
Об одной метрике качества кода
Есть разные метрики, используемые в программировании, в том числе и для оценки качества кода. Одна из них – это плотность ошибок. Казалось бы, с ней можно уж точно сказать, какой код качественный, а какой нет. Или нельзя?
Плотность ошибок в коде подсчитать довольно просто. Надо взять количество ошибок и поделить его на количество строк кода. Например, если в коде на 100 строк будет 6 ошибки, то плотность ошибок составляет 6/100=0.06. Конечно, это довольно плохой код, на уровне лабораторной работы начинающего студента.
При использовании статического анализа кода возникает желание пользоваться такой метрикой. Например, если статический анализатор выдал 10 сообщений на 1000 строк кода – говорит ли это что-либо о качестве проверяемого кода? К сожалению не так много как хотелось. И вот почему.
Рассмотрим простой пример, где есть два потенциальных переполнения буфера:
int _tmain(int argc, _TCHAR* argv[]) {
char buf[4];
printf("Enter your name: ");
scanf("%s", buf);
printf("Name: %sn", buf);
printf("Enter your surname: ");
scanf("%s", buf);
printf("Surname: %sn", buf);
return 0;
}Переполнения буфера возможны (и, скорее всего, будут) в строках с scanf. Плотность ошибок в коде: 2/10=0.2.
Однако если чтение вынести в единую функцию, то «ошибок» станет меньше – всего одна:
void my_scanf(char buf[]) {
scanf("%s", buf);
}
int _tmain(int argc, _TCHAR* argv[]) {
char buf[4];
printf("Enter your name: ");
my_scanf(buf);
printf("Name: %sn", buf);
printf("Enter your surname: ");
my_scanf(buf);
printf("Surname: %sn", buf);
return 0;
}Хотя программа надежнее не стала, плотность ошибок получилась меньше почти в два раза: 1/13= 0.08! При этом в программе как было два потенциальных переполнения буфера, так и остались.
Конечно, это не значит, что такая метрика как плотность ошибок бесполезна. В больших объемах кода такой эффект будет скомпенсирован. Однако надо понимать, что относиться к такой метрике следует внимательно.
Присылаем лучшие статьи раз в месяц
Надёжность программного обеспечения | areliability.com блог инженера по надёжности

Статья обновлена 23.04.2020
Надёжность программного обеспечения. Введение
Надёжность программного обеспечения — загадочное и неуловимое нечто. Если вы попытаетесь найти что-то по этой теме в яндексе, вы увидите кучу теоретических статей, где написано множество умных слов и формул, но ни одна статья не содержит ни единого примера реального расчёта надёжности программы.
На предприятиях космической отрасли ситуация ещё лучше. Когда я спросил у специалистов одного уральского НПО, как они считают надёжность программного обеспечения, они сделали круглые глаза и сказали: «А чё там, за единицу берём да и всё. А надёжность обеспечиваем отработкой». Я согласен, что такой подход имеет право на жизнь, однако хотелось бы большего. Короче, я написал свою методику, прошу любить и жаловать. Внизу привожу калькулятор, на котором можно посчитать надёжность этого вашего ПО.
Проблема надёжности программного обеспечения приобретает все большее значение в связи с постоянным усложнением разрабатываемых систем, расширением круга задач, возлагаемых на них, а, следовательно, и значительным увеличением объемов и сложности ПО. Короче, мы дожили до того дня, когда железо стало надёжнее софта, и одна ошибка в программном коде может угробить космическую миссию ценой в миллиарды долларов.
По факту, пообщавшись с коллегами по надёжности и функциональной безопасности, мы коллективно пришли к выводу, что оценивать ВБР (вероятность безотказной работы) ПО не имеет смысла. ПО это тот объект, для которого малоприменимы хорошо отработанные методики оценки надёжности, используемые при оценке компонентов, агрегатов и систем.
Всё, что мы сейчас можем, это открыть неплохой ГОСТ Р 51904-2002 Программное обеспечение встроенных систем. Общие требования к разработке и документированию и выбрать уровень разработки нашего ПО. Самое высоконадёжное (и самое дорогое) ПО будет уровня А, затем B и так далее. Все, что написано ниже — моя творческая инициатива, позволяющая оценить ВБР ПО.
Надёжность программного обеспечения обуславливается наличием в программах разного рода ошибок, внесенных в неё, как правило, при разработке. Под надёжностью ПО будем понимать способность выполнять заданные функции, сохраняя во времени значения установленных эксплуатационных показателей в заданных пределах, соответствующих заданным режимам и условиям исполнения. Под ошибкой понимают всякое невыполнение программой заданных функций. Проявление ошибки является отказом программы.
Показатели надёжности ПО
Наиболее распространенными показателями надёжности ПО являются следующие:
– начальное число ошибок N0 в ПО после сборки программы и перед её отладкой;
– число ошибок n в ПО, обнаруженных и оставшихся после каждого этапа отладки;
– наработка на отказ (MTBF), часов;
– вероятность безотказной работы (ВБР) ПО за заданное время работы P(t);
– интенсивность отказов ПО λ, 10-6 1/ч.
Упрощенная оценка надёжности ПО
Сперва рассмотрим методики, которые предлагаем нам отечественная нормативная база. Единственный нормативный документ по данной теме это ГОСТ 28195-99.
Оценка надежности ПО по ГОСТ 28195-99 рассчитывается по весьма упрощенной методике, констатирующей фактическую надёжность по опыту эксплуатации программного комплекса P(t) 1-n/N, где n – число отказов при испытаниях ПО; N – число экспериментов при испытаниях. Очевидно, что посчитать по этой методике ничего нельзя.
Статистическая оценка надёжности ПО
Куда больший интерес представляет описанная в [1] среднестатистическая оценка начального числа N0 ошибок в ПО после автономной отладки. Согласно данной оценке, количество ошибок на 1 К слов кода составляет 4,34 для языков низкого уровня (Ассемблер) и 1,44 для языков высокого уровня (С++). К сожалению, не совсем понятно, что имели в виду авторы под фразой «1 К слов кода». В англоязычной литературе принято использовать параметр тысяча строк кода (ТСК) (KLOC). Так, согласно [3] для операционной системы Windows 2000 плотность ошибок составляет 1,8-2,2 на ТСК. Учитывая, что Windows 2000 написан на языке программирования C и имеет близкую размерность числа ошибок, можно с высокой долей достоверности предположить, что отечественный авторы имели в виду именно параметр ТСК.
Отечественные авторы в [1] приводят статистические показатели интенсивности отказов ПО λ. Приведём их в таблице 1.1.
Таблица 1.1
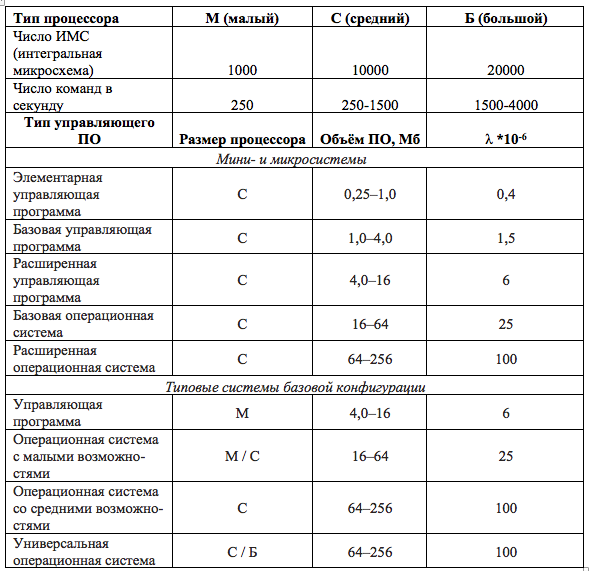
К сожалению, для какого языка ПО это действительно, авторы не сказывают. Кроме того, вводятся поправочные коэффициенты:
Таблица 1.2

И коэффициент, отражающий влияние времени работы программы:
Таблица 1.3
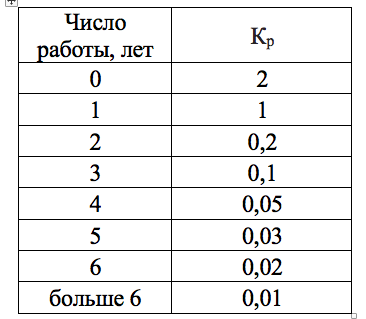
Тогда интенсивность отказов ПО λ определяется с помощью таблиц 1.1-1.3 по выражению:
λ по = λ* Кр* Кк* Кз* Ки (1.1)
Пример расчёта 1.
Объем ПО составляет 1 Мб, например.
Тогда, согласно таблице 1.1 λ = 6
Используем усредненные поправочные коэффициенты. Пусть:
Кр = 2 (короткий срок использования ПО)
Кк = 0,25 (высокое качество ПО)
Кз = 0,25 (высокая частота изменений ПО)
Ки = 1 (уровень загруженности средний)
λ по = 0,1 * 10 -6 отказов/час
Далее, используя экспоненциальную модель надёжности (при использовании данной модели поток отказов считается постоянным), можно получить ВБР ПО по стандартной формуле надёжности:
P(t) = exp**(-λ*t) (1.2)
Данная статистическая модель оценки надёжности ПО обладает значительными достоинствами по сравнению с упрощенной, однако и обладает рядом серьезных недостатков, в частности, она не учитываем язык разработки ПО и имеет большие интервалы объема ПО. То есть нельзя, например, сказать, какая будет надёжность у программы объёмом 2 гига и которая должна работать 10 лет.
Кроме того, поправочные коэффициенты имеют субъективную оценку. С какого потолка они взяты — неизвестно.
Попыткой устранения данных недостатков является Количественная модель оценки надёжности ПО.
Количественная модель оценки надёжности ПО
В основе данной модели лежит моё предположение, что уровень надежности ПО зависит от объема ПО (в битах или тысячах строк кода). Это утверждение не противоречит классической теории надежности, согласно которой чем объект сложнее, тем ниже его надёжность. Логично же. Чем больше будет строк кода, тем больше в итоге будет ошибок и тем ниже будет вероятность безотказной работы программы.
Используем оценку количества ошибок в зависимости от языка разработки из статистической модели:
Таблица 1.4
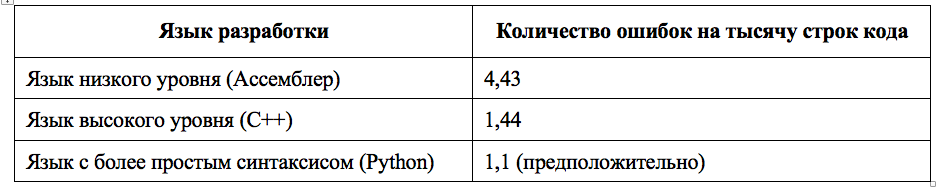
Далее, из [3] взята статистическая оценка связи количества строк кода и битов.
Для языка C, согласно [3] одна строка кода содержит 17 ± 3 байтов (146 битов) информации.
Зная V, объём кода ПО, в битах, мы можем получить число строк этого кода. Удобнее использовать параметр ТСК.
ТСК = V/146000 (1.3)
Используя данные таблицы 1.4 можно получить β, коэффициент количества ошибок на тысячу строк кода:
β = 1,44*ТСК/1000 (1.4)
Пример 2.
Объем ПО составляет 10 Мб. Язык разработки С++.
Тогда, согласно 1.3-1.4, β составит 0,08
Данный показатель очень близок к результату Примера 1.
Так появилась идея сопоставить параметр λ — интенсивности отказов ПО, получаемые статистической моделью и β, коэффициент количества ошибок ПО.
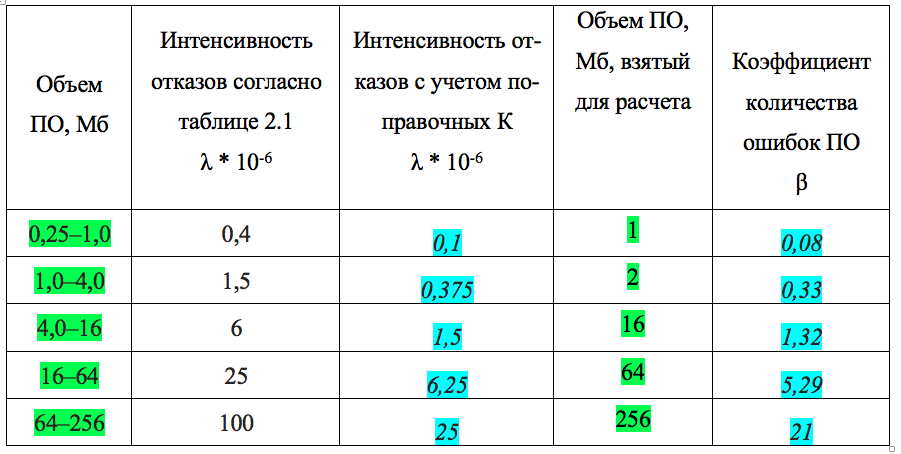
Сейчас внимание! Как видим, есть сильная корреляция результатов между интенсивностью отказов ПО с учётом поправочных коэффициентов и β — коэффициентом количества ошибок ПО. Использование других поправочных коэффициентов приводит к схожим результатам.
Можно сделать предположение, что введенный нами (придуманный мной) β по физическому смыслу близок к λ, интенсивности отказов. λ характеризует частоту отказов. β характеризует частоту ошибок в программе, а значит и отказов. Но! λ и β различаются. λ, единожды определённый для транзистора не изменяется от количества транзисторов. β — коэффициент динамический. Чем больше объём программы, тем больше β. Но это и логично. Чем больше программа, тем в ней больше ошибок. Кроме того, можно предположить, что авторы таблицы 1.1 написали её для ПО на языке С.
Очевидно, чем дольше работает программа, тем выше вероятность, что она откажет.
Используя экспоненциальную модель надёжности (при использовании данной модели поток отказов считается постоянным), можно получить ВБР ПО:
P(t) = exp**(-λ*t)
Резюмируя, для того чтобы оценить надёжность программного обеспечения, необходимо знать его язык разработки (высокий или низкий) и объём кода ПО.
[1] Надёжность авиационных приборов и измерительно-вычислительных комплексов, В.Ю. Чернов/ В.Г. Никитин; Иванов Ю.П. – М. 2004.
[2] Надёжность и эффективность в технике: Справочник., В.С. Авдуевский. 1988.
[3] Estimating source lines of code from object code, L. Hatton. 2005.
Попробуйте теперь что-нибудь посчитать. Например, найдите надёжность программного обеспечения, объём которого 100 Мб, и которое должно проработать 100 часов. Важно! Обратите внимание, что λ при изменении объёма ПО каждый раз пересчитывается под конкретный размер ПО.
KLOC, объём ПО в тысячах строк
β, к-т количества ошибок на тысячу строк кода для языка высокого уровня
β, к-т количества ошибок на тысячу строк кода для языка низкого уровня
λ, интенсивность отказов, язык высокого уровня
λ, интенсивность отказов, язык низкого уровня
t, время работы программы, часов
Вероятность безотказной работы, язык высокого уровня
Вероятность безотказной работы, язык низкого уровня
Валидация модели. Согласно этому сайту надёжность (вероятность безотказной работы) Windows 7 Home Premium составляет 0.98. Правда неизвестно, для какого времени работы сделан расчёт.
Давайте посчитаем по калькулятору. Windows 7 Home Premium после установки занимает около 15 гигабайт или 15360 мегабайт. Примем время работы — большой рабочий день = 12 часов. Тогда ВБР по калькулятору составит 0.984. Неплохо?
Продолжение. К вероятностной оценке надёжности программного обеспечения
Если вы хотите заказать у меня расчет надежности — нажмите на эту ссылку или на кнопку ниже.

Внимание! Если вас интересует корпоративное групповое обучение специалистов вашей компании, пожалуйста перейдите по ссылке ниже. Возможна адаптация учебной программы под ваши требования/пожелания/возможности как по объёму учёбы срокам обучения, формату обучения, так и по балансу теория/практика.


До встречи на обучении! С уважением, Алексей Глазачев. Инженер и преподаватель по надежности.
Over the years I’ve heard various estimates for the average number of exploitable bugs per thousand lines of code, a common figure being one exploitable bug per thousand lines of code. A Google search gives some much lower figures like 0.020 and 0.048 on one hand but also very high figures like 5 to 50. All these numbers are for code that hasn;t been reviewed nor tested for security.
Have any serious empirical studies been done on this subject? Such a study could be done based on well reviewed open source software by checking how many security holes have been reported over the years. If not, where do these numbers come from?
![]()
asked Oct 4, 2012 at 22:28
![]()
5
Any number you get is going to be fairly meaningless — some factors to consider:
-
Programming Language — Some languages let you do very unsafe things; e.g., C makes you directly allocate memory, do pointer arithmetic, has null terminated strings, so introduces many potential security flaws that safer (but slightly slower) languages like ruby/python do not allow. Purpose of application? What type of coder/code review?
-
Type of Application — if a non-malicious programmer writes a relatively complex angry bird type game in Java (not using
unsafemodule), there a very good chance there aren’t any «exploitable» bugs — especially after testing; with the possible exception of being able to crash the program. A web application in PHP written by amateurs, has a good chance of having various exploitable flaws (SQL injection, cross-site scripting, bad session management, weak hashing, remote file inclusion, etc.). -
Programmer expertise at writing secure code. If you hire a high school student with no past experience to code up some web application, there’s a reasonable chance they’ll be major flaws.
Furthermore, counting the number of «exploitable» bugs is not a straightforward task either; if finding bugs was straightforward they’d be removed in code review. Sometimes many bugs only arise due to subtle race conditions or complex interactions among programs/libraries.
However, if you take open-source projects, its fairly easy to find a count of LoC at ohloh.net and a count of «exploitable» vulnerabilities at cvedetails.com (I arbitrarily defined ‘exploitable’ as CVSS over 7). I randomly decided to look at some web browsers, programming languages, and web frameworks and found:
Web Browsers:
- Google Chrome 380 CVE with 6 239 930 LoC so 0.06 vulnerabilities per thousand LoC.
- Firefox 395 CVE in 8 000 969 LoC at rate 0.05 per 1000 lines of code.
open source programming languages:
- python with 3 exploitable CVSS>=7)
in 862 830 lines of code at a rate of 0.003 - Ruby 13 CVSS >= 7 in 171 122 LoC at a rate of 0.08
- PHP with 122 exploitable CVSS>=7 in 3 761 587 lines of code at a rate of 0.03 (factor of ten worse than python).
Web Frameworks:
- django with 1 exploitable CVSS >= 7 in 149 292 LoC at a rate of 0.007.
- Ruby on Rails 7 exploitable CVSS >= 7 in 156 317 LoC at a rate of 0.05.
So again for these specific major programming projects (likely written by expert programmers) found rates of major exploitable vulnerabilities at a rate of 0.003 to 0.08 per 1000 LoC. (Or 1 per 12 500 — 300 000 LoC). I would necessarily extrapolate to non major open source projects.
answered Oct 5, 2012 at 18:45
![]()
dr jimbobdr jimbob
38.9k8 gold badges92 silver badges162 bronze badges
2
As someone who security tests web apps for fun and profit the security defects per thousand lines is way higher in common open source web apps than the 0.08 figure quoted. Presumably the issue is CVEs record only security defects found and reported via the relevant channels, you need metrics where the code has undergone systematic reviews so that at least low hanging security defects have been detected, otherwise what you are measuring is some fraction of the testing effort.
answered Oct 2, 2016 at 16:12
![]()
Over the years I’ve heard various estimates for the average number of exploitable bugs per thousand lines of code, a common figure being one exploitable bug per thousand lines of code. A Google search gives some much lower figures like 0.020 and 0.048 on one hand but also very high figures like 5 to 50. All these numbers are for code that hasn;t been reviewed nor tested for security.
Have any serious empirical studies been done on this subject? Such a study could be done based on well reviewed open source software by checking how many security holes have been reported over the years. If not, where do these numbers come from?
![]()
asked Oct 4, 2012 at 22:28
![]()
5
Any number you get is going to be fairly meaningless — some factors to consider:
-
Programming Language — Some languages let you do very unsafe things; e.g., C makes you directly allocate memory, do pointer arithmetic, has null terminated strings, so introduces many potential security flaws that safer (but slightly slower) languages like ruby/python do not allow. Purpose of application? What type of coder/code review?
-
Type of Application — if a non-malicious programmer writes a relatively complex angry bird type game in Java (not using
unsafemodule), there a very good chance there aren’t any «exploitable» bugs — especially after testing; with the possible exception of being able to crash the program. A web application in PHP written by amateurs, has a good chance of having various exploitable flaws (SQL injection, cross-site scripting, bad session management, weak hashing, remote file inclusion, etc.). -
Programmer expertise at writing secure code. If you hire a high school student with no past experience to code up some web application, there’s a reasonable chance they’ll be major flaws.
Furthermore, counting the number of «exploitable» bugs is not a straightforward task either; if finding bugs was straightforward they’d be removed in code review. Sometimes many bugs only arise due to subtle race conditions or complex interactions among programs/libraries.
However, if you take open-source projects, its fairly easy to find a count of LoC at ohloh.net and a count of «exploitable» vulnerabilities at cvedetails.com (I arbitrarily defined ‘exploitable’ as CVSS over 7). I randomly decided to look at some web browsers, programming languages, and web frameworks and found:
Web Browsers:
- Google Chrome 380 CVE with 6 239 930 LoC so 0.06 vulnerabilities per thousand LoC.
- Firefox 395 CVE in 8 000 969 LoC at rate 0.05 per 1000 lines of code.
open source programming languages:
- python with 3 exploitable CVSS>=7)
in 862 830 lines of code at a rate of 0.003 - Ruby 13 CVSS >= 7 in 171 122 LoC at a rate of 0.08
- PHP with 122 exploitable CVSS>=7 in 3 761 587 lines of code at a rate of 0.03 (factor of ten worse than python).
Web Frameworks:
- django with 1 exploitable CVSS >= 7 in 149 292 LoC at a rate of 0.007.
- Ruby on Rails 7 exploitable CVSS >= 7 in 156 317 LoC at a rate of 0.05.
So again for these specific major programming projects (likely written by expert programmers) found rates of major exploitable vulnerabilities at a rate of 0.003 to 0.08 per 1000 LoC. (Or 1 per 12 500 — 300 000 LoC). I would necessarily extrapolate to non major open source projects.
answered Oct 5, 2012 at 18:45
![]()
dr jimbobdr jimbob
38.9k8 gold badges92 silver badges162 bronze badges
2
As someone who security tests web apps for fun and profit the security defects per thousand lines is way higher in common open source web apps than the 0.08 figure quoted. Presumably the issue is CVEs record only security defects found and reported via the relevant channels, you need metrics where the code has undergone systematic reviews so that at least low hanging security defects have been detected, otherwise what you are measuring is some fraction of the testing effort.
answered Oct 2, 2016 at 16:12
![]()
- Инструменты для автоматизации code review PHP
- Методика поиска инструментов
- Инструменты для анализа PHP-кода
- Инструменты для контроля совместимости кода с разными версиями PHP
- Инструменты для поиска уязвимостей в PHP-коде
- Что на выходе
- PHP CS Fixer
- PHP Code Sniffer
- PHP Mess Detector
- PHP Dead Code Detector
- PHP Copy Paste Detector
- PHP Static Analysis Tool
- Phan
- PHP Compatibility
- PHP 7 Compatibility Checker
- Qafoo Quality Analyzer
- PHP Metrics
- Итоговая таблица сравнения инструментов
- Апробация инструментов на 1С-Битрикс
- Вывод
Вызывает интерес ваш технический прогресс.
Как у вас там сеют брюкву, с кожурою, али без?
Программист — творческая профессия. Мы создаем что-то новое, руководствуясь своими знаниями, внутренним пониманием качества и поставленными дедлайнами. Дедлайны и знания пока оставим в стороне и сосредоточимся на качестве.
Даже у двух братьев-программистов, закончивших один вуз и работающих в одной компании, это понимание качества будет разным. А работать приходится в команде, и у коллег не должно возникать желания выкинуть весь ваш код и написать все с нуля.

«Что такое плохой/хороший код» — вопрос риторический. В нашей статье под качественным кодом мы будем понимать:
- корректный с точки зрения платформы (без запросов к БД в шаблонах компонентов, запросы к БД с использованием индексов),
- совместимый с актуальными версиями PHP (5.6, 7.0),
- соответствующий единым стандартам кодирования, принятым в команде,
- без ляпов (запросы к БД в цикле, запросы к внешним системам на хитах),
- без уязвимостей (XSS, CSRF и т.д.).
С написанием хорошего кода отлично справляются самые опытные из нас: тимлиды. Но их мало (в штуках), а их время стоит дорого. У менее опытных разработчиков бывают проблемы со всем вышеперечисленным.
Как обеспечить качество кода с точки зрения методологии известно. Нужно развивать в команде процессы Continuous Integration: версионирование, тестирование, code review. Мы решили разобраться: какие инструменты подойдут для автоматизации code review при промышленной веб-разработке на PHP. А заодно проверим, как найденные инструменты оценят код нашего собственного сайта и нескольких решений из Marketplace 1С-Битрикс.
Инструменты для автоматизации code review PHP
Методика поиска инструментов
Мы нашли на github.com и packagist.org самые оцениваемые и самые скачиваемые проекты, связанные с анализом кода PHP. В обзор мы включили только надежные (созданы не вчера), поддерживаемые (есть сообщество и контрибьюторы) и популярные (количество звезд-”лайков”).
Выделили три категории инструментов:
- проводящие анализ кода с целью поиска проблемных мест;
- проверяющие совместимость версий PHP 5-7;
- проверяющие уязвимости.
Инструменты для анализа PHP-кода

PHP Code Sniffer анализирует PHP, CSS и JavaScript-файлы на соответствие стандартам кодирования, находит и исправляет ошибки. Стандарт представляет собой совокупность sniff-файлов, задающих правила. Количество установок анализатора с 2016 года превысило ~330 тысяч. Использование зафиксировано в ~7500 проектах.
PHP CS Fixer — инструмент, разработанный автором фрэймворка Symfony. Обнаруживает и исправляет ошибки в коде. Помимо следования стандартам кодирования (PSR-1, PSR-2 и др.). Позволяет писать собственные правила. Поддерживает PHP 7. Проект стремительно развивается и приобретает популярность как среди пользователей (~325 тысяч установок с начала 2016 года), так и у разработчиков (с 2017 года используется в ~1500 проектах).
PHP Mess Detector определяет ошибки кода, неоптимальные и усложненные места, неиспользуемые переменные, методы, свойства. Позволяет создавать пользовательские правила. Поддерживает PHP 7. Сохраняет отчеты в трех форматах: текстовый, html, xml. С 2016 года пользователи установили ~315 тысяч раз, используется в ~2000 проектах.
PHP Metrics — инструмент статического анализа для PHP. Выдает информацию о проекте и используемых классах в виде сгенерированного сайта. Поддерживает PHP 7. С 2016 года зарегистрировано ~260 тысяч скачиваний.
PHP Static Analysis Tool анализирует количество и типы параметров, передаваемых конструкторам, методам и функциям; типы, возвращаемые методами и функциями и т.д. Инструмент включает поддержку PHP 7 и предоставляет написание собственных правил. Количество скачиваний с 2016 года ~150 тысяч раз, использован разработчиками в ~200 проектах.
PHP Copy Paste Detector выдает информацию о дублированных участках кода. Проект набирает популярность (количество установок с 2016 года составляет ~100 тысяч раз, используется в ~1000 проектах).
Phan — статический анализатор для PHP. Проверяет определение и доступность методов, функций, классов, traits, интерфейсов, констант, свойств и переменных, обнаруживает неиспользуемый код, проверяет код на обратную совместимость php7 к php5. С 2016 года зафиксировано ~80 тысяч раз скачиваний.
PHP Dead Code Detector сообщает пользователю о функциях и методах, которые не используются в коде. Развитие проекта было остановлено в 2015 году. Начиная с 2016 года, количество установок пошло на спад.
Qafoo Quality Analyzer — инструмент, предназначенный для визуализации метрик исходного кода. Начиная с 2015 года, инструмент установлен пользователями ~4800 раз.
Инструменты для контроля совместимости кода с разными версиями PHP

PHP Compatibility — набор правил для PHP Code Sniffer, которые проверяют совместимость текущего кода с другими версиями PHP, включая PHP 7. Начиная с 2016 года, инструмент установлен пользователями ~22 тысячи раз.
PHP 7 Compatibility Checker — инструмент для проверки кода PHP 5.3 – 5.6 на совместимость с PHP 7. Находит потенциальные проблемы в коде и генерирует отчеты, содержащие имена файлов, номера строк и краткое описание проблемы. При этом проблемы двух типов: ошибки, вызывающие серьезные проблемы (фатальная ошибка, ошибка синтаксиса и т.д.) и предупреждения, приводящие к логическим ошибкам. Начиная с 2016 года, инструмент установлен пользователями ~15 тысяч раз.
Инструменты для поиска уязвимостей в PHP-коде

К сожалению нам не удалось найти ни одного проекта для анализа уязвимостей в PHP-коде, который заслуживал бы внимания. А жаль…
Вывод простой: не надейтесь что нажатием пары кнопок вы сможете найти все уязвимости в своем коде. Вместо этого изучите и применяйте правила безопасности, специфичные для вашей CMS/фреймворка.
Что на выходе
PHP CS Fixer
Результат запуска PHP CS Fixer — единый патч-файл, в котором указываются:
- файлы, в которых обнаружены ошибки;
- правила, которые сработали;
- изменения, затронувшие строки файла: удаленные, оставшиеся без изменений, добавленные строки.
Пример:
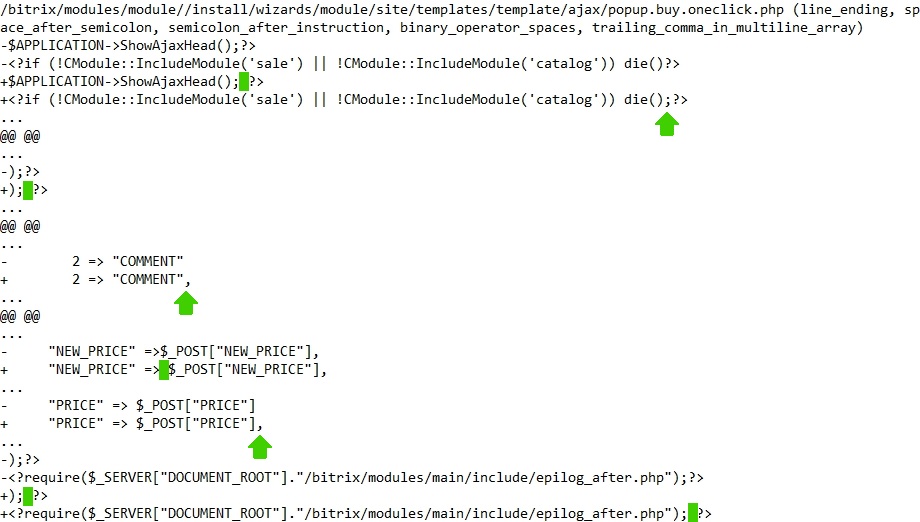
PHP Code Sniffer
Итог работы PHP Code Sniffer — список файлов и сопутствующих им сообщений о том, сколько ошибок может быть автоматически исправлено, а также таблиц с описаниями нарушений в виде: строка, вид (ошибка, предупреждение), возможность исправления, описание.
Пример:
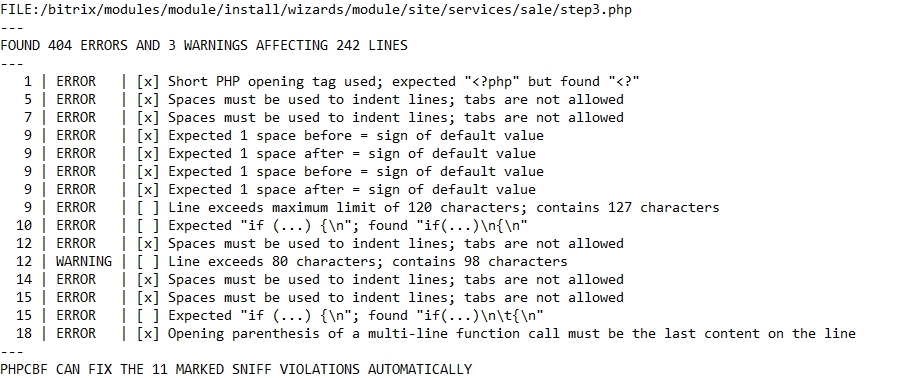
PHP Mess Detector
Отчет в PHP Mess Detector генерируется в одном из трех форматов: текстовый, html, xml. Полученный файл содержит информацию об обнаруженных проблемах в файлах. Проблема описывается начальной и конечной строкой, сработавшим правилом и поясняющим сообщением.
Пример:

PHP Dead Code Detector
Отчет в PHP Dead Code Detector — это список неиспользуемых функций и методов с указанием количества занимаемых строк, файла и номера строки в файле.
Пример:

PHP Copy Paste Detector
В отчет по PHP Copy Paste Detector заносятся файлы, в которых дублируются строки.
Пример:
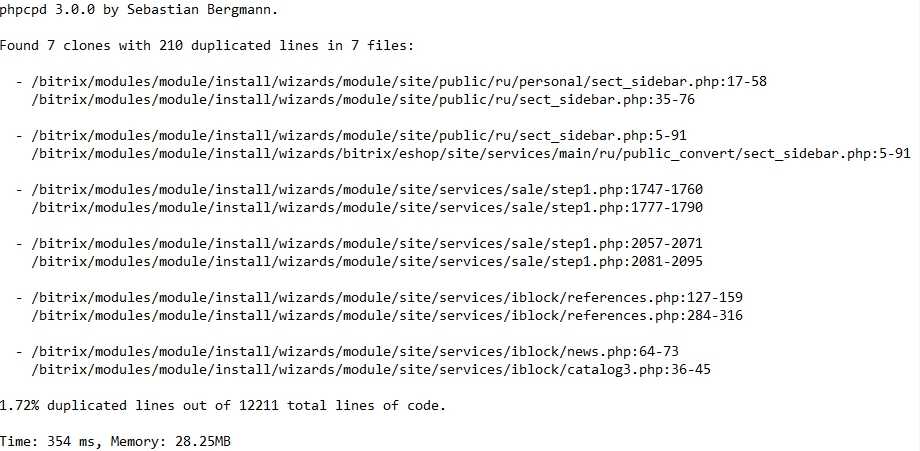
PHP Static Analysis Tool
В отчете PHP Static Analysis Tool для каждого файла, в котором обнаружены ошибки, указывается номер строки в файле и описание ошибки. В конце отчета приводится общее количество найденных ошибок.
Пример:
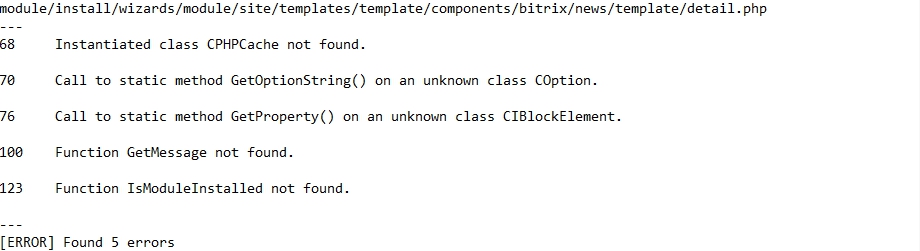
Инструмент показал себя не лучшим образом и был исключён из анализа. Почему — читайте в конце статьи.
Phan
Результат работы в Phan может быть выведен в следующих режимах: ‘text’, ‘json’, ‘csv’, ‘codeclimate’, ‘checkstyle’, и ‘pylint’. В режиме ‘csv’ выводятся следующие столбцы: файл, строка, категория ошибки, phan-тип ошибки, сообщение.
Пример:
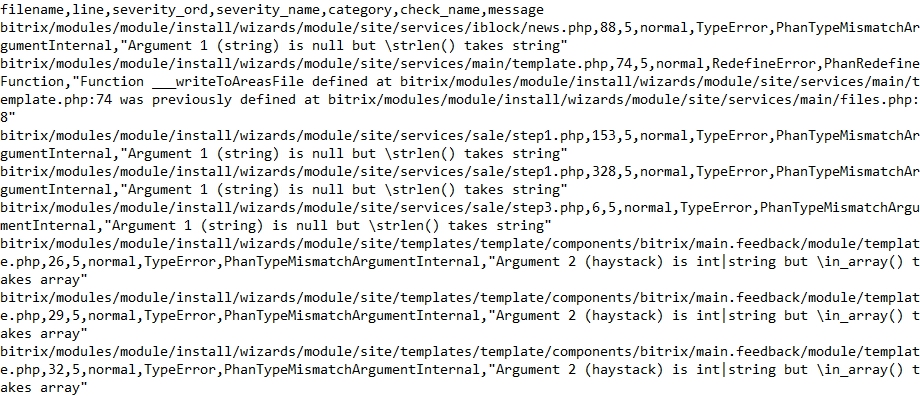
PHP Compatibility
Результатом PHP Compatibility является список ошибок и предупреждений, найденных при проверке на совместимость с указанной версией PHP.
Пример:

PHP 7 Compatibility Checker
При проверке на совместимость PHP 7 Compatibility Checker генерирует список нарушений в коде: указывается файл, строка, поясняющее сообщение и ошибочный код.
Пример:

Qafoo Quality Analyzer
Qafoo Quality Analyzer генерирует отчет в формате xml, где для каждого файла приводится список обнаруженных ошибок с описанием.
Пример:
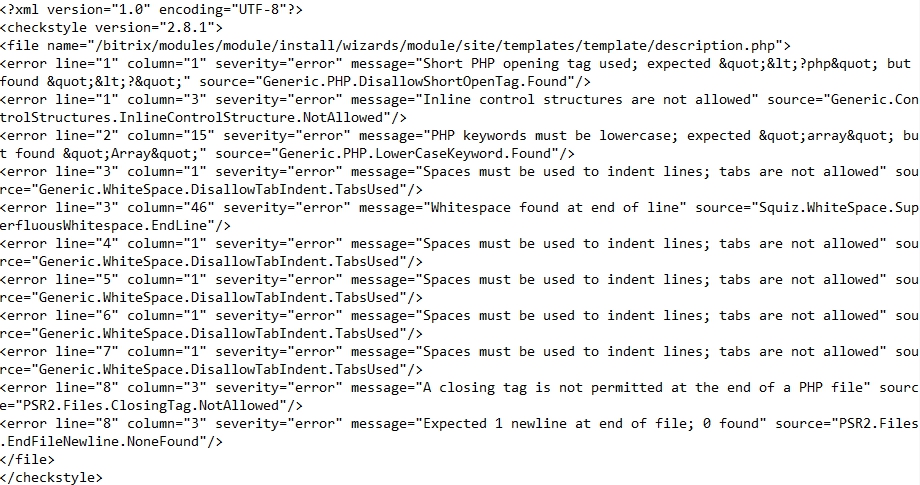
PHP Metrics
PHP Metrics по окончании своего выполнения генерирует количественный отчет по метрикам и визуализирует полученные данные в виде созданного сайта.
Пример:
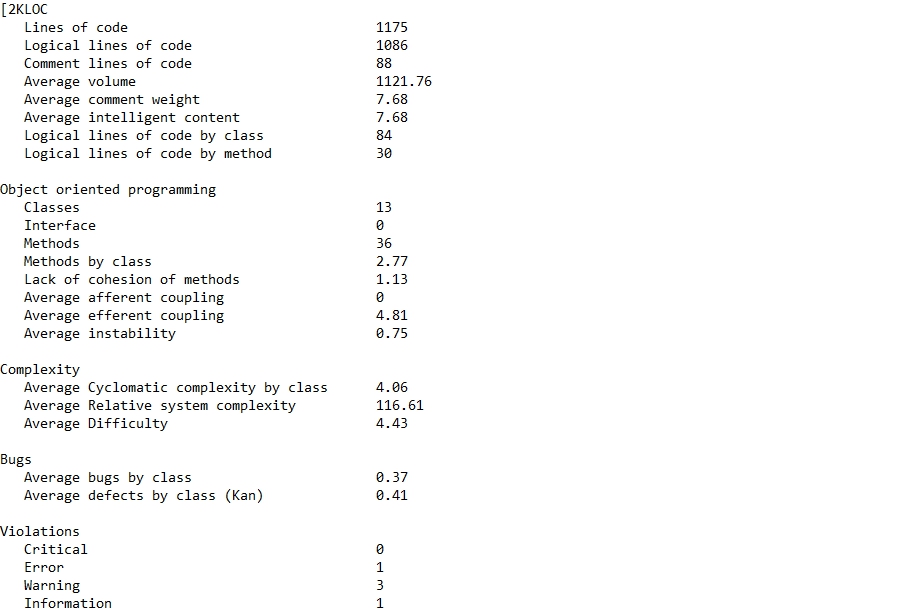
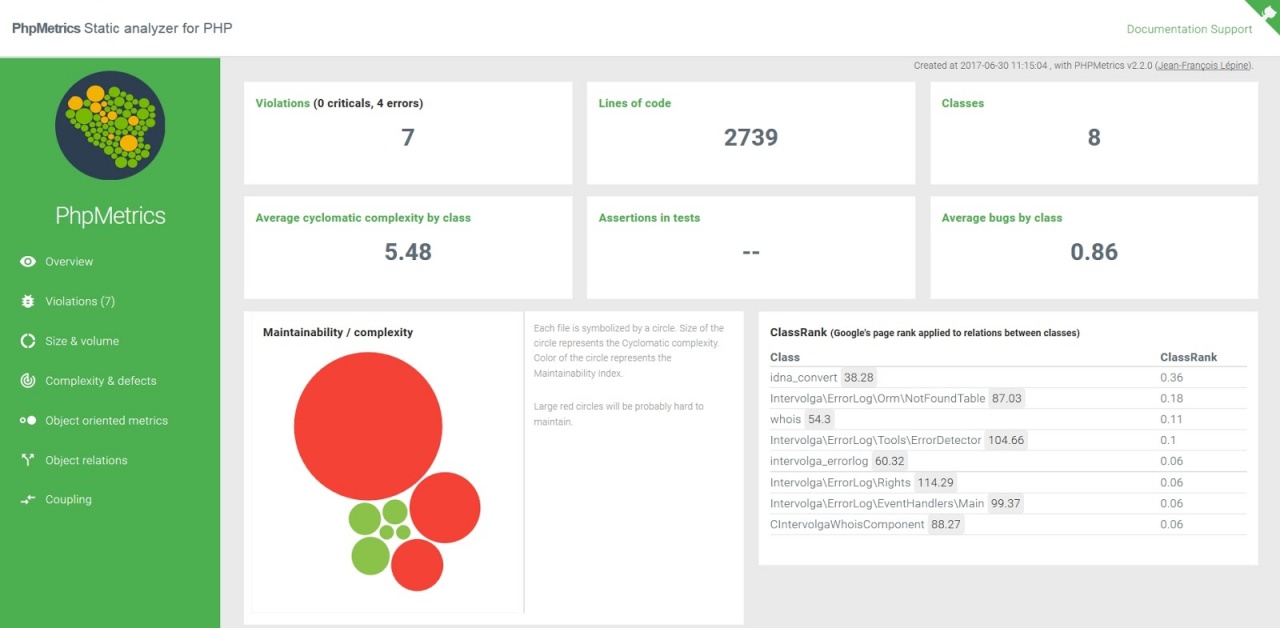
Итоговая таблица сравнения инструментов
| Что в отчёте | Инструмент объясняет, в чём ошибка | Что считать? Какая метрика? | Своя конфигурация правил, свои правила | |
| PHP CS Fixer | Патч-файл с перечнем рекомендованных изменений | Нет | Количество строк, которые предлагает заменить инструмент | Да |
| PHP Code Sniffer | Таблицы с перечнем ошибок и отметкой, какие можно исправить автоматически | Да |
1. Количество ошибок 2. Количество неисправимых ошибок |
Да |
| PHP 7 Compatibility Checker | Единый отчёт, по каждой ошибке: файл, строка, объяснение сути ошибки | Да | Количество ошибок | Нет |
| PHP Compatibility | Единый отчёт, по каждой ошибке: файл, строка, объяснение сути ошибки | Да | Количество ошибок | Да |
| PHP Copy Paste Detector | Единый отчёт с перечнем мест, где повторяется тот или иной участок кода | Да* |
1. Количество “клонов” 2. Количество повторяющихся строк |
Нет |
| PHP Dead Code Detector | Перечень неиспользуемых функций и методов, файл с их объявлением и количество строк кода | Да* |
1. Количество неиспользуемых функций/методов 2. Количество строк, которые занимают такие функции/методы |
Нет |
| PHP Mess Detector | Перечень ошибок: файл, строка, правило | Да | Количество ошибок | Да |
| PHP Metrics | Перечень ошибок: файл, строка, правило | Да | Количество ошибок | Да |
| PHP Static Analysis Tool | Перечень ошибок: файл, строка, правило | Да | Количество ошибок | Да |
| Qafoo Quality Analyzer | Перечень ошибок: файл, серьёзность ошибки, строка, правило | Да |
1. Количество ошибок 2. Количество предупреждений |
Да |
| Phan | Перечень ошибок: файл, серьёзность ошибки, строка, правило | Да |
1. Количество ошибок категории low 2. Количество ошибок категории normal 3. Количество ошибок категории critical |
Да |
| * — у инструмента единственное назначение, объяснения ошибок не требуется |
Апробация инструментов на 1С-Битрикс

Каждый из инструментов был опробован на коде:
- тиражных решений из Marketplace 1С-Битрикс (3 платных решения, 5 бесплатных),
- современного сайта ИНТЕРВОЛГИ (на 1С-Битрикс),
- устаревшего сайта ИНТЕРВОЛГИ (на самописной CMS).
Прежде чем подвести итоги, сообщаем что инструмент PHP Static Analysis Tool был дисквалифицирован и исключён из соревнования. Причина — 90% его ошибок это “неизвестная константа”, “неизвестный метод”, “неизвестный класс” ядра Битрикса (мы проверяли только папку с решением). То есть, чем больше решение использовало API Bitrix, тем больше в нём было “ошибок”. Попытка добавить ядро Битрикса в анализ привела к аварийному завершению работы инструмента с ошибкой “Класс BitrixMainSystemException объявлен дважды”. И действительно, в ядре множество классов объявленных в разных местах. Решив “а давайте временно уберём этот класс”, получили другую ошибку. Убрали её — получили третью и т.д. Попытки прекратили после 13-ой итерации.
Теперь к итогам сравнения решений. Мы считали не общее количество ошибок, а количество ошибок на 1000 строк кода.
ВАЖНО! Чтобы получить максимально показательную картину, мы суммировали ВСЕ замечания ВСЕХ 15 инструментов. Не удивлятесь что число ошибок часто больше числа строк.
Места распределились таким образом:
- Старый сайт ИВ (703 ошибки на 1000 строк)
- 1С-Битрикс: Современный интернет-магазин (1457 ошибки на 1000 строк)
- Новый сайт ИВ (1881 ошибки на 1000 строк)
- 1С-Битрикс: Корпоративный сайт (1998 ошибки на 1000 строк)
- Платный ИМ (2506 ошибки на 1000 строк)
- Платный ИМ (2525 ошибки на 1000 строк)
- Платный ИМ (2682 ошибки на 1000 строк)
- Бесплатный ИМ (3542 ошибки на 1000 строк)
- 1С-Битрикс: Информационный портал (3578 ошибки на 1000 строк)
- Бесплатный ИМ (7361 ошибки на 1000 строк)
ВАЖНО! Чтобы получить максимально показательную картину, мы суммировали ВСЕ замечания ВСЕХ 15 инструментов. Не удивлятесь что число ошибок часто больше числа строк.
Подробные результаты приведены в таблице.
То, что лучшим стал старый сайт ИВ нас искренне удивило — мы ожидали прямо противоположного результата. У этого проекта 2 рекордных показателя — количество ошибок и количество строк кода. Так и вышло, что на 1000 строк кода проблем меньше всего. Но старый сайт — “почётный” участник, посмотрим на реальные результаты.
Настоящий победитель нашего исследования — 1С-Битрикс: Современный интернет-магазин. Что можно о нём сказать по результатам исследования:
- Из 1000 строк в этом решении — в среднем 17 строк “копипасты”.
- В 2 строках есть вызовы устаревшего API.
- Есть 6 нарушений при работе с методами и полями.
- 284 строки кода можно отформатировать автоматически с помощью PHP CS Fixer.
- Почти нет проблем с совместимостью PHP.
Второе место получает новый сайт ИНТЕРВОЛГИ. Разрабатывавшийся силами всей компании в разные годы, он как-то смог не уронить высокую планку качества, заданную компанией 1С-Битрикс.
Третье место — 1С-Битрикс: Корпоративный сайт. Снова 1С-Битрикс показал всем, как надо делать сайты.
Худшим решением по мнению “жюри” признан бесплатный ИМ из ТОПа маркетплейса.
Добавим ложку дёгтя в бочку мёда компании 1С-Битрикс — вторым с конца оказалось тоже их решение, на которой выросло не одно поколение программистов.
Предпоследнее место — 1С-Битрикс: Информационный портал
Что касается инструментов… По-настоящему полезным, почти без оговорок, показал себя PHP Copy Paste Detector — на нашем сайте, например, он находил блоки кода по 50-100 строк, повторяющиеся в 2-3 местах. Единственная оговорка — часто он ругается на вызовы вложенных компонентов (например, catalog.element внутри catalog).
Отличить настоящие ошибки от ложного срабатывания было сложно в PHP Dead Code Detector — тут оказывались обработчики событий, агенты, конструкторы и инсталляторы, которые явным образом нигде не вызываются в коде или вызываются извне модулей.
Насчёт PHP Static Analysis Tool уже было сказано, что почти все его ошибки были “ложными срабатываниями”.
Хорошо показал себя PHP Mess Detector: отследил мелкую, но неприятную ошибку статического вызова динамических методов и наоборот. В то же время он ругался на каждый else, так как “else is never necessary and you can simplify the code to work without else”.
Главный “хлеб” таких инструментов, как Qafoo Quality Analyzer, PHP Code Sniffer, PHP CS Fixer: превышение длины строк, переводы строк в конце файла, короткие-длинные открывающие php-теги, пробелы после ключевых слов if, for, while и т.п. Из предлагаемого инструментами набора правил мы выбрали наиболее похожие на стандарт оформления кода 1С-Битрикс, но всё равно получили около 50% ложных срабатываний.
Полезную статистику предоставляет PHP Metrics, если в вашей команде есть понимание, сколько операторов для класса уже “много”, а сколько — “ещё нормально”. Аналогично с цикломатической сложностью.
Вывод
Смысл затеи с инструментами проверки качества кода был в том, чтобы выяснить какой инструмент стоит выбрать для автоматизации Code Review. Эту цель мы достигли и свой выбор остановили на PHP CS Fixer и PHP Code Sniffer. Они адекватны задаче, популярны, развиваются, их можно расширять, и есть масса уже готовых тестов. Осталось только адаптировать их к реалиям разработки сайтов на 1С-Битрикс: Управление Сайтом.
Теперь, с той же обстоятельностью и упорством, с которыми мы писали этот обзор, будем внедрять эти инструменты в свою командную разработку.