Пересказ статьи aveek22. Transaction Isolation Levels
Введение
Работая с базами данных SQL, мы часто пишем запросы, не задумываясь о том, как запрос собирается читать данные из соответствующих таблиц. Как мы знаем, базы данных проектируются в соответствии с базовыми свойствами ACID (атомарность, согласованность, изоляция, длительность), и каждое свойство изоляции гарантирует корректную целостность в рамках транзакции, выполняемой в сеансе. Проще говоря, это означает, что когда транзакция выполняется, ядро считает, что она является единственной транзакцией в сеансе. Это свойство базы данных помогает поддерживать согласованность системы, а также является важным фактором чтения данных из источника при одновременном выполнении множества транзакций в том же и других сеансах.
Зачем нужна изоляция транзакций?
Установка правильного уровня изоляции для вашего приложения является весьма важным шагом при проектировании базы данных. Это не только помогает устранить блокировки таблиц при чтении, но также помогает ядру строить корректный план выполнения запроса, улучшая, тем самым, общую производительность.
Предположим, что вы работаете с базой данных OLTP, которая содержит таблицу с 50 миллионами записей. Существует множество сервисов, которые подключаются к базе данных для чтения и модификации данных. Еще есть панель управления, которая считывает данные из той же таблицы и представляет их рабочей группе для обработки. Важно отметить, что любое обновление или выборка в такой таблице повлечет за собой определенные затраты, поскольку данные огромны. Давайте рассмотрим сценарий, когда сервис находится в процессе обновления записей и в то же самое время срабатывает запрос панели управления. В этом случае, если уровень изоляции задан неверно, мы можем прочитать некоторые данные, которые, возможно, вообще не существуют. Это приведет к неверной интерпретации данных командой аналитиков и послужит принятию неверных решений.
Имеющиеся типы изоляции транзакций
SQL Server имеет 4 уровня изоляции.
1. READ UNCOMMITTED: означает, что транзакция в пределах текущей сессии может читать данные, которые модифицируются или удаляются другой транзакцией, но еще не зафиксированы. Этот уровень изоляции накладывает наименьшие ограничения, поскольку ядро базы данных не накладывает никаких разделяемых блокировок. В результате весьма вероятно, что транзакция прочитает данные, которые были вставлены, обновлены или удалены, но не будут зафиксированы в базе данных. Такой сценарий называется грязным чтением.
2. READ COMMITTED: Это установка по умолчанию для большинства запросов SQL Server. Она определяет, что транзакция в текущем сеансе не может читать данные, которые были модифицированы другой транзакцией. Тем самым при этой установке предотвращается грязное чтение.
3. REPEATABLE READ: С этой установкой транзакция не только может читать данные, которые зафиксированы другой модифицирующей транзакцией, но также накладывает ограничение, чтобы никакая другая транзакция не могла модифицировать данные, которые читаются, пока первая транзакция не завершит работу. Это устраняет проблему неповторяющихся чтений.
4. SERIALIZABLE: Этим уровнем изоляции устанавливается множество свойств. Этот уровень изоляции является наиболее ограничительным по сравнению с другими, в результате чего могут возникнуть некоторые проблемы с производительностью при установке этого уровня. Вот упомянутые свойства:
- Текущая транзакция может читать только зафиксированные данные, модифицированные другой транзакцией данные.
- Другие транзакции ставятся в очередь ожидания пока первая транзакция не завершит выполнение.
- Никаким транзакциям не разрешается вставлять данные, которые отвечают условию текущей транзакции.
Изменение уровня изоляции в SSMS
Существует два способа установки изоляции транзакций в SSMS:
1. Использование GUI
2. Использование команд T-SQL
Использование GUI
1. Щелкнуть правой кнопкой мышки в окне запроса и выбрать «Query Options» (Параметры запроса).
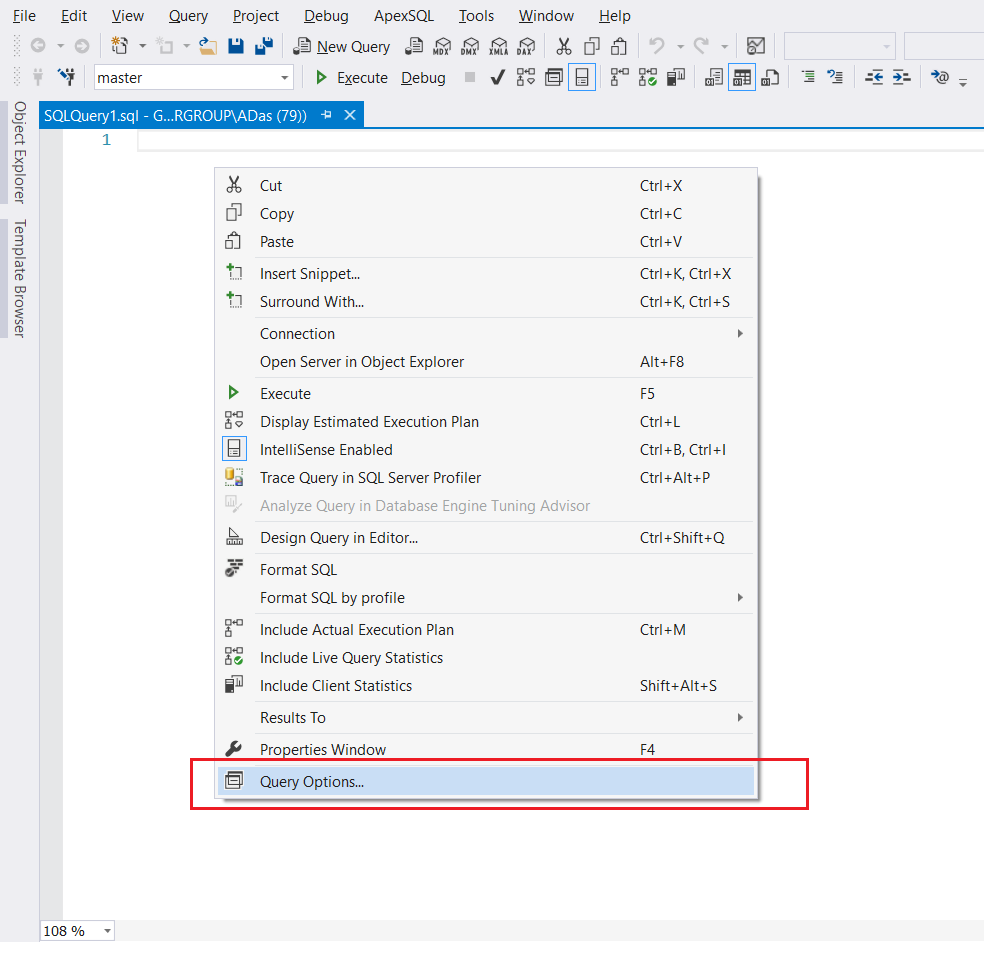 2. Выбрать «Advances» (дополнительно) в группе «Execution» (выполнение) на левой панели.
2. Выбрать «Advances» (дополнительно) в группе «Execution» (выполнение) на левой панели.
3. Щелкнуть по выпадающему списку рядом с «SET TRANSACTION ISOLATION LEVEL».
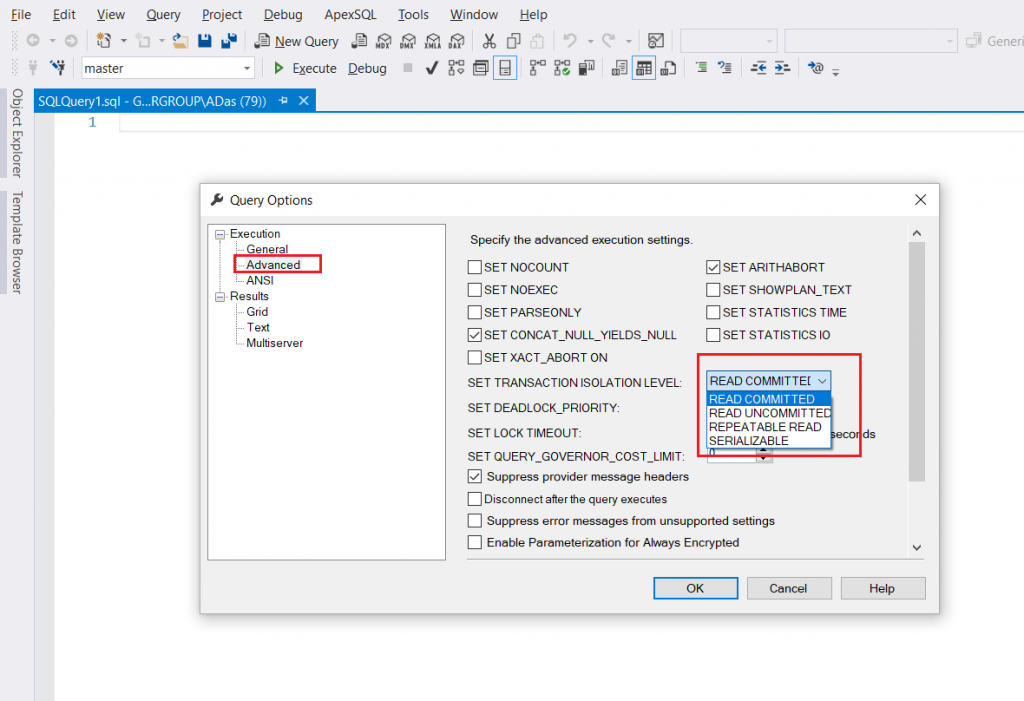 4. Выбрать подходящий уровень изоляции из списка.
4. Выбрать подходящий уровень изоляции из списка.
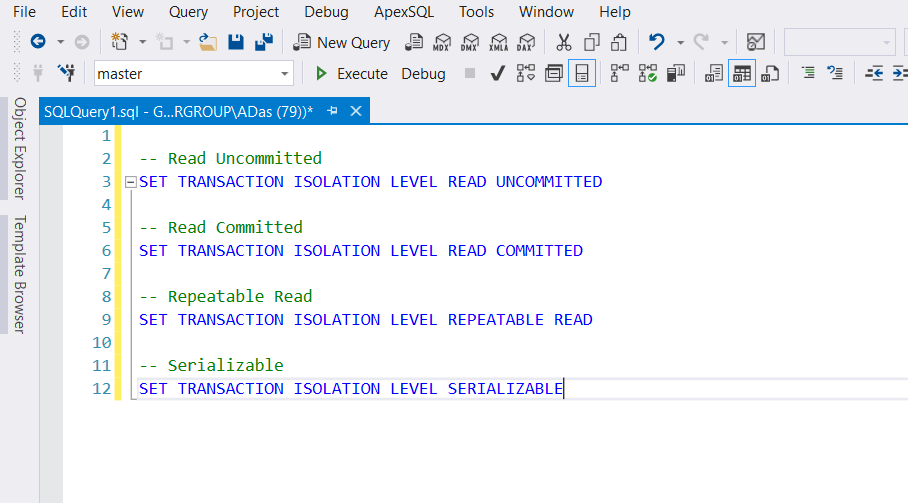
Использование команд T-SQL
Для установки каждого уровня изоляции есть отдельная команда. Все эти команды я показываю на скриншоте ниже. Эта установка применяется к текущей сессии и сохраняется до тех пор, пока не будет явно изменена.
Заключение
Вне зависимости от преимуществ и недостатков уровней изоляции транзакций мы должны разумно использовать этот параметр. Убедитесь, что вы правильно понимаете специфику ваших данных, прежде чем применять непосредственно какой-либо уровень изоляции. Хотя уровень изоляции по умолчанию установлен в значение READ COMMITTED, часто необходимо изменить его на основе бизнес требований, а иногда чтобы повысить производительность базы данных.
Уровни изолированности транзакций для самых маленьких
Время прочтения
5 мин
Просмотры 158K

Сегодня хотел бы довести крайне интересный, но часто покрытый тайнами для обычных смертных программистов раздел базы данных (БД) — уровни изолированности транзакций. Как показывает практика, многие люди, связанные с IT, в частности с работой с БД, слабо понимают зачем нужны эти уровни и как их можно использовать себе во благо.
Немного теории
Сами транзакции особых объяснений не требуют, транзакция — это N (N≥1) запросов к БД, которые выполнятся успешно все вместе или не выполнятся вовсе. Изолированность же транзакции показывает то, насколько сильно влияют друг на друга параллельно выполняющиеся транзакции.
Выбирая уровень транзакции, мы пытаемся прийти к консенсусу в выборе между высокой согласованностью данных между транзакциями и скоростью выполнения этих самых транзакций.
Стоит отметить, что самую высокую скорость выполнения и самую низкую согласованность имеет уровень read uncommitted. Самую низкую скорость выполнения и самую высокую согласованность — serializable.
Подготовка окружения
Для примеров была выбрана СУБД MySQL. PostgreSQL мог бы тоже использоваться, но он не поддерживает уровень изоляции read uncommitted, и использует вместо него уровень read committed. Да и как оказалось, разные СУБД по-разному воспринимают уровни изолированности. Могут иметь разнообразные нюансы в обеспечении изоляции, иметь дополнительные уровни или не иметь общеизвестных.
Создадим окружение с помощью готового образа MySQL с Docker Hub. И заполним базу данными.
docker-compose.yaml
version: '3.4'
services:
db:
image: mysql:8
environment:
- MYSQL_ROOT_PASSWORD=12345
command: --init-file /init.sql
volumes:
- data:/var/lib/mysql
- ./init.sql:/init.sql
expose:
- "3306"
ports:
- "3309:3306"
volumes:
data:
Заполнение базы данных
create database if not exists bank;
use bank;
create table if not exists accounts
(
id int unsigned auto_increment
primary key,
login varchar(255) not null,
balance bigint default 0 not null,
created_at timestamp default now()
) collate=utf8mb4_unicode_ci;
insert into accounts (login, balance) values ('petya', 1000);
insert into accounts (login, balance) values ('vasya', 2000);
insert into accounts (login, balance) values ('mark', 500);
Рассмотрим как работают уровни и их особенности.
Примеры будем выполнять на 2 параллельно исполняющихся транзакциях. Условно транзакцию в левом окне будем называть транзакция 1 (Т1), в правом окне — транзакция 2 (Т2).
Read uncommitted
Уровень, имеющий самую плохую согласованность данных, но самую высокую скорость выполнения транзакций. Название уровня говорит само за себя — каждая транзакция видит незафиксированные изменения другой транзакции (феномен грязного чтения). Посмотрим какое влияние оказывают друг на друга такие транзакции.
Шаг 1. Начинаем 2 параллельные транзакции.

Шаг 2. Смотрим какая информация имеется у нас в начале.

Шаг 3. Теперь выполняем операции INSERT, DELETE, UPDATE в Т1, и посмотрим, что теперь видит другая транзакция.

Т2 видит данные другой транзакции, которые еще не были зафиксированы.
Шаг 4. И Т2 может получить какие-то данные.

Шаг 5. При откате изменений Т1, данные полученные Т2 окажутся ошибочными.

На данном уровне нельзя использовать данные, на основе которых делаются важные для приложения выводы и критические решения т.к выводы эти могут быть далеки от реальности.
Данный уровень можно использовать, например, для примерных расчетов чего-либо. Результат COUNT(*) или MAX(*) можно использовать в каких-нибудь нестрогих отчетах.
Другой пример это режим отладки. Когда во время транзакции, вы хотите видеть, что происходит с базой.
Read committed
Для этого уровня параллельно исполняющиеся транзакции видят только зафиксированные изменения из других транзакций. Таким образом, данный уровень обеспечивает защиту от грязного чтения.
Шаг 1 и Шаг 2 аналогичны предыдущему примеру.
Шаг 3. Также выполним 3 простейшие операции с таблицей accounts (Т1) и сделаем полную выборку из этих таблиц в обеих транзакциях.
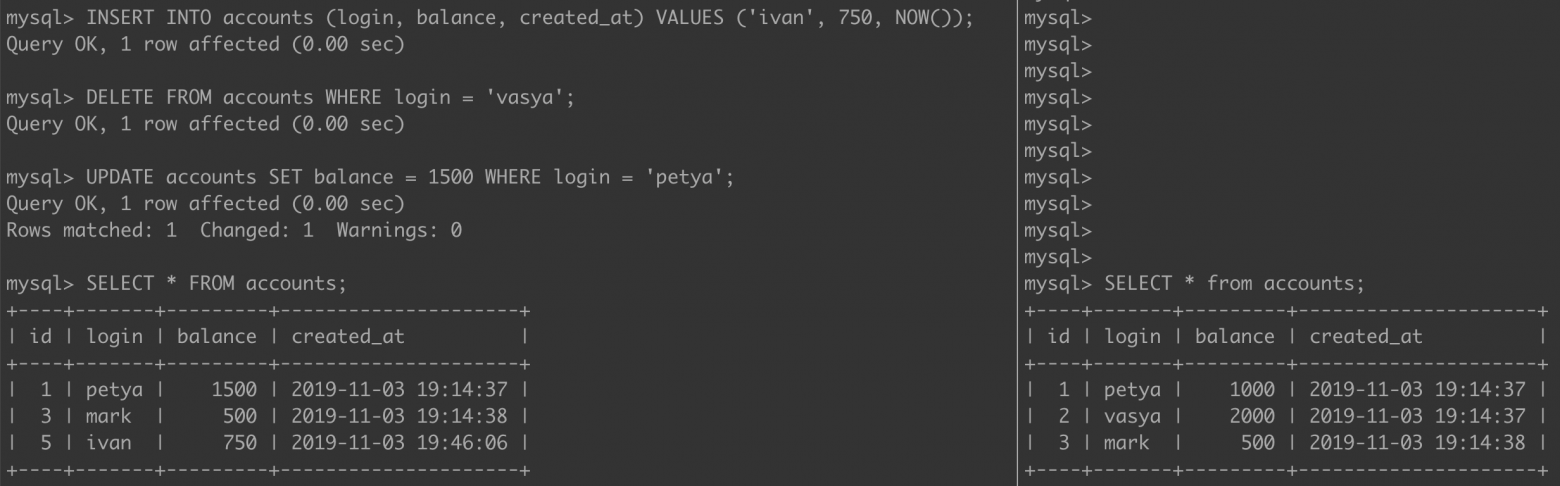
И увидим, что феномен грязного чтения в Т2 отсутствует.
Шаг 4. Зафиксируем изменения Т1 и проверим, что теперь видит Т2.

Теперь Т2 видит все, что сделала Т1. Это так называемые феномен неповторяющегося чтения, когда мы видим обновленные и удаленные строки (UPDATE, DELETE), и феномен чтения фантомов, когда мы видим добавленные записи (INSERT).
Repeatable read
Уровень, позволяющий предотвратить феномен неповторяющегося чтения. Т.е. мы не видим в исполняющейся транзакции измененные и удаленные записи другой транзакцией. Но все еще видим вставленные записи из другой транзакции. Чтение фантомов никуда не уходит.
Снова повторяем Шаг 1 и Шаг 2.
Шаг 3. В Т1 выполняем запросы INSERT, UPDATE и DELETE. После, в Т2 пытаемся обновить ту же самую строку, которую обновили в Т1.

И получаем lock: T2 будет ждать, пока T1 не зафиксирует изменения или не откатится.
Шаг 4. Зафиксируем изменения, которые сделала Т1. И прочитаем снова данные из таблицы accounts в Т2.

Как видно, феноменов неповторяющегося чтения и чтения фантомов не наблюдается. Как же так, ведь по умолчанию, repeatable read позволяет нам предотвратить только феномен неповторяющегося чтения?
На самом деле в MySQL отсутствует эффект чтения фантомов для уровня repeatable read. И в PostgreSQL от него тоже избавились для этого уровня. Хотя в классическом представлении этого уровня, мы должны наблюдать этот эффект.
Небольшой абстрактный пример — сервис генерации подарочных сертификатов (кодов) и их использования. Например, злоумышленник сгенерировал себе код сертификата и пытается его активировать, пытаясь послать несколько запросов подряд на активацию купона. В таком случае у нас запустится несколько параллельно исполняемых транзакций, работающих с одним и тем же купоном. И в некоторых ситуациях может возникнуть двойная или даже тройная активация купона (пользователь получит 2x/3x бонусов). При repeatable read в данном случае возникнет lock и активация пройдет единожды, а в предыдущих 2 уровнях возможна многократная активация. Подобную проблему можно также решить с помощью запроса SELECT FOR UPDATE, который также заблокирует обновляемую запись (купон).
Serializable
Уровень, при котором транзакции ведут себя как будто ничего более не существует, никакого влияния друг на друга нет. В классическом представлении этот уровень избавляет от эффекта чтения фантомов.
Шаг 1. Начинаем транзакции.
Шаг 2. Т2 читаем таблицу accounts, затем Т1 пытаемся обновить данные прочитанные Т2.

Получаем lock: мы не можем изменить данные в одной транзакции, прочитанные в другой.
Шаг 3. И INSERT и DELETE ведет нас к lock’у в Т1.

Пока Т2 не завершит свою работу, мы не сможем работать с данными, которые она прочитала. Мы получаем максимальную согласованность данных, никакие лишние данные не зафиксируются. Цена за это медленная скорость транзакций из-за частых lock’ов поэтому при плохой архитектуре приложения это может сыграть с Вами злую шутку.
Выводы
В большинстве приложений уровень изолированности редко меняется и используется значение по умолчанию (например, в MySQL это repeatable read, в PostgreSQL — read committed).
Но периодически возникают, задачи, в которых поиск лучшего баланса между высокой согласованностью данных или скоростью выполнения транзакций может помочь решить некоторую прикладную задачу.
Не помню определения транзакции и не собираюсь сейчас давать его, поэтому просто своими словами скажу – это возможность базы данных, которая поддерживается SQL. Когда мы выполняем одну команду, то она будет выполнена или не выполнена. Если команда не может быть выполнена, то все изменения отменяются.
А что, если нам нужно выполнить несколько команд, которые должны выполниться все или не выполниться вовсе? Вот тут как раз и подтягиваются транзакции. С помощью специальных команд мы начинаем и заканчиваем транзакцию, а все команды между началом и концом будут выполнены полностью или не будут выполнены вовсе.
В зависимости от базы данных команды и процесс может немного отличаться. В oracle, кажется, любая команда изменения данных начинала транзакцию. Я с этой базой данных не работал уже лет 14 и недавно дочке помогал с домашней работой и увидел, что у них до сих пор изменения начинают транзакцию. Но Oracle отличался неплохими настройками и скорей всего это настраивается.
Классическая задача – перевод денег с одного счета на другой. Допустим, что у вы хотите перевести деньги с одного счета на другой. Для этого нужно снять деньги с одного счета и прибавить на другой, а это две операции. Допустим, что после снятия денег со счета произошла ошибка, сеть отключилась или завис компьютер – все потеряно. Деньги сняли, а никуда не добавили, так что мы потеряли деньги.
Может сначала добавлять деньги на новый аккаунт, а потом снимать? Ну тогда в случае ошибки мы подарим счастливчику деньги и не спишем, а это уже невыгодно.
Нужно гарантировать, что обе операции будут выполнены полностью или не выполнены вовсе, если в процессе произошла ошибка.
Итак, транзакция – это какая-то фигня, которая гарантирует, что все команды выполнены или не выполнены. И мы должны как-то сказать, где начинается эта фигня, а где заканчивается. Как я уже сказал в Oracle любое обновление данных кажется создает эту фигню, которую все называют транзакцией, но можно и вручную указать начало с помощью команды START TRANSACTION. В MySQL для этого используется BEGIN WORK или START TRANSACTION, а в MS SQL это BEGIN TRANSACTION. Не знаю, зачем каждая база данных использует свой вариант команды, но вот такая печалька. Я все примеры показываю на MySQL, поэтому везде, где я буду использовать START TRANSACTION, вы должны заменять эту команду на BEGIN TRANSACTION, если работаете с MS SQL Server.
В MySQL транзакцию можно начать с помощью BEGIN WORK или START TRANSACTION, но в чем разница? Согласно документации MySQL разницы нет, а BEGIN WORK – это псевдоним к START TRANSACTION.
Итак, наша логика перевода денег должна выглядеть так:
START TRANSACTION; СНЯТЬ ДЕНЬГИ С АККАУНТА 1; ДОБАВИТЬ ДЕНЬГИ НА АККАУНТ 2; COMMIT или ROLLBACK
Если мы выполним COMMIT, то оба изменения попадут в базу данных. Если выполнить ROLLBACK, то все изменения будут потеряны.
Это и все, всего три команды:
— начать транзакцию START TRANSACTION для MySQL или BEGIN TRANSACTION для MS SQL Server
— зафиксировать изменения COMMIT
— отменить изменения ROLLBACK
Фиксируются или отменяются все изменения, которые могут находиться между началом и фиксацией/отменой. Теория простая, а теперь нужно на практики зафиксировать транзакцию, которую я начал в этой главе, чтобы информация не откатилась.
Открываем любимый редактор для работы с SQL, я сегодня буду использовать Workbench, который все чаще использую во время записи видео. Подключайтесь к базе данных и начинаем выполнять команды:
START TRANSACTION;
Теперь давайте вставим новую запись в таблицу команд:
INSERT team (name) VALUES ('sdfsdf');
Проверим, вставилась ли запись или нет, просто выбирая все записи из таблицы:
SELECT * FROM team;
Вы должны увидеть новую запись с именем команды ‘sdfsdf’.
Теперь подключимся к базе данных еще раз, выбираем Database — Connect to Database второй раз.
В первой (слева) закладке я начал транзакцию и вставил запись, а во второй закладке давайте тоже попробуем выполнить SELECT запрос и посмотрим на содержимое таблицы team. Вы не должны увидеть команды с названием sdfsdf.
Если выбирать данные из таблицы team в той закладке, в которой мы создали транзакцию, то мы будем видеть изменения, потому что транзакция создается для определенного подключения. Если сейчас убить программу через процессы, если выключить питание компьютера, то транзакция не будет завершенной и все изменения будут отменены. Потеряв доступ к подключению, вы никогда уже не сможете завершить транзакцию с помощью команды COMMIT и сервер должен отменить изменения.
Пока commit не выполнен, данные в базе данных не зафиксированы. Значит ли это, что никто другой не сможет их видеть, как в нашем случае? Не факт, потому что тут есть еще одно понятие – уровень изоляции, но об этом стоит поговорить отдельно, совсем чуть-чуть позже. В зависимости от базы данных поведение по умолчанию может отличаться, запрос на второй закладке может как бы зависнуть и висеть, пока вы его не отмените или пока не завершите транзакцию на первой закладке.
Выполните ROLLBACK и теперь попробуйте снова посмотреть на содержимое таблиц. На какой закладке вы не выполняли бы запрос, вы больше изменения не увидите, они полностью отменены.
Попробуем еще раз выполнить те же команды, но на этот раз не будем откатывать изменения, а зафиксируем их с помощью COMMIT:
START TRANSACTION;
INSERT team (name) VALUES ('sdfsdf');
COMMIT
Отлично, теперь все подключения к базе данных будут видеть одно и то же, потому что теперь вставка новой строки зафиксирована и реально сохранена в базе.
Уровни изоляции транзакций
Уровень изоляции можно устанавливать для базы данных и для текущей сессии. Для базы данных меняется в настройках и тут скорей всего понадобиться перезапускать сервер базы данных. Опять же, я все базы данных знать не могу, поэтому говорить не буду. Мы будем менять уровень изоляции только для текущей сессии (соединение к базе данных) и рассмотрим только mysql. Тут нужно выполнить команду:
SET SESSION TRANSACTION ISOLATION LEVEL УРОВЕНЬ ИЗОЛЯЦИИ;
Если вы работаете с MS SQL Server, то команда выглядит точно также, только слово SESSION нужно опустить, то есть в нем выполняем команду:
SET TRANSACTION ISOLATION LEVEL УРОВЕНЬ ИЗОЛЯЦИИ;
Посмотреть текущий уровень можно с помощью команды:
SHOW VARIABLES LIKE 'tx_isolation';
Это команда не совсем SQL
Уровень изоляции READ COMMITTED
Давайте теперь поговорим про уровни изоляции. READ COMMITTED, это когда все изменения доступны внутри транзакции, которую мы создали, но эти изменения не будут видны другим. Именно это мы уже видели. Это очень хороший уровень, но у него есть недостаток – мы создали транзакцию, изменили данные, а другие считают, что данные не изменены и будут видеть старые данные и поэтому другие пользователи могут принять неверное решение.
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
Уровень изоляции REPEATABLE READ
По умолчанию в MySQL используется REPEATABLE READ – работает почти как READ COMMITTED, только еще более жестко, потому что транзакция влияет еще и на чтение данных. Например, вы начинаете транзакцию и читаете данные из базы данных:
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; START TRANSACTION; SELECT * FROM team;
Теперь в другом окне попробуйте вставить новую строку и вернитесь в первое окно с транзакцией и попробуйте прочитать данные. При изоляции READ COMMITTED вы увидите новую строку, а при REPEATABLE READ – нет. В этом режиме гарантируется, что при первом чтении вы как бы фиксируете данные и после этого повторные чтения будут возвращать тот же результат. Именно чтение фиксирует данные. Подчеркиваю, именно «как бы» фисксируете, потому что реальной фиксации нет.
Этот уровень изоляции значит, что если сделать что-то типа:
СОЕДИНЕНИЕ 1: Начинаем транзакцию СОЕДИНЕНИЕ 2: Вставляет данные 1 СОЕДИНЕНИЕ 1: Выбирает данные СОЕДИНЕНИЕ 2: Вставляет данные 2
В этом случае вставленные данные 1 будут видны в соединении/сессии 1. А вот вторая вставка видна не будет, потому что соединение 1 к этому моменту уже прочитала данные, зафиксировало состояние и последующие чтения должны возвращать тот же результат.
В остальном REPEATABLE READ – работает также, как и READ COMMITTED. Если где-то внутри транзакции вставлены или изменены данные, вы их не увидите.
Уровень изоляции READ UNCOMMITTED
Следующий уровень изоляции – READ UNCOMMITTED, он позволяет видеть изменения, которые сделала другая транзакция и эти данные еще не подтверждены.
Давайте посмотрим его на практике. В одном окне выполняем вставку в транзакции:
START TRANSACTION;
INSERT team (name) VALUES ('sdfsdf');
Данные еще не зафиксированы и по умолчанию мы их не должны видит. Но давайте в другой закладке с другим подключением выполним:
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; SELECT * FROM team;
Отлично, мы увидели данные, которые не подтверждены.
Такой уровень называют грязным чтением и не просто так, потому что это хуже, чем какой-либо из уровней. Если какая-то транзакция прочитает не зафиксированные данные, а оригинальная транзакция не будет завершена удачно и изменения отменятся, то результат будет еще хуже. Пользователи, прочитавшие не зафиксированные данные могут потом их зафиксировать, потому что будут думать, что это норм. Они могут принять неверные решения.
Уровень изоляции SERIALIZABLE
Это еще более жестокий вровень, который не разрешает другим соединениям/сессиям модифицировать данные, потому что SELECT создает range lock.
Допустим в одной сессии мы начинаем транзакцию и выбираем данные из базы:
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE; START TRANSACTION; SELECT * FROM team;
Теперь попробуйте в другой сессии вставить новую запись в таблицу.
INSERT TEAM VALUES ('test')
Запрос зависнет, вы не сможете вставить данные, потому что при этом уровне изоляции первая транзакция прочитала данные и заблокировала их. Запрос на вставку будет висеть до тех пор, пока вы не завершите первую транзакцию. Как только вы выполните COMMIT в первом окне, вставка данных во втором окне завершиться успешно.
Уровень изоляции SNAPSHOT
Этот уровень не поддерживается в MySQL. При начале транзакции данные как бы фиксируются. В отличии от REPEATABLE READ нам не нужно читать данные, чтобы зафиксировать что-то, достаточно просто начать транзакцию, и мы будем видеть данные на момент старта.
Мертвые блокировки DEADLOCK
Вернем назад уровень изоляции repeatable read:
SET session transaction isolation level repeatable read;
Теперь в одном окне создаем транзакцию и выполняем обновление таблицы Team:
START TRANSACTION;
update team
set name = 'dfgerdg'
where teamid = 1;
В результате обновляемая запись в таблице team будет заблокирована.
В другом окне с другой сессией тоже создаем транзакцию и обновляем таблицу Person:
START TRANSACTION;
update person
set firstname = 'sdfsdfds'
where personid = 1;
В результате обновляемая запись в таблице person будет заблокирована.
Каждая транзакция блокирует по одной записи. А что если теперь в первой транзакции попытаться обновить заблокированную запись в таблице Person:
update person set firstname = 'sdfsdfds' where personid = 1;
Эта операция подвиснет и не сможет завершиться, потому что запись заблокирована в другой транзакции и пока та транзакция не завершиться COMMIT или ROLLBACK, первое окно будет в состоянии ожидании.
А что если теперь второе окно попытается обновить team:
update team set name = ‘dfgerdg’ where teamid = 1;
Вот тут сразу же произойдет мертвая блокировка deadlock и обе сразу же отменятся. Дело в том, что сервер видит, что две транзакции блокируют друг друга и тут же сообщит нам об ошибке.
Чтобы снизить вероятность возникновения таких проблем нужно стараться обновлять данные во всех транзакциях в одинаковом порядке. Это не будет гарантировать сто процентной защиты, но по крайней мере снизит вероятность возникновения проблем.
Еще нужно делать так, чтобы транзакции были как можно более короткими – если мы открываем транзакцию, то нужно делать так, чтобы она завершалась как можно быстрее, все запросы в транзакции должны выполняться как можно быстрее и тут больше вопрос оптимизации.