Время прочтения
6 мин
Просмотры 18K
В этой статье пойдет речь о том, как строятся персональные рекомендации на Avito. Исторически бизнес-модель Avito устроена так, что выдача объявлений в поиске происходит по времени их размещения. При этом пользователь может покупать дополнительные услуги для того, чтобы поднять свое объявление в поиске в том случае, если со временем объявление опустилось далеко в поисковой выдаче и перестало набирать просмотры и контакты.
В контексте данной бизнес-модели не очевидно, зачем нужны персональные рекомендации. Ведь они как раз нарушают логику сортировки по времени и те пользователи, которые платят за поднятие объявления, могут обидеться за то, что чье-то другое объявление мы «поднимаем» и показываем пользователю совершенно бесплатно только потому, что наша рекомендательная модель посчитала это объявление более релевантным для какого-то пользователя.
Однако сейчас персональные рекомендации становятся “must have” для классифайдов (и не только) по всему миру. Мы хотим помогать пользователю в поиске того, что ему нужно. Уже сейчас всё более значительная доля просмотров объявлений на Avito производится с рекомендаций на главной странице приложений или рекомендаций похожих объявлений на карточке товара. В этом посте я расскажу, какие именно задачи решает наша команда в Avito.

Виды рекомендаций
Сначала рассмотрим, какие типы рекомендаций могут быть полезны на Avito.
User-item рекомендации
В первую очередь это user-item рекомендации, то есть рекомендации объявлений для пользователя. Они могут быть двух типов. Первый — это товары или услуги, которые в настоящий момент ищет пользователь. Второй тип — дополняющие их товары или услуги. Например, чехлы для телефона, если человек ищет телефон. Или услуги перевозки мебели, если человек покупает или продает квартиру. Или кляссеры для хранения коллекции филателиста, если человек ищет почтовые марки.
User-item рекомендации мы доставляем до пользователей сейчас тремя способами:
- блоки с рекомендациями на главной странице мобильных приложений;
- баннеры с рекомендациями в поисковой выдаче на desktop;
- email- и push-рассылки с подборкой рекомендованных объявлений.
User-category рекомендации
Также бывает нужно рекомендовать не конкретные объявления, а категории товаров (user-category рекомендации), перейдя в которые пользователь уже сам уточняет поисковые фильтры. User-category рекомендации так же делятся на два типа: рекомендации категорий текущих интересов пользователя и кросс-категорийные рекомендации. Сейчас мы используем этот тип рекомендаций в push-рассылках и на главной странице приложений.
Кросс-категорийные рекомендации особенно важны для Avito, так как большинство пользователей Рунета так или иначе хоть раз пользовались Avito, но часто «сидят» в одной категории. Многие не догадываются, что на Avito кроме личных вещей еще можно эффективно продать квартиру или автомобиль. Кросс-категорийные рекомендации помогают нам расширить спектр категорий, в которых пользователь является продавцом или покупателем, и таким образом увеличить вовлеченность пользователей.
Item-item рекомендации
Еще одним перспективным направлением рекомендаций на Avito являются item-item рекомендации, то есть рекомендации товаров для других товаров. Этот тип рекомендаций также делится на рекомендации похожих товаров (аналоги) и дополняющих товаров или услуг. Это направление является особенно важным, так как, в отличие от медийных порталов (фильмы, музыка), пользователь, как правило, приходит на Avito за чем-то конкретным, и нам сложно заранее предсказать текущие предпочтения пользователей. Но если пользователь уже сам смотрит какой-то товар, то тут мы можем посоветовать ему альтернативы или дополняющие товары, и они с большой вероятностью будут релевантны его текущему поиску. Рекомендации похожих объявлений показываются на карточке объявления, а также используются в email- и push-рассылках.
User-item рекомендации для классифайдов
Теперь немного углубимся в задачу user-item рекомендаций, как наиболее интересную с теоретической точки зрения. Входными данными являются:
- история действий пользователей на сайте: просмотры, поисковые запросы, контакты, избранное;
- профили пользователей: данные из привязанных аккаунтов соц. сетей, локация;
- все активные объявления на Avito: заголовок, описание, параметры, цена.
При этом объем данных сравнительно большой: 20 млн. активных пользователей, 35 млн. активных объявлений.
Постановка задачи звучит следующим образом: для каждого активного пользователя показать top-N объявлений с наибольшей вероятностью запроса контакта (звонок или отправка сообщения).
Несмотря на то, что формулировка задачи звучит как классическая задача любой рекомендательной системы, её построение для Avito имеет существенные отличия от задач рекомендаций медийного контента: фильмов, музыки и прочего. Во-первых, ликвидные товары частников быстро продаются, не успев даже набрать хорошую историю по просмотрам и запросам контактов. Классические алгоритмы коллаборативной фильтрации устроены так, что объявления с короткой историей не попадают в рекомендации. Чаще рекомендуются долго живущие объявления, которые, как правило, представляют меньший интерес для покупателей.
Также пользователя, как правило, интересует типовой товар, для которого может быть много активных объявлений. Например, ему нужно купить конкретную модель iPhone, а у кого — уже не так важно. Поэтому строить рекомендации лучше не на объявлениях, а на типовых товарах. Для этого мы строим специальные алгоритмы кластеризации.
Еще одной особенностью рекомендаций на Avito является то, что объявления создаются обычными пользователями и содержат ошибки, неполные описания. Это приводит к тому, что нам приходится серьезно работать над text processing, извлечением полезных признаков из описаний объявлений.
Методы
Теперь несколько слов о том, какие методы мы используем для построения рекомендаций.
Offline-модели
Исторически мы использовали и продолжаем использовать модели, которые обрабатывают click stream пользователей в «batch» режиме. Эти алгоритмы позволяют реагировать на новые действия, совершенные пользователем, с отставанием в 1-2 часа. Мы называем их offline-моделями.
Offline-модели рекомендаций глобально делятся на коллаборативные и контентные. Очевидно, что каждая из этих моделей имеет свои плюсы и минусы и наилучшие результаты показывают гибридные модели, которые учитывают как историю действий пользователей, так и контент объявлений. Именно гибридную модель мы и используем в качестве основной для offline-рекомендаций.
Online-модели
Offline-модели способны генерировать качественные рекомендации, но они не могут быстро реагировать на изменения интересов пользователя. Это — их существенный минус. Например, если пользователь начал искать какой-то новый товар на Avito, то мы хотим в рамках той же сессии начать рекомендовать ему подходящие товары. Для этого мы должны в реальном времени учитывать интересы пользователя. Такие модели мы называем online-моделями.
Их особенностью является то, что они более сложны с архитектурной точки зрения (время от момента совершения действия пользователем до обновления рекомендаций — не более 1 секунды). Классическая online модель основана на построении online профиля интересов пользователя, с помощью которого отбираются самые свежие и релевантные объявления. Из-за жестких требований к производительности online-алгоритмы, как правило, более простые, чем offline.
Оценка качества моделей
После того, как новая модель создана, её нужно как-то оценить. Целевой метрикой по компании является прирост количества сделок на Avito. Все offline- и online-метрики так или иначе должны коррелировать с ней.
Для оценки offline-моделей существует ряд отличных метрик, таких как precision, recall, NDCG, R-score и другие.
Не всегда удается подобрать такие offline-метрики, которые хорошо коррелируют с целевой метрикой компании. Здесь на помощь приходят online-метрики (CTR, конверсия в контакты, прирост в уникальных покупателях). На online сплит-тестах мы можем сравнить рекомендации от различных моделей и различные frontend-интерфейсы. Для оптимизации метапараметров моделей хорошо подходит метод многоруких бандитов.
Итоги
Перед командой рекомендации Avito стоят амбициозные задачи, которые требуют глубокого и активного исследования методов рекомендаций, способных выдерживать нагрузки Avito по производительности и показывать отличные результаты на целевых метриках.
Для того, чтобы найти оптимальные подходы, мы читаем много статей, ездим и выступаем на конференциях и проводим конкурсы. Не так давно закончился наш конкурс по рекомендациям, и мы не планируем на этом останавливаться. Призываем всех заинтересованных помочь нам в этом нелегком труде путем участия в наших конкурсах. А мы постараемся не скупиться на призовые :). Также у нас периодически открываются вакансии, о которых мы обязательно сообщаем в slack-канале ODS.
Кроме этого, мы и сами участвуем в конкурсах. BTW, в 2016 и 2017 годах мы вошли в десятку лучших команд на крупнейшем международном соревновании по рекомендательным системам Recsys Challenge.
Спасибо за внимание!
Ручное редактирование десятков или сотен объявлений занимает много времени. Менеджер Авито по работе с рекламными агентствами Николай Кондратенко рассказал, как сэкономить время и быстро выгрузить объявления в нужную дату, дублировать на новые города, расставить визуальные акценты, загрузить изображения или изменить цены, а также перенести их в другой аккаунт.
Николай Кондратенко, Менеджер Авито по работе с рекламными агентствами
Предположим, вы создали объявления на Авито вручную. Продажи пошли, и спустя время вы решили масштабироваться. Например, показывать объявления жителям соседних городов, если это разрешено правилами Авито (зависит от категории), или публиковать их в определенные даты. Вы можете вручную скопировать и отредактировать объявления в интерфейсе Авито, но на это уйдет много времени, если у вас их больше десяти. Хорошая новость: можно легко и быстро редактировать или масштабировать объявления через файл обратной выгрузки.
 Николай Кондратенко, Менеджер Авито по работе с рекламными агентствами
Николай Кондратенко, Менеджер Авито по работе с рекламными агентствамиПолучайте до 8% от оборота клиентов на Авито
Продвигайте клиентов на Авито и возвращайте до 8% от их оборотов на площадке. Только для участников партнерской программы eLama
Узнать больше
Для чего нужен файл обратной выгрузки
Файл обратной выгрузки — это файл с данными об объявлениях, который можно скачать на Авито, отредактировать и загрузить обратно. Тогда все изменения появятся в объявлениях и вам не нужно будет менять их вручную.
Выгрузка в нужную дату
Зайдите в раздел «Автозагрузка», нажмите «Настройки» и выберите объявления, с которыми хотите работать — например, активные. Впишите почту и нажмите «Скачать файл с объявлениями». На почту придет письмо, в котором будет Excel-файл обратной выгрузки. В случае, если объявлений сотни, вы получите письмо в течение часа, если их меньше — быстрее.
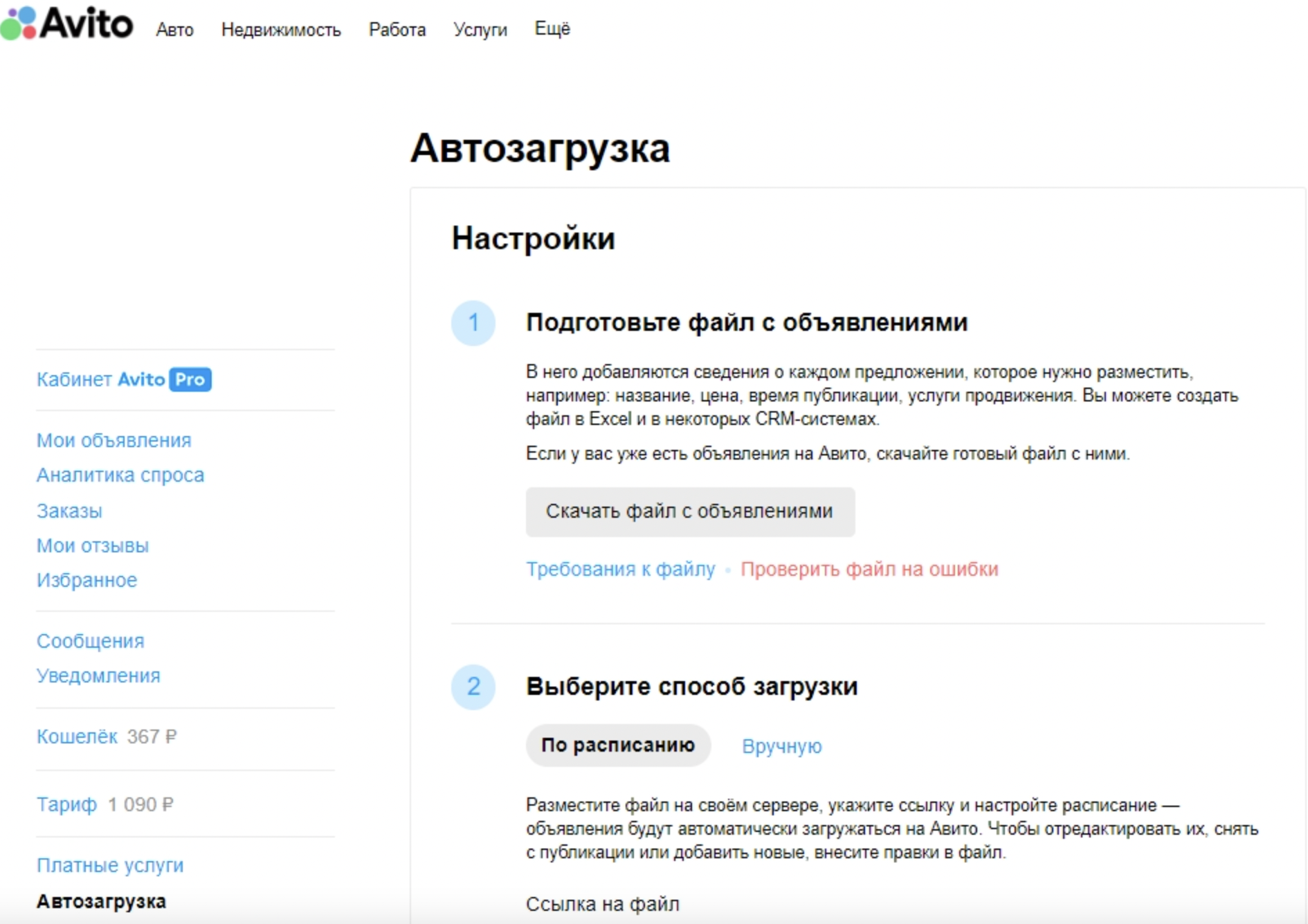
Откройте скачанный файл и добавьте в него столбец с заголовком DateBegin. Это параметр, который поможет опубликовать объявления на Авито в конкретный день и час.
Укажите в столбце DateBegin год, месяц и день напротив каждого объявления. Если важны конкретный час и минута, впишите и их по формату:
-
Дата: 2022-12-24,
-
Дата и время: 2022-12-22T17:35:00+03:00, где +03:00 — прибавка времени к часовому поясу Москвы. Например, если вы запускаете объявления в Омске.
В первом случае публикация пройдет в начале дня по московскому времени, во втором — с точностью до часа.
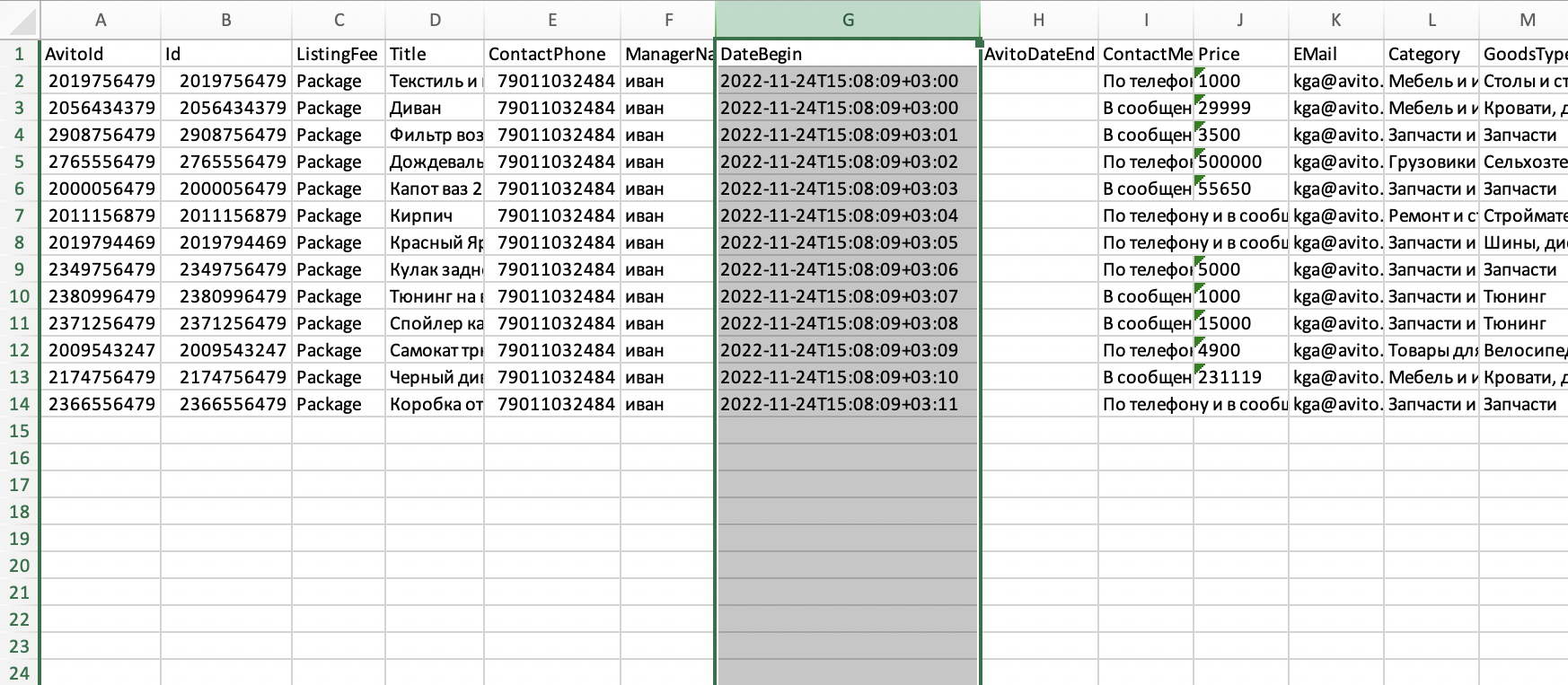
Подпись: В примере DateBegin мы вставили в столбец G Alt + Shift + 5
Затем вернитесь в раздел «Автозагрузка» и загрузите файл с объявлениями обратно на Авито. Для этого в настройках укажите способ загрузки «Вручную», выберите файл и загрузите его. Теперь объявления появятся в вашем аккаунте в нужные даты и часы.
Важно: активировать в конкретную дату можно либо новые объявления, которые вы еще не запускали, либо объявления, со дня публикации которых прошло более 30 дней. Если поставить DateBegin на завтра объявлению, которое мы разместили вчера, оно не активируется заново: сначала должны открутиться 30 дней.
Дублирование на несколько городов
Предположим, вы проводите онлайн-консультации и размещаете объявления о них в Москве, Петербурге, Сочи, Красноярске и других городах. Создавать копии объявлений вручную долго. Вместо этого можно сделать вручную одно объявление и скопировать его для других городов с помощью файла обратной выгрузки.
Создайте первое качественное объявление: с оптимальным фото, заголовком и описанием. Опубликуйте его и выгрузите в формате Excel.
Идите путем, описанным выше: зайдите в раздел «Автозагрузка», нажмите «Настройки» и выберите объявления, с которыми хотите работать. Укажите почту, нажмите «Скачать файл с объявлениями» и получите на почту письмо с Excel-файлом обратной выгрузки.
Затем:
- Скопируйте строки параметров объявлений, начиная с третьего столбца.
- Вставьте копии сразу под оригинальными параметрами.
- В скопированных строках замените город. Публиковать объявления в разных городах можно в определенных категориях — посмотрите условия в справке Авито.
- Повторите несколько раз, чтобы разместить объявления в нужных городах.
- Первый столбец не нужно заполнять — в нем находится Авито ID, который Авито сам присваивает объявлениям.
- Второй столбец — это внутренний ID объявления, в нем можно поставить цифру 1 и растянуть на все объявления в каждом городе.
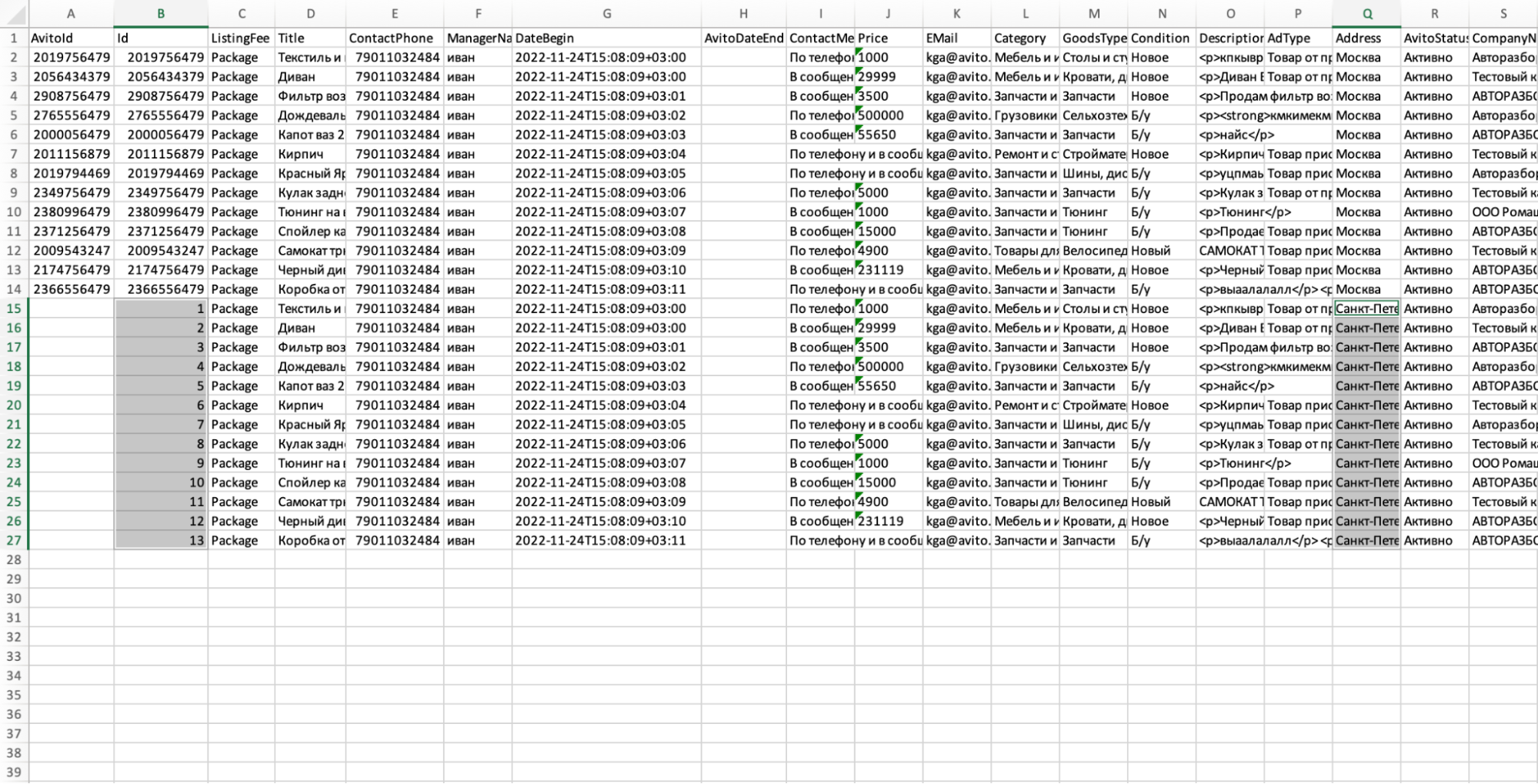
Подпись к изображению: Должно получиться так: у новых объявлений новые ID во втором столбце и новый город
Сохраните файл, в разделе «Автозагрузка» зайдите в настройки — укажите способ загрузки «Вручную» — выбрать файл и загрузить его.
Визуальные акценты в заголовке и описании
В опубликованных объявлениях можно визуально выделять заголовок и описание. Для этого выгрузите в разделе «Автозагрузка» XML- или XLS-файл с объявлениями, а затем используйте Online HTML Editor:
- Откройте Online HTML Editor.
- Вставьте в поле слева текст из описания объявления.
- Выделите жирным слова, к которым хотите привлечь внимание.
- Опишите свойства товара в виде списка и выделите буллетами.
- Скопируйте код из правого поля и вставьте в исходный файл в столбец Description.
- Загрузите файл обратно на Авито.
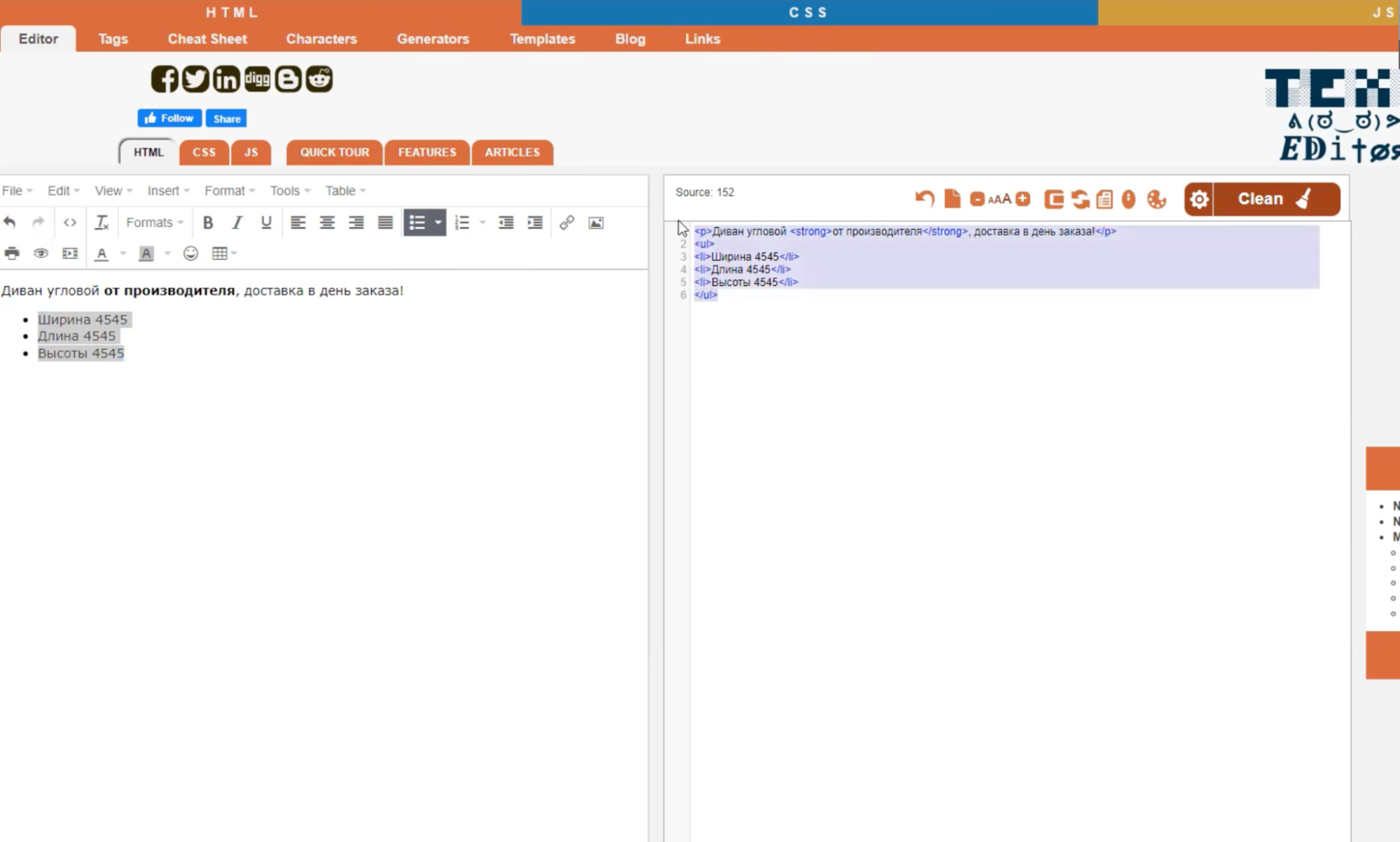
Теперь в объявлении появятся визуальные акценты, а вы можете вносить их не вручную, а массово.
Загрузка изображений
Чтобы загрузить изображения объявлений через файл автозагрузки, нужно найти столбец Image Urls. Вставьте в него прямую ссылку на изображение. Ссылка на Google Диск не подойдет: найдите способ открыть картинку в браузере, скопируйте URL и для проверки вставьте в адресную строку. По ссылке должна открываться только картинка.
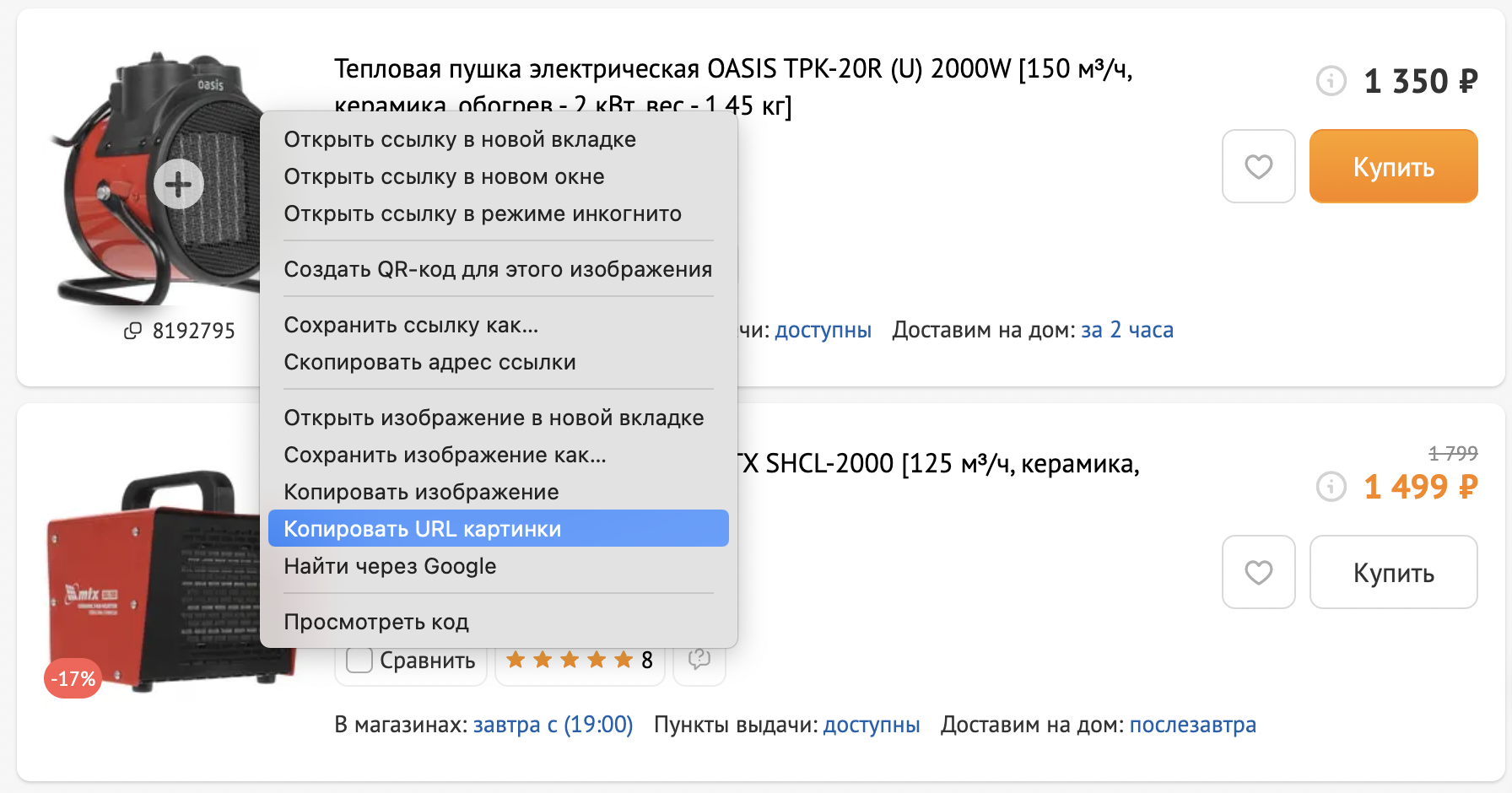
Теперь добавьте этот URL в нужные объявления в Excel-таблице, и загрузка файла обновит их изображения на Авито.
Изменение цен
Вы можете быстро скорректировать цены через кабинет Авито Pro или через файл обратной загрузки.
Если у вас 10-20 объявлений:
- Зайдите в кабинет Авито Pro.
- Отметьте галочкой нужные объявления.
- Нажмите «Изменить цену» и увеличьте или уменьшите ее на несколько процентов.
Если у вас 100-200 объявлений, выгрузите Excel-файл, замените цены на актуальные в столбце Prices и загрузите файл обратно на Авито.
Перенос объявлений между аккаунтами: 2 способа
Предположим, вам нужно перенести объявления с одной учетной записи в другую. Это можно сделать двумя способами — через службу поддержки и через обратную выгрузку.
Через службу поддержки
Для удобства пронумеруем учетные записи:
- Первая запись — та, в которой опубликованы объявления.
- Вторая запись — та, в которую его нужно перенести.
В начале получите ID объявлений, которые хотите перенести. Для этого выгрузите файл в разделе «Автозагрузка» либо зайдите в статистику кабинета Avito Pro, там выберите «Общая» и скачайте отчет в XLS. В обоих случаях вы получите файл, внутри которого будут ID объявлений.
Сохраните ID объявлений, которые нужно перенести, в новый файл и отправьте на почту поддержки shop_support@avito.ru два письма.
С первой учетной записи напишите: «Добрый день! Нам нужно перенести объявления из вложения в другую учетную запись (укажите ID второй записи)». И прикрепите к письму таблицу с ID объявлений.
Со второй учетной записи напишите: «Добрый день! Нам нужно загрузить эти объявления с учетной записи (укажите ID первой записи)». И снова прикрепите к письму таблицу с ID объявлений.
Поддержка поймет, что обе учетные записи связаны, и перенесет объявления.
Если во второй учетной записи оплачен и активен тариф, то новые объявления будут сразу активированы. Если у обеих записей нет тарифов, тогда нужно в чате службы поддержки с каждой учетной записи написать «Нам нужно перенести объявления». Поддержка напишет на почты обеих записей ответ: пришлите ID объявлений, которые нужно перенести. Прикрепите в ответ ID объявлений и поддержка их перенесет.
Через файл обратной загрузки
В личном кабинете зайдите в раздел «Автозагрузка», выберите настройки и скачайте файл с объявлениями. Напишите письмо в службу поддержки по адресу shop_support@avito.ru
«Добрый день! Мы сделали обратную выгрузку и собираемся перевыставить эти объявления из-под учетной записи с ID NNNNNN (укажите ID второй записи). Заблокируйте их, пожалуйста, в текущей учетной записи».
Так вы предупредите поддержку: она не посчитает подозрительными новые объявления во второй записи и не заблокирует их. Дождитесь ответа о том, что старые объявления заблокированы, и загрузите файл с объявлениями в разделе «Автозагрузка» в новой учетной записи.
Читайте также: Как составить объявление и не получить отклонение или блокировку
Используйте лайфхаки для массового редактирования объявлений на Авито и экономьте время!
Авито умный сервис, и если допускать ошибки в публикации объявлений, то позиции будут очень низкими в выдаче. Давайте разберем топ 10 ошибок, которые совершают Авитологи, маркетологи, пользователи и новички на Авито.
Ошибка №1. Релевантность заголовка. Заголовок не соответствует поисковому запросу клиента.
Чтобы избежать этой ошибки, мы должны следовать правилам:
- Названия объявлений должны соответствовать поисковым запросам покупателей. Для этого у нас есть поисковые подсказки. Авито нам подсказывает, как люди ищут, а мы должны свои объявления соответственно назвать. То есть мы должны ответить на ключевой вопрос нашего клиента.
- Мы должны использовать Seo оптимизацию. Объявление должно быть уникальным и оптимизированным под поисковые запросы Авито.
Подробнее о том, как искать поисковые подсказки мы рассматривали в статье Составляем заголовок объявления с помощью Авито подсказок
Ошибка № 2. Релевантность фото к заголовку. Фото визуально не отвечает поисковому запросу.
Если в объявлении указана, например, услуга электрика, то и на фото должен быть изображен электрик, а не сантехник. Это происходит, когда в одном объявлении пытаются скомпоновать все услуги. То есть в универсальном объявлении и фото должно быть универсальным.
Ошибка №3. Несоответствующий формат фото.
Как этого избежать:
- Используйте горизонтальный формат фото.
- Не используйте вместо фото ваш логотип.
- Не перегружайте фото информацией.
- Используйте реальные, живые фото.
- Не используйте фото товара с маркетплейсов.

Здесь хорошо видно, что первое фото никак не соответствует заголовку «Электрик».
Во втором фото был использован логотип, который визуально не отвечает нашему поисковому запросу, тем белее логотип не популярен и никому неизвестен. На Авито нет продвижения брендов. Авито — это для получения максимально горячих клиентов. Поэтому этот логотип вообще не уместен.
Третье фото слишком перегружено информацией и совершенно нечитабельно. Много маленьких фотографий, много маленьких текстов, обрезано и т. д.

Это фото очень бросается в глаза своей нереальностью. Оно красивое, но сразу заметно, что сделано в студии. На фотографии изображен не живой сантехник, слегка помятый и небритый, а какай-то Супер-Марио. Клиенту сразу понятно, что вы скачали эту фотографию из интернета, и доверие к вам падает.
Ошибка № 3.1. Количество фото в объявлении
Минимальное количество фотографий в объявлении — 3 шт. Но лучше загружайте все допустимое количество фотографий в вашей нише.
Здесь основная ошибка, которая может произойти — это когда вы примените к своему объявлению XL услугу. Это значит, что объявление становится большим. Его телефоне видно очень хорошо, а на компьютере это будет выглядеть как три маленьких фотографии. Как на примере: есть две фотографии под основной большой:

Посмотрите на фото ниже. Несмотря на то, что пользователь применил услугу XL, чтобы увеличить свое объявление, но по факту он эту услугу не использовал. Площадь, занимаемая этим объявлением, тоже меньше, чем, когда у нас вот эти все три фотографии отображаются. А это значит, у клиента взгляд на ваше объявление больше цепляется.

Получается что если фото мало, то деньги потраченные на XL-услугу потрачены зря.
Ошибка № 4. Нереальная цена либо сильно занижена.
Как её избежать:
- Не указывайте цену в 1 рубль.
- Не указывайте заниженную цену.
- Можно указать «Цена договорная».

В случае указания цены в 1 рубль — мы понимаем, что это изначально ложь. Недоверие клиента на высоком уровне, вам не напишут и не позвонят.
В случае указания цены ниже рыночной — Авито такие объявления будет понижать в выдаче.
Ошибка № 5. Нет выгоды клиента. Не продублирован заголовок в тексте объявления.
Действительно, дублировать заголовок в тексте объявления достаточно важно. Потому что роботы индексируют не только заголовки, но и считывают данные самого объявления. Чем быстрее робот наткнется на тот самый заветный поисковый запрос, тем выше вероятность того, что ваше объявление покажется в рекомендации или по поисковой выдаче клиента.
Немаловажный момент, когда вы в самом начале текста должны дать выгоду, пользу или «плюшку» для клиента. То есть дать что-то важное. Или ответить на боли клиента, закрыть его потребности. Ни в коем случае не надо говорить о том, какие мы замечательные, какие мы хорошие и как много мы хотим на вас заработать денег.
Ошибка № 6. Нет призыва к действию либо он неправильный.
Чтобы это не допустить:
- Не прописывайте ссылки на какие-либо социальные сети.
- Не прописывайте ссылки на интернет-магазин.
- Сделайте 3 целевых действия в тексте объявления
- Добавить в избранное
- Написать сообщение
- Показать телефон
Помните, что объявление на Авито — это самостоятельная рекламная площадка. Задача этих объявлений — получить контакт, а не отправить куда-то. Вы должны дделать призыв к действию в т. Такие целевые действия не только сподвигнут вашего клиента на контакт с вами, но и для роботов Авито это означает, что ваше объявление живое, интересное, на него кликают. То есть, помимо того, что на ваше объявление зашли, ещё внутри самого объявления нужно сделать целевые действия, чтобы заработать хороший CTR для Авито.
У клиентов в основном установлено мобильное приложение и тем, кто добавили ваше объявление в избранное, Авито периодически присылает напоминание.
Авито максимально помогает и подкидывает эти push-уведомления на мобильные устройства вашего клиента.
Ошибка № 7. Спам ключи съедают бюджет иксовых услуг и «убивают» выдачу обычных.
Все это происходит потому, что мы хотим максимально показаться по большому количеству поисковых запросов и буквально запихиваем все возможные ключи в одно объявление. Но алгоритмы Авито так не работают. Потому что у нас есть заголовок объявления. У этого заголовка объявления есть конкретное название и описание, которому соответствуют определенные ключи. А если эти ключи не соответствуют заголовку и описанию, то алгоритмы Авито просто не знают, по какому ключу вас рекомендовать и не показывают ваше объявление. А если вы продвигаете свои объявления платно через икс услуги, то вы просто сжигаете бюджет.
Пример. Ваш клиент ищет «фанера» и ваше объявление показывается под словом «фанера», но заголовке написано «Утеплитель battle» и фотография утеплителя. А клиент ищет фанеру, то есть он не получает ответ на свой поисковый запрос. Авито свою миссию выполнил. Он показал ваше объявление, потому что вы заплатили. Авито гарантирует вам увеличить количество просмотров в десять раз, но ведь не гарантирует, что на ваше объявление кликнут и что у вас будут просмотры. Тем самым вы этими не целевыми поисковыми запросами просто сжигаете бюджет иксовых услуг. И вместо того, чтобы рекламироваться по конкретному поисковому запросу, вы в своё объявление напихали кучу нецелевых поисковых запросов.
Ошибка № 8. «Простыня» текста. Нет четкого разделения на абзацы или же «провалена» вся структуризация текста.
Этого можно избежать, если:
- Разбить текст на абзацы.
- Использовать межстрочные интервальные промежутки.
- Использовать разные шрифты для выделения информации.
- Структурировать текст.
Здесь имеется ввиду визуальное восприятие текста и читабельность этих объявлений. Необходимо помнить, что 70% пользователей используют Авито с помощью мобильного приложения на телефоне.
Ошибка № 9. Нет рейтинга и доверия. Нет статистики отправок Авито доставкой
Это не совсем ошибка. Это замечание, которое относится к новичкам на Авито, которые еще не имеют свой рейтинг. Помимо рейтинга, есть еще так называемая проверка своего аккаунта. Должны быть подтверждены реквизиты. Это тоже влияет не только на доверие, но и на выдачу.

Авито доставка на сегодняшний день — достаточно мощный инструмент в продажах. Клиенты очень часто используют Авито доставку в другие регионы или в переделах города. Опыт продавца с Авито доставкой указывается в профиле, что повышает доверие к продавцу.
Особенно это очень печально, когда вы продвигаете свои объявления через иксовые услуги.
Предположим вы разместили 100 объявлений, не купив при этом ни «Расширенный», ни «Максимальный» тариф. В итоге, когда ваш потенциальный клиент заходит на ваше объявление, он читает ваши объявления, спускается вниз, и ему идет рекомендация от других аккаунтов.
- В «Базовом» тарифе показываются рядом с вашими объявлениями и объявления вашего конкурента.
- А в «Расширенном тарифе» отображаются только ваши объявления. И ни в коем случае бы клиент уже не перешел на вашего конкурента. Вы на самом деле за свои деньги рекламируете своих конкурентов. Это реальная ошибка. Лучше переплатите за «Расширенный» тариф. И будьте спокойны, что вы в своих объявлениях вы не будете рекламировать своих конкурентов.
Бонусный совет — следите за Топ-выдачей!
Важно автомате мониторить свои объявления. То есть мониторить Топ-выдачи, чтобы вовремя реагировать на ситуацию. Применять, если нужно, платные услуги продвижения и, естественно, обходить своих конкурентов.
Это достаточно легко делать с помощью инструмента Мониторинг поисковой выдачи Авито
Привет! Меня зовут Василий Копытов, я руковожу группой разработки рекомендаций в Авито. Мы занимается системами, которые предоставляют пользователю персонализированные объявления на сайте и в приложениях. На примере нашего основного сервиса покажу, когда стоит переходить с Python на Go, а когда нужно оставить всё как есть. В конце дам несколько советов по оптимизации сервисов на Python.

Как работают рекомендации на главной Авито
Любой человек, который зашёл на главную страницу сайта или приложения, видит персональную ленту объявлений — рекомендации. Нагрузка на наш основной сервис рекомендаций representation, который отвечает за формирование бесконечной ленты айтемов на главной, порядка 200 000 запросов в минуту. Весь трафик за рекомендациями — порядка 500 000 запросов в минуту.

Сервис representation выбирает самые подходящие объявления из 100 миллионов активных объявлений (айтемов) под каждого пользователя. Рекомендации формируются на основе всех действий человека за последний месяц.
Representation работает по такому алгоритму:
-
Сервис обращается к хранилищу истории пользователя и забирает из него агрегированную историю и интересы.
Интересы — это набор категорий и подкатегорий объявлений, которые в последнее время просматривал человек. Например, детская одежда, товары для рукоделия или домашние животные.
-
Затем передаёт историю и интересы, как набор параметров, нескольким ML-моделям первого уровня
ML-модели первого уровня — это нижележащие сервисы. Сейчас у нас 4 таких модели. Они предсказывают айтемы по различным алгоритмам машинного обучения. На выходе от каждого сервиса получаем список id (рекомендованных айтемов).
-
Фильтруем id на основе истории пользователя. В итоге получается примерно 3000 айтемов на один аккаунт.
-
И самое интересное — representation внутри себя использует ML-модель второго уровня на основе CatBoost для ранжирования объявлений от ML-моделей первого уровня в realtime.
-
Из данных готовятся фичи — параметры для ранжирования рекомендаций. Для этого по id айтема идем за данными в хранилище (1 TB шардированный Redis). Данные айтема — title, цена и много еще чего, порядка 50 полей.
-
Сервис передает фичи и айтемы в ML-модель второго уровня на основе библиотеки CatBoost. На выходе получаем отранжированную ленту объявлений.
-
Далее representation выполняет бизнес-логику. Например, поднимает в ленте те объявления, для которых оплачено премиум-размещение (boost VAS).
-
Отдаём сформированную ленту рекомендаций пользователю, в ленте около 3000 объявлений.

Почему мы решили переписать сервис рекомендаций
Representation — один из самых высоконагруженных сервисов в Авито. Он обрабатывает 200 000 запросов в минуту. Сервис стал таким не сразу: мы постоянно внедряли что-то новое и улучшали качество рекомендаций. В какой-то момент он начал потреблять почти столько же ресурсов, сколько и остаток монолита Avito. Нам стало тяжело выкатывать сервис днём, в часы пик, из-за нехватки ресурсов в кластере — в это время большинство разработчиков деплоило свои сервисы.

Одновременно с ростом потребления ресурсов росло и время ответа сервиса. Во время пиковых нагрузок пользователь мог ждать свои рекомендации до 1,6 секунды — это 8-ми кратный рост за последние 2 года. Все это могло заблокировать дальнейшую разработку и улучшение рекомендаций.
Причины всего этого достаточно очевидны:
-
Большая IO-bound нагрузка. В representation каждый запрос состоит из примерно 20 корутин — блоков кода, которые работают асинхронно во время обработки сетевых запросов.
-
CPU-bound нагрузка от realtime вычислений ML-моделью, которые полностью занимает CPU, пока происходит ранжирование объявлений.
-
GIL — representation изначально был написан на однопоточном Python. На этом языке невозможно совместить IO-bound и CPU-bound нагрузки так, чтобы сервис использовал ресурсы эффективно.
Как мы решали проблемы с сервисом рекомендаций
Давайте расскажу, что нам помогло жить под нашими нагрузками на Python:
-
ProcessPoolExecutor
ProcessPoolExecutor создает пул из ядер процессора — воркеров. Каждый воркер представляет собой отдельный процесс, который будет выполняться на отдельном ядре. В такой воркер можно передать CPU-bound нагрузку, чтобы она не тормозила другие процессы в сервисе.
В representation мы изначально использовали ProcessPoolExecutor, чтобы разделить CPU-bound и IO-bound нагрузки. Помимо основного питонячьего процесса, которые обслуживает запросы и ходит по сети (IO-bound) мы выделили три воркера для ML-модели (CPU-bound).
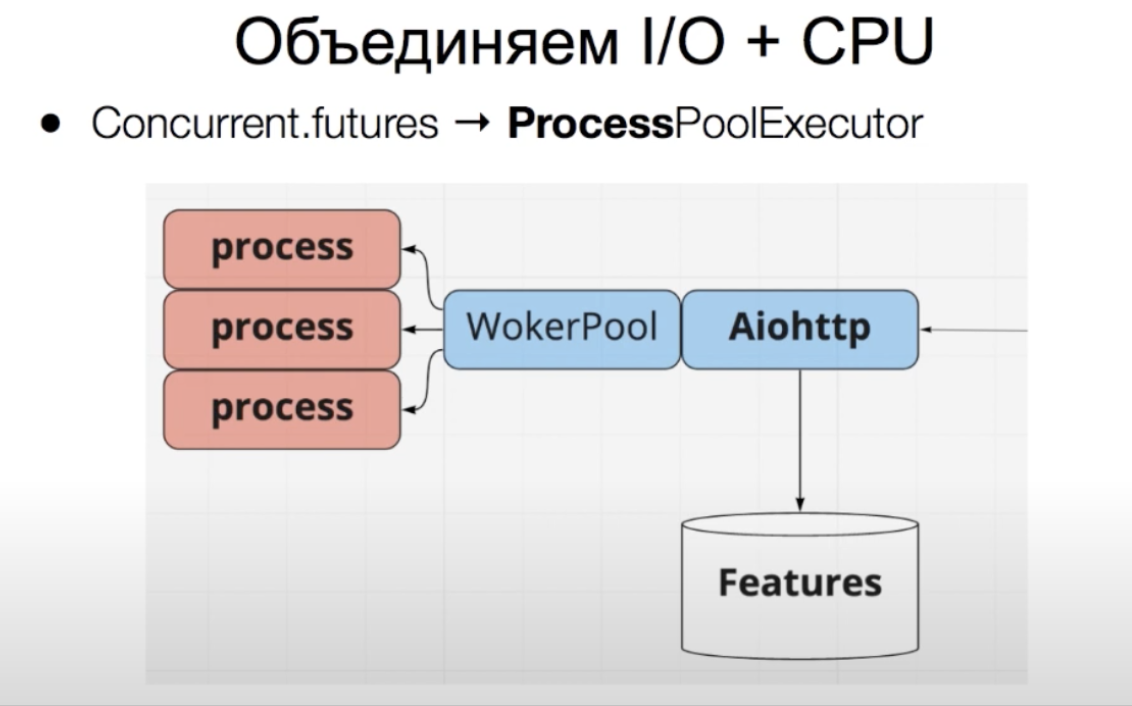
У нас есть асинхронный сервис на aiohttp, который обслуживает запросы и успешно справляется с IO-bound нагрузкой. ProcessPoolExecutor создает пул из ядер процессора — воркеров. Это отдельные процессы, которые будут выполняться на отдельном ядре. В такой воркер можно передать CPU-bound нагрузку, чтобы она не тормозила корутины в основном процессе сервиса и влияла на latency всего сервиса.
Выигрыш по времени от использования ProcessPoolExecutor около 35%. Для эксперимента мы решили сделать код синхронным и отключили ProcessPoolExecutor. То есть IO-bound и CPU-bound нагрузка стала выполняться в одном процессе.

Как это выглядит в коде:
async def process_request(user_id):
# I/O task
async with session.post(feature_service_url,
json={'user_id': user_id}) as resp:
features = await resp.json()
return featuresУ нас есть асинхронный хэндлер который обрабатывает запрос. Для тех кто не знаком с async await — служебные слова, которые означают точки переключения корутин.
То есть на строчке 5 у нас корутина засыпает и отдает выполнение другой корутине в сервисе, которой уже пришли данные — тем самым мы экономим процессорное время. В питоне таком образом реализована кооперативная многозадачность.
def predict(features)
preprocessed_features = processor.preprocess(features)
return model.infer(preprocessed_features)
async def process_request(user_id):
# I/O task
async with session.post(feature_service_url,
json={'user_id': user_id}) as resp:
features = await resp.json()
# blocking CPU task
return predict(features)Вдруг нам понадобилось выполнить cpu-bound нагрузку от ml модели. Функция predict. И вот на строчке 12 наша корутина заблокирует питонячий процесс пока не выполнится, соответственно все запросы на сервис встанут в очередь и время ответа сервиса вырастет как мы видели ранее.
executor = concurrent.futures.ProcessPoolExecutor(man_workers=N)
def predict(features):
preprocessed_features = processor.preprocess(features)
return model.infer(preprocessed_features)
async def process_request(user_id):
# I/O task
async with session.post(feature_service_url,
json={'user_id': user_id}) as resp:
features = await resp.json()
# Non blocking CPU task
return await loop.run_in_executor(executor, predict(features))Тут появляется ProcessPoolExecutor со своим пулом воркеров, который решает эту проблему. На строке 1 мы создаем пул. На строке 15 берем оттуда воркер и перекидываем CPU-bound задачу на отдельное ядро, таким образом функция predict будет исполнятся асинхронно по отношению к родительскому процессу и не блокировать его. Самое приятное, что все это будет обернуто в обычный синтаксис async-await и CPU-bound задачи будут выполняться асинхронно наравне с IO-bound задачами, но под капотом будет дополнительная магия с процессами.
Видео, в котором подробнее рассказывается про CPU-bound задачи в Python.
ProcessPoolExecutor позволил нам уменьшить оверхед от realtime ml модели, но даже с ним в какой-то момент стало плохо. Первым делом начали с самого очевидного — профилирование и поиск узких мест.
-
Профилирование сервиса и поиск узких мест
Даже если сервис пишут опытные программисты — в нём есть, что улучшать. Чтобы понять, какие участки кода работают медленно, а какие быстро, мы профилировали сервис с помощью профайлера py-spy.
Профайлер строит диаграмму, на которой горизонтальные полосы означают, сколько процентов процессорного времени тратит участок кода. Первое, что увидели — это 3 столбика справа. Это как раз наши дочерние процессы для скоринга фичей ml моделью.
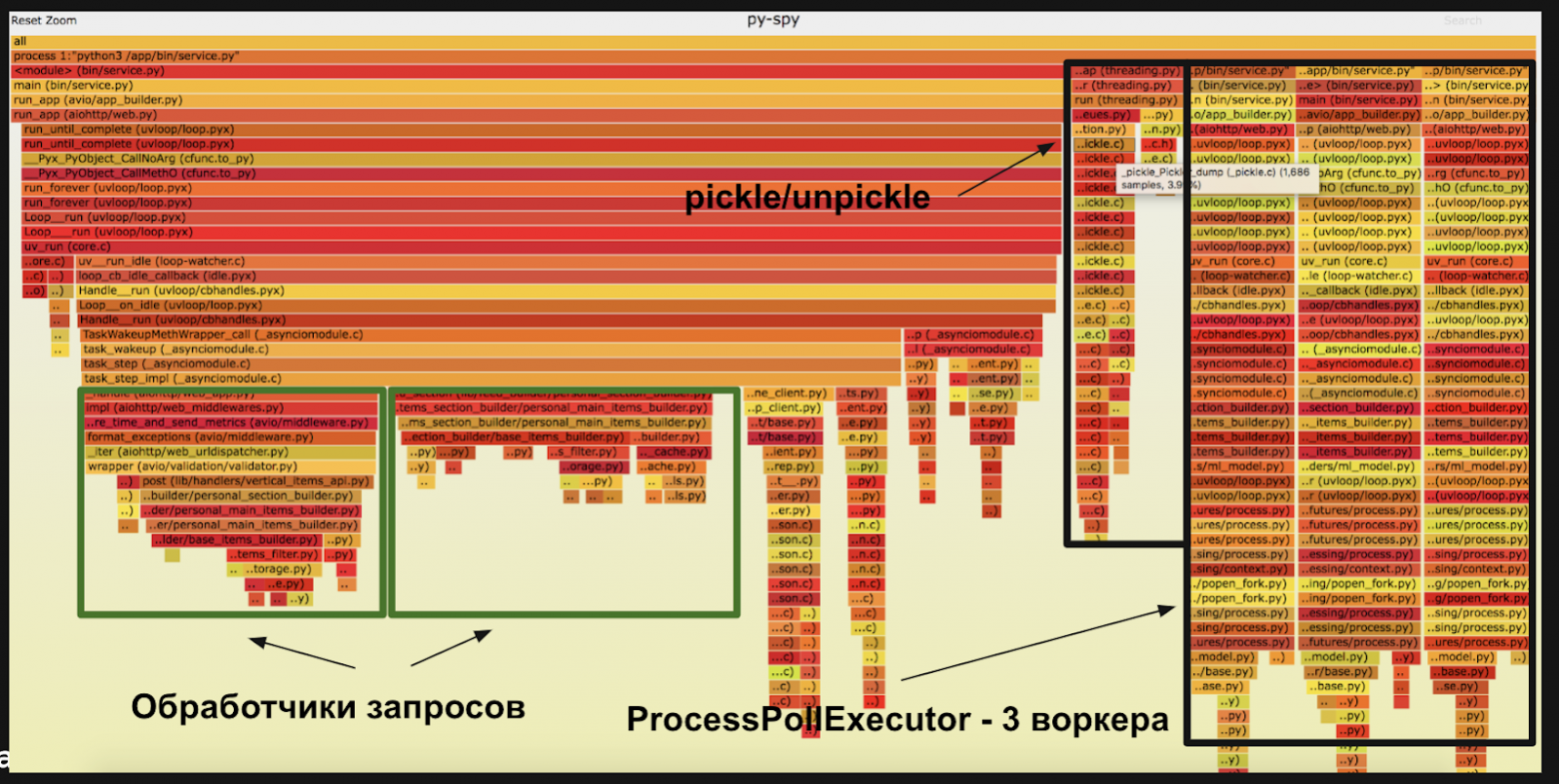
По flame графу мы увидели интересные детали:
-
7% времени процессор тратит на сериализацию данных между процессами. Сериализация — это перекодирование данных в байты. В Python этот процесс называется pickle, а обратный ему — unpickle.
-
3% времени уходит на накладные расходы ProcessPoolExecutor — подготовку пула воркеров и распределение нагрузки между ними.
-
6,7% времени занимает сериализация данных для сетевых запросов в json.loads и json.dumps.
Помимо процентного распределения мы хотели узнать конкретное время, которое занимают разные участки кода. Для этого снова отключили ProcessPoolExecutor, запустили ML-модель для ранжирования синхронно.
")
Но выросло время ответа самого сервиса по причинам описанным выше. Конкретный участок кода стал быстрее, но сам сервис медленнее.

После экспериментов выяснили:
-
Накладные расходы ProcessPoolExecutor составляют примерно 100 миллисекунд.
-
IO-bound запросы от корутин ожидают 80 миллисекунд, то есть корутина уснула и EventLoop до нее добирается вновь через 80 ms, чтобы возобновить ее выполнение. В representation три больших группы IO-bound запросов — итого 240 миллисекунд уходит на IO-wait.
Тут мы впервые задумались перейти на Go, так как в нем из коробки реализована более эффективная модель шедулинга рутин.
-
Разделили cpu-bound и io-bound нагрузку на 2 отдельных сервиса
Одно из крупных изменений, которое мы попробовали, — убрать ML-модель в отдельный сервис rec-ranker. То есть остался наш сервис representation в котором только сетевые запросы, а скоринг ml модели был на отдельном сервисе rec-ranker в который мы передавали все необходимые данные и возвращали скоры для ранжирования. Казалось что чуть снизим latency и будем раздельно масштабировать обе части.
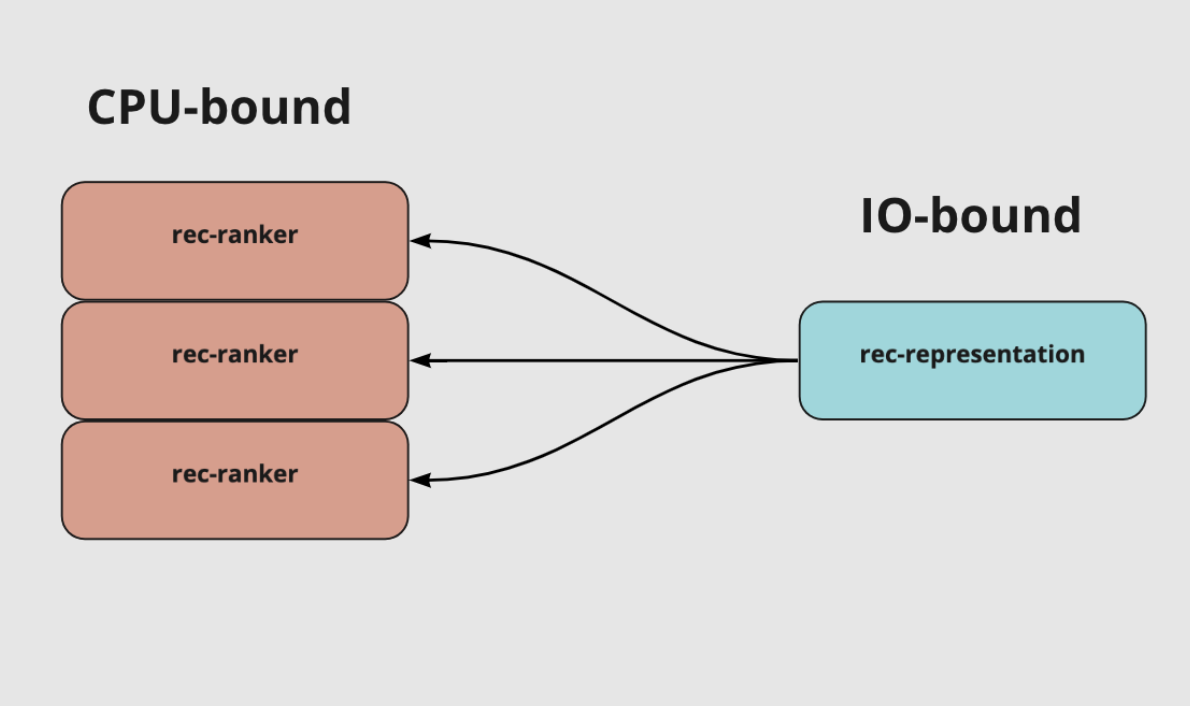
Эксперимент показал: мы экономим время на работе модели, но получаем задержку в 270 миллисекунд при передаче данных по сети и json.loads/json.dumps. На один запрос нужно пересылать примерно 4 Мб, а для очень активных пользователей — до 12 Мб данных для ml модели. После масштабирования реплик rec-ranker стало не намного меньше, чем у старого representation, а время ответа тоже самое, был mvp не с самой удачной архитектурой для проверки гипотезы. Для нашего кейса разделение на сервисы оказалось неудачным решением, поэтому мы вернулись к предыдущей реализации representation.
-
Оценили Shared Memory
В сервисе representation данные между процессами передаются через pickle/unpickle. Вместо этого в процессах, которые делятся данными, можно указать на общий участок памяти. Так экономится время на сериализации.
По максимальным оценкам можно выиграть примерно 70 миллисекунд на сериализации и еще примерно на такое же время — 70 миллисекунд уменьшается время выполнения запроса, так как pickle/unpickle — CPU-bound нагрузка и она лочила основной python процесс, который обрабатывал запросы от пользователей, то есть всего 140 миллисекунд. Этот вывод мы сделали на основе профайла: pickle/unpickle занимает всего 7% процессорного времени, большого профита от shared memory мы не получили бы.
-
Сделали подготовку фичей на Go
Мы решили проверить эффективность Go сначала на части сервиса. Для эксперимента выбрали самую тяжелую cpu-bound задачу в сервисе — подготовку фичей.
Фичи в сервисе рекомендация — это данные айтема. Например, название объявления, цена, информация о показах и кликах. Всего около 60 параметров, которые влияют на результат работы ML-модели, то есть мы подготавливаем все эти данные для 3000 айтемов и отправляем в модель, она отдает скор для каждого по которому мы ранжируем ленту.
Чтобы связать код на Go для подготовки фичей с остальным кодом сервиса на Python, мы использовали ctypes.
def get_predictions(
raw_data: bytes,
model_ptr: POINTER(c_void_p),
size: int,
) -> list:
raw_predictions = lib.GetPredictionsWithModel(
GoString(raw_data, len(raw_data)),
model_ptr,
)
predictions = [raw_predictions[i] for i in range(size)]
return predictionsТак выглядит подготовка фичей внутри Python. Модуль lib это скомпилированный гошный пакет в котором есть функция GetPredictionsWithModel в которую мы передаем байты с данными об айтемах и указатель на ML модель. Все фичи подготавливаются для модели гошным кодом.
Результаты нас впечатлили:
-
фичи на go считаются в 20-30 раз быстрее;
-
весь шаг ранжирования ускорился в 3 раза учитываю лишнюю сериализаю десиарилизацию данных в байты;
-
ответ главной упал на 35 процентов.


Итоги
После всех экспериментов сделали три вывода:
-
Фичи на Go для 3000 айтемов на запрос считаются в 20-30 раз быстрее, экономия 30% времени.
-
ProcessPoolExecutor тратит около 10% времени;
-
Три группы io-bound-запросов занимают 25% времени на пустое ожидание.
-
После перехода на Go сэкономим примерно 65% времени.
Переписали все на Go
В representation-go есть ML-модель. Нативно кажется что ml дружит только с питоном, но в нашем случае ml модель на CatBoost и у нее есть С API, которое можно вызывать из Go. Этим мы и воспользовались.
Ниже кусочек кода в Go, подробно на этом останавливаться не буду, отмечу только, что это работает и инференс дает такие же результаты как в питоне. Можно загуглить и вы увидите в официальной документации что-то подобное. C — псевдопакет, который предоставляет Go интерфейс для взаимодействия с библиотеками на C.
if !C.CalcModelPrediction(
model.Handler,
C.size_t(nSamples),
floatsC,
C.size_t(floatFeaturesCount),
catsC,
C.size_t(categoryFeaturesCount),
(*C.double)(&results[0]),
C.size_t(nSamples),
) {
return nil, getError()
}Есть проблема в том, что обучение ml модели по прежнему на питоне. И чтобы она обучалась и скорилась на одних и тех же фичах, важно, чтобы они не разъехались.
Подготавливать их мы стали с помощью кода Go сервиса. Обучение происходит на отдельных машинах, туда скачивается код сервиса на Go, фичи подготавливаются этим кодом, сохраняются в файл, потом Python скрипт скачивает этот файл и обучает на них модель. Как бонус обучение тоже стало в 20-30 раз быстрее.
Representation-go показал отличные результаты:
-
Ответ главной страницы упал в 3 раза с 1280 до 450 миллисекунд;
-
Потребление CPU упало в 5 раз;
-
Потребление RAM снизилось в 21 раз.

Разблокировали дальнейшую разработку рекомендаций — можем дальше внедрять тяжелые фичи.
Когда стоит переписывать сервис с Python на Go
В нашем случае переход на Go дал нужный результат. На опыте сервиса рекомендаций мы вывели три условия при одновременном выполнении которых стоит переходить на Go:
-
в сервисе много CPU-bound-нагрузки;
-
при этом также много IO-bound нагрузки;
-
нужно передавать по сети большой объем данных, например для подготовки фичей.
Если у вас есть только IO-bound нагрузка, то лучше остаться на Python. При переходе на Go вы почти не выиграете по времени, только сэкономите ресурсы, что при малых и средних нагрузках не так важно.
Если в сервисе используются обе нагрузки, но по сети передаётся не так много данных как у нас, есть два варианта:
-
Использовать ProcessPoolExecutor. Накладные расходы времени будут не очень большими, пока сервис не гигант.
-
Как нагрузка станет большой — разбить на 2 сервиса, для раздельного масштабирования.
Оптимизации сервиса, c чего нужно начать
Профилируйте ваш сервис. Используйте py-spy, как мы, или другой профайлер Python. Скорее всего, в вашем коде нет огромных неоптимальных участков. Но нужно внимательнее посмотреть все небольшие участки, из которых собирается приличный объём для улучшения. Возможно, переписывать весь код вам не понадобится.
Запуск py-spy в не блокирующем режиме:
record -F -o record.svg -s --nonblocking -p 1
Это первый flame, который мы получили без всяких оптимизаций. Что первое тут бросилось в глаза — заметный кусок времени тратится на json валидацию запроса, которая в нашем случае не очень нужна, поэтому мы её убрали. Еще больше времени тратилось json loads/dumps всех сетевых запросов, заменили на orjson.
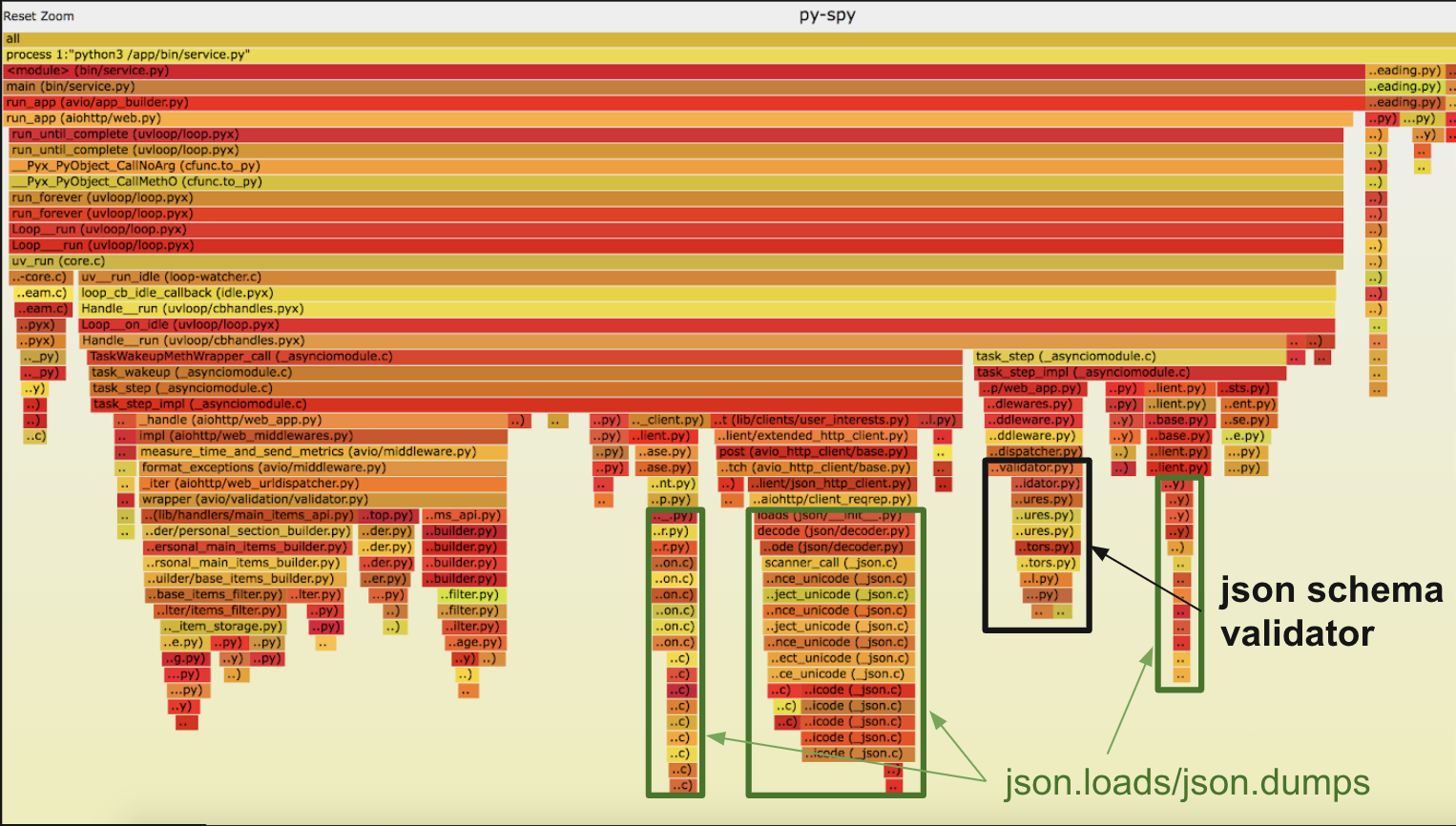
Ну и в завершении дам несколько советов:
-
Используйте request validator с умом.
-
Для парсинга используйте orjson для Python или jsoniter для Golang.
-
Уменьшайте нагрузку на сеть — жмите данные(zstd). Оптимизируйте хранение, чтение/запись данных в БД (Protobuf/MessagePack). Иногда быстрее сжать, отправить и разжать, чем отправлять несжатые данные.
-
Смотрите на участки кода, которые выполняются дольше всего.