В этой статье пример оптимального, на мой взгляд, кода для файла robots.txt под WordPress, который вы можете использовать в своих сайтах.
Для начала, вспомним зачем нужен robots.txt — файл robots.txt нужен исключительно для поисковых роботов, чтобы «сказать» им какие разделы/страницы сайта посещать, а какие посещать не нужно. Страницы, которые закрыты от посещения не будут попадать в индекс поисковиков (Yandex, Google и т.д.).

Закрыть страницу от робота можно также через мета-тег robots или в HTTP-заголовке ответаX-Robots-Tag. Преимущество файла robots.txt в том, что робот при посещении сайта сначала загружает все правила из файла robots.txt и опираясь на них ходит по страницам сайта исключая из посещения страницы, URL которых не подходит под правила.
Таким образом, если мы закрыли страницу в robots.txt, робот просто пропустит её не сделав никаких запросов на сервер. А если мы закрыли страницу в заголовке X-Robots-Tag или мета-теге, роботу нужно сначала сделать запрос к серверу, получить ответ, посмотреть что находится в заголовке или метатеге и только потом принять решения индексировать страницу или нет.
Таким образом, файл robots.txt объясняет роботу какие страницы (URL) сайта нужно просто пропускать не делая никаких запросов. Это экономит время обхода роботом всех страниц сайта и экономит ресурсы сервера.
Рассмотрим на примере. Допустим, у нас есть сайт на котором всего 10 000 страниц (не 404 URL). Из них полезных страниц с уникальным контентом всего 3000, остальное это архивы по датам, авторам, страницы пагинации и другие страницы контент на которых дублируется (например фильтры с GET параметрами). Допустим, мы хотим закрыть от индексации эти 7000 неуникальных страниц:
- если сделать это через robots.txt, то роботу для индексации всего сайта нужно будет посетить всего 3000 страниц остальное будет отсеяно сразу же на уровне URL.
- если сделать это через мета-тег robots, то роботу для индексации всего сайта нужно будет посетить все 10 000 страниц сайта. Потому что нужно получить контент страницы, чтобы узнать что находится в мета-теге (в котором указано что страницу индексировать не нужно).
Несложно догадаться, что в этом случае первый вариант гораздо предпочтительнее потому что на обход сайта робот будет тратить гораздо меньше времени, а сервер будет генерировать гораздо меньше страниц.
Оптимальный код robots.txt для WordPress
Важно понимать, что ниже приведен универсальный пример кода для файла robots.txt. Для каждого конкретного сайта его нужно расширять или вносить корректировки. И лучше не трогайте ничего если не понимаете что делаете — обращайтесь к знающим людям.
Версия 1 (не строгая)
Эта версия, пожалуй, более предпочтительна по сравнению со второй, потому что тут нет опасности запретить индексацию каких либо файлов внутри ядра WordPress или папки wp-content.
User-agent: * # Создаем секцию правил для роботов. * значит для всех # роботов. Чтобы указать секцию правил для отдельного # робота, вместо * укажите его имя: GoogleBot, Yandex. Disallow: /cgi-bin # Стандартная папка на хостинге. Disallow: /wp-admin/ # Закрываем админку. Allow: /wp-admin/admin-ajax.php # Откроем аякс. Disallow: /? # Все параметры запроса на главной. Disallow: *?s= # Поиск. Disallow: *&s= # Поиск. Disallow: /search # Поиск. Disallow: /author/ # Архив автора. Disallow: */embed$ # Все встраивания. Disallow: */xmlrpc.php # Файл WordPress API Disallow: *utm*= # Ссылки с utm-метками Disallow: *openstat= # Ссылки с метками openstat # Одина или несколько ссылок на карту сайта (файл Sitemap). Это независимая # директива и дублировать её для каждого User-agent не нужно. Так например # Google XML Sitemap создает 2 карты сайта: Sitemap: http://example.com/sitemap.xml Sitemap: http://example.com/sitemap.xml.gz # Версия кода: 2.0 # Не забудьте поменять `example.com` на ваш сайт.
Версия 2 (строгая)
В этом варианте мы контролируем все доступы. Сначала глобально запрещаем доступ к почти всему от WP (Disallow: /wp-), а затем открываем, там где нужно.
Этот код я пожалуй не рекомендовал бы, потому что тут закрывается все от wp- и нужно будет описать все что разрешено. Так в будущем, когда WP введет что-то новое, это новое может стать недоступно для роботов. Так например получилось с картой сайта WP.
User-agent: * # Создаем секцию правил для роботов. * значит для всех # роботов. Чтобы указать секцию правил для отдельного # робота, вместо * укажите его имя: GoogleBot, Yandex. Disallow: /cgi-bin # Стандартная папка на хостинге. Disallow: /wp- # Все связанное с WP - это: /wp-content /wp-admin # /wp-includes /wp-json wp-login.php wp-register.php. Disallow: /wp/ # Каталог куда установлено ядро WP (если ядро установлено # в подкаталог). Если WP установлен стандартно, то # правило можно удалить. Disallow: /? # Все параметры запроса на главной. Disallow: *?s= # Поиск. Disallow: *&s= # Поиск. Disallow: /search # Поиск. Disallow: /author/ # Архив автора. Disallow: */embed$ # Все встраивания. Disallow: */xmlrpc.php # Файл WordPress API Disallow: *utm*= # Ссылки с utm-метками Disallow: *openstat= # Ссылки с метками openstat Allow: */wp-*/*ajax*.php # AJAX запросы: */admin-ajax.php */front-ajaxs.php Allow: */wp-sitemap # карта сайта (главная и вложенные) Allow: */uploads # открываем uploads Allow: */wp-*/*.js # внутри /wp- (/*/ - для приоритета) Allow: */wp-*/*.css # внутри /wp- (/*/ - для приоритета) Allow: */wp-*/*.png # картинки в плагинах, cache папке и т.д. Allow: */wp-*/*.jpg # картинки в плагинах, cache папке и т.д. Allow: */wp-*/*.jpeg # картинки в плагинах, cache папке и т.д. Allow: */wp-*/*.gif # картинки в плагинах, cache папке и т.д. Allow: */wp-*/*.svg # картинки в плагинах, cache папке и т.д. Allow: */wp-*/*.webp # файлы в плагинах, cache папке и т.д. Allow: */wp-*/*.swf # файлы в плагинах, cache папке и т.д. Allow: */wp-*/*.pdf # файлы в плагинах, cache папке и т.д. # Секция правил закончена # Одна или несколько ссылок на карту сайта (файл Sitemap). Это независимая # директива и дублировать её для каждого User-agent не нужно. Так например # Google XML Sitemap создает 2 карты сайта: Sitemap: http://example.com/wp-sitemap.xml Sitemap: http://example.com/wp-sitemap.xml.gz # Версия кода: 2.0 # Не забудьте поменять `example.com` на ваш сайт.
В правилах Allow: вы можете видеть дополнительные, казалось бы ненужные, знаки * — они нужны для увеличения приоритета правила. Зачем это нужно смотрите в сортировке правил.
Директивы (разбор кода)
- Google doc по robots.txt.
- Yandex doc по robots.txt
- User-agent:
-
Определяет для какого робота будет работать блок правил, который написан после этой строки. Тут возможны два варианта:
-
User-agent: *— указывает, что правила после этой строки будут работать для всех поисковых роботов. User-agent: ИМЯ_РОБОТА— указывает конкретного робота, для которого будет работать блок правил. Например:User-agent: Yandex,User-agent: Googlebot.
Возможные роботы (боты) Яндекса:
Yandex робот проверяет наличие записей, начинающихся с
User-agent:, в них учитываются подстрокиYandex(регистр значения не имеет) или*. Если обнаружена строкаUser-agent: Yandex, то строкаUser-agent: *не учитывается. Если строкиUser-agent: YandexиUser-agent: *отсутствуют, считается, что доступ роботу не ограничен.Yandex— любой робот Яндекса.YandexImages— Индексирует изображения для показа на Яндекс Картинках.YandexMedia— Индексирует мультимедийные данные.YandexDirect— Скачивает информацию о контенте сайтов-партнеров Рекламной сети Яндекса, чтобы уточнить их тематику для подбора релевантной рекламы.YandexDirectDyn— Скачивает файл фавиконки сайта для отображения в результатах поиска.YandexBot— Основной индексирующий робот.YandexAccessibilityBot— Скачивает страницы для проверки их доступности пользователям. Его максимальная частота обращений к сайту составляет 3 обращения в секунду. Робот игнорирует настройку в интерфейсе Яндекс Вебмастера.YandexAdNet— Робот Рекламной сети Яндекса.YandexBlogs— Робот поиска по блогам, индексирующий комментарии постов.YandexCalendar— Робот Яндекс Календаря. Скачивает файлы календарей по инициативе пользователей, которые часто располагаются в запрещенных для индексации каталогах.YandexDialogs— Отправляет запросы в навыки Алисы.YaDirectFetcher— Скачивает целевые страницы рекламных объявлений для проверки их доступности и уточнения тематики. Это необходимо для размещения объявлений в поисковой выдаче и на сайтах-партнерах.. Робот не использует файл robots.txt, поэтому игнорирует директивы, установленные для него.YandexForDomain— Робот почты для домена, используется при проверке прав на владение доменом.YandexImageResizer— Робот мобильных сервисов.YandexMobileBot— Определяет страницы с версткой, подходящей под мобильные устройства.YandexMarket— Робот Яндекс Маркета.YandexMetrika— Робот Яндекс Метрики. Скачивает страницы сайта для проверки их доступности, в том числе проверяет целевые страницы объявлений Яндекс Директа. Робот не использует файл robots.txt, поэтому игнорирует директивы, установленные для него.YandexMobileScreenShotBot— Делает снимок мобильной страницы.YandexNews— Робот Яндекс Новостей.YandexOntoDB— Робот объектного ответа.YandexOntoDBAPI— Робот объектного ответа, скачивающий динамические данные.YandexPagechecker— Обращается к странице при валидации микроразметки через форму Валидатор микроразметки.YandexPartner— Скачивает информацию о контенте сайтов-партнеров ЯндексаYandexRCA— Собирает данные для формирования превью. Например, для расширенного отображения сайта в поиске.YandexSearchShop— Скачивает YML-файлы каталогов товаров (по инициативе пользователей), которые часто располагаются в запрещенных для индексации каталогах.YandexSitelinks— Проверяет доступность страниц, которые используются в качестве быстрых ссылок.YandexSpravBot— Робот Яндекс Бизнеса.YandexTracker— Робот Яндекс Трекера.YandexTurbo— Обходит RSS-канал, созданный для формирования Турбо-страниц. Его максимальная частота обращений к сайту составляет 3 обращения в секунду. Робот игнорирует настройку в интерфейсе Яндекс Вебмастера и директиву Crawl-delay.YandexUserproxy— Проксирует действия пользователей на сервисах Яндекса: отправляет запросы в ответ на нажатие кнопок, скачивает страницы для перевода онлайн и т. д.YandexVertis— Робот поисковых вертикалей.YandexVerticals— Робот Яндекс Вертикалей: Авто.ру, Янекс.Недвижимость, Яндекс Работа, Яндекс Отзывы.YandexVideo— Индексирует видео для показа в поиске Яндекса по видео.YandexVideoParser— Индексирует видео для показа в поиске Яндекса по видео.YandexWebmaster— Робот Яндекс Вебмастера.
- Полный список роботов Яндекса.
Возможные роботы (боты) Google:
Googlebot— основной индексирующий робот.Googlebot-Image— индексирует изображения.Mediapartners-Google— робот отвечающий за размещение рекламы на сайте. Важен для тех, у кого крутится реклама от AdSense. Благодаря этому user-agent вы можете управлять размещение рекламы запрещая или разрешая её на тех или иных страницах.- Полный список роботов Google.
-
- Disallow:
-
Запрещает роботам «ходить» по ссылкам, в которых встречается указанная подстрока:
Disallow: /cgi-bin— закрывает каталог скриптов на сервере.Disallow: *?s=— закрывает страницы поиска.Disallow: */page/— закрывает все виды пагинации.Disallow: */embed$— закрывает все URL заканчивающиеся на/embed.
Пример добавления нового правила. Допустим нам нужно закрыть от индексации все записи в категории news. Для этого добавляем правило:
Disallow: /news
Оно запретить роботам ходить по ссылками такого вида:
http://example.com/newshttp://example.com/news/drugoe-nazvanie/
Если нужно закрыть любые вхождения /news, то пишем:
Disallow: */news
Закроет:
- http://example.com/news
- http://example.com/my/news/drugoe-nazvanie/
- http://example.com/category/newsletter-nazvanie.html
Подробнее изучить директивы robots.txt вы можете на странице помощи Яндекса. Имейте ввиду, что не все правила, которые описаны там, работают для Google.
ВАЖНО о кириллице: роботы не понимают кириллицу, её им нужно предоставлять в кодированном виде. Например:
Disallow: /каталог # неправильно. Disallow: /%D0%BA%D0%B0%D1%82%D0%B0%D0%BB%D0%BE%D0%B3 # правильно.
- Allow:
- В строке
Allow: */uploadsмы намеренно разрешаем индексировать страницы, в которых встречается/uploads. Это правило обязательно, т.к. выше мы запрещаем индексировать страницы начинающихся с/wp-, а /wp- входит в /wp-content/uploads. Поэтому, чтобы перебить правилоDisallow: /wp-нужна строчкаAllow: */uploads, ведь по ссылкам типа /wp-content/uploads/… у нас могут лежать картинки, которые должны индексироваться, так же там могут лежать какие-то загруженные файлы, которые незачем скрывать.
Allow:может быть расположена «до» или «после»Disallow:. При чтении правил роботы их сначала сортируют, затем читают, поэтому не имеет значения в каком месте находитсяAllow:,Disallow:. Подробнее о сортировке смотрите ниже. - Sitemap:
- Правило
Sitemap: http://example.com/sitemap.xmlуказывает роботу на файл с картой сайта в формате XML. Если у вас на сайте есть такой файл, то пропишите полный путь к нему. Таких файлов может быть несколько, тогда нужно указать путь к каждому файлу отдельно.
ВАЖНО: Сортировка правил
Yandex и Google обрабатывает директивы Allow и Disallow не по порядку в котором они указаны, а сначала сортирует их от короткого правила к длинному, а затем обрабатывает последнее подходящее правило:
User-agent: * Allow: */uploads Disallow: /wp-
будет прочитана как:
User-agent: * Disallow: /wp- Allow: */uploads
Таким образом, если проверяется ссылка вида: /wp-content/uploads/file.jpg, правило Disallow: /wp- ссылку запретит, а следующее правило Allow: */uploads её разрешит и ссылка будет доступна для сканирования.
Чтобы быстро понять и применять особенность сортировки, запомните такое правило: «чем длиннее правило, тем больший приоритет оно имеет. Если длина правил одинаковая, то приоритет отдается директиве Allow.»
Проверка robots.txt и документация
Проверить правильно ли работают правила можно по следующим ссылкам:
- Яндекс: http://webmaster.yandex.ru/robots.xml.
-
Google: https://www.google.com/webmasters/tools/robots-testing-tool Нужна авторизация и наличия сайта в панели веб-мастера.
- Яндекс документация robots.txt.
-
Google документация robots.txt
- Сервис для создания файла robots.txt: http://pr-cy.ru/robots/
- Сервис для создания и проверки robots.txt: https://seolib.ru/tools/generate/robots/
robots.txt в WordPress
В WordPress запрос на страницу /robots.txt обрабатывается отдельно и для него «налету» через PHP создается контент файла robots.txt. Поэтому не рекомендуется физически создавать файл robots.txt в корне сайта! Потому что при таком подходе никакой плагин или код не сможет нормально изменить этот файл, а вот динамическое создание контента для страницы /robots.txt позволит гибко его изменять.
Изменить содержание robots.txt можно через:
- Плагин https://ru.wordpress.org/plugins/pc-robotstxt/ или ему подобный.
- Хук robots_txt.
- Хук do_robotstxt.
Рассмотрим как использовать оба хука.
robots_txt
По умолчанию WP 5.5 создает следующий контент для страницы /robots.txt:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: http://example.com/wp-sitemap.xml
Смотрите do_robots() — как работает динамическое создание файла robots.txt.
Этот хук позволяет дополнить уже имеющиеся данные файла robots.txt. Код можно вставить в файл темы functions.php.
// Дополним базовый robots.txt
// -1 before wp-sitemap.xml
add_action( 'robots_txt', 'wp_kama_robots_txt_append', -1 );
function wp_kama_robots_txt_append( $output ){
$str = '
Disallow: /cgi-bin # Стандартная папка на хостинге.
Disallow: /? # Все параметры запроса на главной.
Disallow: *?s= # Поиск.
Disallow: *&s= # Поиск.
Disallow: /search # Поиск.
Disallow: /author/ # Архив автора.
Disallow: */embed # Все встраивания.
Disallow: */page/ # Все виды пагинации.
Disallow: */xmlrpc.php # Файл WordPress API
Disallow: *utm*= # Ссылки с utm-метками
Disallow: *openstat= # Ссылки с метками openstat
';
$str = trim( $str );
$str = preg_replace( '/^[t ]+(?!#)/mU', '', $str );
$output .= "$strn";
return $output;
}
В результате перейдем на страницу /robots.txt и видим:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Disallow: /cgi-bin # Стандартная папка на хостинге. Disallow: /? # Все параметры запроса на главной. Disallow: *?s= # Поиск. Disallow: *&s= # Поиск. Disallow: /search # Поиск. Disallow: /author/ # Архив автора. Disallow: */embed # Все встраивания. Disallow: */page/ # Все виды пагинации. Disallow: */xmlrpc.php # Файл WordPress API Disallow: *utm*= # Ссылки с utm-метками Disallow: *openstat= # Ссылки с метками openstat Sitemap: http://example.com/wp-sitemap.xml
Обратите внимание, что мы дополнили родные данные ВП, а не заменили их.
do_robotstxt
Этот хук позволяет полностью заменить контент страницы /robots.txt.
add_action( 'do_robotstxt', 'wp_kama_robots_txt' );
function wp_kama_robots_txt(){
$lines = [
'User-agent: *',
'Disallow: /wp-admin/',
'Disallow: /wp-includes/',
'',
];
echo implode( "rn", $lines );
die; // обрываем работу PHP
}
Теперь, пройдя по ссылке http://site.com/robots.txt увидим:
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/
Рекомендации
Не рекомендуется исключать фиды: Disallow: */feed
Потому что наличие открытых фидов требуется, например, для Яндекс Дзен, когда нужно подключить сайт к каналу (спасибо комментатору «Цифровой»). Возможно открытые фиды нужны где-то еще.
Фиды имеют свой формат в заголовках ответа, благодаря которому поисковики понимают что это не HTML страница, а фид и, очевидно, обрабатывают его иначе.
Ошибочные рекомендации
-
Прописывание Sitemap после каждого User-agent
Это делать не нужно. Один sitemap должен быть указан один раз в любом месте файла robots.txt. -
Закрыть папки wp-content, wp-includes, cache, plugins, themes
Это устаревшие требования. Однако подобные советы я находил даже в статье с пафосным названием «Самые правильный robots для WordPress 2018»! Для Яндекса и Google лучше будет их вообще не закрывать. Или закрывать «по умному», как это описано выше (Версия 2). -
Закрывать страницы тегов и категорий
Если ваш сайт действительно имеет такую структуру, что на этих страницах контент дублируется и в них нет особой ценности, то лучше закрыть. Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика -
Прописать Crawl-Delay
Модное правило. Однако его нужно указывать только тогда, когда действительно есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей. - Ляпы
Некоторые правила я могу отнести только к категории «блогер не подумал». Например: Disallow: /20 — по такому правилу не только закроете все архивы, но и заодно все статьи о 20 способах или 200 советах, как сделать мир лучше

Спорные рекомендации
-
Закрывать от индексации страницы пагинации
/page/
Это делать не нужно. Для таких страниц настраивается тегrel="canonical", таким образом, такие страницы тоже посещаются роботом и на них учитываются расположенные товары/статьи, а также учитывается внутренняя ссылочная масса. -
Комментарии
Некоторые ребята советуют закрывать от индексирования комментарииDisallow: /commentsиDisallow: */comment-*. -
Открыть папку uploads только для Googlebot-Image и YandexImages
User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/
Совет достаточно сомнительный, т.к. для ранжирования страницы необходима информация о том, какие изображения и файлы на ней размещены.
Источник по рекомендациям.
Нестандартные Директивы
Clean-param
Google не понимаю эту директиву. Указывает роботу, что URL страницы содержит GET-параметры, которые не нужно учитывать при индексировании. Такими параметрами могут быть идентификаторы сессий, пользователей, метки UTM, т.е. все то что не влияет на содержимое страницы.
Заполняйте директиву Clean-param максимально полно и поддерживайте ее актуальность. Новый параметр, не влияющий на контент страницы, может привести к появлению страниц-дублей, которые не должны попасть в поиск. Из-за большого количества таких страниц робот медленнее обходит сайт. А значит, важные изменения дольше не попадут в результаты поиска. Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы, в которых параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница:
example.com/dir/bookname?ref=site_1 example.com/dir/bookname?ref=site_2 example.com/dir/bookname?ref=site_3
Если указать директиву следующим образом:
User-agent: Yandex Clean-param: ref /dir/bookname
то робот Яндекса сведет все адреса страницы к одному:
example.com/dir/bookname
Пример очистки нескольких параметров сразу: ref и sort:
Clean-param: ref&sort /dir/bookname
Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. Если директив указано несколько, все они будут учтены роботом.
Crawl-delay (устарела)
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Crawl-delay: 1.5 User-agent: * Disallow: /wp-admin Disallow: /wp-includes Allow: /wp-*.gif
Google не понимает эту директиву. Таймаут его роботам можно указать в панели вебмастера.
Яндекс перестал учитывать Crawl-delay
Подробнее Яндекс перестал учитывать Crawl-delay:
Проанализировав письма за последние два года в нашу поддержку по вопросам индексирования, мы выяснили, что одной из основных причин медленного скачивания документов является неправильно настроенная директива Crawl-delay в robots.txt […] Для того чтобы владельцам сайтов не пришлось больше об этом беспокоиться и чтобы все действительно нужные страницы сайтов появлялись и обновлялись в поиске быстро, мы решили отказаться от учёта директивы Crawl-delay.
Для чего была нужна директива Crawl-delay
Когда робот сканирует сайт как сумасшедший и это создает излишнюю нагрузку на сервер. Робота можно попросить «поубавить обороты». Для этого можно использовать директиву Crawl-delay. Она указывает время в секундах, которое робот должен простаивать (ждать) для сканирования каждой следующей страницы сайта.
Host (устарела)
Google Директиву Host никогда не поддерживал, а Яндекс полностью отказывается от неё. Host можно смело удалять из robots.txt. Вместо Host нужно настраивать 301 редирект со всех зеркал сайта на главный сайт (главное зеркало).
Подробнее читайте на сайте Яндекса.
Поддерживаемые директвы от Google.
Заключение
Важно помнить, что изменения в robots.txt на уже рабочем сайте будут заметны только спустя несколько месяцев (2-3 месяца).
Ходят слухи, что Google иногда может проигнорировать правила в robots.txt и взять страницу в индекс, если сочтет, что страница ну очень уникальная и полезная и она просто обязана быть в индексе. Однако другие слухи опровергают эту гипотезу, ссылаясь на неправильный код robots.txt. Я больше склоняюсь ко второму.
Рассмотрим, зачем нужен файл robots.txt для WordPress, где он находится на хостинге и как настроить правильный robots.txt для WordPress.
Для чего нужен файл robots.txt?
Для того чтобы сайт начал отображаться в Яндекс, Google, Yahoo и других поисковых системах (ПС), они должны внести его страницы в свои каталоги. Этот процесс называется индексацией.
Чтобы проиндексировать тот или иной веб-ресурс, поисковые системы посылают на сайты поисковых роботов (иногда их называют ботами). Они методично сканируют и обрабатывают содержимое каждой страницы сайта. После окончания индексации начинается «социальная жизнь» ресурса: его контент попадается пользователям в результатах поиска по запросам.
Многие сайты создаются на готовых движках и CMS (системах управления контентом) WordPress, Joomla, Drupal и других. Как правило, такие системы содержат страницы, которые не должны попадать в поисковую выдачу:
- временные файлы (tmp);
- личные данные посетителей (private);
- служебные страницы (admin);
- результаты поиска по сайту и т. д.
Чтобы внутренняя информация не попала в результаты поиска, ее нужно закрыть от индексации. В этом помогает файл robots.txt. Он служит для того, чтобы сообщить поисковым роботам, какие страницы сайта нужно индексировать, а какие — нет. Иными словами, robots.txt — это файл, состоящий из текстовых команд (правил), которыми поисковые роботы руководствуются при индексации сайта.
Наличие robots.txt значительно ускоряет процесс индексации. Благодаря нему в поисковую выдачу не попадают лишние страницы, а нужные индексируются быстрее.
Где находится robots.txt WordPress?
Файл robots.txt находится в корневой папке сайта. Если сайт создавался на WordPress, скорее всего, robots.txt присутствует в нем по умолчанию. Чтобы найти robots.txt на WordPress, введите в адресной строке браузера:
https://www.домен-вашего-сайта/robots.txt- Если файл присутствует, откроется страница с перечнем правил индексации. Однако чтобы редактировать их, вам потребуется найти и открыть robots.txt на хостинге. Как правило, он находится в корневой папке сайта:
- Если же файл robots.txt по какой-то причине отсутствует, вы можете создать его вручную на своем компьютере и загрузить на хостинг или воспользоваться готовыми решениями (плагинами WordPress).
Как создать файл robots.txt для WordPress?
Есть два способа создания robots.txt:
-
Вручную на компьютере.
-
С помощью плагинов в WordPress.
Первый способ прост лишь на первый взгляд. После создания пустого документа и загрузки его на сайт, вы должны будете наполнить его содержанием (директивами). Ниже мы расскажем об основных правилах, однако стоит учитывать, что тонкая настройка требует специальных знаний SEO-оптимизации.
Создание robots.txt вручную
-
1.
Откройте программу «Блокнот».
-
2.
Нажмите Файл → Сохранить как… (или комбинацию клавиш Ctrl + Shift + S):
-
3.
Введите название robots.txt и нажмите Сохранить.
-
4.
Откройте корневую папку сайта и загрузите в нее созданный файл по инструкции.
Готово, вы разместили пустой файл и после этого сможете редактировать его прямо в панели управления хостингом.
Создание robots.txt с помощью плагина
-
1.
Откройте административную панель WordPress по инструкции.
-
2.
Перейдите в раздел «Плагины» и нажмите Добавить новый:
-
3.
Введите в строке поиска справа название Yoast SEO и нажмите Enter.
-
4.
Нажмите Установить → Активировать:
-
5.
Перейдите к настройкам плагина, выбрав в меню SEO → Инструменты. Затем нажмите Редактор файлов:
-
6.
Нажмите Создать файл robots.txt:
-
7.
Нажмите Сохранить изменения в robots.txt:
Готово, файл с минимальным количеством директив будет создан автоматически.
Настройка robots.txt WordPress
После создания файла вам предстоит настроить robots.txt для своего сайта. Рассмотрим основы синтаксиса (структуры) этого файла:
- Файл может состоять из одной и более групп директив (правил).
- В каждой группе должно указываться, для какого поискового робота предназначены правила, к каким разделам/файлам у него нет доступа, а к какому — есть.
- Правила читаются поисковыми роботами по порядку, сверху вниз.
- Файл чувствителен к регистру, поэтому если название раздела или файла задано капслоком (например, FILE.PDF), именно так стоит писать и в robots.txt.
- Все правила одной группы должны следовать без пропуска строк.
- Чтобы оставить комментарий, нужно прописать шарп (#) в начале строки.
Все правила в файле задаются через двоеточие. Например:
Где User-agent — команда (директива), а Googlebot — значение.
Основные директивы и их значения
User-agent — эта директива указывает, на каких поисковых роботов распространяются остальные правила в документе. Она может принимать следующие значения:
- User-agent: * — общее правило для всех поисковых систем;
- User-agent: Googlebot — робот Google;
- User-agent: Yandex — робот Яндекс;
- User-agent: Mai.ru — робот Mail.ru;
- User-agent: Yahoo Slurp — робот Yahoo и др.
У крупнейших поисковых систем Яндекс и Google есть десятки роботов, предназначенных для индексации конкретных разделов и элементов сайтов. Например:
- YandexBot — для органической выдачи;
- YandexDirect — для контекстной рекламы;
- YandexNews — для новостных сайтов и т. п.
Для решения некоторых специфических задач веб-разработчики могут обращаться к конкретным поисковым роботам и настраивать правила исключительно для них.
Disallow — это директива, которая указывает, какие разделы или страницы нельзя посещать поисковым роботам. Все значения задаются в виде относительных ссылок (то есть без указания домена). Основные правила запрета:
- Disallow: /wp-admin — закрывает админку сайта;
- Disallow: /cgi-bin — запрет индексации директории, в которой хранятся CGI-скрипты;
- Disallow: /*? или Disallow: /search — закрывает от индексации поиск на сайте;
- Disallow: *utm* — закрывает все страницы с UTM-метками;
- Disallow: */xmlrpc.php — закрывает файл с API WordPress и т. д.
Вариантов того, какие файлы нужно закрывать от индексации, очень много. Вносите значения аккуратно, чтобы по ошибке не указать контентные страницы, что повредит поисковой позиции сайта.
Allow — это директива, которая указывает, какие разделы и страницы должны проиндексировать поисковые роботы. Как и с директивой Disallow, в значении нужно указывать относительные ссылки:
- Allow: /*.css или Allow: *.css — индексировать все css-файлы;
- Allow: /*.js — обходить js-файлы;
- Allow: /wp-admin/admin-ajax.php — разрешает индексацию асинхронных JS-скриптов, которые используются в некоторых темах.
В директиве Allow не нужно указывать все разделы и файлы сайта. Проиндексируется всё, что не было запрещено директивой Disallow. Поэтому задавайте только исключения из правила Disallow.
Sitemap — это необязательная директива, которая указывает, где находится карта сайта Sitemap. Единственная директива, которая поддерживает абсолютные ссылки (то есть местоположение файла должно указываться целиком): Sitemap: https://site.ru/sitemap.xml , где site.ru — имя домена.
Также есть некоторые директивы, которые считаются уже устаревшими. Их можно удалить из кода, чтобы не «засорять» файл:
- Crawl-delay. Задает паузу в индексации для поисковых роботов. Например, если задать для Crawl-Delay параметр 2 секунды, то каждый новый раздел/файл будет индексироваться через 2 секунды после предыдущего. Это правило раньше указывали, чтобы не создавать дополнительную нагрузку на хостинг. Но сейчас мощности современных процессоров достаточно для любой нагрузки.
- Host. Указывает основное зеркало сайта. Например, если все страницы сайта доступны с www и без этого префикса, один из вариантов будет считаться зеркалом. Главное — чтобы на них совпадал контент. Раньше зеркало нужно было задавать в robots.txt, но сейчас поисковые системы определяют этот параметр автоматически.
- Clean-param. Директива, которая использовалась, чтобы ограничить индексацию совпадающего динамического контента. Считается неэффективной.
Пример robots.txt
Рассмотрим стандартный файл robots.txt, который можно скопировать и использовать для блога, заменив название домена в директиве Sitemap и убрав комментарии (текст справа, включая #):
User-agent: * # общие правила для всех поисковых роботов
Disallow: /wp-admin/ # запретить индексацию папки wp-admin (все служебные папки)
Disallow: /readme.html # закрыть доступ к стандартному файлу о программном обеспечении
Disallow: /*? # запретить индексацию результатов поиска по сайту
Disallow: /?s= # запретить все URL поиска по сайту
Allow: /wp-admin/admin-ajax.php # индексировать асинхронные JS-файлы темы
Allow: /*.css # индексировать CSS-файлы
Allow: /*.js # индексировать JS-скрипты
Sitemap: https://site.ru/sitemap.xml # указать местоположение карты сайтаКак редактировать robots.txt на WordPress?
Чтобы внести изменения в файл robots.txt, откройте его в панели управления хостингом. Используйте плагин Yoast SEO (или аналогичное решение в WordPress) для редактирования файлов:
Проверка работы файла robots.txt
Чтобы убедиться в корректности составленного файла, используйте стандартный инструмент Яндекс.Вебмастер:
- 1.
-
2.
Перейдите в раздел Инструменты → Анализ robots.txt.
-
3.
Содержимое robots.txt обновится автоматически. Нажмите Проверить:
Если в синтаксисе файла будут ошибки, Яндекс укажет, в каких строчках проблема и даст рекомендации по исправлению.
Файл robots.txt необходим роботам поисковых систем, чтобы они могли понять, какие страницы и разделы сайта следует посещать и включать в индекс, а какие – не нужно. Запрещенные для посещения поисковыми ботами страницы не будут индексироваться и появляться в выдаче Яндекса, Google и прочих поисковиков.
Вот наглядный пример того, в чем разница между веб-ресурсом, у которого настроен файл robots, и сайтом без него:
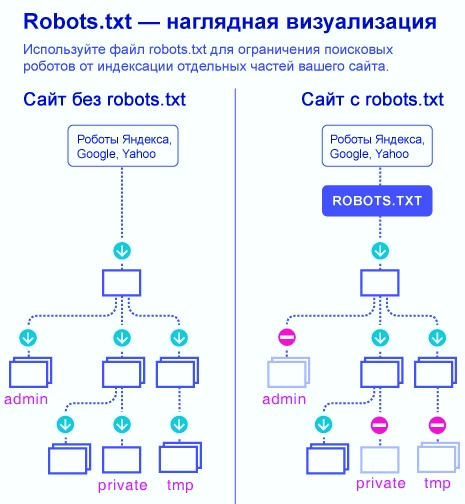
В данной статье я расскажу о нескольких способах правильной настройки robots.txt для популярного движка WordPress.
Оптимальный код файла для WordPress
User-agent: *
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /? # все параметры запроса с ?
Disallow: /*? # поиск
Disallow: /& # поиск
Disallow: /*& # поиск
Disallow: /author/ # архив автора
Disallow: /embed # все встраивания
Disallow: /page/ # все виды пагинации
Disallow: /trackback # уведомление о ссылках-трекбэках
Allow: /uploads # открываем uploads
Allow: /*.js # внутри /wp- (/*/ - для приоритета)
Allow: /*.css # внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.svg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.pdf # файлы в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php
Sitemap: https://domain.ru/sitemap.xmlСкачать .zip
Важно! Не забудьте поменять “https://domain.ru/sitemap.xml” на свой пусть к файлу sitemap.
Теперь разберем, какие директивы в коде что означают:
1. Директива User-agent: * означает, что все правила, описанные ниже нее, касаются всех роботов поисковых систем. Если вы хотите прописать правила для одного определенного бота, вместо * нужно ввести его имя. Например:
- User-agent: Googlebot – для главного робота Гугла.
- User-agent: Yandex – для главного бота Яндекса.
Подробнее о директиве User-agent
2. Строка Allow: /uploads указывается, чтобы разрешить ботам вносить в индекс страницы, где присутствует /uploads. Нужно обязательно указать данное правило, потому что выше запрещены к индексированию страницы, которые начинаются с /wp-, а проблема в том, что /uploads присутствует в /wp-content/uploads.
Команда Allow: /uploads нужна для перебивания правила Disallow: /wp-, так как по ссылкам типа /wp-content/uploads/ могут располагаться изображения, важные для индексации. Помимо картинок есть вероятность присутствия прочих файлов, которые нет нужды запрещать включать в поиск. Строчку Allow допускается прописывать и до, и после Disallow.
Подробнее о директиве Allow
3. Директивы Disallow:
запрещают ботам переходить по ссылкам, начинающимся с:
- Disallow: /trackback — закрывает уведомления
- Disallow: /s или Disallow: /*? — закрывает страницы поиска
- Disallow: /page/ — закрывает все виды пагинации
Подробнее о директиве Dissalow
4. Строчка Sitemap: http://domain.ru/sitemap.xml сообщает поисковому боту о XML файле с картой сайта. Если на вашем ресурсе присутствует данный файл, укажите к нему полный путь. Если их несколько, нужно прописать путь отдельно к каждому из них.
Рекомендуется не закрывать от индексации фиды: Disallow: /feed.
Это связано с тем, что доступ к фидам нужен, к примеру, для подключения сайта к каналу Яндекс Дзен, Турбо страниц. Могут быть еще некоторые случаи, где нужны открытые фиды. Через feed передается контент в формате .rss. Если вы не знаете что это такое, то читайте более подробную статью — что такое RSS.
У фидов собственный формат в заголовках ответа, что позволяет поисковым системам понять, что это фид, а не HTML документ, и обрабатывать его по-другому.
А если вы не хотите передавать RSS, чтобы например у вас не воровали через него контент, то тогда надежнее отключить его с помощью специальных плагинов, например Disable Feeds.
Сортировка правил перед обработкой
Google и Яндекс обрабатывают правила Disallow и Allow без соблюдения порядка, в котором они прописаны в robots.txt. Поисковики сортируют директивы от коротких к длинным, после чего обрабатывают последнюю подходящую директиву.
Например, данная инструкция:
User-agent: *
Allow: /uploads
Disallow: /wp-Поисковые системы обработают следующим образом:
User-agent: *
Disallow: /wp-
Allow: /uploadsВ случае проверки ссылки типа /wp-content/uploads/file.jpg, директива Disallow сначала
запретит ссылку с /wp-,
а затем Allow разрешит ее индексировать, поэтому ссылка будет доступна для
роботов.
На заметку.
Запомните главное при сортировке правил: чем директива в файле robots.txt длиннее, тем
она приоритетнее. Когда директивы одинаковой длины, приоритетной становится Allow.
Стандартный файл robots для WordPress
Хотя первый метод является более современным и логичным, но я все же пользуюсь вторым файлом robots.txt. Потому что мне так спокойнее, что с помощью директивы Dissalow: /wp- я не запрещу что то нужное, поэтому я прописываю каждую папку отдельно.
Исходя из вышеперечисленных правок, у меня получается вот такой robots.txt:
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-json/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /embed
Disallow: /trackback
Disallow: /page/
Disallow: /search
Disallow: /&
Disallow: /?
Disallow: /*?
Allow: /wp-admin/admin-ajax.php
Sitemap: http://domain.ru/sitemap.xmlСкачать .zip
Важно! Не забудьте поменять “https://domain.ru/sitemap.xml” на свой пусть к файлу sitemap.
Доработка файла под свои цели
Если потребуется заблокировать еще какие-то страницы или разделы веб-ресурса, добавьте директиву Disallow. К примеру, желая скрыть от роботов все публикации в рубрике News, пропишите правило:
Disallow: /newsТак вы запретите ботам переходить по ссылкам типа http://domain.ru/news и закроете от индексации такие страницы:
- http://domain.ru/news;
- http://domain.ru/my/news/nazvanie/;
- http://domain.ru/category/newsletter-nazvanie.html.
Постоянно проверяйте, какие страницы проиндексированы поисковыми системами и находятся в выдаче. Сделать это можно с помощью оператора site:domain.ru.
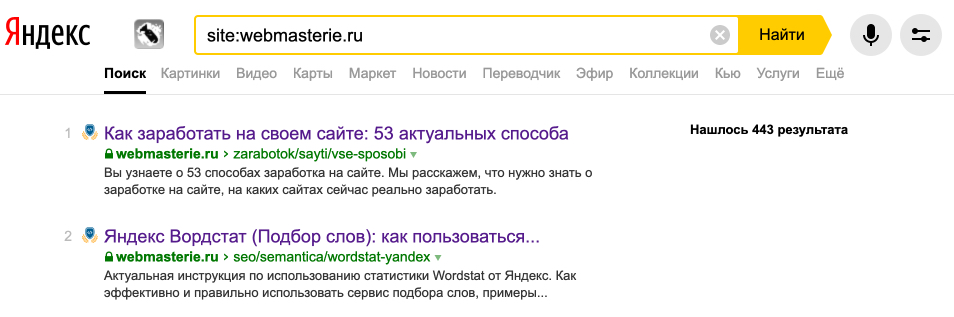
И если заметили мусорные, ненужные страницы, то блокируйте их в robots.txt.
Проверка файла и документация
Проверить корректность директив, прописанных в robots.txt, вы можете по ссылкам:
- Google Search Console https://www.google.com/webmasters/tools/dashboard?pli=1. Необходимо зарегистрировать сайт в панели вебмастера, если вы этого еще не сделали.
- Яндекс: http://webmaster.yandex.ru/robots.xml.
- Сервис для создания и проверки файла robots: https://seolib.ru/tools/generate/robots/.
- Сервис для создания robots.txt: http://pr-cy.ru/robots/.
- Документация Яндекса: https://yandex.ru/support/webmaster/controlling-robot/robots-txt.html.
- Документация Google: https://developers.google.com/search/reference/robots_txt.
Подробнее о проверке файла robots.txt
Динамический robots.txt
В CMS Вордпресс обработка запроса на файл robots производится
отдельно. Вебмастеру нет нужды самостоятельно создавать в корневом каталоге
сайта файл robots. Это
не то что можно не делать, но и нужно, иначе плагины не смогут изменять
созданный вебмастером файл, когда в этом появится необходимость.
Для изменения содержания динамического robots налету,
через хук do_robotstxt, добавьте данный код
в файл funtcions.php:
add_action( 'do_robotstxt', 'my_robotstxt' );
function my_robotstxt(){
$lines = [
'User-agent: *',
'Disallow: /wp-admin/',
'Disallow: /wp-includes/',
'',
];
echo implode( "rn", $lines );
die; // обрываем работу PHP
}При переходе по ссылке http://example.com/robots.txt вы
увидите следующий код:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/Заключение
Обязательно следите за актуальностью своего robots.txt. Проверяйте страницы на индексацию, чтобы там не было мусорных, не нужных страниц. Если такие заметили, то блокируйте их. При внесении изменений в файл robots.txt для уже рабочего веб-сайта результат будет видно не раньше, чем через 2-3 месяца.
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Всем, привет! Сегодня небольшой пост — как автоматически создать файл robots.txt для WordPress? Друзья, вы можете создать правильный robots.txt для WordPress в пару кликов, прочитав данное руководство. Создание правильного файла robots.txt для WordPress очень важно. Благодаря ему поисковые системы будут знать, какие страницы индексировать и показывать в поиске. То есть, результаты поиска будут именно такими, как вам нужно, без дублирования страниц WordPress.

Читайте, дамы и господа — WordPress robots.txt: лучшие примеры для SEO.
WordPress robots.txt где лежит/находится? По умолчанию WordPress автоматически создает виртуальный файл robots.txt для вашего сайта. Таким образом, даже если вы ни чего не делали, на вашем сайте ВордПресс уже должен быть файл robots.txt. Вы можете проверить, так ли это, добавив /robots.txt в конец вашего доменного имени. Например, так https://ваш сайт/robots.txt

Поскольку этот файл является виртуальным, вы не можете его редактировать. Однако, если вы хотите отредактировать свой файл robots.txt WordPress как надо, вам необходимо создать физический файл на вашем хостинге. Создайте свой правильный robots.txt для WordPress, который вы сможете легко редактировать по мере необходимости.
Как создать файл robots.txt для WordPress
Robots.txt — это текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем.
Файл robots.txt сообщает поисковым роботам, какие страницы или файлы на вашем сайте можно или нельзя обрабатывать.
Яндекс и Google
Для начала напомню вам, создать (и редактировать) файл robots.txt для WordPress можно вручную и с помощью плагина Yoast SEO

Друзья, имейте ввиду, что Yoast SEO устанавливает свои правила по умолчанию, которые перекрывают правила существующего виртуального файла robots.txt ВордПресс:

Что должно быть в правильно составленного robots.txt? Идеального файла не существует. Например, сайт Yoast SEO использует такой robots.txt для WordPress:
User-agent: *И всё. Для большинства сайтов WordPress лучший пример. Вот даже скриншот сделал у Yoast SEO:

Что это значит? Директива говорит что, все поисковые роботы могут свободно сканировать этот сайт без ограничений. Этого хватит для правильной индексации сайта WP. А наша SEO специалисты рекомендуют почти тоже самое. Пример, правильно составленного robots.txt для WordPress сайта:
User-agent: *
Disallow:
Sitemap: https://mysite.ru/sitemap.xmlДанная запись в файле роботс делает доступным для индексирования полностью сайт для роботов всех известных поисковиков. Здесь, также прописан путь к карте сайта XML.
Создать и редактировать файл также можно при помощи All in One SEO Pack прямо из интерфейса SEO плагина. Модуль robots.txt в SEO-пакете Все в одном позволяет вам настроить файл robots.txt для вашего сайта, который переопределит файл robots.txt по умолчанию, который создает WordPress:

Вы сможете управлять своим файлом Robots.txt, в разделе All in One SEO Pack — Robots.txt. Сам официальный сайт плагина использует вот такой роботс:

Правила по умолчанию, которые отображаются в поле Создать файл Robots.txt (показано на снимке экрана выше), требуют, чтобы роботы не сканировали ваши основные файлы WordPress. Для поисковых систем нет необходимости обращаться к этим файлам напрямую, потому что они не содержат какого-либо релевантного контента сайта.
А если вы не используете данные SEO модули, то предлагаю вам воспользоваться специальным плагином — Robots.txt Editor.
Плагин Robots.txt Editor
Плагин Robots.txt для WordPress — создание и редактирование файла robots.txt для сайта ВордПресс. Очень простой, лёгкий и эффективный плагин.

Плагин Robots.txt Editor (редактор) позволяет создать и редактировать файл robots.txt на вашем сайте WordPress.
Плагин Robots.txt возможности
- Работает в сети сайтов Multisite на поддоменах;
- Пример правильного файла robots.txt для WordPress;
- Не требует дополнительных настроек;
- Абсолютно бесплатный.
Как использовать? Установите плагин robots.txt стандартным способом. То есть, из админки. Плагины — Добавить новый. Введите в окно поиска его название — Robots.txt Editor:

Установили и сразу активировали. Всё, готово. Теперь смотрим, что получилось. Заходим, Настройки — Чтение и видим результат. Автоматически созданный правильный файл robots.txt для WordPress со ссылкой на ваш файл Sitemap. Пример, правильный robots.txt для сайта ВордПресс:

Естественно, вы можете его легко отредактировать под свои нужды. А также просмотреть, нажав соответствующею ссылку — Просмотр robots.txt.
Как создать robots.txt вручную
Если вы не захотите использовать плагины, которые предлагают функцию robots.txt, вы все равно можете создать и управлять своим файлом robots.txt на своём хостинге. Как создать файл robots.txt самостоятельно?
В текстовом редакторе создайте файл с именем robots в формате txt и заполните его:

Файл должен иметь имя robots.txt и никакое другое больше. Сохраните данный файл локально на компьютере. А затем, загрузите созданный файл в корневую директорию вашего сайта.
Корневая папка (корневая директория/корневой каталог/корень документа) — это основная папка, в которой хранятся все файлы сайта. Обычно, это папка public_html (там где находятся файлы — .htaccess, wp-config.php и другие). Именно в эту папку загружается файл robots.txt:

Чтобы проверить, получилось ли у вас положить файл в нужное место, перейдите по адресу: https://ваш_сайт.ru/robots.txt
Теперь, когда ваш файл robots.txt создан и загружен на сайт, вы можете проверить его на ошибки.
Проверка вашего файла robots.txt
Вы можете проверить файл robots.txt WordPress в Google Search Console и Яндекс.Вебмастер, чтобы убедиться, что он правильно составлен.
Например, проверка файла robots.txt WordPress в Яндекса.Вебмастер. В блоке Результаты анализа robots.txt перечислены директивы, которые будет учитывать робот при индексировании сайта.

Если будет найдена ошибка, информация об этом будет показана вам.
В заключение
Для некоторых сайтов WordPress нет необходимости срочно изменять стандартный виртуальный файл robots.txt (по умолчанию). Но, если вам нужен физический файл robots.txt, то используйте плагины Robots.txt Editor, All in One SEO Pack или Yoast SEO. С ними можно легко редактировать файл прямо из панели инструментов WordPress, чтобы добавить свои собственные правила.
До новых встреч, друзья и я надеюсь, что вам понравилось это маленькое руководство. И не стесняйтесь, обязательно оставьте комментарий, если у вас возникнут дополнительные вопросы по использованию файла robots.txt на сайте WordPress.
В этом руководстве я поделюсь методикой составления правильного robots.txt для сайтов на базе WordPress. Вы узнаете все об основных параметрах и допустимых значениях этого файла, а так же способах манипулирования поведением поисковых роботов для ускорения индексации сайта.
Что такое robots.txt?
Robots.txt — это текстовый файл, который содержит директивы и их значения для управления индексированием сайта в поисковых системах.
В базовый набор директив (параметров) для поисковой системы Яндекс входят:
| Директива | Описание |
|---|---|
| User-agent | Указывает на робота, для которого действуют правила (например, Yandex). |
| Allow | Разрешает обход и индексирование разделов, страниц, файлов. |
| Disallow | Запрещает обход и индексирование разделов, страниц, файлов. |
| Clean-param | Указывает роботу, какие параметры URL (например, UTM-метки) не следует учитывать при индексировании. |
| Sitemap | Указывает путь к файлу Sitemap, который размещен на сайте. |
Все директивы, кроме Clean-param одинаково интерпретируются в других поисковых системах и помогают решить 90% задач связанных с индексированием сайтов на WordPress.
Краулинговый бюджет: что это и как им управлять
Важно понимать, что файл robots.txt не является инструментом для запрета индексирования сайта. Поисковая система Google может не учитывать значения директив и индексировать страницы по своему усмотрению.
Crawler (веб-паук, краулер) или поисковой бот. Его задачи: найти, прочитать и внести в поисковую базу данных веб-страницы найденные в Интернете.
Владельцы сайтов могут управлять поведением краулера. Для этого достаточно разместить инструкции в robots.txt с помощью указанных директив в исходном коде страниц.
От правильности настройки будет зависеть частота сканирования вашего сайта. Основная цель такого управления — это снижение нагрузки на краулер и экономия квоты обхода страниц.
Где находится robots.txt в WordPress
Согласно требованиям поисковых систем файл robots.txt должен быть расположен в корневой директории. Если у вас он отсутствует, убедитесь, что вы не используете SEO-плагины.
Плагины позволяют редактировать robots.txt из панели администратора WordPress и не создают копию файла в корневой папке сайта (например, в режиме Multisite).
Если вы не используете плагин, создайте файл заново и проверьте его доступность. Ручная проверка доступности должна выявить:
- Наличие файла в корневой директории,
- Правильный ответ сервера (код 200 ОК),
- Допустимый размер файла (не более 500 Кб).
После проверки сообщите поисковым системам о внесении изменений.
Стандартный robots.txt для WordPress
После инсталляции WordPress 5.9.3 по умолчанию robots.txt выглядит так:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/wp-sitemap.xml
Из содержания следует, что разработчики рекомендуют закрывать от поисковых машин раздел административной панели, кроме сценария admin-ajax.php из этой же директории. При составлении файла robots.txt для любого проекта под управлением WordPress это необходимо учитывать.
Правильный robots.txt для WordPress
В WordPress имеется набор системных директорий, файлов и параметров, которые любят сканировать поисковые системы. Все они должны быть запрещены к индексированию за исключением редких случаев.
Системные директории и файлы
| Директория / Файл | Описание |
|---|---|
| /wp-admin | Панель администратора |
| /wp-json | JSON REST API |
| /xmlrpc.php | Протокол XML-RPC |
Параметры URL
| Параметр | Описание |
|---|---|
| s | Стандартная функция поиска |
| author | Личная страница пользователя |
| p&preview | Просмотр черновика записи |
| customize_theme | Изменение внешнего вида темы оформления |
| customize_autosaved | Автосохранение состояния кастомайзера |
Для более гибкой настройки мы рекомендуем разделять robots.txt на две секции. Первая секция будет содержать инструкции для всех поисковых систем, кроме Яндекса. Вторая — только для Яндекса.
Примечательно, что системные каталоги, файлы и параметры URL можно запретить с помощью директивы Disallow без использования Clean-param. В результате правильный robots.txt для WordPress выглядит так:
User-agent: *
Allow: /wp-admin/admin-ajax.php
Disallow: /*?
Disallow: /wp-admin
Disallow: /wp-json
Disallow: /xmlrpc.php
User-agent: Yandex
Allow: /wp-admin/admin-ajax.php
Disallow: /*?
Disallow: /wp-admin
Disallow: /wp-json
Disallow: /xmlrpc.php
Sitemap: https://example.com/wp-sitemap.xml
Не забудьте изменить значение директивы Sitemap.
Это универсальная конфигурация robots.txt для сайтов под управлением WordPress.
Значение /*? директивы Disallow запрещает к индексированию все параметры URL для главной страницы, записей и категорий. В том числе: рекламные UTM-метки, параметры плагинов, поисковых систем, сервисов коллтрекинга и CRM-платформ.
Отлично! Теперь перейдем к индивидуальной настройке.
Несколько примеров из практики
Запрет индексирования AMP страниц в поиске Яндекса
Сайт использует плагин для генерации мобильных страниц в формате AMP для поисковой системы Google. Яндекс их не поддерживает, но умеет сканировать. Для экономии квоты, запрещаем обход AMP страниц для Яндекса с помощью директивы Disallow:
User-agent: *
Allow: /wp-admin/admin-ajax.php
Disallow: /*?
Disallow: /wp-admin
Disallow: /wp-json
Disallow: /xmlrpc.php
User-agent: Yandex
Allow: /wp-admin/admin-ajax.php
Disallow: /*?
Disallow: /amp
Disallow: /wp-admin
Disallow: /wp-json
Disallow: /xmlrpc.php
Sitemap: https://example.com/wp-sitemap.xml
Не забудьте изменить значение директивы Sitemap.
Запрет индексирования служебных URL
Сайт использует плагин кастомной авторизации. Ссылки на страницы входа, регистрации и восстановления пароля выглядят так:
- https://example.com/login,
- https://example.com/register,
- https://example.com/reset-password.
Предварительно, исключим страницы из wp-sitemap.xml и добавим запрет на их сканирование с помощью директивы Disallow в файле robots.txt:
User-agent: *
Allow: /wp-admin/admin-ajax.php
Disallow: /*?
Disallow: /login
Disallow: /register
Disallow: /reset-password
Disallow: /wp-admin
Disallow: /wp-json
Disallow: /xmlrpc.php
User-agent: Yandex
Allow: /wp-admin/admin-ajax.php
Disallow: /*?
Disallow: /amp
Disallow: /login
Disallow: /register
Disallow: /reset-password
Disallow: /wp-admin
Disallow: /wp-json
Disallow: /xmlrpc.php
Sitemap: https://example.com/wp-sitemap.xml
Не забудьте изменить значение директивы Sitemap.
Использование директивы Clean-param
Директива Clean-param позволяет гибко настроить индексирование страниц с параметрами URL, которые влияют на содержание страниц.
Она поддерживается только поисковой системой Яндекса. Поисковые роботы Google теперь работают с параметрами URL автоматически.
Например, в торговом каталоге WooCommerce имеется фильтр, который сортирует товары по различным характеристикам: цвету, бренду, размеру.
| Параметр | Описание |
|---|---|
| orderby | Функция сортировки |
| add-to-cart | Функция добавления товара в корзину |
| removed_item | Функция удаления товара из корзины |
Чтобы разрешить индексирование каталога с сортировками в Яндексе без ущерба квоте на переобход сайта, потребуется сделать несколько корректировок.
Разрешим сканирование параметров URL в каталоге, где установлен Woocommerce. Определим лишние параметры — это add-to-cart и removed_item. Воспользуемся директивой Clean-param и внесем изменения:
User-agent: *
Allow: /wp-admin/admin-ajax.php
Disallow: /*?
Disallow: /login
Disallow: /register
Disallow: /reset-password
Disallow: /wp-admin
Disallow: /wp-json
Disallow: /xmlrpc.php
User-agent: Yandex
Allow: /catalog/?
Allow: /wp-admin/admin-ajax.php
Disallow: /*?
Disallow: /amp
Disallow: /login
Disallow: /register
Disallow: /reset-password
Disallow: /wp-admin
Disallow: /wp-json
Disallow: /xmlrpc.php
Clean-param: add-to-cart
Clean-param: removed_item
Sitemap: https://example.com/wp-sitemap.xml
Не забудьте изменить значение директивы Sitemap.
Сканирование сортировок товара разрешено в рамках экономии квоты переобхода страниц. Поисковой бот Яндекса не будет сканировать параметры URL предназначенные для манипуляций с корзиной товаров.
Отслеживание лишних страниц в поисковой консоли
Для получения максимального эффекта регулярно отслеживайте сканирование страниц в поисковой консоли Яндекса (разд. Статистика обхода) и запрещайте обход лишних страниц в robots.txt.
При настройке robots.txt я не рекомендую:
- Запрещать обход страниц пагинации записей и разделов (используйте атрибут
rel="canonical"), - Исключать из поиска комментарии пользователей к записям,
- Запрещать сканирование системных папок, где хранятся изображения, скрипты и стили тем оформления WordPress: wp-content, wp-includes и пр.
Как сообщить об изменениях поисковикам
Для отправки изменений используйте инструменты для анализа robots.txt в Яндекс.Вебмастер и Google Search Console.
Do you want to know how to edit a robots.txt file in WordPress?
A robots.txt file is a powerful SEO tool since it works as a website guide for search engine crawl bots or robots. Telling bots to not crawl unnecessary pages can increase the load speed of your site and improve rankings in search engines.
In this post, we’ll show you how to edit your robots.txt file in WordPress step by step. We’ll also cover what a robots.txt file is and why it’s important.
Feel free to click on these quick links to jump straight to different sections:
- What Is a Robots.txt File?
- Why Is the Robots.txt File Important?
- Edit Robots.txt in WordPress Using AIOSEO
What Is a Robots.txt File?
A robots.txt file tells search engines how to crawl your site — where they’re allowed to go or not.
Search engines like Google use these web crawlers, sometimes called web robots, to archive and categorize websites.
Most bots are configured to search for a robots.txt file on the server before it reads any other file from your site. It does this to see if you’ve added special instructions on how to crawl and index your site.
And the robots.txt file is typically stored in the root directory, also known as the main folder of your website.
The URL can look like this:
http://www.example.com/robots.txt
To check the robots.txt file for your own website, you simply replace the http://www.example.com/ with your domain and add robots.txt at the end.
Now, let’s take a look at how the basic format for a robots.txt file looks like:
User-agent: [user-agent name]
Disallow: [URL string not to be crawled]
User-agent: [user-agent name]
Allow: [URL string to be crawled]
Sitemap: [URL of your XML Sitemap]
For this to make any sense, we first need to explain what User-agent means. It’s basically the name of the search engine bot or robot that you want to block or allow to crawl your site (for example the Googlebot crawler).
Second, you can include multiple instructions to either Allow or Disallow specific URLs, plus adding multiple sitemaps. Like you’ve probably figured out, the disallow option tells search engine bots not to crawl these URLs.
Default Robots.txt File in WordPress
By default, WordPress automatically creates a robots.txt file for your site. So even if you don’t lift a finger, your site should already have the default WordPress robots.txt file.
But when you later customize it with your own rules, the default content is replaced.
Here’s how the default WordPress robots.txt file looks:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
The asterisk after User-agent: * means that the robots.txt file is for all web robots that visit your site. And like mentioned, the Disallow: /wp-admin/ tells robots to not visit your wp-admin page.
You can test your robots.txt file by adding /robots.txt at the end of your domain name. For example, if you enter “https://aioseo.com/robots.txt” in your web browser it shows the robots.txt file for AIOSEO:
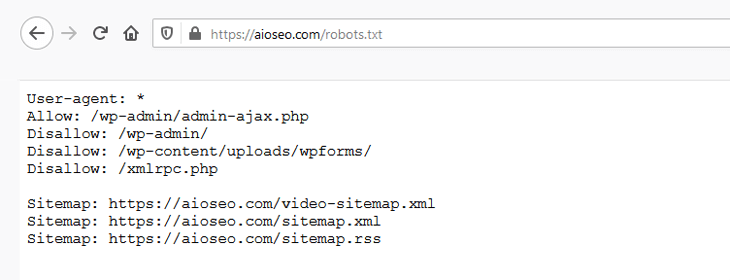
Now that you know what a robots.txt file is and the basics of how it works, let’s take a look at why the robots.txt file matters in the first place.
Why Is the Robots.txt File Important?
")
The robots.txt file is important if you want to:
- Optimize Your Site Load Speed — by telling bots to not waste time on pages you don’t want them to crawl and index, you can free up resources and increase your site load speed.
- Optimizing Your Server Usage — blocking bots that are wasting resources, will clean up your server and reduce 404 errors.
When to Use the Meta Noindex Tag Instead of Robots.txt
However, if your primary goal is to stop certain pages from being included in search engine results, the proper approach is to use a meta noindex tag.
This is because the robots.txt is not directly telling search engines not to index content – it’s just telling them not to crawl it.
In other words, you can use robots.txt to add specific rules for how search engines and other bots interact with your site, but it won’t explicitly control whether your content is indexed or not.
With that said, let’s show you how to easily edit your robots.txt file in WordPress step by step using AIOSEO.
Edit Robots.txt in WordPress Using AIOSEO
The easiest way to edit the robots.txt file is by using the best WordPress SEO plugin, All in One SEO (AIOSEO). It allows you to take control of your website and configure a robots.txt file that will override the default WordPress file.
If you didn’t know this already, AIOSEO is a complete WordPress SEO plugin, which lets you optimize your content for search engines and increase rankings with just a few clicks. Check out our powerful SEO tools and features here.
Enable Custom Robots.txt
To get started editing your robots.txt file, click on Tools in the All in One SEO menu, and then click on the Robots.txt Editor tab.
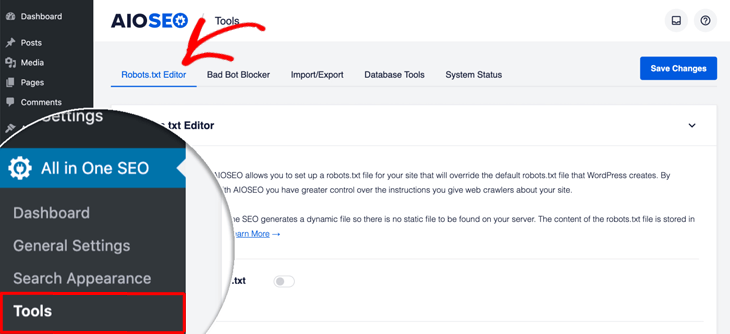
AIOSEO will then generate a dynamic robots.txt file. Its content is stored in your WordPress database and can be viewed in your web browser as we’ll show you in a bit.
Once you’ve entered the Robots.txt Editor, you need to Enable Custom Robots.txt.
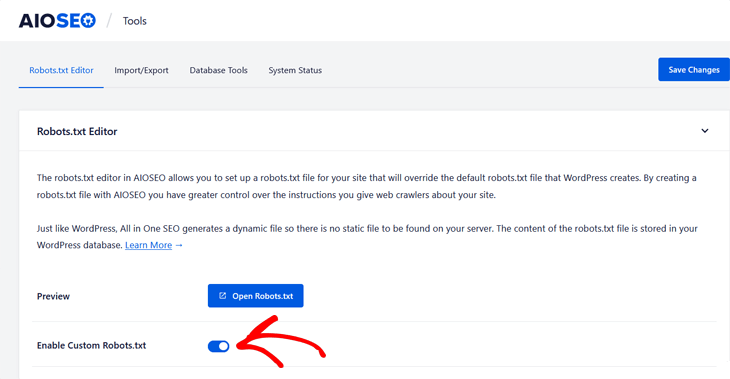
Click on the button so it turns blue.
You’ll then see the Robots.txt Preview section at the bottom of the screen, which shows the WordPress default rules that you can overwrite with your own. The default rules tell robots not to crawl your core WordPress files (admin pages).

Now, let’s move on to how you can add your own rules using the rule builder.
Adding Rules Using the Rule Builder
The rule builder is used to add your own custom rules for what pages the robots should crawl or not.
For instance, if you’d like to add a rule that blocks all robots from a temp directory (meaning a temporary folder on for example a hard drive), you can use the rule builder to do this.
Like in this example:

To add a custom rule, simply enter the User Agent (for example Googlebot crawler) in the User Agent field. Or you can use the * symbol that will make your rule apply to all user agents (robots).
Next, select either Allow or Disallow to allow or block the User Agent.

After you’ve decided what bots to allow or disallow, you need to enter the directory path or filename in the Directory Path field.
Once this is done, you can go ahead and click the Save Changes button in the right bottom corner of the page.
And if you want to add more rules, you can click the Add Rule button and repeat the steps above.
Don’t forget to save your changes when you’re done.
Anyway, when you’ve saved your new rules, they’ll appear in the Robots.txt Preview section.
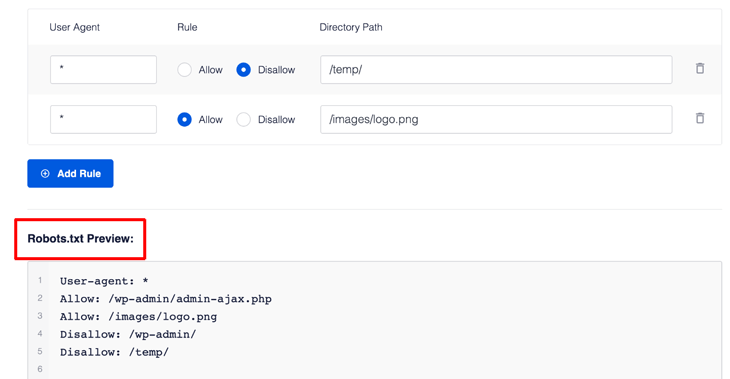
To view your robots.txt file, you simply click on the Open Robots.txt button.

Now, let’s take a look at how you can edit your rules next.
Editing Rules Using the Rule Builder
To edit your rules, you can just change the details in the rule builder and click on the Save Changes button.
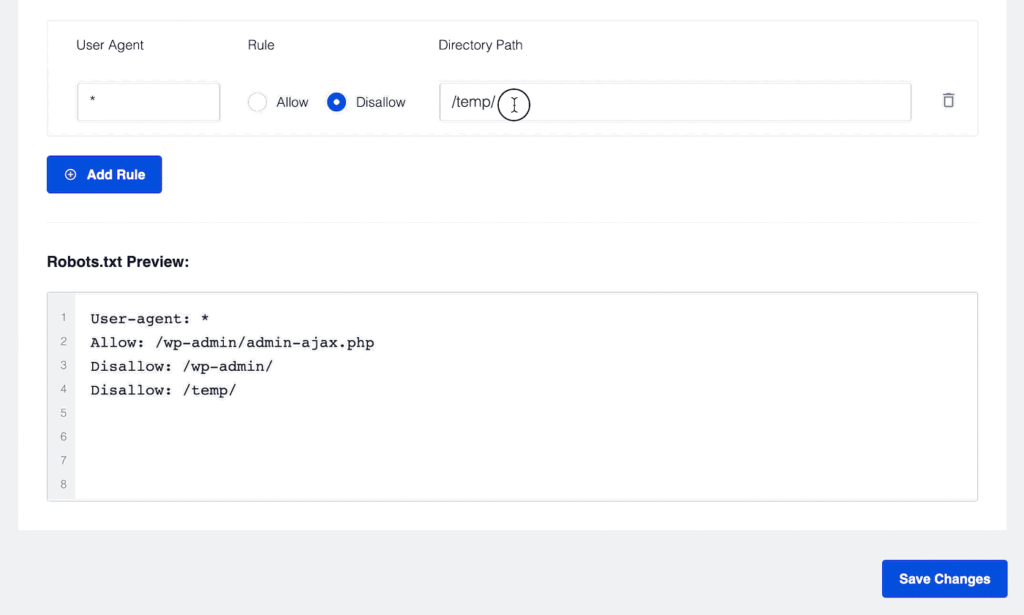
It’s very easy! And so is deleting rules like we’ll show you next.
Deleting a Rule in the Rule Builder
To delete a rule, simply click the trash can icon to the right of the rule.
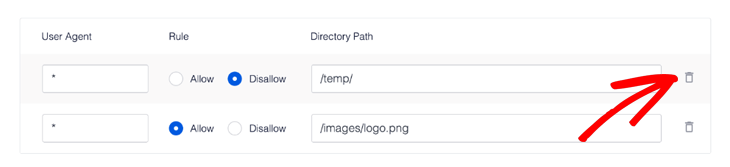
As simple as that!
Before leaving this topic, we want to let you know that in case you need to edit your robots.txt file for multisite networks, you can check out our documentation on how to do that here.
We hope this tutorial showed you how to easily edit a robots.txt file in WordPress. Now, go ahead and add your own rules, and you’ll make sure your website is optimized for optimal performance in no time.
One more thing…
…do you think Google Search Console is confusing? It doesn’t have to be!
Check out our guide on how to easily verIfy your WordPress site using AIOSEO.
And if you’re looking for great ways to improve your SEO to drive even more traffic to your site, check out our blog post SEO checklist or ultimate WordPress SEO guide.
Stay tuned for AIOSEO’s new features and improvements.
Если вам интересно, как для улучшения SEO оптимизировать файл robots.txt WordPress, то вы попали в нужное место.
В этом кратком руководстве я объясню, что такое файл robots.txt, почему он важен для улучшения поискового рейтинга и как вносить в него изменения и отправлять в Google и Яндекс.
Давайте начнем!
Содержание
- Что такое файл robots.txt для WordPress?
- Что находиться в файле robots.txt?
- Как оптимизировать robots.txt WordPress для улучшения SEO
- Как выглядит идеальный файл robots.txt?
- Что разрешить и запретить в robots.txt?
- Как отправить файл WordPress robots.txt в Google?
- Как отправить файл WordPress robots.txt в Яндекс?
- Вывод
Что такое файл robots.txt для WordPress?
Файл robots.txt — это файл на вашем сайте, который позволяет запретить поисковым системам доступ к определенным файлам и папкам. Вы можете использовать его, чтобы заблокировать роботов Google (и других поисковых систем) от сканирования определенных страниц на вашем сайте.
Так как же отказ в доступе к поисковым системам на самом деле улучшает ваше SEO? Кажется контринтуитивным…
Это работает следующим образом: чем больше страниц на вашем сайте, тем больше страниц должны сканировать поисковые системы.
Например, если в вашем блоге много страниц категорий и тегов, эти страницы некачественные и не нуждаются в сканировании поисковыми системами. Они просто потребляют краулинговый бюджет вашего сайта (количество страниц, которые поисковые системы будет сканировать на вашем сайте в любой момент времени).
Бюджет сканирования важен, потому что он определяет, насколько быстро поисковые системы улавливают изменения на вашем сайте и, следовательно, как быстро вы занимаете высшее место в поиске. Это может особенно помочь с SEO электронной коммерции!
Будьте осторожны, так как это может повредить вашему SEO, если все сделать плохо. Вы потеряете позиции находясь в высококонкурентной нише с большими сайтами. Однако, если вы только начинаете свой первый блог, создание ссылок на ваш контент и создание большого количества высококачественных статей являются более важными приоритетами.
Что находиться в файле robots.txt?
Файл robots.txt состоит из одного или нескольких блоков кода, каждый из которых содержит инструкции для одного или нескольких ботов. Кодовый блок состоит из:
- User-agent, который идентифицирует бота, на которого распространяется правило. Звездочкой (*), означает что применяется к любому пользовательскому агенту, который посещает веб-сайт. Однако вы можете настроить таргетинг на конкретного бота с помощью его пользовательского агента. Например, пользовательский агент Google — Googlebot.
- Disallow указывает ботам поисковых систем игнорировать указанный файл или файлы.
- Allow позволяет ботам поисковых систем получать доступ к указанному файлу или файлам. В этом нет необходимости, если только вы не хотите разрешить доступ к файлу или подкаталогу в запрещенном родительском каталоге.
- Crawl-delay указывает, сколько времени робот поисковой системы должен ждать между загрузками страницы. Он связан с числовым значением в секундах.
- Sitemap сообщает роботам, где находится ваша карта сайта. Эта строка не является обязательной. Я рекомендую вам отправлять карту сайта в поисковые системы с помощью специального инструмента, такого как Google Search Console. Может включать один или несколько файлов Sitemap, каждый из которых связан с URL-адресом карты сайта.
Как оптимизировать robots.txt WordPress для улучшения SEO
Теперь давайте обсудим, как на самом деле получить (или создать) и оптимизировать файл WordPress robots.txt.
Robots.txt обычно находится в корневой папке вашего сайта. Вам нужно будет подключиться к вашему сайту с помощью FTP-клиента или с помощью файлового менеджера cPanel для его просмотра. Это обычный текстовый файл, который можно открыть в любом текстовом редакторе.
Если у вас нет файла robots.txt в корневом каталоге вашего сайта, вы можете создать его. Все, что вам нужно сделать, это создать новый текстовый файл на вашем компьютере и сохранить его как robots.txt. Затем просто загрузите его в корневую папку вашего сайта.
Как выглядит идеальный файл robots.txt?
Формат файла robots.txt очень прост. Первая строка обычно называет пользовательский агент. Пользовательский агент — это имя поискового бота, с которым вы пытаетесь связаться. Например, Googlebotили Bingbot. Вы можете использовать звездочку *, чтобы проинструктировать всех ботов.
Следующая строка следует с инструкциями «Разрешить» или «Запретить» какие части вы хотите, чтобы они индексировали, а какие — нет.
Вот правильный robots.txt для WordPress:
|
User—agent: * # Предотвращено индексирование конфиденциальных файлов Disallow: /wp—admin Disallow: /wp—includes Disallow: /wp—content/cache Disallow: /trackback Disallow: /*.php$ Disallow: /*.inc$ Disallow: /*.gz$ # Не индексируем страницу входа (ненужный контент) Disallow: /wp—login.php Sitemap: https://mrwp.ru/sitemap_index.xml |
Обратите внимание, что если вы используете такой плагин, как Yoast или All in One SEO, вам может не понадобиться добавлять раздел карты сайта, поскольку они делают это автоматически. Если это не удается, вы можете добавить его вручную, как в примере выше.
Что разрешить и запретить в robots.txt?
В руководстве Google для веб-мастеров советуют не использовать файл robots.txt для сокрытия некачественного контента. Таким образом, использование вашего файла robots.txt, чтобы запретить поисковым системам индексировать вашу категорию, дату и другие страницы архива, может быть неразумным выбором.
Помните, что файл robots.txt предназначен для того, чтобы проинструктировать ботов, что делать с контентом, который они сканируют на вашем сайте. Это не мешает им сканировать ваш сайт.
Кроме того, вам не нужно добавлять страницу входа в WordPress, каталог администратора или страницу регистрации в robots.txt, потому что страницы входа и регистрации имеют тег noindex, автоматически добавленный WordPress.
Однако я рекомендую запретить файл readme.html в файле robots.txt.Этот файл readme может быть использован кем-то, кто пытается выяснить, какую версию WordPress вы используете. Если это человек, он может легко получить доступ к файлу, просто просмотрев его. Кроме того, размещение тега Disallow может блокировать вредоносные атаки.
Как отправить файл WordPress robots.txt в Google?
После того как вы обновили или создали файл robots.txt, вы можете отправить его в Google с помощью Google Search Console.
Тем не менее, я рекомендую сначала протестировать его с помощью инструмента тестирования Google robots.txt.

Если вы не видите созданную вами версию здесь, вам придется повторно загрузить файл robots.txt, который вы создали, на свой сайт WordPress.
Как отправить файл WordPress robots.txt в Яндекс?
Автоматически Яндекс попробует загрузить файл по адресу https://ваш-домен.ru/robots.txt. Если вы вручную не создавали этот файл, то по-умолчанию будет использоваться встроенный в WordPress (физически он может отсутствовать на хостинге) и часто его хватает для работы.
Для того, чтобы проанализировать действие файла в Яндексе, следует перейти на соответствующую страницу в разделе Яндекс.Вебмастер. Заходим в раздел Инструменты –> Анализ robots.txt.

Как видите, никакого запрета на индексирование страницы со стороны robots.txt мы не видим, значит все в порядке :).
Вывод
Теперь вы знаете, как оптимизировать файл WordPress robots.txt для улучшения SEO.
Будьте осторожны при внесении каких-либо серьезных изменений на свой сайт с помощью файла robots.txt. Хотя эти изменения могут улучшить ваш поисковый трафик, они также могут принести больше вреда, чем пользы, если вы не будете осторожны.
У вас есть вопросы о том, как оптимизировать файл robots.txt WordPress? Какое влияние оказало изменение на ваш поисковый рейтинг? Дайте мне знать об этом в комментариях.
Содержание
- Для чего нужен robots.txt
- Где лежит файл robots в WordPress
- Как создать правильный robots txt
- Настройка команд
- Рабочий пример инструкций для WordPress
- Как проверить работу robots.txt
- Плагин–генератор Virtual Robots.txt
- Добавить с помощью Yoast SEO
- Изменить модулем в All in One SEO
- Правильная настройка для плагина WooCommerce
- Итог
Robots.txt создан для регулирования поведения поисковых роботов на сайтах, а именно куда им заходить можно и брать в поиск, а куда нельзя. Лет 10 назад сила данного файла была велика, по его правилам работали все поисковые системы, но сейчас он скорее как рекомендация, чем правило.
Но пока не отменили, вебмастера должны делать его и настраивать правильно исходя из структуры и иерархии сайтов. Отдельная тема это WordPress, потому что CMS содержит множество элементов, которые не нужно сканировать и отдавать в индекс. Разберемся как правильно составить robots.txt
Где лежит файл robots в WordPress
На любом из ресурсов robots.txt должен лежать в корневой папке. В случае с вордпресс, там где находится папка wp-admin и ей подобные.

Если не создавался и не загружался администратором сайта, то по умолчанию на сервере не найти. Стандартная сборка WordPress не предусматривает наличие такого объекта.
Как создать правильный robots txt
Создать правильный robots txt задача не трудная, сложнее прописать в нем правильные директивы. Сначала создадим документ, открываем программу блокнот и нажимаем сохранить как.

В следующем окне задаем название robots, оставляем расширение txt, кодировку ANSI и нажимаем сохранить. Объект появится в папке куда произошло сохранение. Пока документ пустой и ничего не содержит в себе, давайте разберемся какие именно директивы он может поддерживать.
При желании можете сразу скачать его на сервер в корень через программу FileZilla.

Настройка команд
Выделю четыре основные команды:
- User-agent: показывает правила для разных поисковых роботов, либо для всех, либо для отдельных
- Disalow: запрещает доступ
- Allow: разрешаем доступ
- Sitemap: адрес до XML карты
Устаревшие и ненужные конфигурации:
- Host: указывает главное зеркало, стало не нужным, потому что поиск сам определит правильный вариант
- Crawl-delay: ограничивает время на пребывание робота на странице, сейчас сервера мощные и беспокоится о производительности не нужно
- Clean-param: ограничивает загрузку дублирующегося контента, прописать можно, но толку не будет, поисковик проиндексирует все, что есть на сайте и возьмет по–максимому страниц
Рабочий пример инструкций для WordPress
Дело в том что поисковой робот не любит запрещающие директивы, и все равно возьмет в оборот, что ему нужно. Запрет на индексацию должен быть объектов, которые 100% не должны быть в поиске и в базе Яндекса и Гугла. Данный рабочий пример кода помещаем в robots txt.
User-agent: *
Disallow: /wp-
Disallow: /tag/
Disallow: */trackback
Disallow: */page
Disallow: /author/*
Disallow: /template.html
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: *.js
Allow: *.css
Allow: *.png
Allow: *.gif
Allow: *.jpg
Sitemap: https://ваш домен/sitemap.xmlРазберемся с текстом и посмотрим что именно мы разрешили, а что запретили:
- User-agent, поставили знак *, тем самым сообщив что все поисковые машины должны подчиняться правилам
- Блок с Disallow запрещает к индексу все технические страницы и дубли. обратите внимание что я заблокировал папки начинающиеся на wp-
- Блок Allow разрешает сканировать скрипты, картинки и css файлы, это необходимо для правильного представления проекта в поиске иначе вы получите портянку без оформления
- Sitemap: показывает путь до XML карты сайта, обязательно нужно ее сделать, а так же заменить надпись»ваш домен»
Остальные директивы рекомендую не вносить, после сохранения и внесения правок, загружаем стандартный robots txt в корень WordPress. Для проверки наличия открываем такой адрес https://your-domain/robots.txt, заменяем домен на свой, должно отобразится так.

Как проверить работу robots.txt
Стандартный способ проверить через сервис yandex webmaster. Для лучшего анализа нужно зарегистрировать и установить на сайт сервис. Вверху видим загрузившийся robots, нажимаем проверить.

Ниже появится блок с ошибками, если их нет то переходим к следующему шагу, если неверно отображается команда, то исправляем и снова проверяем.

Проверим правильно ли Яндекс обрабатывает команды, спускаемся чуть ниже, введем два запрещенных и разрешенных адреса, не забываем нажать проверить. На снимке видим что инструкция сработала, красным помечено что вход запрещен, а зеленой галочкой, что индексирование записей разрешена.

Проверили, все срабатывает, перейдем к следующему способу это настройка robots с помощью плагинов. Если процесс не понятен, то смотрите наше видео.
Плагин–генератор Virtual Robots.txt
Если не хочется связываться с FTP подключением, то приходит на помощь один отличный WordPress плагин–генератор называется Virtual Robots.txt. Устанавливаем стандартно из админки вордпресс поиском или загрузкой архива, выглядит так.

Переходим в админку Настройки > Virtual Robots.txt, видим знакомую конфигурацию, но нам нужно ее заменить, на нашу из статьи. Копируем и вставляем, не забываем сохранять.

Роботс автоматически создастся и станет доступен по тому же адресу. При желании проверить есть он в файлах WordPress – ничего не увидим, потому что документ виртуальный и редактировать можно только из плагина, но Yandex и Google он будет виден.
Добавить с помощью Yoast SEO
Знаменитый плагин Yoast SEO предоставляет возможность добавить и изменить robots.txt из панели WordPress. Причем созданный файл появляется на сервере (а не виртуально) и находится в корне сайта, то есть после удаления или деактивации роботс остается. Переходим в Инструменты > Редактор.

Если robots есть, то отобразится на странице, если нет есть кнопка «создать», нажимаем на нее.

Выйдет текстовая область, записываем, имеющийся текст из универсальной конфигурации и сохраняем. Можно проверить по FTP соединению документ появится.
Изменить модулем в All in One SEO
Старый плагин All in One SEO умеет изменять robots txt, чтобы активировать возможность переходим в раздел модули и находим одноименный пункт, нажимаем Activate.

В меню All in One SEO появится новый раздел, заходим, видим функционал конструктора.

- Записываем имя агента, в нашем случае * или оставляем пустым
- Разрешаем или запрещаем индексацию
- Директория или страница куда не нужно идти
- Результат
Модуль не удобный, создать по такому принципу валидный и корректный robots.txt трудно. Лучше используйте другие инструменты.
Правильная настройка для плагина WooCommerce
Чтобы сделать правильную настройку для плагина интернет магазина на WordPress WooCommerce, добавьте эти строки к остальным:
Disallow: /cart/
Disallow: /checkout/
Disallow: /*add-to-cart=*
Disallow: /my-account/
Делаем аналогичные действия и загружаем на сервер через FTP или плагином.
Итог
Подведем итог что нужно сделать чтобы на сайте WordPress был корректный файл для поисковиков:
- Создаем вручную или с помощью плагина файл
- Записываем в него инструкции из статьи
- Загружаем на сервер
- Проверяем в валидаторе Yandex
- Не пользуйтесь генераторами robots txt в интернете, пошевелите немного руками
Совершенствуйте свои блоги на WordPress, продвигайтесь и правильно настраивайте все параметры, а мы в этом поможем, успехов!
Пожалуйста, оцените материал:
На чтение 15 мин. Просмотров 5k. Опубликовано 27 октября, 2020
Чтобы нужные страницы сайта попадали в индекс поисковых систем, важно правильно настроить файл robots.txt. Этот документ дает рекомендации поисковым роботам, какие страницы обрабатывать, а какие — нет: например, от индексации можно закрыть панель управления сайтом или страницы, которые находятся в разработке. Рассказываем, как правильно настроить robots.txt, если ваш сайт сделан на WordPress.
Что такое robots.txt и для чего он нужен?
Чтобы понять, какие страницы есть на сайте, поисковики «напускают» на него роботов: они сканируют сайт и передают перечень страниц в поисковую систему. robots.txt — это текстовый файл, в котором содержатся указания о том, какие страницы можно, а какие нельзя сканировать роботам.
Обычно на сайте есть страницы, которые не должны попадать в выдачу: например, это может быть административная панель, личные страницы пользователей или временные страницы сайта. Кроме этого, у поисковых роботов есть определенный лимит сканирования страниц (кроулинговый бюджет) — за раз они могут обработать только ограниченное их количество.
Проведем аналогию: представим сайт в виде города, а страницы в виде домов. По дорогам между домов ездят роботы и записывают информацию о каждом доме (индексируют страницы и добавляют в базу). Роботы получают ограниченное количество топлива в день — например, 10 литров на объезд города в день. Это топливо — кроулинговый бюджет, который выделяют поисковые системы на обработку сайта.
На маленьких проектах, 500-1000 страниц, кроулинговый бюджет не сказывается критично, но на интернет-магазинах, маркетплейсах, больших сервисах могут возникнут проблемы. Если они спроектированы неверно, то робот может месяцами ездить по одному кварталу (сканировать одни и те же страницы), но не заезжать в отдаленные районы. Чем больше проект, тем больший кроулинговый бюджет выделяют поисковики, но это не поможет, если дороги сделаны неудобно и вместо прямой дороги в 1 км нужно делать крюк в 15 км.
Правильный robots.txt помогает решить часть этих проблем.
Разные поисковые системы по-разному обрабатывают robots.txt: например, Google может включить в индекс даже ту страницу, которая запрещена в этом файле, если найдет ссылку на такую страницу на страницах сайта. Яндекс же относится к robots.txt как к руководству к действию — если страница запрещена для индексации в файле, она не будет включена в результаты поиска, но с момента запрета может пройти до двух недель до исключения из индекса. Таким образом, правильная настройка robots.txt в 99% случаев помогает сделать так, чтобы в индекс попадали только те страницы, которые вы хотите видеть в результатах поиска.
Кроме этого, robots.txt может содержать технические сведения о сайте: например, главное зеркало, местоположение sitemap.xml или параметры URL-адресов, передача которых не влияет на содержимое страницы.
Файл robots.txt рекомендует роботам поисковых систем, как правильно обрабатывать страницы сайта, чтобы они попали в выдачу.
Где находится файл robots.txt?
По умолчанию в WordPress нет файла robots.txt. При установке WordPress создает виртуальный файл robots.txt с таким содержимым:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpТакая настройка говорит поисковым роботам следующее:
User-agent: * — для любых поисковых роботов
Disallow: /wp-admin/ — запретить обрабатывать /wp-admin/
Allow: /wp-admin/admin-ajax.php — разрешить обрабатывать элементы сайта, которые загружаются через AJAX
Этот файл не получится найти в папках WordPress — он работает, но физически его не существует. Поэтому, чтобы настроить robots.txt, сначала нужно его создать.
Robots.txt должен находиться в корневой папке (mysite.ru/robots.txt), чтобы роботы любых поисковых систем могли его найти.
Как редактировать и загружать robots.txt
Есть несколько способов создать файл robots.txt — либо сделать его вручную в текстовом редакторе и разместить в корневом каталоге (папка самого верхнего уровня на сервере), либо воспользоваться специальными плагинами для настройки файла.
Как создать robots.txt в Блокноте
Самый простой способ создать файл robots.txt — написать его в блокноте и загрузить на сервер в корневой каталог.
Лучше не использовать стандартное приложение — воспользуйтесь специальными редакторы текста, например, Notepad++ или Sublime Text, которые поддерживают сохранение файла в конкретной кодировке. Дело в том, что поисковые роботы, например, Яндекс и Google, читают только файлы в UTF-8 с определенными переносами строк — стандартный Блокнот Windows может добавлять ненужные символы или использовать неподдерживаемые переносы.
Говорят, что это давно не так, но чтобы быть уверенным на 100%, используйте специализированные приложения.
Рассмотрим создание robots.txt на примере Sublime Text. Откройте редактор и создайте новый файл. Внесите туда нужные настройки, например:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://mysite.ru/sitemap.xmlГде mysite.ru — домен вашего сайта.
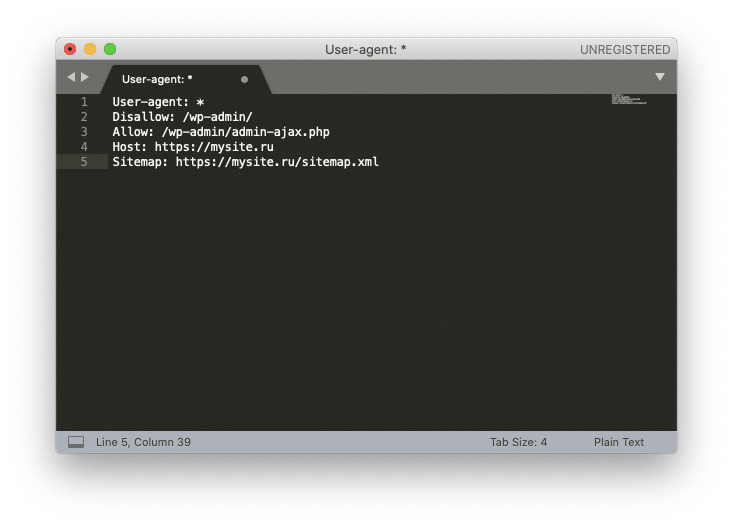
После того, как вы записали настройки, выберите в меню File ⟶ Save with Encoding… ⟶ UTF-8 (или Файл ⟶ Сохранить с кодировкой… ⟶ UTF-8).
Назовите файл “robots.txt” (обязательно с маленькой буквы).
Файл готов к загрузке.
Загрузить robots.txt через FTP
Для того, чтобы загрузить созданный robots.txt на сервер через FTP, нужно для начала включить доступ через FTP в настройках хостинга.
После этого скопируйте настройки доступа по FTP: сервер, порт, IP-адрес, логин и пароль (не совпадают с логином и паролем для доступа на хостинг, будьте внимательны!).
Чтобы загрузить файл robots.txt вы можете воспользоваться специальным файловым менеджером, например, FileZilla или WinSCP, или же сделать это просто в стандартном Проводнике Windows. Введите в поле поиска “ftp://адрес_FTP_сервера”.
После этого Проводник попросит вас ввести логин и пароль.
Введите данные, которые вы получили от хостинг-провайдера на странице настроек доступа FTP. После этого в Проводнике откроются файлы и папки, расположенные на сервере. Скопируйте файл robots.txt в корневую папку. Готово.
Загрузить или создать robots.txt на хостинге
Если у вас уже есть готовый файл robots.txt, вы можете просто загрузить его на хостинг. Зайдите в файловый менеджер панели управления вашим хостингом, нажмите на кнопку «Загрузить» и следуйте инструкциям (подробности можно узнать в поддержке у вашего хостера.
Многие хостинги позволяют создавать текстовые файлы прямо в панели управления хостингом. Для этого нажмите на кнопку «Создать файл» и назовите его “robots.txt” (с маленькой буквы).
После этого откройте его во встроенном текстовом редакторе хостера. Если вам предложит выбрать кодировку для открытия файла — выбирайте UTF-8.
Добавьте нужные директивы и сохраните изменения.
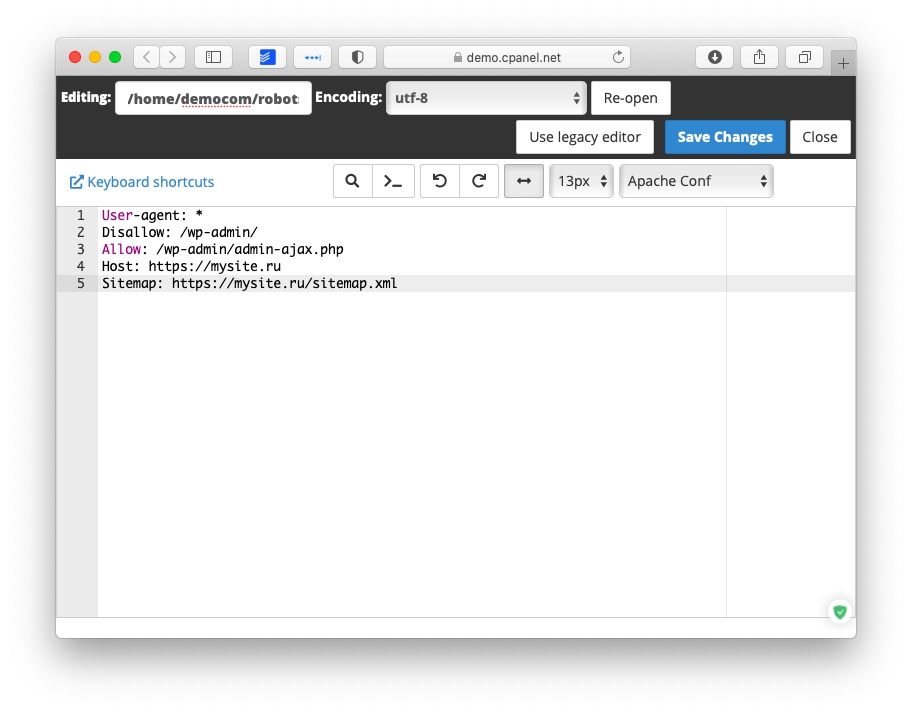
Плагины для редактирования robots.txt
Гораздо проще внести нужные директивы в robots.txt с помощью специальных плагинов для редактирования прямо из панели управления WordPress. Самые популярные из них — ClearfyPro, Yoast SEO и All in One SEO Pack.
Clearfy Pro
Этот плагин отлично подходит для начинающих: даже если вы ничего не понимаете в SEO, Clearfy сам создаст правильный и валидный файл robots.txt. Кроме этого, плагин предлагает пошаговую настройку самых важных для поисковой оптимизации функций, так что на первых этапах развития сайта этого будет достаточно.
Чтобы настроить robots.txt, в панели управления WordPress перейдите в пункт Настройки ⟶ Clearfy ⟶ SEO.
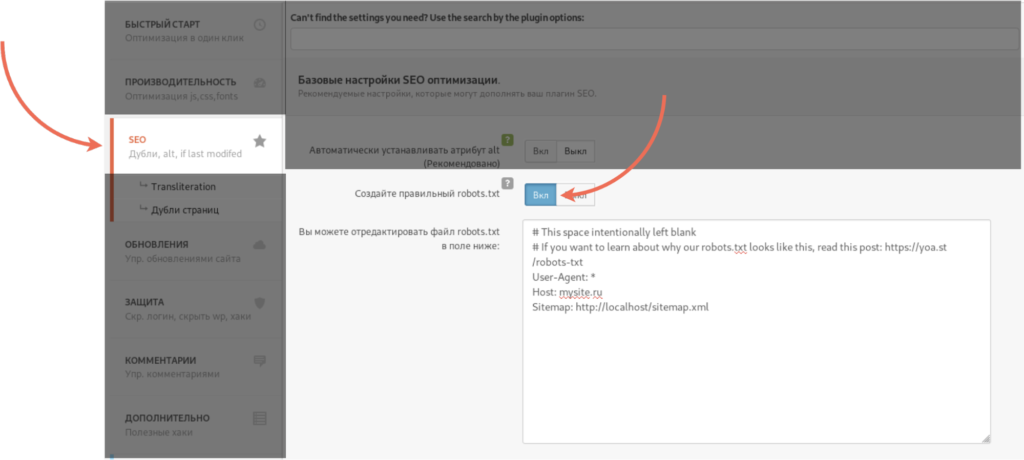
Переключите «Создайте правильный robots.txt» в положение «Вкл». Clearfy отобразит правильные настройки файла robots.txt. Вы можете дополнить эти настройки, например, запретив поисковым роботам индексировать папку /wp-admin/.
После внесения настроек нажмите на кнопку «Сохранить» в верхнем правом углу.
Yoast SEO
Плагин Yoast SEO хорош тем, что в нем есть много настроек для поисковой оптимизации: он напоминает использовать ключевые слова на странице, помогает настроить шаблоны мета-тегов и предлагает использовать мета-теги Open Graph для социальных сетей.
С его помощью можно отредактировать и robots.txt.
Для этого зайдите в раздел Yoast SEO ⟶ Инструменты ⟶ Редактор файлов.
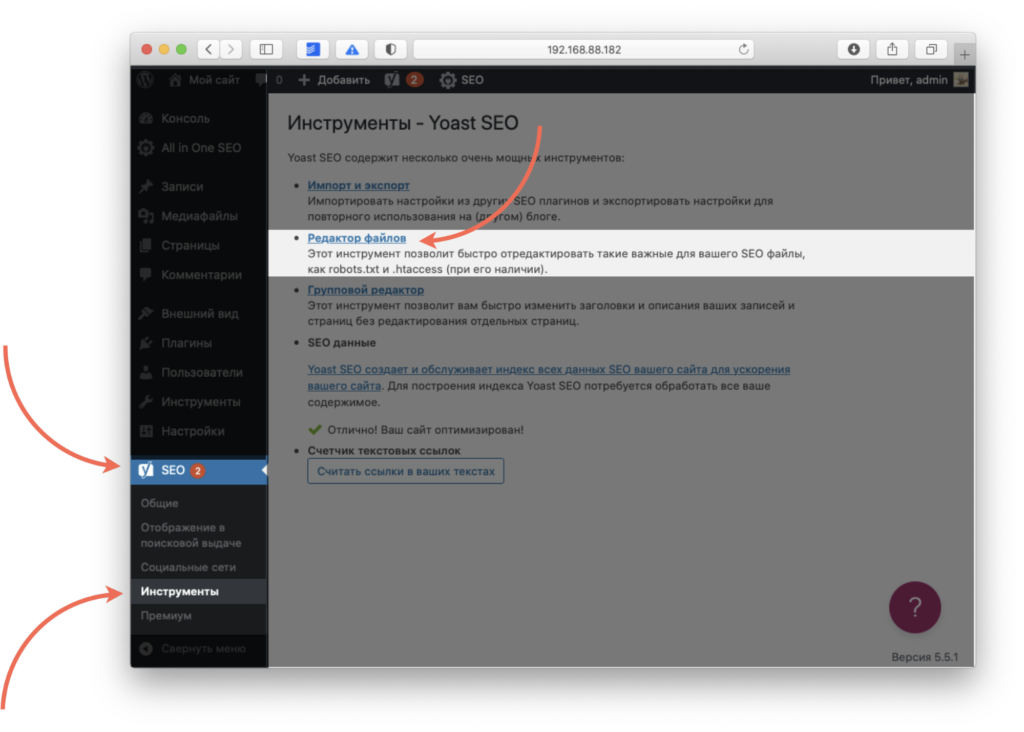
Здесь вы сможете отредактировать robots.txt и сохранить его, не заходя на хостинг. По умолчанию Yoast SEO не предлагает никаких настроек для файла, так что его придется прописать вручную.
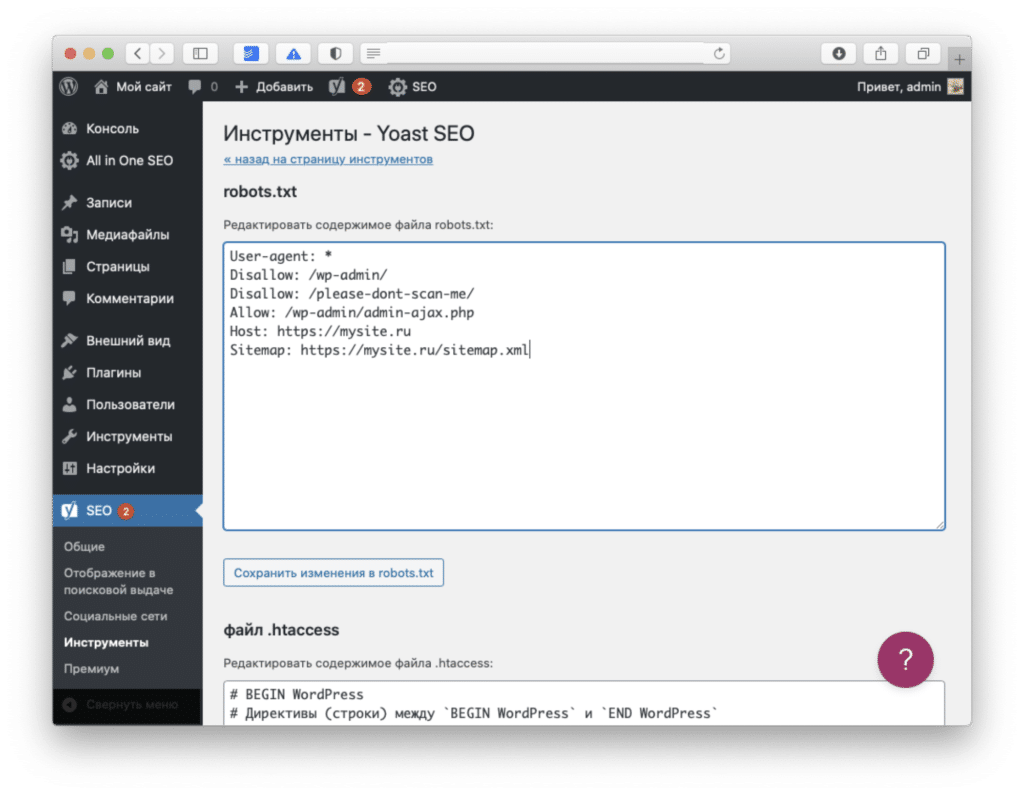
После изменений нажмите на кнопку «Сохранить изменения в robots.txt».
All in One SEO Pack
Еще один мощный плагин для управления SEO на WordPress. Чтобы отредактировать robots.txt через All in One SEO Pack, сначала придется активировать специальный модуль. Для этого перейдите на страницу плагина в раздел «Модули» и нажмите «Активировать» на модуле «robots.txt».
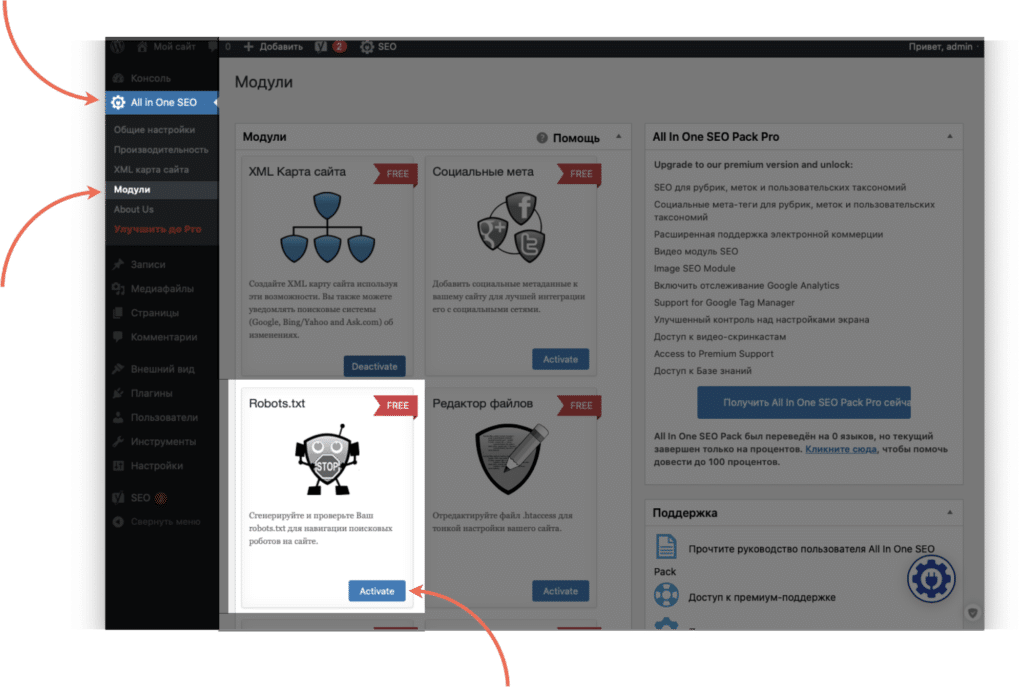
После подключения модуля перейдите на его страницу. С помощью него можно разрешать или запрещать для обработки конкретные страницы и группы страниц для разных поисковых роботов, не прописывая директивы вручную.
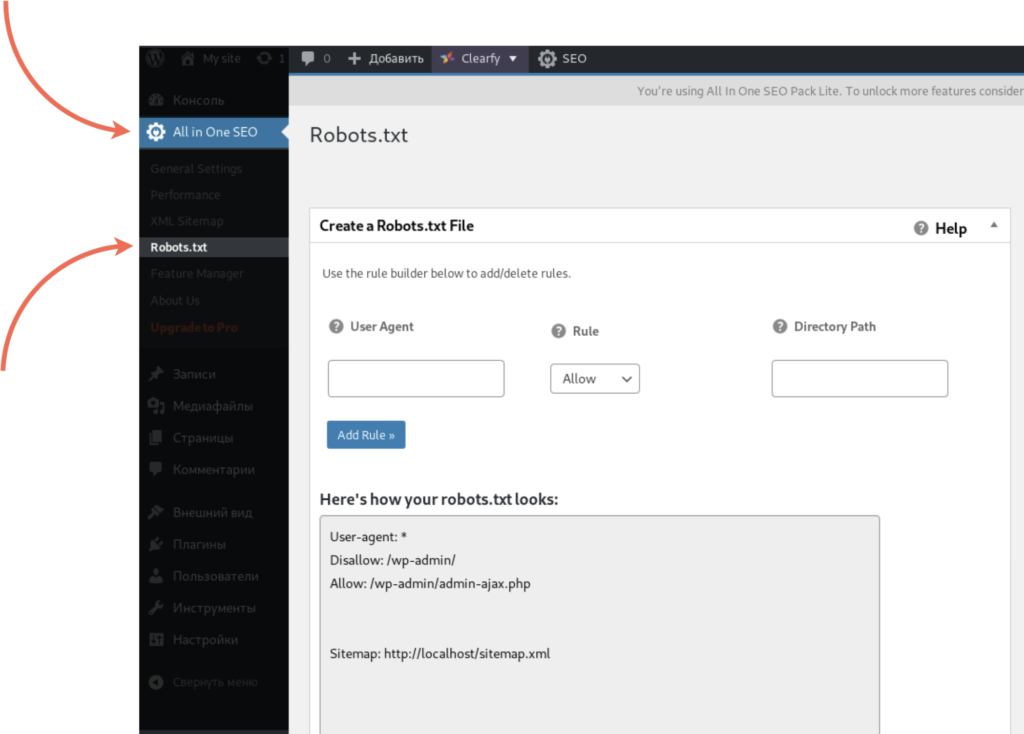
Правильный и актуальный robots.txt в 2020 году
Для того, чтобы создать правильный файл robots.txt, нужно знать, что означает каждая из директив в файле, записать их в правильном порядке и проверить файл на валидность.
Что означают указания в файле robots.txt?
User-agent — поисковой робот
В строке User-agent указывается, для каких роботов написаны следующие за этой строкой указания. Например, если вы хотите запретить индексацию сайта для поисковых роботов Bing, но разрешить для Google и Яндекс, это будет выглядеть примерно так:
| User-agent: Googlebot Disallow: User-agent: Yandex User-agent: Bingbot |
Для робота Google Запретить: ничего Для робота Яндекс Для робота Bing |
На практике необходимость разграничивать указания для разных поисковых роботов встречается довольно редко. Гораздо чаще robots.txt пишут для всех роботов сразу. Это указывается через звездочку:
User-agent: *У поисковых систем есть и специальные роботы — например, бот YandexImages обходит изображения, чтобы выдавать их в поиске Яндекса по картинкам, а Googlebot-News собирает информацию для выдаче в Google Новостях. Полные списки ботов можно найти в справке поисковых систем — введите в поиск «поисковые роботы [название ПС]».
Disallow
Эта директива сообщает поисковым роботам, что страница или целый список страниц запрещены для обхода. Важно понимать, что указание в robots.txt не гарантирует, что страница не попадет в выдачу — если ссылка на запрещенную в файле страницу встречается на разрешенных страницах сайта, поисковик все равно может включить его в индекс.
Если вы хотите разрешить поисковым роботам обрабатывать все страницы сайта, оставьте это указание пустым.
User-agent: *
Disallow:Если вам нужно запретить для индексации несколько страниц или директорий, указывайте каждую из них отдельно:
User-agent: *
Disallow: /wp-admin/
Disallow: /dev/
Disallow: /index2.htmlAllow
Это указание разрешает ботам поисковиков сканировать определенные страницы. Обычно это используют, когда нужно закрыть целую директорию, но разрешить обрабатывать часть страниц.
User-agent: *
Disallow: /wp-admin/
Disallow: /dev/
Allow: /dev/index.phpБольшинство поисковых систем обрабатывают в первую очередь более точные правила (например, с указанием конкретных страниц), а затем — более широкие. Например:
User-agent: *
Disallow: /wp-admin/
Disallow: /dev/
Allow: /dev/index.phpТакой файл robots.txt укажет роботам, что не нужно сканировать все страницы из папки «catalog», кроме «best-offers.html».
Host
Указание host говорит поисковым роботам, какое из зеркал сайта является главным. Например, если сайт работает через защищенный протокол https, в robots.txt стоит это указать:
User-agent: *
Disallow: /wp-admin/
Host: https://mysite.ruЭта директива уже устарела, и сегодня ее использовать не нужно. Если она есть в вашем файле сейчас, лучше ее удалить — есть мнение, что она может негативно сказываться на продвижении.
Sitemap
Этот атрибут — еще один способ указать поисковым роботам, где находится карта сайта. Она нужна для того, чтобы поисковик смог добраться до любой страницы сайта в один клик вне зависимости от сложности его структуры.
User-agent: *
Disallow: /wp-admin/
Host: https://mysite.ru
Sitemap: https://mysite.ru/sitemap.xmlCrawl-delay
Такой параметр помогает установить задержку для обработки сайта поисковыми роботами. Это может быть полезно, если сайт расположен на слабом сервере и вы не хотите, чтобы боты перегружали его запросами: передайте в crawl-delay время, которое должно проходить между запросами роботов. Время передается в секундах.
User-agent: *
Disallow: /wp-admin/
Host: https://mysite.ru
Sitemap: https://mysite.ru/sitemap.xml
Crawl-delay: 10На самом деле современные поисковые роботы и так делают небольшую задержку между запросами, так что прописывать это явно стоит только в том случае, если сервер очень слабый.
Clean-param
Эта настройка пригодится, чтобы скрыть из поиска страницы, в адресе которых есть параметры, не влияющие на ее содержание. Звучит сложно, так что объясняем на примере.
Допустим, на сайте есть категория «Смартфоны» и она расположена по адресу mysite.ru/catalog/smartphones.
У категории есть фильтры, которые передаются с помощью GET-запроса. Предположим, пользователь отметил в фильтре «Производитель: Apple, Samsung». Адрес страницы поменялся на
mysite.ru/catalog/smartphones/?manufacturer=apple&manufacturer=samsung,
где ?manufacturer=apple&manufacturer=samsung — параметры, которые влияют на содержимое страницы. Логично, что такие страницы можно и нужно выводить в поиске — эту страницу со включенным фильтром можно продвигать по запросу вроде «смартфоны эппл и самсунг».
А теперь представим, что пользователь перешел в категорию «Смартфоны» по ссылке, которую вы оставили во ВКонтакте, добавив к ней UTM-метки, чтобы отследить, эффективно ли работает ваша группа.
mysite.ru/catalog/smartphones/?utm_source=vk&utm_medium=post&utm_campaign=sale
В такой ссылке параметры ?utm_source=vk&utm_medium=post&utm_campaign=sale не влияют на содержимое страницы — mysite.ru/catalog/smartphones/ и mysite.ru/catalog/smartphones/?utm_source=vk&utm_medium=post&utm_campaign=sale будут выглядеть одинаково.
Чтобы помочь поисковым роботам понять, на основании каких параметров содержимое меняется, а какие не влияют на контент страницы, и используется настройка Clean-param.
User-agent: *
Disallow: /wp-admin/
Host: https://mysite.ru
Sitemap: https://mysite.ru/sitemap.xml
Clean-param: utm_campaign /
Clean-param: utm_medium /
Clean-param: utm_source /С помощью такой директивы вы укажете поисковым роботам, что при обработке страниц для поисковой выдачи нужно удалять из ссылок такие параметры, как utm_campaign, utm_medium и utm_source.
Как проверить robots.txt
Для того, чтобы проверить валидность robots.txt, можно использовать инструменты вебмастера поисковых систем. Инструмент проверки robots.txt есть у Google в Search Console — для его использования понадобится авторизация в Google и подтверждение прав на сайт, для которого проверяется файл.
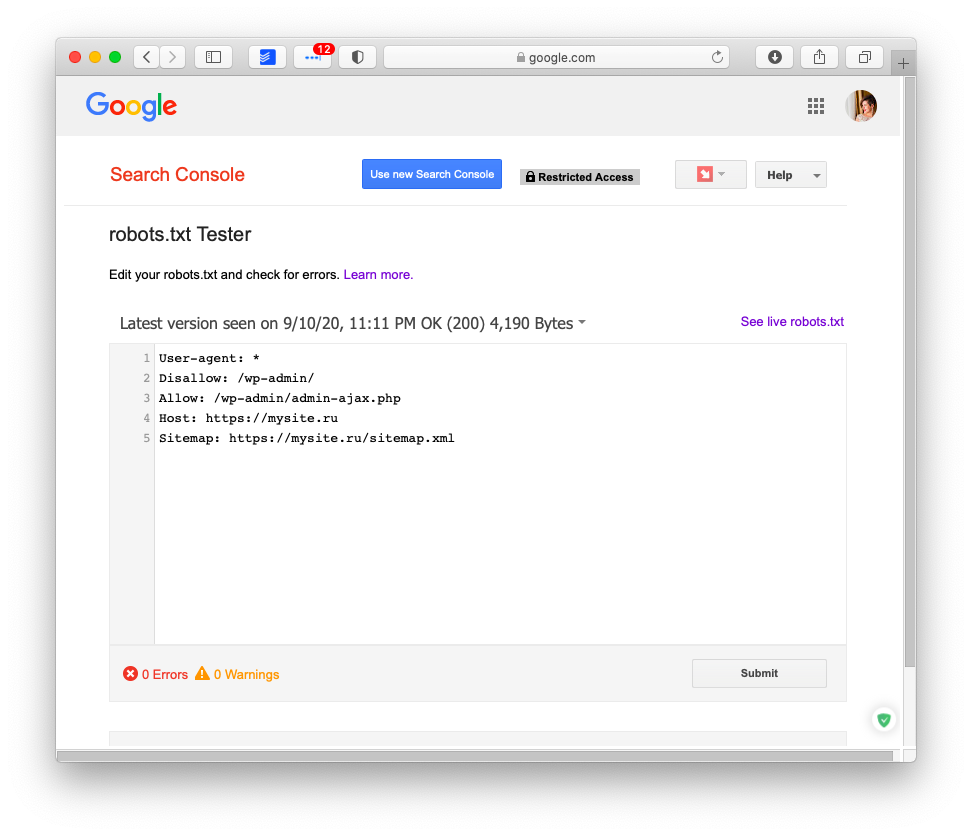
Похожий инструмент для проверки robots.txt есть и у Яндекса, и он даже удобнее, потому что не требует авторизации.
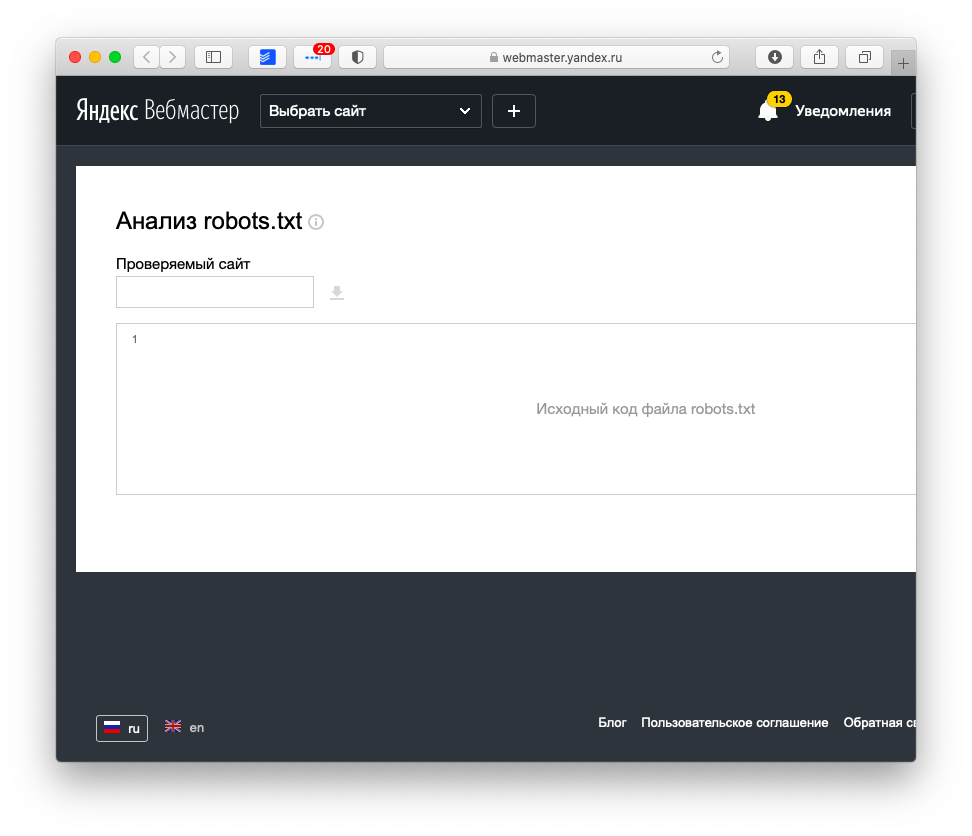
Эти приложения помогают понять, как поисковый робот видит файл: если какие-то из директив прописаны в нем неверно, инструмент проверки их проигнорирует либо предупредит о них.
Чего стоит избегать при настройке robots.txt?
Будьте внимательны: хоть robots.txt непосредственно и не влияет на то, окажется ли ваш сайт в выдаче, этот файл помогает избежать попадания в индекс тех страниц, которые должны быть скрыты от пользователей. Все, что робот не сможет интерпретировать, он проигнорирует.
Вот несколько частых ошибок, которые можно допустить при настройке.
Не указан User-Agent
Или указан после директивы, например:
Disallow: /wp-admin/
User-agent: *Такую директиву робот прочитает так:
Disallow: /wp-admin/ — так, это не мне, не читаю
User-agent: * — а это мне… Дальше ничего? Отлично, обработаю все страницы!
Любые указания к поисковым роботам должны начинаться с директивы User-agent: название_бота.
User-agent: GoogleBot
Disallow: /wp-admin/
User-agent: Yandex
Disallow: /wp-admin/Или для всех сразу:
User-agent: *
Disallow: /wp-admin/Несколько папок в Disallow
Если вы укажете в директиве Disallow сразу несколько директорий, неизвестно, как робот это прочтет.
User-agent: *
Disallow: /wp-admin/ /catalog/ /temp/ /user/ — “/wp-admin/catalog/temp/user/”? “/catalog/ /user”? “??????”?По своему разумению он может обработать такую конструкцию как угодно. Чтобы этого не случилось, каждую новую директиву начинайте с нового Disallow:
User-agent: *
Disallow: /wp-admin/
Disallow: /catalog/
Disallow: /temp/
Disallow: /user/Регистр в названии файла robots.txt
Поисковые роботы смогут прочитать только файл с названием “robots.txt”. “Robots.txt”, “ROBOTS.TXT” или “R0b0t.txt” они просто проигнорируют.
Резюме
- robots.txt — файл с рекомендациями, как обрабатывать страницы сайта, для поисковых роботов.
- В WordPress по умолчанию нет robots.txt, но есть виртуальный файл, который запрещает ботам сканировать страницы панели управления.
- Создать robots.txt можно в блокноте и загрузить его на хостинг в корневой каталог.
- Файл robots.txt должен быть создан в кодировке UTF-8.
- Проще создать robots.txt с помощью плагинов для WordPress — Clearfy Pro, Yoast SEO, All in One SEO Pack или других SEO-плагинов.
- С помощью robots.txt можно создать директивы для разных поисковых роботов, сообщить о главном зеркале сайта, передать адрес sitemap.xml или указать параметры URL-адресов, которые не влияют на содержимое страницы.
- Проверить валидность robots.txt можно с помощью инструментов от Google и Яндекс.
- Все директивы файла robots.txt, которые робот не сможет интерпретировать, он проигнорирует.
Всем привет! Сегодня я бы хотел Вам рассказать про файл robots.txt. Да, про него очень много чего написано в интернете, но, если честно, я сам очень долгое время не мог понять, как же создать правильный robots.txt. В итоге я сделал один и он стоит на всех моих блогах. Проблем с индексацией сайта я не замечаю, robots.txt работает просто великолепно.
А зачем, собственно говоря, нужен robots.txt? Ответ все тот же – продвижение сайта в поисковых системах. То есть составление robots.txt – это одно из частей поисковой оптимизации сайта (кстати, очень скоро будет урок, который будет посвящен всей внутренней оптимизации сайта на WordPress. Поэтому не забудьте подписаться на RSS, чтобы не пропустить интересные материалы.).
Одна из функций данного файла – запрет индексации ненужных страниц сайта. Также в нем задается адрес карты сайта sitemap.xml и прописывается главное зеркало сайта (сайт с www или без www).
Примечание: для поисковых систем один и тот же сайт с www и без www совсем абсолютно разные сайты. Но, поняв, что содержимое этих сайтов одинаковое, поисковики “склеивают” их. Поэтому важно прописать главное зеркало сайта в robots.txt. Чтобы узнать, какое главное (с www или без www), просто наберите адрес своего сайта в браузере, к примеру, с www, если Вас автоматически перебросит на тот же сайт без www, значит главное зеркало Вашего сайта без www. Надеюсь правильно объяснил.
Было:
Стало (после перехода на сайт, www автоматически удалились, и сайт стал без www):
Так вот, этот заветный, по-моему, правильный robots.txt для WordPress Вы можете увидеть ниже.
Правильный Robots.txt для WordPress
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Host: wpnew.ru
Sitemap: https://wpnew.ru/sitemap.xml.gz
Sitemap: https://wpnew.ru/sitemap.xml
Все что дано выше, Вам нужно скопировать в текстовой документ с расширением .txt, то есть, чтобы название файла было robots.txt. Данный текстовой документ Вы можете создать, к примеру, с помощью программы Notepad++. Только, не забудьте, пожалуйста, изменить в последних трех строчках адрес wpnew.ru на адрес своего сайта. Файл robots.txt должен располагаться в корне блога, то есть в той же папке, где находятся папки wp-content, wp-admin и др. .
Те, кому же лень создавать данный текстовой файл, можете просто скачать robots.txt и также там подкорректировать 3 строчки.
Хочу отметить, что в техническими частями, о которых речь пойдет ниже, себя сильно загружать не нужно. Привожу их для “знаний”, так сказать общего кругозора, чтобы знали, что и зачем нужно.
Итак, строка:
User-agent
задает правила для какого-то поисковика: к примеру “*” (звездочкой) отмечено, что правила для всех поисковиков, а то, что ниже
User-agent: Yandex
означает, что данные правила только для Яндекса.
Disallow
Здесь же Вы “засовываете” разделы, которые НЕ нужно индексировать поисковикам. К примеру, на странице https://wpnew.ru/tag/seo у меня идет дубль статей (повторение) с обычными статьями, а дублирование страниц отрицательно сказывается на поисковом продвижении, поэтому, крайне желательно, данные секторы нужно закрыть от индексации, что мы и делаем с помощью этого правила:
Disallow: /tag
Так вот, в том robots.txt, который дан выше, от индексации закрыты почти все ненужные разделы сайта на WordPress, то есть просто оставьте все как есть.
Host
Здесь мы задаем главное зеркало сайта, о котором я рассказывал чуть выше.
Sitemap
В последних двух строчках мы задаем адрес до двух карт сайта, созданные с помощью плагина Google XML Sitemaps.
Возможные проблемы
Если у Вас на блоге не стоит ЧПУ (именно так у меня происходит с тем сайтом, которого я занимаюсь продвижением), то с тем robots.txt, который дан выше, могут быть проблемы. Напомню, что без ЧПУ ссылки на сайте на посты выглядят примерно следующим образом:
А вот из-за этой строчки в robots.txt, у меня перестали индексироваться посты сайта:
Disallow: /*?*
Как видите, эта самая строка в robots.txt запрещает индексирование статей, что естественно нам нисколько не нужно. Чтобы исправить это, просто нужно удалить эти 2 строчки (в правилах для всех поисковиков и для Яндекса) и окончательный правильный robots.txt для WordPress сайта без ЧПУ будет выглядеть следующим образом:
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
Host: wpnew.ru
Sitemap: https://wpnew.ru/sitemap.xml.gz
Sitemap: https://wpnew.ru/sitemap.xml
Анализ robots.txt
Чтобы проверить, правильно ли мы составили файл robots.txt я рекомендую Вам воспользоваться сервисом Яндекс Вебмастер (как регистрироваться в данном сервисе я рассказывал тут).
Заходим в раздел Настройки индексирования –> Анализ robots.txt:
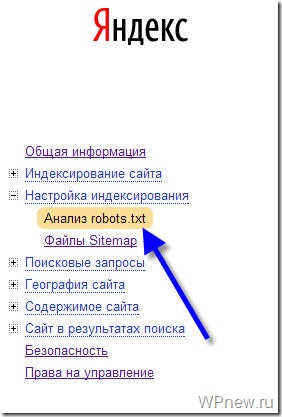
Уже там нажимаете на кнопку “Загрузить robots.txt с сайта”, а затем нажимаете на кнопку “Проверить”:
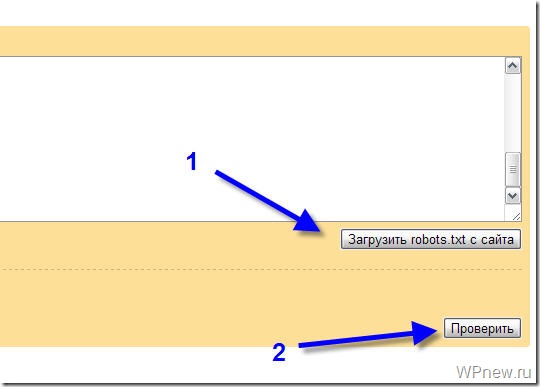
Если Вы увидите примерно следующее сообщение, значит у Вас правильный robots.txt для Яндекса:
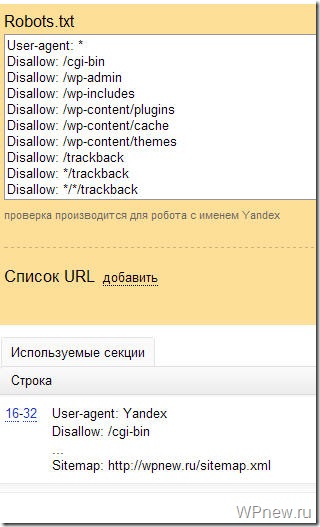
Также Вы можете в “Список URL” добавить адрес любой статьи сайта, чтобы проверить не запрещает ли robots.txt индексирование данной страницы:
Как видите, никакого запрета на индексирование страницы со стороны robots.txt мы не видим, значит все в порядке :).
Надеюсь больше вопросов, типа: как составить robots.txt или как сделать правильным данный файл у Вас не возникнет. В этом уроке я постарался показать Вам правильный пример robots.txt:
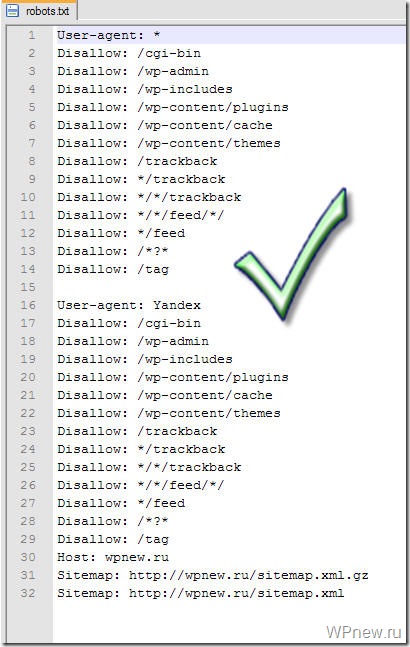
Вы можете посмотреть другие варианты, как еще можно составлять robots.txt.
До скорой встречи!
P.s. Совсем недавно я добавил блог в Яндекс Каталог, что же интересного произошло? 🙂