех трех способов. Я же буду использовать первый вариант.
Кодировка (character set) и представление (collation) сервера
Секция 10.1.3.1. Server Character Set and Collation
Кодировка (characher set) — набор используемых символов.
Представление (collation) — набор правил для сравнения символов в наборе.
Тут есть несколько фундаментальных вещей которые надо понимать.
Основные параметры используемые в контексте сервера — это character_set_server и collation_server. Оба параметра влияют на определение кодировки и отображения сервера MySQL.
Можно задать оба параметра либо только один из них. При этом важно знать как задача того или иного влияет на определение отсутствующего:
-
Не заданы — используются значения по умолчанию (дефолтные),
-
Заданы оба — используются указанные кодировка и ее представление,
-
Задана только кодировка — ее представление выставляется по умолчанию для данного типа кодировки. Что это значит? Для каждого типа кодировки есть ее дефолтное представление, например, дефолтная кодировка сервера —
latin1, а дефолтное отображение для нее —latin1_swedish_ci.
Посмотреть соответствие кодировки и ее дефолтного представления можно используя команду:SHOW COLLATION LIKE ‘your_character_set_name’;
Пример:
mysql> SHOW COLLATION LIKE ‘latin1%’;
+-------------------+---------+----+---------+----------+---------+ | Collation | Charset | Id | Default | Compiled | Sortlen | +-------------------+---------+----+---------+----------+---------+ | latin1_german1_ci | latin1 | 5 | | Yes | 1 | | latin1_swedish_ci | latin1 | 8 | Yes | Yes | 1 | | latin1_danish_ci | latin1 | 15 | | Yes | 1 | | latin1_german2_ci | latin1 | 31 | | Yes | 2 | | latin1_bin | latin1 | 47 | | Yes | 1 | | latin1_general_ci | latin1 | 48 | | Yes | 1 | | latin1_general_cs | latin1 | 49 | | Yes | 1 | | latin1_spanish_ci | latin1 | 94 | | Yes | 1 | +-------------------+---------+----+---------+----------+---------+
Поле Default дает ответ о представлении выбранной кодировки.
В нашем случае, при настройке дефолтной кодировки в UTF8, параметры должны быть определены, так как могут быть использованы при определении кодировки или представления базы данных:
Наши команды:
my.cnf (my.ini)
[mysqld]
character-set-server = utf8
collation-server = utf8_unicode_ci
Дефолтное представление для utf8 — utf8_general_ci, так что если бы мы его использовали вместо utf8_unicode_ci, то параметр collation_server можно было бы вообще опустить.
Кодировка (character set) и представление (collation) базы данных
Секция 10.1.3.2. Database Character Set and Collation
Секция 10.1.4. Connection Character Sets and Collations
Тут есть два варианта определения кодировки и представления:
-
явно — при выполнении запроса на создание базы данных:
CREATE DATABASE db_name CHARACTER SET latin1 COLLATE latin1_swedish_ci;
-
неявно через переменные
character_set_databaseиcollation_database.
Однако, эти переменные нельзя задать явно ни в командной строке ни в конфигурационном файле. Как они инициализируются — чуть ниже.
Вообще при работе с базой данных огромную роль помимо серверных настроек играют настройки клиент-серверного соединения (connection). На этом этапе вступают в игру следующие специфичные для соединения параметры:
character_set_client— кодировка в которой посылается запрос от клиентаcharacter_set_connection— кодировка используемая для конвертации пришедшего запроса (statement’а)character_set_results— кодировку, в которую сервер должен перевести результат перед его отправкой клиенту
Есть еще представление кодировки соединения (colation_connection). Для чего нужен этот параметр думаю пояснять не надо.
Озадачиваться проблемой инициализации всех этих переменных не стоит (хотя в нашем случае присвоить им значения необходимо).
Есть способ проще: существует два типа запросов (statements) которые задают настройки соединения клиента с сервером группой:
Запрос SET NAMES ‘charset_name’ [COLLATE ‘collation_name’]
Параметр определяет в какой кодировке теперь будут приходить сообщения для сервера от клиента. Прелесть в том, что запрос SET NAMES x эквивалентен следующей группе:
SET character_set_client = x;
SET character_set_results = x;
SET character_set_connection = x;
Для определении представления кодировки соединения (colation_connection) отличного от дефолтного, следует дополнить запрос:
SET NAMES x COLLATE y
А так как у нас utf8 и ее дефолтное представление utf8_general_ci, то нам нужно выпонить полный запрос:
SET NAMES utf8 COLLATE utf8_unicode_ci
Таким образом, используя только этот запрос, можно добиться корректной UTF8 инициализации соединения.
Однако, тут есть один нюанс:
SET NAMES x, как понятно из определения, определяет настройку клиента при коннекте к серверу. Но что делать, если клиент — сам mysql.exe и нам хочется установить collation_connection по-умолчанию, не выполняя каждый раз SET NAMES x при коннекте?
Для этих целей, существует еще один параметр — default_character_set.
Он эквивалентен запросу SET NAMES utf8. В случае его использования задать collation_connection отличный от дефолтного уже не получится, поэтому придется заюзать еще одну команду init_connect (так как напрямую collation_connection нельзя прописать в конфигурационном файле):
init_connect=‘SET collation_connection = utf8_unicode_ci’
Но и тут есть еще одно но: init_connect команда не выполняется для SUPER пользователей — пользователей, обладающих привилегией SUPER. root входит в этот перечень, поэтому при коннекте root’ом команду SET collation_connection = utf8_unicode_ci все же придется выполнить вручную.
Запрос SET CHARACTER SET charset_name
Запрос групповой и он также эквивалентен следующей группе:
SET character_set_client = x;
SET character_set_results = x;
SET collation_connection = @@collation_database;
Согласно документации, разница между двумя запросами в том, что параметры character_set_connection и collation_connection будут установлены на @@character_set_database и @@collation_database соответственно (выше я про них упоминал).
За более детальной информацией отсылаю по двум источникам — собственно к официальной документации и прекрасно оформленному ответу на stackoverflow.com.
Для нашей задачи вполне хватает первого параметра вместе с дополнительной командой.
Подытожим: различные сценарии и что юзается на каждом из них — относительно к настройкам соединения:
- Если к базе коннектится mysql.exe клиент с пользователем с привилегией SUPER:
- срабатывает опция в конфигурационном файле
default_character_set = utf8 - надо выполнить вручную команду
init_connect='SET collation_connection = utf8_unicode_ci'
- срабатывает опция в конфигурационном файле
- Если к базе коннектится mysql.exe клиент с пользователем без привилегии SUPER:
- срабатывает опция в конфигурационном файле
default_character_set = utf8 - срабатывает команда в конфигурационном файле
init_connect='SET collation_connection = utf8_unicode_ci'
- срабатывает опция в конфигурационном файле
- Если к базе коннектится внешний клиент:
- надо выполнить вручную команду
SET NAMES utf8 COLLATE utf8_unicode_ci
- надо выполнить вручную команду
Наши команды:
my.cnf (my.ini)
[client]
default_character_set = utf8[mysqld]
init_connect=‘SET collation_connection = utf8_unicode_ci’
Кодировка (character set) и представление (collation) таблиц
Секция 10.1.3.3. Table Character Set and Collation
Тут все довольно просто. Задать кодировку и ее представление можно через команды:
CREATE TABLE t1 ( … )
CHARACTER SET utf8 COLLATE utf8_unicode_ci;
Тут главное иметь в виду, что если эти настройки не заданы, то берутся настройки базы данных (см. пред. раздел). Нам эти настройки не интересны.
Кодировка (character set) и представление (collation) колонок в таблице
Секция 10.1.3.4. Column Character Set and Collation
Тут по аналогии с пред. секцией. Если параметры кодировок не указаны, берутся те, что указывались для таблицы.
Прежде чем перейти к след. разделу, должен сказать, что все команды и запросы относятся к указанной версии MySQL и в случае возникновения каких-либо проблем советую обратиться к соответствующей версии документации.
skip-character-set-client-handshake
Помимо освещенных параметров, есть еще один довольно часто фигурирующий в разного рода источниках — skip-character-set-client-handshake. Установка этого параметра позволит проигнорировать информацию клиента о кодировке. Я данный параметр не использовал.
Верификация настроек
Итак, вот финальный snapshot наших изменений в файле my.cnf (my.ini):
[mysqld]
init_connect=‘SET collation_connection = utf8_unicode_ci’
character-set-server = utf8
collation-server = utf8_unicode_ci[client]
default-character-set = utf8
После применения всех опций и рестарта сервера mysql для проверки настроек можно воспользоваться командами SHOW VARIABLES LIKE 'char%' и SHOW VARIABLES LIKE 'collation%';
Состояние среды до изменений:
mysql> SHOW VARIABLES LIKE'character%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | latin1 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
mysql> SHOW VARIABLES LIKE 'collation%';
+----------------------+-------------------+
| Variable_name | Value |
+----------------------+-------------------+
| collation_connection | latin1_swedish_ci |
| collation_database | latin1_swedish_ci |
| collation_server | latin1_swedish_ci |
+----------------------+-------------------+
Состояние среды после изменений (в случае, если вы приконнектились не SUPER пользователем):
mysql> SHOW VARIABLES LIKE 'character%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
mysql> SHOW VARIABLES LIKE 'collation%';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_unicode_ci |
| collation_database | utf8_unicode_ci |
| collation_server | utf8_unicode_ci |
+----------------------+-----------------+
Для примера, вот отличие при соединении через mysql.exe пользователем с и без привилегии SUPER:
с привилегией:
mysql> SHOW VARIABLES LIKE 'collation%';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | **utf8_general_ci** |
| collation_database | utf8_unicode_ci |
| collation_server | utf8_unicode_ci |
+----------------------+-----------------+
с привилегией и выполненной вручную командой ‘SET collation_connection = utf8_unicode_ci’:
mysql> SHOW VARIABLES LIKE 'collation%';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_unicode_ci |
| collation_database | utf8_unicode_ci |
| collation_server | utf8_unicode_ci |
+----------------------+-----------------+
без привилегии:
mysql> SHOW VARIABLES LIKE 'collation%';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_unicode_ci |
| collation_database | utf8_unicode_ci |
| collation_server | utf8_unicode_ci |
+----------------------+-----------------+
Поздравляю, теперь ваши база, таблицы и все в таблицах по-умолчанию в кодировке UTF8.
Ссылки
- Официальное руководство MySQL версии 5.1
- Отличие utf8_unicode_ci от utf8_general_ci
- “MySQL Character Set Support” на informit.com позволит вам больше узнать о том что есть characher set и collation.
« Previous Blog Post | Back to top | Next Blog Post »
comments powered by Disqus
-
Доступные статьи
-
MySQL
-
Кодировки в MySQL
Работа с кодировками в MySQL 4.1.11 и выше
- Тестовая машина
- Устанавливаем MySQL
- Начало работы
- Разумные выводы
- Настройка кодировок
- Через names
- Через системные переменные
- Через настройки сервера
- Что делать, если данные внесены в неправильной кодировке
- Правильный вариант работы с MySQL
Полезность первоисточника информации трудно переоценить, поэтому не поленитесь и скачайте полный мануал от разработчиков MySQL — http://dev.mysql.com/doc/
Тестовая машина
test# uname -a FreeBSD test.dm 7.0-RELEASE FreeBSD 7.0-RELEASE #1: Fri May 9 15:40:21 YEKST 2008 zg@test.dm:/usr/obj/usr/src/sys/GATE i386 test#
Устанавливаем MySQL 5.1
test# pkg_add -r mysql51-server Fetching ftp://ftp.freebsd.org/pub/FreeBSD/ports/i386/ packages-7.0-release/Latest/mysql51-server.tbz... Done. Fetching ftp://ftp.freebsd.org/pub/FreeBSD/ports/i386/ packages-7.0-release/All/mysql-client-5.1.22.tbz... Done. Added group "mysql". Added user "mysql". ************************************************************************ Remember to run mysql_upgrade (with the optional --datadir=<dbdir> flag) the first time you start the MySQL server after an upgrade from an earlier version. ************************************************************************ test# echo mysql_enable="YES" >> /etc/rc.conf test# cp /usr/local/share/mysql/my-large.cnf /etc/my.cnf test# /usr/local/etc/rc.d/mysql-server start Starting mysql. test# sockstat | grep mysql mysql mysqld 1154 13 tcp4 *:3306 *:* mysql mysqld 1154 14 stream /tmp/mysql.sock test#
Пускай это не самый «правильный» способ установки MySQL-сервера, зато быстрый и рабочий.
Начало работы
Итак, sockstat показала, что сервер работает, а установка говорит о том, что сервер абсолютно девственный. Чем это грозит? Кодировки по умолчанию выставлены англоязычные, а значит, будут проблемы при использовании кирилицы. Но как это распознать? Проверяем:
test# mysql Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 2 Server version: 5.1.22-rc-log FreeBSD port: mysql-server-5.1.22 Type 'help;' or 'h' for help. Type 'c' to clear the buffer. mysql> use test; Database changed mysql> create table `test` (`field` VARCHAR(60)); Query OK, 0 rows affected (0.01 sec) mysql> insert into `test` values ('иван'), ('родил'), ('девчёнку'); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql>
Первым делом используем тестовую базу, которая уже есть на сервере, затем создаём в ней таблицу и вставляем в неё три слова на русском, про кодировки мы пока ничего не знаем и знать не хотим ))).
Пока всё хорошо и радужно, никаких ошибок нет, пробуем сделать выборку:
mysql> select * from `test`; +----------+ | field | +----------+ | иван | | родил | | девчёнку | +----------+ 3 rows in set (0.01 sec) mysql> select * from `test` where `field` like "иван"; +-------+ | field | +-------+ | иван | +-------+ 1 row in set (0.00 sec)
Как видно, запросы работают абсолютно корректно, так где же грабли?… Оказывается мы на них уже стоим:
mysql> select * from `test` order by `field` DESC; +----------+ | field | +----------+ | девчёнку | | родил | | иван | +----------+ 3 rows in set (0.01 sec)
Запрос на выборку с обратной сортировкой привёл к тому, что записи просто вывелись в обратном порядке, но не по алфавиту… До удара граблей остаются считанные секунды, но пока растянем удовольствие  Сперва ответим на вопрос — почему поля не сортируются по алфавиту? У MySQL имеется мощный и богатый механизм для работы с интернациональными наборами символов, но.. но откуда MySQL узнает, что наши символы — есть русский алфавит, мы же качали английскую версию? Ничего не остаётся, как идти ковырять мануал на предмет кодировок…
Сперва ответим на вопрос — почему поля не сортируются по алфавиту? У MySQL имеется мощный и богатый механизм для работы с интернациональными наборами символов, но.. но откуда MySQL узнает, что наши символы — есть русский алфавит, мы же качали английскую версию? Ничего не остаётся, как идти ковырять мануал на предмет кодировок…
После того, как загрузился 16-метровый мануал, можно не полениться и прочитать первые пару-тройку страниц с оглавлением )), а можно просто сделать поиск на предмет charset или character set. Не суть важно, но через некоторое время можно найти раздел 9.1.2. Character Sets and Collations in MySQL, в котором написано много и интересно, а, главное, содержательно про то, каким образом можно и нужно работать с кодировками.
Расставляя точки над и, Character Set — транслируется как «кодировка», а Collation — сравнение. В чём разница? Сравнение — это правила сравнения букв кодировки. Сравнения работают только в рамках кодировки, и нельзя сравнивать данные в латинице по правилам кирилицы. Поясню на примере: мы, как увидим позже, внесли данные в таблицу на латинице, а сортировать нужно на кирилице, для чего можно использовать ключевое слово collate:
mysql> select * from `test` order by `field` collate cp1251_general_ci DESC; ERROR 1253 (42000): COLLATION 'cp1251_general_ci' is not valid for CHARACTER SET 'latin1' mysql>
MySQL отказывается это делать… но почему? Потому, что latin1 не поддерживает сравнение в кирилице, а доступные «сравнения» можно увидеть так:
mysql> show collation like 'latin1%'; +-------------------+---------+----+---------+----------+---------+ | Collation | Charset | Id | Default | Compiled | Sortlen | +-------------------+---------+----+---------+----------+---------+ | latin1_german1_ci | latin1 | 5 | | Yes | 1 | | latin1_swedish_ci | latin1 | 8 | Yes | Yes | 1 | | latin1_danish_ci | latin1 | 15 | | Yes | 1 | | latin1_german2_ci | latin1 | 31 | | Yes | 2 | | latin1_bin | latin1 | 47 | | Yes | 1 | | latin1_general_ci | latin1 | 48 | | Yes | 1 | | latin1_general_cs | latin1 | 49 | | Yes | 1 | | latin1_spanish_ci | latin1 | 94 | | Yes | 1 | +-------------------+---------+----+---------+----------+---------+ 8 rows in set (0.00 sec) mysql>
Ни о какой кирилице не может идти и речи… Куда копать?.. В создание таблицы!
mysql> show create table `test`; +-------+-------------------------------------------------+ | Table | Create Table | +-------+-------------------------------------------------+ | test | CREATE TABLE `test` ( `field` varchar(60) DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=latin1 | +-------+-------------------------------------------------+ 1 row in set (0.00 sec)
Ага! По-умолчанию при создании таблицы была взята кодировка latin1, значит, если мы изменим таблицу и укажем ей, что надо использовать кирилистическую кодировку, то всё заработает?… В мануале написан пример про изменение кодировки таблицы, используем его:
mysql> alter table `test` charset "cp1251"; Query OK, 3 rows affected (0.02 sec) Records: 3 Duplicates: 0 Warnings: 0
Ок! Проверяем, что получилось…
mysql> select * from `test` order by `field` collate cp1251_general_ci DESC; ERROR 1253 (42000): COLLATION 'cp1251_general_ci' is not valid for CHARACTER SET 'latin1'
Хм.. опять та же ошибка, но откуда ей взяться?!..
mysql> show create table `test`; +-------+-------------------------------------------------+ | Table | Create Table | +-------+-------------------------------------------------+ | test | CREATE TABLE `test` ( `field` varchar(60) CHARACTER SET latin1 DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=cp1251 | +-------+-------------------------------------------------+ 1 row in set (0.00 sec)
Ого, структура таблицы резко изменилась, теперь у неё задана одна кодировка, а у поля совсем другая.. :(( Порыв ещё мануал, можно изменить и кодировку столбца:
mysql> alter table `test` modify `field` varchar(60) charset "cp1251"; Query OK, 3 rows affected, 3 warnings (0.02 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> show create table `test`; +-------+------------------------------------------+ | Table | Create Table | +-------+------------------------------------------+ | test | CREATE TABLE `test` ( `field` varchar(60) DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=cp1251 | +-------+------------------------------------------+ 1 row in set (0.01 sec)
Ну вот!!! Злой кодировки latin1 нет и в помине, можно проверять наш роддом )))
mysql> select * from `test` order by `field` collate cp1251_general_ci DESC; +----------+ | field | +----------+ | ???????? | | ????? | | ???? | +----------+ 3 rows in set (0.00 sec)
И вот тот страшный удар граблями, который так долго оттягивался! Внимательный читатель мог заметить, что когда была сделана попытка принудительно сменить кодировку столбца, содержащего данные в latin1, то на каждую запись, содержащую русские буквы, у MySQL был варнинг! Это был крик о том, что сервер не знает, каким образом можно перевести данные из latin1 в cp1251, ну и лучшего способа, чем заменить символы не latin1 вопросиками, он не нашёл :))). Роддом безвозвратно потерян потому, что теперь вместо кирилицы в базе содержатся вопросики..
Вопросиков можно было избежать
На самом деле, ситуация, когда изначально выставлена неправильная кодировка, встречается сплошь и рядом. Симптомы можно выявить следующим образом:
mysql> show variables like "char%"; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | latin1 | | character_set_connection | latin1 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | latin1 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/local/share/mysql/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.02 sec)
Именно эти переменные отвечают за дефолтные значения кодировок.
character_set_client— кодировка, в которой данные будут поступать от клиентаcharacter_set_connection— кодировка по умолчанию для всего, что в рамках соединения не имеет кодировкиcharacter_set_database— кодировка по умолчанию для базcharacter_set_filesystem— кодировка для работы с файловой системой (LOAD DATA INFILE, SELECT … INTO OUTFILE, и т.д.)character_set_results— кодировка, в которой будет выбран результатcharacter_set_server— кодировка, в которой работает серверcharacter_set_system— кодировка, в которой задаются идентификаторы MySQL, всегда UTF8character_sets_dir— папка с кодировками
ВАЖНО: Если character_sets_dir установлена неверно, то работа с кодировками будет под угрозой. Не пытайтесь менять её значение, если вы неуверены в своих силах. Если вы системный администратор, то перед установкой лучше ознакомиться с мануалом.
Наиболее значимые для простых пользователей следующие переменные: character_set_client, character_set_results, character_set_connection. Поскольку именно они отвечают за внесение, извлечение информации и создание таблиц/баз соответственно. Какими они могут быть?
mysql> SHOW CHARACTER SET; +----------+-----------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+-----------------------------+---------------------+--------+ | dec8 | DEC West European | dec8_swedish_ci | 1 | | cp850 | DOS West European | cp850_general_ci | 1 | | hp8 | HP West European | hp8_english_ci | 1 | | koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 | | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 | | swe7 | 7bit Swedish | swe7_swedish_ci | 1 | | ascii | US ASCII | ascii_general_ci | 1 | | hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 | | koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 | | greek | ISO 8859-7 Greek | greek_general_ci | 1 | | cp1250 | Windows Central European | cp1250_general_ci | 1 | | latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 | | armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 | | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | cp866 | DOS Russian | cp866_general_ci | 1 | | keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 | | macce | Mac Central European | macce_general_ci | 1 | | macroman | Mac West European | macroman_general_ci | 1 | | cp852 | DOS Central European | cp852_general_ci | 1 | | latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 | | cp1251 | Windows Cyrillic | cp1251_general_ci | 1 | | cp1256 | Windows Arabic | cp1256_general_ci | 1 | | cp1257 | Windows Baltic | cp1257_general_ci | 1 | | binary | Binary pseudo charset | binary | 1 | | geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 | +----------+-----------------------------+---------------------+--------+ 26 rows in set (0.00 sec)
Любую из этих кодировок можно пользовать на свой вкус. Обычно русскоязычные пользователи предпочитают cp1251 или utf8, но по сути, неважно, в какой кодировке хранятся данные, важно, чтобы она была изначально правильно указана и данные были корректно внесены.
Настройка кодировок
Мануал предлагает нам три варианта задания кодировок:
- Через names
- Через непосредственно переменные character_set_*
- Через настройки самого сервера
ВНИМАНИЕ!!! Первые два варианта работают только в рамках текущего соединения. Это значит, что при следующем подключении все настройки вернутся в начальное состояние! Чтобы не выставлять кодировку каждый раз, нужно воспользоваться третьим вариантом.
Вариант 1 — Через names
mysql> set names 'cp1251'; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | cp1251 | | character_set_connection | cp1251 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | cp1251 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/local/share/mysql/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.02 sec)
Ну, тут всё ясно, три самые нужные кодировки в одном )))
Вариант 2 — Через непосредственно переменные character_set_*
mysql> set @@character_set_client='cp1251'; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | cp1251 | | character_set_connection | latin1 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | latin1 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/local/share/mysql/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.01 sec)
Более детальная настройка, чем names.
Вариант 3 — Через настройки самого сервера
Тут можно пойти двумя путями — либо через конфиг файл:
---- Файл my.cnf [client] # Для местного клиента default-character-set=cp1251 .... [mysqld] # Для всего сервера default-character-set=cp1251 ....
либо
shell> mysqld --character-set-server=cp1251
Ещё можно при конфигурировании задать кодировку по умолчанию
shell> ./configure --with-charset=latin1
Но лучше, когда кодировка настраивается прямо в соединении.
Что делать, если данные внесены в неправильной кодировке
Если база/таблица/данные были созданы/внесены в кодировке отличной от нужной, то необходимо сделать следующее:
- Создать бэкап базы данных
- Создать текстовый дамп базы в SQL-запросах (mysqldump или PhpMyAdmin)
- С помощью текстового редактора исправить вхождения неверной кодировки на нужную (а лучше попросту удалить всю информацию о кодировках и сравнениях)
- Удалить базу/таблицу
- Выставить нужную кодирвку на клиента/соединение
- Импортировать данные исправленного SQL-дампа
Этот вариант подходит почти для всех случаев, за исключением некоторых особых ситуаций, например, когда сравнение, выставленное по-умолчанию, не уместно для некоторых полей. Пример — поле для хранения пароля, необходимо сравнивать его с учётом регистра, тогда как по-умолчанию выставляется сравнение без учёта регистра.
mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | latin1 | | character_set_connection | latin1 | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | latin1 | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/local/share/mysql/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.02 sec) ## Кодировки выставлены неверно, нужно их настроить mysql> set names 'koi8r'; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | koi8r | | character_set_connection | koi8r | | character_set_database | latin1 | | character_set_filesystem | binary | | character_set_results | koi8r | | character_set_server | latin1 | | character_set_system | utf8 | | character_sets_dir | /usr/local/share/mysql/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.02 sec) ## Я работаю через koi8r, поэтому и выставляю её, ## но данные в таблице буду хранить в cp1251 mysql> create table `test2` (`field` varchar(60)) charset cp1251; Query OK, 0 rows affected (0.01 sec) ## Проверяем, всё ли в порядке mysql> show create table `test2`; +-------+--------------------------------------------+ | Table | Create Table | +-------+--------------------------------------------+ | test2 | CREATE TABLE `test2` ( `field` varchar(60) DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=cp1251 +-------+--------------------------------------------+ 1 row in set (0.01 sec) ## Вносим данные mysql> insert into `test2` values ('и раз'), ('Два'),('три'), ('И ять'), ('шесть'); Query OK, 5 rows affected (0.01 sec) Records: 5 Duplicates: 0 Warnings: 0 ## Проверяем сортировки ## В обычном сравнении "И" и "и" одинаковы, поэтому ## сравнение идёт до первого отличного символа mysql> select * from `test2` order by `field` collate cp1251_general_ci ASC; +-------+ | field | +-------+ | Два | | и раз | | И ять | | три | | шесть | +-------+ 5 rows in set (0.01 sec) ## В бинарном сравнении "И" меньше чем "и", поскольку у неё код меньше mysql> select * from `test2` order by `field` collate cp1251_bin ASC; +-------+ | field | +-------+ | Два | | И ять | | и раз | | три | | шесть | +-------+ 5 rows in set (0.00 sec)
Таким образом, клиент работает в KOI8-R, но данные хранятся в cp1251, MySQL знает об этом и делает перекодировку на лету.
Ну и на посошок:
mysql> set character_set_results='cp1251'; Query OK, 0 rows affected (0.00 sec) mysql> select * from `test2`; +-------+ | field | +-------+ | Х ПЮГ | | дБЮ | | РПХ | | х ЪРЭ | | ЬЕЯРЭ | +-------+ 5 rows in set (0.00 sec)
Выбирать данные можно в любой кодировке, так же, как и вносить, главное — правильно сообщить об этом MySQL.
Mysql поддерживает много кодировок и это нередко является головной болью для программистов. Самая частая проблема — кракозяблы вместо русского текста. Это происходит из за того, что текст либо лежит на сервере, либо отдается клиенту в неверной кодировке. Последнее(а иногда и первое) решается проще всего. Устанавливаем кодировку соединения (в utf8 в примере) сразу после установления соединения
|
mysql_set_charset(‘utf8’); // или mysql_query(‘SET NAMES «utf8″‘); |
Хуже, когда скрипт отдает в базу, данные в верной кодировке, а в ответ получаем кракозяблы или вопросики. Или когда часть таблиц в верной кодировке, часть нет.. В таких случаях придется разбираться детально.
|
mysql_query(«SHOW VARIABLES LIKE ‘char%'» ); /* character_set_client: latin1 character_set_connection: latin1 character_set_database: utf8 character_set_filesystem: binary character_set_results: latin1 character_set_server: cp1251 character_set_system: utf8 character_sets_dir: usrlocalmysql-5.1sharecharsets */ |
Этот запрос обязательно проверять в самом скрипте, а не в phpmyadmin, где могут быть установлены другие параметры
character_set_client— кодировка, в которой данные будут поступать от клиентаcharacter_set_connection— по умолчанию для всего, что в рамках соединения не имеет кодировкиcharacter_set_database— кодировка по умолчанию для базcharacter_set_filesystem— кодировка для работы с файловой системой (LOAD DATA INFILE, SELECT … INTO OUTFILE, и т.д.)character_set_results— кодировка, в которой будет выбран результатcharacter_set_server— кодировка, в которой работает серверcharacter_set_system— идентификаторы MySQL, всегда UTF8character_sets_dir— папка с кодировками
По умолчанию после установки mysql сервер, который устанавливается ленивым хостеромадмином имеет кодировку latin1. Соответственно указанные выше глобальные переменные будут в latin1. Базы соответственно по умолчанию и таблицы так же. И именно на это стоит обратить в самом начале обратить внимание, чтобы проблемы не всплывали позднее.
В идеальном варианте, нам следуетпривести все отмеченные цветом кодировки к единому значению. Тогда мы просто будем избавлены от мелких ошибок с кодировкой. Фактически, если мы работаем с хостингом, то на (3) и (6) мы повлиять не сможем. Но и это не страшно если настроены остальные три параметра. Mysql умет перекодировать на лету если правильно настроена кодировка соединения.
Ну и наконец, основной вопрос, что делать если одна из mysql таблиц(или несколько) в неверной кодировке и на сайте видны кракозяблывопросики?
1. Выяснить кодировку таблицы.
|
mysql > SHOW CREATE TABLE `files` ————————————————————————— CREATE TABLE `files` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `iNode` int(10) unsigned NOT NULL, `pid` int(10) unsigned NOT NULL, `sName` varchar(128) CHARACTER SET latin1 COLLATE latin1_general_ci NOT NULL, `sTitle` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, PRIMARY KEY (`id`), KEY `iNode` (`iNode`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 |
В этой таблице поле sName в кодировке latin1, если у нас соединение в другой кодировке, то мы увидим кракозябры.
2. Поэтому дальше проверим кодировку соединения, sql запросом SHOW VARIABLES LIKE ‘character_set_client’. Замечу, что php функция mysqli_client_encoding(), нам не подойдет, так как она отображает кодировку только на момент соединения.
3. Если кодировка соединения не совпала с кодировкой одного из полей таблицы, то 2 очевидных варианта.
Если у нас все таблицы в одной кодировке, то проще поменять кодировку соединения .
А как исправить неверную кодировку поля таблицы?
Для этого выполним 2 запроса
|
ALTER TABLE files CHANGE sName sName BLOB; ALTER TABLE files CHANGE sName sName VARCHAR(128) CHARACTER SET utf8; |
Нельзя обойтись только вторым запросом. Важно выполнить оба. Первый преобразовывает данные в двоичные, второй запрос, преобразовывает данные в строковые сменив кодировку.. Т.е. по сути мы не измениили двоичные данные, мы изменили правило формирования символов. Если бы мы попробовали обойтись только вторым запросом, то получили бы ошибочный набор.
Автор: Fix Xxer (PHP Club)
У MySQL версии 4.1 и выше (далее 4.1+) с русскими буквами бывают несколько проблем — рассмотрим их по отдельности.
1. PHP использует неверную кодировку в качестве клиентской.
Симптомы:
- Через phpMyAdmin (здесь и далее подразумевается версия умеющая работать с кодировками, т.е. >= 2.6.0) все по-русски, а в скрипт приходят вопросительные знаки.
- Скрипт, заносящий данные в базу, видит русский нормально, а после вставки, как в правильном скрипте, так и в phpMyAdmin-е — знаки вопросов.
Тестирование:
Попробуйте в начале вашего скрипта, но после соединения, выполнить SQL-запрос «SET NAMES кодировка». Где кодировка — та кодировка, в которой у вас (по вашему мнению) данные. Например, для русской Windows кодировки (windows-1251) это будет cp1251, для KOI8-R – koi8r, для UTF-8 – utf8 и так далее. В дальнейшем она будет упоминаться как «кодировка».
Результат тестирования:
- Если буквы (но необязательно слова) стали русскими, значит, данные в базе лежат в правильной кодировке, сама база эту самую кодировку и использует.
- Если буквы стали русскими, а слова нет («бнопня»), значит, скрипт ожидает данные в другой русской кодировке — пробуйте другие, пока не получится русских слов.
Решение:
1) Оставить запрос «SET NAMES кодировка» в начале скрипта. Если скриптов много – см. вариант 2.
2) Заставить MySQL автоматически выполнять этот запрос при каждом соединении с ним.
Для этого необходимо в конфигурационном файле MySQL, в секции [mysqld] добавить следующую строку: init-connect=»SET NAMES кодировка».
Однако, следует заметить, что это НЕ будет работать, если пользователь, которым вы подключаетесь к базе имеет привилегию SUPER (а стандартный пользователь root к таким относится, так же как и все созданные через «GRANT ALL PRIVILEGES ON *.* TO …»). Это сделано для того, чтобы в случае ошибки в этом запросе (а его можно изменить во время работы), хоть кто-то мог подключиться к базе и исправить его.
Внимание! Функция mysqli_client_encoding() и сотоварищи, отображает кодировку клиента на момент соединения и не меняют возвращаемое значение в процессе работы. Поэтому не стоит кричать, что кодировка не меняется. Просто делайте, что говорят и смотрите результат работы скрипта. Получить нужное значение можно SQL-запросом «SHOW VARIABLES LIKE ‘character_set_client'».
3) Начиная с версий 4.1.15 и 5.0.13 добавить в секцию [mysqld] или [server] конфигурационного файла MySQL параметр skip-character-set-client-handshake. Этот параметр заставляет сервер игнорировать кодировку, посылаемую клиентом, и использовать указанную серверу. В примере конфигурации ниже этот параметр уже есть.
2. MySQL использует неверную кодировку
Симптомы:
Русский текст приходит в скрипт как русский, в консольном клиенте тоже все хорошо. Однако не работает сортировка, перевод в верхний/нижний регистр и т.д. Если применить решение из проблемы №1, то либо русский текст становится вопросами, либо mysql_error() возвращает сообщение похожее на «Illegal mix of collations (latin1_general_ci,IMPLICIT) and (cp1251_general_ci,COERCIBLE)…». В тоже время phpMyAdmin русский текст отображает как «крокозябры» (латинские символы с умляутами и т.д.).
Тестирование:
Попробуйте в phpMyAdmin’е выполнить запрос вида «SELECT CONVERT(CONVERT(поле USING binary) USING кодировка) FROM таблица». Где «таблица» и «поле» — соответствующая таблица и поле с русским текстом, а «кодировка» — кодировка из проблемы №1.
Результат тестирования:
- Если буквы (но необязательно слова) стали русскими, значит текст в базе лежал не в правильной кодировке и его нужно сконвертировать.
- Если буквы стали русскими, а слова нет («бнопня»), значит неверно выбрана одна из русских кодировок – пробуйте другие, пока не получится русских слов.
Решение:
1) Установить для MySQL нужную кодировку по умолчанию.
Внимание! Это решение сработает сработает, только если кодировки не переопределены для базы, таблицы или столбца.
Для этого нужно в конфигурационном файле MySQL в секции [mysqld] добавить следующую строку:
default-character-set=cp1251
2) Сконвертировать таблицы в нужную кодировку.
Про то как конвертировать таблицы с неверными кодировками хорошо написано в мануале MySQL. Повторять здесь то же самое не к чему.
Дополнительно:
Наша справка:
Конфигурационный файл MySQL — применяется для записи и хранения параметров программ MySQL, что исключает необходимость ввода этих параметров в командной строке при каждом вызове программы. Все определенные в конфигурационном файле параметры могут перекрываться параметрами, заданными в командной строке. В ОС UNIX в качестве конфигурационного файла используется my.cnf, в ОС Windows используется my.ini. Найти конфигурационный файл можно в корневой директории MySQL (см. местоположение конфигурационного файла MySQL). Внутри конфигурационных файлов параметры распределены по группам. Например:
[client]
user=sampadm
password=secret
[mysqld]
port = 3306
socket = /tmp/mysql.sock
Названия групп заключаются в квадратные скобки и обычно соответствуют именам программ. Так, например, группа [mysqld] (в ранних версиях mysql — [server]) соответствует программе mysqld, являющейся сервером MySQL, который обеспечивает клиентским программам доступ к базам данных.