Кодирование
информации при передаче с помехами.
Для этих целей
используются помехоустойчивые коды,
позволяющие обнаруживать и исправлять
ошибки. Способность кода обнаруживать
и исправлять ошибки обусловлена наличием
избыточных символов.
Кратностью ошибки
называют количеством исправленных
символов в кодовой комбинации.
Кодовое расстояние
d
– это число символов, в которых комбинации
отличаются одна от другой. Достаточно
подсчитать число единиц, получаемых
после сложения по mod
2 всех комбинаций.
Минимальное
расстояние, взятое по всем парам кодовых
разрешённых комбинаций кода, называется
минимальным кодовым расстоянием d
min.
При d=1
все кодовые комбинации являются
разрешёнными
При d=2
ни одна из разрешённых кодовых комбинаций
при одиночной ошибке не переходит в
другую разрешённую комбинацию. Тогда
подмножество разрешённых кодовых
комбинаций может быть образованно по
принципу чётности в них числа единиц.
В общем случае при
необходимости обнаруживать ошибки
кратности до r
включительно минимальное Хеммингово
расстояние между разрешёнными
комбинациями должно быть по крайней
мере, на единицу больше *, т.е
d0min≥r+1
Тогда ошибка
кратности r
не в состоянии перевести одну разрешённую
комбинацию в другую.
Для исправления
одиночной ошибки каждой разрешённой
кодовой комбинацией необходимо
сопоставить подмножество запрещённых
кодовых комбинаций. Чтобы эти подмножества
не пересекались, Хеммингово расстояние
между разрешёнными кодовыми комбинациями
должно быть не меньше трёх.
В общем случае для
облегчения возможности исправления
всех ошибок кратности до S
включительно минимальным Хемминоговым
расстоянием между комбинациями:
dnmin≥2S+1
Для исправления
всех ошибок кратности S
и одновременного обнаружения всех
ошибок кратности r (r≥S)
минимальное Хеммингово расстояние
нужно выбирать из условия
dn0min≥r+S+1
Приведённые формулы
справедливы для случая взаимно-независимых
ошибок и дают завышенные значения при
помехе, передаваемой с сигналом.
Двоичные линейные
групповые коды.
Двоичный групповой
код является n-разрядным
и содержит k-информационных
разрядов и m
= (n-k)
– проверочных, являющихся избыточными.
В двоичном линейном
коде значения проверочных символов
(опознавателя – синдрома) подбирают
так, чтобы сумма по mod
2 всех индексов (включая проверочный),
входящих в каждое из равенств, равнялось
нулю.
Количество
подлежащих исправлению ошибок является
орпеделяющим для выбора числа избыточных
символов (n-k).
Их должно быть достаточно для того,
чтобы обеспечить необходимое число
опознавателей.
Если необходимо
исправить все одиночные ошибки, то
исправлению подлежит n
ошибок, тогда необходимое число
проверочных разрядов должно определяться
из соотношения
2n-k-1≥n,
или
2n-k-1≥Cn1
(k=4, n=7),
(k=11,
n=15),
(k=26,
n=31).
Если необходимо
исправить все одиночные и двойные
ошибки, то количество проверочных
разрядов выбирается из соотношения
2n—k-1≥Cn1+Cn2
(k=2,
n=7).
В общем случае для
исправления всех независимых ошибок
кратности до S
включительно имеем
2n—k-1≥Cn1+Cn2+…+CnS
Это теоретический
придел минимально возможного числа
проверочных символов, но их иногда
требуется больше.
Проверочные
равенства кода Хэмминга
В качестве примера
рассмотрим коды, предназначенные для
исправления одиночных ошибок.
Оптимальные коды:
(4,7); (15,11); (31,26); (63,57); и т.д., где первое
число- n,
а второе –k.
Проверочные
равенства (для кода (15,11)):
E1=a1+a3+a5+a7+a9+a11+a13+a15=0
E2=a2+a3+a6+a7+a10+a11+a14+a15=0
E3=a14+a15+a16+a17+a12+a13+a14+a15=0
E4=a7+a9+a10+a11+a12+a13+a14+a15=0
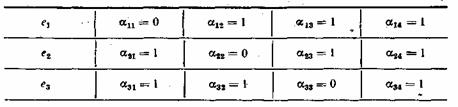
Контолирующие
разряды : 20=1
—
a1
21=2
— a2
22=4
— a4
23=8
— a8.
Пример
Передать по
дискретному каналу число 10d:
(10d=1010)
кодом, исправляющим одиночные ошибки.
x3=a7=1;
a1=a3+a5+a7=0+1+1=0
x2=a6=0;
a2=a3+a6+a7=0+0+1=1
x1=a5=1; a4=a5+a6+a7=1+0+1=0
x0=a3=0
Передаваемый код:
1 0 1 0 0 1 0
Если исправить
ошибку в разряде a6,то
тогда имеем код 1 1 1 0 0 1 0 и
E1=a1+a3+a5+a7=0,
E2=a2+a3+a6+a7=1,
E3=a4+a5+a6+a7=1.
Модифицированный
код Хэмминга
К контрольным
разрядам добавляется ещё один разряд
контроля чётности всех одновременно
считываемых (записываемых) индексных
и конролирующих разрядов, т.е будем
иметь код, способный исправлять одиночные
и обнаруживать двойные ошибки: коды
(8,4); (16,11); (32,26) и т.д.
При считывании
формируются корректирующее число
Хэмминга
Ek
Ek-1…E1
и разряд общей чётности F
для всех считанных разрядов, включая
контрольный разряд. Так для кода (8, 4)
F=a5+a7+a6+…+a1
Результаты
отображены в виде таблицы
|
Корректирующее |
F |
Наличие |
|
Ek |
||
|
Нули |
0 |
Нет ошибок |
|
Нули |
1 |
Ошибка в контр. |
|
≠0 |
0 |
Двойная ошибка |
|
≠0 |
1 |
Одиночная ошибка |
Соседние файлы в папке ТИК-контр-з
- #
- #
- #
- #
- #
- #
Все помехоустойчивые коды делятся на блоковые и непрерывные (их называют также цепные или рекуррентные). При блоковом кодировании данные передаются отдельными блоками (словами, кодовыми комбинациями). При этом поступающие в кодер символы, разбиваются на блоки по k информационных символов. В кодере этот блок информационных символов преобразуется в блок из ![]() кодовых символов, где п называется длиной кода. Добавленные при кодировании r = n – k символов являются проверочными. Такой блоковый код принято обозначать как (n, k) – код. Величину R = k / n называют скоростью кода, а величину, обратную скорости, Rи = n / k называют избыточностью кода.
кодовых символов, где п называется длиной кода. Добавленные при кодировании r = n – k символов являются проверочными. Такой блоковый код принято обозначать как (n, k) – код. Величину R = k / n называют скоростью кода, а величину, обратную скорости, Rи = n / k называют избыточностью кода.
Проверочные символы являются избыточными, они необходимы для обнаружения и (или) исправления ошибок, возникших при передаче. Существуют безызбыточные (примитивные) коды. У этих кодов проверочных символов нет (n = k), поэтому у них самая высокая скорость кода R = 1, но они не способны обнаруживать ошибки.
Ошибки при передаче кодового слова возникают потому, что некоторые из переданных символов могут быть приняты неверно. Принцип обнаружения ошибок заключается в следующем. Если блоковый (n, k) – код имеет основание (количество символов в используемом алфавите) q, то возможно Q = qn различных кодовых слов. Для передачи же используются только Qр = qk кодовых слов, которые называются разрешенными. Остальные Qз = Q – Qр слов априорно для передачи не используются и называются запрещенными.
В дальнейшем будут рассматриваться только двоичные коды, у которых алфавит состоит из двух символов 0 и 1, т. е. с основанием q = 2.
В памяти кодера и декодера хранится таблица разрешенных слов. Работа кодера заключается в выборе разрешенного кодового слова, соответствующего поступившему информационному слову. Приходящее в декодер кодовое слово сравнивается с таблицей разрешенных слов и, если происходит совпадение, то потребитель получает информационное слово, соответствующее данному разрешенному слову. Если же совпадение не наступает, то слово считается запрещенным, а потребитель получает сообщение об ошибке. Однако если совокупность ошибок превратит одно разрешенное слово в другое разрешенное, то возникшие ошибки не могут быть обнаружены.
Пример 1. Требуется передача сообщения о наступлении одного из четырех возможных событий A, B, C, D. Эти события представлены информационными словами 00, 01, 10, 11 соответственно. При передаче этих слов безызбыточным кодом все возможные комбинации являются разрешенными. Поэтому достаточно искажения хотя бы одного символа, чтобы сообщение было принято неверно. Так, если передавалось сообщение A в виде кодового слова 00, а принято было слово 01, то декодер, найдя в таблице такое разрешенное слово, вынесет решение о приеме сообщения B.
Если к вышеперечисленным информационным словам добавить по одному избыточному символу, поставив в соответствие разрешенные слова 000, 011, 101, 110, то искажение одного символа в переданном слове можно обнаружить. Так, если передавалось сообщение A в виде кодового слова 000, а принято было слово 001, то декодер, не найдя в таблице такого разрешенного слова, объявит принятое слово запрещенным и сообщит об обнаружении ошибки в слове. Однако если было принято слово 011, то декодер вынесет решение о приеме сообщения B.
Для сравнения слов необходимо задать метрику, т. е. способ измерения расстояний между кодовыми словами. Известно несколько способов выбора метрики, из которых наиболее распространенным является метрика Хэмминга. Расстоянием Хэмминга между двумя кодовыми словами называется количество несовпадающих символов в этих словах. Важнейшей характеристикой блочного кода является кодовое расстояние – d, оно равно наименьшему расстоянию из всех возможных для данного кода.
Пример 2. Для передачи используются три разрешенных слова 000, 100, 111. Расстояние между первым и вторым словами равно 1, между вторым и третьим словами – 2, а между первым и вторым – 3. Кодовое расстояние для данного кода d = 1.
Очевидно, что у безызбыточного кода d = 1, так как между любой парой его слов расстояние равно единице. Этот код не позволяет обнаруживать ошибки. Приведенный в примере 1 избыточный код (он называется кодом с проверкой на четность) имеет d = 2. Он позволяет гарантировано обнаружить однократную ошибку.
Кратностью ошибки называется количество неправильно принятых символов в кодовом слове. Если искажения символов возникают независимо друг от друга, то ошибки меньшей кратности более вероятны, чем ошибки большей кратности. Следовательно, прежде всего требуется вести борьбу с ошибками малой кратности.
Можно заметить, что максимальная кратность гарантировано обнаруживаемой ошибки tо = d – 1. Действительно, при возникновении необнаруженной ошибки одно разрешенное слово должно превратиться в другое разрешенное слово. А для этого надо, чтобы кратность возникшей ошибки была не менее d, поскольку все разрешенные слова по определению кодового расстояния различаются не менее, чем на d символов. Если же принятое кодовое слово хотя бы на один символ отличается от разрешенных кодовых слов, то будет зафиксировано появление ошибки.
При декодировании вместо обнаружения ошибок возможно их исправление. Так, если было принято запрещенное кодовое слово, то можно не отбрасывать его, а найти наиболее похожее разрешенное слово и объявить его принятым. Таким образом, возникшие при передаче ошибки считаются исправленными, и потребитель получает не сообщение об ошибке, а очередное информационное слово. При декодировании с исправлением ошибок решение принимается по минимуму расстояния Хэмминга, т. е. переданным считается то разрешенное кодовое слово, которое отличается от принятого слова наименьшим количеством несовпадающих символов.
Пример 3. Для передачи используется два разрешенных кодовых слова 000 и 111. Было принято слово 001, на беглый взгляд оно больше похоже на 000, чем на 111. Действительно, слово 001 от первого разрешенного слова отличается на один символ, а от второго на два. Так как однократная ошибка вероятнее двукратной, то скорее всего было передано первое слово и в нем исказился один символ. Декодер принимает решение по минимуму расстояния Хэмминга и объявляет принятым разрешенное слово 000.
В
рассмотренном примере код имеет d = 3, он позволяет гарантировано исправлять однократную ошибку. Можно заметить, что максимальная кратность гарантировано исправляемой ошибки :
где [x] –целая часть числа x.
Существует так называемый прием со стиранием. Это частный случай приема с мягким решением. Его особенность состоит в том, что решающее устройство имеет область неопределенности, в которую попадают все сигналы, не превысившие установленный порог. Решающее устройство выдает при этом специальный символ, заменяющий неуверенно принятый сигнал. Этот символ оказывается, таким образом, «стертым». Так, при передаче двоичным кодом на выходе решающего устройства появляется один из трех символов: 0, 1 и символ стирания Х.
Восстановить стертые знаки часто оказывается легче, чем исправить ошибочные. Это обусловлено тем, что местонахождение стертых знаков известно, так как оно обозначено символом стирания Х, тогда как местоположение ошибок неизвестно, и каждый из знаков 0 или 1 может быть как верным, так и неверным.
Для сохранения различимости кодовых комбинаций при стирании не более s знаков кодовое расстояние d должно удовлетворять условию:
![]()
Для того, чтобы код мог одновременно исправлять t ошибок и восстанавливать s стертых символов кодовое расстояние должно быть:
![]()
Преимущество кодов со стираниями очевидно: например, при d = 3 такой код может как и обычный исправить одиночную ошибку, но может восстановить два стертых символа.
Описанный выше метод кодирования и декодирования, основанный на запоминании таблицы разрешенных слов, называется универсальным, поскольку годится для всех блочных кодов. Однако этот метод практически не применяется из-за сложности реализации и низкого быстродействия. Если длина информационного слова достаточно велика, то требуется большой объем памяти для хранения всех разрешенных слов. Кроме того, сравнение принятого слова со всей таблицей может продолжаться очень долго, что недопустимо при работе в режиме реального времени. Поэтому созданы другие методы кодирования и декодирования блочных кодов, в которых используется не поиск разрешенных слов, а математические операции над информационными и проверочными символами.
Чаще всего применяются систематические коды. Систематическим называется такой блочный код, у которого информационные и проверочные символы расположены на одних и тех же позициях во всех кодовых словах
В примере 1 был рассмотрен избыточный код с проверкой на четность. При его кодировании к информационному слову добавляется один проверочный символ так, чтобы количество единиц в кодовом слове было четным. При декодировании проверяется выполнение этого условия. Если количество единиц в принятом слове нечетно, то слово является запрещенным. Таким образом, можно обойтись без запоминания таблицы разрешенных слов.
Если в кодере используются лишь линейные операции над поступающими информационными символами, то код называется линейным. Принцип кодирования и декодирования линейного кода заключается в системе линейных уравнений, в которую входят информационные и проверочные символы. Для каждого кода эта система своя. Рассмотрим её на примере кода (7, 4), имеющего d = 3.
a1 а2 а3 а5 = 0
а2 а3 а4 а6 = 0
а1 а2 а4 а7 = 0
где — знак сложения по модулю 2, символы а1, а2, а3, а4 являются информационными, а символы а5, а6, а7 – проверочными. При кодировании проверочные символы вычисляются из информационных так, чтобы они удовлетворяли системе уравнений. При декодировании символы принятого слова подставляются в систему уравнений и вычисляется её правая часть. Эта правая часть представляет собой вектор, который называется исправляющим вектором или синдромом. Анализ синдрома позволяет исправлять ошибки. Каждому возможному синдрому соответствует номер искаженного символа.
|
Синдром |
Номер искаженного символа |
|
000 |
Ошибок не обнаружено |
|
101 |
1 |
|
111 |
2 |
|
110 |
3 |
|
011 |
4 |
Проверочные символы вычисляются с помощью производящей (порождающей) матрицы. Производящая матрица G – это таблица, у которой k строк и n столбцов, в которой записаны k линейно независимых разрешенных комбинаций данного кода. По ней можно построить все остальные разрешенные кодовые комбинации, складывая поразрядно по модулю 2 строки производящей матрицы во всех возможных сочетаниях. В памяти кодера достаточно иметь производящую матрицу. С помощью набора сумматоров можно получить любую разрешенную кодовую комбинацию.
Производящую матрицу принято представлять в каноническом виде. Для рассматриваемого кода она будет:

Где левая часть матрицы — единичная матрица, соответствующая информационным символам, а правая часть матрицы соответствует проверочным символам. Схема кодирования строится на основе производящей матрицы. Кодер состоит из k-элементного регистра для информационного слова и n – k сумматоров по модулю 2. Элементы правой части производящей матрицы pij отвечают за вычисление проверочных символов. Они показывают связь i-ой ячейки регистра с j-м сумматором. Если pij = 1, то связь есть, если pij = 0 , то связи нет.
Д
ля декодирования требуется проверочная матрица H, содержащая n – k строк и n столбцов. В каждой строке этой матрицы единицы находятся в тех разрядах, которые входят в соответствующее проверочное уравнение. Для рассмотренного кода Хэмминга (7, 4) проверочная матрица будет иметь вид:
Существует особый класс блочных линейных кодов – циклические коды. Они отличаются тем, что всякая циклическая перестановка символов разрешенного кодового слова приводит также к разрешенному слову. Все кодовые комбинации можно получить циклическим сдвигом одного слова. Поэтому важным достоинством циклических кодов является то, что операции кодировании и декодирования легко реализуются на сдвигающих регистрах.
7.1. Классификация корректирующих кодов
7.2. Принципы помехоустойчивого кодирования
7.3. Систематические коды
7.4. Код с четным числом единиц. Инверсионный код
7.5. Коды Хэмминга
7.6. Циклические коды
7.7. Коды с постоянным весом
7.8. Непрерывные коды
7.1. Классификация корректирующих кодов
В каналах с помехами эффективным средством повышения достоверности передачи сообщений является помехоустойчивое кодирование. Оно основано на применении специальных кодов, которые корректируют ошибки, вызванные действием помех. Код называется корректирующим, если он позволяет обнаруживать или обнаруживать и исправлять ошибки при приеме сообщений. Код, посредством которого только обнаруживаются ошибки, носит название обнаруживающего кода. Исправление ошибки при таком кодировании обычно производится путем повторения искаженных сообщений. Запрос о повторении передается по каналу обратной связи. Код, исправляющий обнаруженные ошибки, называется исправляющим, кодом. В этом случае фиксируется не только сам факт наличия ошибок, но и устанавливается, какие кодовые символы приняты ошибочно, что позволяет их исправить без повторной передачи. Известны также коды, в которых исправляется только часть обнаруженных ошибок, а остальные ошибочные комбинации передаются повторно.
Для того чтобы «од обладал корректирующими способностями, в кодовой последовательности должны содержаться дополнительные (избыточные) символы, предназначенные для корректирования ошибок. Чем больше избыточность кода, тем выше его корректирующая способность.
Помехоустойчивые коды могут быть построены с любым основанием. Ниже рассматриваются только двоичные коды, теория которых разработана наиболее полно.
В настоящее время известно большое количество корректирующих кодов, отличающихся как принципами построения, так и основными характеристиками. Рассмотрим их простейшую классификацию, дающую представление об основных группах, к которым принадлежит большая часть известных кодов [12]. На рис. 7.1 показана схема, поясняющая классификацию, проведенную по способам построения корректирующих кодов.
Все известные в настоящее время коды могут быть разделены
на две большие группы: блочные и непрерывные. Блочные коды характеризуются тем, что последовательность передаваемых символов разделена на блоки операции кодирования и декодирования в каждом блоке производятся отдельно. Отличительной особенностью непрерывных кодов является то, что первичная последовательность символов, несущих информацию, непрерывно преобразуется по определенному закону в другую последовательность, содержащую избыточное число символов. Здесь процессы кодирования и декодирования не требуют деления кодовых символов на блоки.
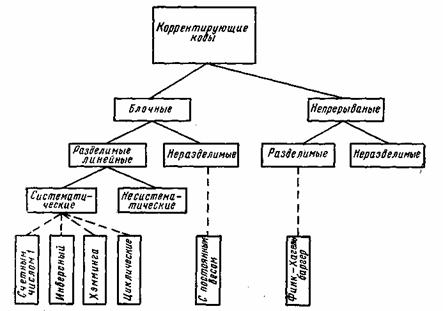
Рис. 7.1. Классификация корректирующих кодов
Разновидностями как блочных, так и непрерывных кодов являются разделимые и неразделимые коды. В разделимых кодах всегда можно выделить информационные символы, содержащие передаваемую информацию, и контрольные (проверочные) символы, которые являются избыточными и служат ‘исключительно для коррекции ошибок. В неразделимых кодах такое разделение символов провести невозможно.
Наиболее многочисленный класс разделимых кодов составляют линейные коды. Основная их особенность состоит в том, что контрольные символы образуются как линейные комбинации информационных символов.
В свою очередь, линейные коды могут быть |разбиты на два подкласса: систематические и несистематические. Все двоичные систематические коды являются групповыми. Последние характеризуются принадлежностью кодовых комбинаций к группе, обладающей тем свойством, что сумма по модулю два любой пары комбинаций снова дает комбинацию, принадлежащую этой группе. Линейные коды, которые не могут быть отнесены к подклассу систематических, называются несистематическими. Вертикальными прямоугольниками на схеме рис. 7.1 представлены некоторые конкретные коды, описанные в последующих параграфах.
7.2. Принципы помехоустойчивого кодирования
В теории помехоустойчивого кодирования важным является вопрос об использовании избыточности для корректирования возникающих при передаче ошибок. Здесь удобно рассмотреть блочные моды, в которых всегда имеется возможность выделить отдельные кодовые комбинации. Напомним, что для равномерных кодов, которые в дальнейшем только и будут изучаться, число возможных комбинаций равно M=2n, где п — значность кода. В обычном некорректирующем коде без избыточности, например в коде Бодо, число комбинаций М выбирается равным числу сообщений алфавита источника М0и все комбинации используются для передачи информации. Корректирующие коды строятся так, чтобы число комбинаций М превышало число сообщений источника М0. Однако в.этом случае лишь М0комбинаций из общего числа используется для передачи информации. Эти комбинации называются разрешенными, а остальные М—М0комбинаций носят название запрещенных. На приемном конце в декодирующем устройстве известно, какие комбинации являются разрешенными и какие запрещенными. Поэтому если переданная разрешенная комбинация в результате ошибки преобразуется в некоторую запрещенную комбинацию, то такая ошибка будет обнаружена, а при определенных условиях исправлена. Естественно, что ошибки, приводящие к образованию другой разрешенной комбинации, не обнаруживаются.
Различие между комбинациями равномерного кода принято характеризовать расстоянием, равным числу символов, которыми отличаются комбинации одна от другой. Расстояние d![]() между двумя комбинациями
между двумя комбинациями ![]() и
и ![]() определяется количеством единиц в сумме этих комбинаций по модулю два. Например,
определяется количеством единиц в сумме этих комбинаций по модулю два. Например,
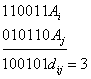
Для любого кода d![]()
![]() . Минимальное расстояние между разрешенными комбинациями ,в данном коде называется кодовым расстоянием d.
. Минимальное расстояние между разрешенными комбинациями ,в данном коде называется кодовым расстоянием d.
Расстояние между комбинациями ![]() и
и ![]() условно обозначено на рис. 7.2а, где показаны промежуточные комбинации, отличающиеся друг от друга одним символом. B общем случае некоторая пара разрешенных комбинаций
условно обозначено на рис. 7.2а, где показаны промежуточные комбинации, отличающиеся друг от друга одним символом. B общем случае некоторая пара разрешенных комбинаций ![]() и
и ![]() , разделенных кодовым расстоянием d, изображается на прямой рис. 7.2б, где точками указаны запрещенные комбинации. Для того чтобы в результате ошибки комбинация
, разделенных кодовым расстоянием d, изображается на прямой рис. 7.2б, где точками указаны запрещенные комбинации. Для того чтобы в результате ошибки комбинация ![]() преобразовалась в другую разрешенную комбинацию
преобразовалась в другую разрешенную комбинацию ![]() , должно исказиться d символов.
, должно исказиться d символов.
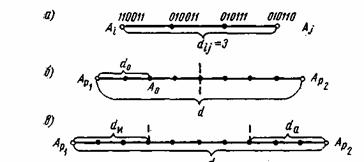
Рис. 7.2. Геометрическое представление разрешенных и запрещенных кодовых комбинаций
При искажении меньшего числа символов комбинация ![]() перейдет в запрещенную комбинацию и ошибка будет обнаружена. Отсюда следует, что ошибка всегда обнаруживается, если ее кратность, т. е. число искаженных символов в кодовой комбинации,
перейдет в запрещенную комбинацию и ошибка будет обнаружена. Отсюда следует, что ошибка всегда обнаруживается, если ее кратность, т. е. число искаженных символов в кодовой комбинации,
![]() (7.1)
(7.1)
Если g>d, то некоторые ошибки также обнаруживаются. Однако полной гарантии обнаружения ошибок здесь нет, так как ошибочная комбинация ib этом случае может совпасть с какой-либо разрешенной комбинацией. Минимальное кодовое расстояние, при котором обнаруживаются любые одиночные ошибки, d=2.
Процедура исправления ошибок в процессе декодирования сводится к определению переданной комбинации по известной принятой. Расстояние между переданной разрешенной комбинацией и принятой запрещенной комбинацией d0 равно кратности ошибок g. Если ошибки в символах комбинации происходят независимо относительно друг друга, то вероятность искажения некоторых g символов в n-значной комбинации будет равна:
![]() (7.2)
(7.2)
где ![]() — вероятность искажения одного символа. Так как обычно
— вероятность искажения одного символа. Так как обычно ![]() <<1, то вероятность многократных ошибок уменьшается с увеличением их кратности, при этом более вероятны меньшие расстояния d0. В этих условиях исправление ошибок может производиться по следующему правилу. Если принята запрещенная комбинация, то считается переданной ближайшая разрешенная комбинация. Например, пусть образовалась запрещенная комбинация
<<1, то вероятность многократных ошибок уменьшается с увеличением их кратности, при этом более вероятны меньшие расстояния d0. В этих условиях исправление ошибок может производиться по следующему правилу. Если принята запрещенная комбинация, то считается переданной ближайшая разрешенная комбинация. Например, пусть образовалась запрещенная комбинация ![]() (см.рис.7.2б), тогда принимается решение, что была передана комбинация
(см.рис.7.2б), тогда принимается решение, что была передана комбинация ![]() . Это .правило декодирования для указанного распределения ошибок является оптимальным, так как оно обеспечивает исправление максимального числа ошибок. Напомним, что аналогичное правило используется в теории потенциальной помехоустойчивости при оптимальном приеме дискретных сигналов, когда решение сводится к выбору того переданного сигнала, который ib наименьшей степени отличается от принятого. Нетрудно определить, что при таком правиле декодирования будут исправлены все ошибки кратности
. Это .правило декодирования для указанного распределения ошибок является оптимальным, так как оно обеспечивает исправление максимального числа ошибок. Напомним, что аналогичное правило используется в теории потенциальной помехоустойчивости при оптимальном приеме дискретных сигналов, когда решение сводится к выбору того переданного сигнала, который ib наименьшей степени отличается от принятого. Нетрудно определить, что при таком правиле декодирования будут исправлены все ошибки кратности
![]() (7.3)
(7.3)
Минимальное значение d, при котором еще возможно исправление любых одиночных ошибок, равно 3.
Возможно также построение таких кодов, в которых часть ошибок исправляется, а часть только обнаруживается. Так, в соответствии с рис. 7.2в ошибки кратности ![]() исправляются, а ошибки, кратность которых лежит в пределах
исправляются, а ошибки, кратность которых лежит в пределах ![]() только обнаруживаются. Что касается ошибок, кратность которых сосредоточена в пределах
только обнаруживаются. Что касается ошибок, кратность которых сосредоточена в пределах ![]() , то они обнаруживаются, однако при их исправлении принимается ошибочное решение — считается переданной комбинация А
, то они обнаруживаются, однако при их исправлении принимается ошибочное решение — считается переданной комбинация А![]() вместо A
вместо A![]() или наоборот.
или наоборот.
Существуют двоичные системы связи, в которых решающее устройство выдает, кроме обычных символов 0 и 1, еще так называемый символ стирания ![]() . Этот символ соответствует приему сомнительных сигналов, когда затруднительно принять определенное решение в отношении того, какой из символов 0 или 1 был передан. Принятый символ в этом случае стирается. Однако при использовании корректирующего кода возможно восстановление стертых символов. Если в кодовой комбинации число символов
. Этот символ соответствует приему сомнительных сигналов, когда затруднительно принять определенное решение в отношении того, какой из символов 0 или 1 был передан. Принятый символ в этом случае стирается. Однако при использовании корректирующего кода возможно восстановление стертых символов. Если в кодовой комбинации число символов ![]() оказалось равным gc, причем
оказалось равным gc, причем
![]() (7.4)
(7.4)
а остальные символы приняты без ошибок, то такая комбинация полностью восстанавливается. Действительно, для восстановления всех символов ![]() необходимо перебрать всевозможные сочетания из gc символов типа 0 и 1. Естественно, что все эти сочетания, за исключением одного, будут неверными. Но так как в неправильных сочетаниях кратность ошибок
необходимо перебрать всевозможные сочетания из gc символов типа 0 и 1. Естественно, что все эти сочетания, за исключением одного, будут неверными. Но так как в неправильных сочетаниях кратность ошибок ![]() , то согласно неравенству (7.1) такие ошибки обнаруживаются. Другими словами, в этом случае неправильно восстановленные сочетания из gc символов совместно с правильно принятыми символами образуют запрещенные комбинации и только одно- сочетание стертых символов даст разрешенную комбинацию, которую и следует считать как правильно восстановленную.
, то согласно неравенству (7.1) такие ошибки обнаруживаются. Другими словами, в этом случае неправильно восстановленные сочетания из gc символов совместно с правильно принятыми символами образуют запрещенные комбинации и только одно- сочетание стертых символов даст разрешенную комбинацию, которую и следует считать как правильно восстановленную.
Если ![]() , то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
, то при восстановлении окажется несколько разрешенных комбинаций, что не позволит принять однозначное решение.
Таким образом, при фиксированном кодовом расстоянии максимально возможная кратность корректируемых ошибок достигается в кодах, которые обнаруживают ошибки или .восстанавливают стертые символы. Исправление ошибок представляет собой более трудную задачу, практическое решение которой сопряжено с усложнением кодирующих и декодирующих устройств. Поэтому исправляющие «оды обычно используются для корректирования ошибок малой кратности.
Корректирующая способность кода возрастает с увеличением d. При фиксированном числе разрешенных комбинаций М![]() увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
увеличение d возможно лишь за счет роста количества запрещенных комбинаций:
![]() (7.5)
(7.5)
что, в свою очередь, требует избыточного числа символов r=n—k, где k — количество символов в комбинации кода без избыточности. Можно ввести понятие избыточности кода и количественно определить ее по аналогии с (6.12) как
![]() (7.6)
(7.6)
При независимых ошибках вероятность определенного сочетания g ошибочных символов в n-значной кодовой комбинации выражается ф-лой ((7.2), а количество всевозможных сочетаний g ошибочных символов в комбинации зависит от ее длины и определяется известной формулой числа сочетаний
![]()
Отсюда полная вероятность ошибки кратности g, учитывающая все сочетания ошибочных символов, равняется:
![]() (7.7)
(7.7)
Используя (7.7), можно записать формулы, определяющие вероятность отсутствия ошибок в кодовой комбинации, т. е. вероятность правильного приема
![]()
и вероятность правильного корректирования ошибок
![]()
Здесь суммирование ‘Производится по всем значениям кратности ошибок g, которые обнаруживаются и исправляются. Таким образом, вероятность некорректируемых ошибок равна:
![]() (7.8)
(7.8)
Анализ ф-лы (7.8) показывает, что при малой величине Р0и сравнительно небольших значениях п наиболее вероятны ошибки малой кратности, которые и необходимо корректировать в первую очередь.
Вероятность Р![]() , избыточность
, избыточность ![]() и число символов n являются основными характеристиками корректирующего кода, определяющими, насколько удается повысить помехоустойчивость передачи дискретных сообщений и какой ценой это достигается.
и число символов n являются основными характеристиками корректирующего кода, определяющими, насколько удается повысить помехоустойчивость передачи дискретных сообщений и какой ценой это достигается.
Общая задача, которая ставится при создании кода, заключается, в достижении наименьших значений Р![]() и
и ![]() . Целесообразность применения того или иного кода зависит также от сложности кодирующих и декодирующих устройств, которая, в свою очередь, зависит от п. Во многих практических случаях эта сторона вопроса является решающей. Часто, например, используются коды с большой избыточностью, но обладающие простыми правилами кодирования и декодирования.
. Целесообразность применения того или иного кода зависит также от сложности кодирующих и декодирующих устройств, которая, в свою очередь, зависит от п. Во многих практических случаях эта сторона вопроса является решающей. Часто, например, используются коды с большой избыточностью, но обладающие простыми правилами кодирования и декодирования.
В соответствии с общим принципом корректирования ошибок, основанным на использовании разрешенных и запрещенных комбинаций, необходимо сравнивать принятую комбинацию со всеми комбинациями данного кода. В результате М сопоставлений и принимается решение о переданной комбинации. Этот способ декодирования логически является наиболее простым, однако он требует сложных устройств, так как в них должны запоминаться все М комбинаций кода. Поэтому на практике чаще всего используются коды, которые позволяют с помощью ограниченного числа преобразований принятых кодовых символов извлечь из них всю информацию о корректируемых ошибках. Изучению таких кодов и посвящены последующие разделы.
7.3. Систематические коды
Изучение конкретных способов помехоустойчивого кодирования начнем с систематических кодов, которые в соответствии с классификацией (рис. 7.1) относятся к блочным разделимым кодам, т. е. к кодам, где операции кодирования осуществляются независимо в пределах каждой комбинации, состоящей из информационных и контрольных символов.
Остановимся кратко на общих принципах построения систематических кодов. Если обозначить информационные символы буквами с, а контрольные — буквами е, то любую кодовую комбинацию, содержащую k информационных и r контрольных символов, можно представить последовательностью:![]() , где с и е в двоичном коде принимают значения 0 или 1.
, где с и е в двоичном коде принимают значения 0 или 1.
Процесс кодирования на передающем конце сводится к образованию контрольных символов, которые выражаются в виде линейной функции информационных символов:
![]()
![]() (7.9)
(7.9)
Здесь ![]() — коэффициенты, равные 0 или 1, а
— коэффициенты, равные 0 или 1, а ![]() и
и ![]() — знаки суммирования по модулю два. Значения
— знаки суммирования по модулю два. Значения ![]()
![]() выбираются по определенным правилам, установленным для данного вида кода. Иными словами, символы е представляют собой суммы по модулю два информационных символов в различных сочетаниях. Процедура декодирования принятых комбинаций может осуществляться различными» методами. Один из них, так называемый метод контрольных чисел, состоит в следующем. Из информационных символов принятой кодовой комбинации
выбираются по определенным правилам, установленным для данного вида кода. Иными словами, символы е представляют собой суммы по модулю два информационных символов в различных сочетаниях. Процедура декодирования принятых комбинаций может осуществляться различными» методами. Один из них, так называемый метод контрольных чисел, состоит в следующем. Из информационных символов принятой кодовой комбинации ![]()
![]()
![]() образуется по правилу (7.9) вторая группа контрольных символов
образуется по правилу (7.9) вторая группа контрольных символов ![]()
![]()
Затем производится сравнение обеих групп контрольных символов путем их суммирования по модулю два:
![]()
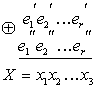 (7.10)
(7.10)
Полученное число X называется контрольным числом или синдромом. С его помощью можно обнаружить или исправить часть ошибок. Если ошибки в принятой комбинации отсутствуют, то все суммы![]()
![]() , а следовательно, и контрольное число X будут равны .нулю. При появлении ошибок некоторые значения х могут оказаться равным 1. В этом случае
, а следовательно, и контрольное число X будут равны .нулю. При появлении ошибок некоторые значения х могут оказаться равным 1. В этом случае ![]() , что и позволяет обнаружить ошибки. Таким образом, контрольное число Х определяется путем r проверок на четность.
, что и позволяет обнаружить ошибки. Таким образом, контрольное число Х определяется путем r проверок на четность.
Для исправления ошибок знание одного факта их возникновения является недостаточным. Необходимо указать номер ошибочно принятых символов. С этой целью каждому сочетанию исправляемых ошибок в комбинации присваивается одно из контрольных чисел, что позволяет по известному контрольному числу определить место положения ошибок и исправить их.
Контрольное число X записывается в двоичной системе, поэтому общее количество различных контрольных чисел, отличающихся от нуля, равно![]()
![]() . Очевидно, это количество должно быть не меньше числа различных сочетаний ошибочных символов, подлежащих исправлению. Например, если код предназначен для исправления одиночных ошибок, то число различных вариантов таких ошибок равно
. Очевидно, это количество должно быть не меньше числа различных сочетаний ошибочных символов, подлежащих исправлению. Например, если код предназначен для исправления одиночных ошибок, то число различных вариантов таких ошибок равно ![]() . В этом случае должно выполняться условие
. В этом случае должно выполняться условие
![]() (7.11)
(7.11)
Формула (7.11) позволяет при заданном количестве информационных символов k определить необходимое число контрольных символов r, с помощью которых исправляются все одиночные ошибки.
7.4. Код с чётным числом единиц. Инверсионный код
Рассмотрим некоторые простейшие систематические коды, применяемые только для обнаружения ошибок. Одним из кодов подобного типа является код с четным числом единиц. Каждая комбинация этого кода содержит, помимо информационных символов, один контрольный символ, выбираемый равным 0 или 1 так, чтобы сумма единиц в комбинации всегда была четной. Примером могут служить пятизначные комбинации кода Бодо, к которым добавляется шестой контрольный символ: 10101,1 и 01100,0. Правило вычисления контрольного символа можно выразить на
основании (7.9) в следующей форме: ![]() . Отсюда вытекает, что для любой комбинации сумма всех символов по модулю два будет равна нулю (
. Отсюда вытекает, что для любой комбинации сумма всех символов по модулю два будет равна нулю (![]() — суммирование по модулю):
— суммирование по модулю):
![]() (7.12)
(7.12)
Это позволяет в декодирующем устройстве сравнительно просто производить обнаружение ошибок путем проверки на четность. Нарушение четности имеет место при появлении однократных, трехкратных и в общем, случае ошибок нечетной кратности, что и дает возможность их обнаружить. Появление четных ошибок не изменяет четности суммы (7.12), поэтому такие ошибки не обнаруживаются. На основании ,(7.8) вероятность необнаруженной ошибки равна:
![]()
![]()
К достоинствам кода следует отнести простоту кодирующих и декодирующих устройств, а также малую .избыточность ![]() , однако последнее определяет и его основной недостаток — сравнительно низкую корректирующую способность.
, однако последнее определяет и его основной недостаток — сравнительно низкую корректирующую способность.
Значительно лучшими корректирующими способностями обладает инверсный код, который также применяется только для обнаружения ошибок. С принципом построения такого кода удобно ознакомиться на примере двух комбинаций: 11000, 11000 и 01101, 10010. В каждой комбинации символы до запятой являются информационными, а последующие — контрольными. Если количество единиц в информационных символах четное, т. е. сумма этих
символов
![]() (7.13)
(7.13)
равна нулю, то контрольные символы представляют собой простое повторение информационных. В противном случае, когда число единиц нечетное и сумма (7.13) равна 1, контрольные символы получаются из информационных посредством инвертирования, т. е. путем замены всех 0 на 1, а 1 на 0. Математическая форма записи образования контрольных символов имеет вид ![]() . При декодировании происходит сравнение принятых информационных и контрольных символов. Если сумма единиц в принятых информационных символах четная, т. е.
. При декодировании происходит сравнение принятых информационных и контрольных символов. Если сумма единиц в принятых информационных символах четная, т. е. ![]() , то соответствующие друг другу информационные и контрольные символы суммируются по модулю два. В противном случае, когда c‘
, то соответствующие друг другу информационные и контрольные символы суммируются по модулю два. В противном случае, когда c‘![]() =1, происходит такое же суммирование, но с инвертированными контрольными символами. Другими словами, в соответствии с (7.10) производится r проверок на четность:
=1, происходит такое же суммирование, но с инвертированными контрольными символами. Другими словами, в соответствии с (7.10) производится r проверок на четность: ![]() . Ошибка обнаруживается, если хотя бы одна проверка на четность дает 1.
. Ошибка обнаруживается, если хотя бы одна проверка на четность дает 1.
Анализ показывает, что при ![]() наименьшая кратность необнаруживаемой ошибки g=4. Причем не обнаруживаются только те ошибки четвертой кратности, которые искажают одинаковые номера информационных и контрольных символов. Например, если передана комбинация 10100, 10100, а принята 10111, 10111, то такая четырехкратная ошибка обнаружена не будет, так как здесь все значения
наименьшая кратность необнаруживаемой ошибки g=4. Причем не обнаруживаются только те ошибки четвертой кратности, которые искажают одинаковые номера информационных и контрольных символов. Например, если передана комбинация 10100, 10100, а принята 10111, 10111, то такая четырехкратная ошибка обнаружена не будет, так как здесь все значения ![]() равны 0. Вероятность необнаружения ошибок четвертой кратности определяется выражением
равны 0. Вероятность необнаружения ошибок четвертой кратности определяется выражением
![]()
Для g>4 вероятность необнаруженных ошибок еще меньше. Поэтому при достаточно малых вероятностях ошибочных символов ро можно полагать, что полная вероятность необнаруженных ошибок ![]()
Инверсный код обладает высокой обнаруживающей способностью, однако она достигается ценой сравнительно большой избыточности, которая, как нетрудно определить, составляет величину ![]() =0,5.
=0,5.
7.5. Коды Хэмминга
К этому типу кодов обычно относят систематические коды с расстоянием d=3, которые позволяют исправить все одиночные ошибки (7.3).
Рассмотрим построение семизначного кода Хэмминга, каждая комбинация которого содержит четыре информационных и триконтрольных символа. Такой код, условно обозначаемый (7.4), удовлетворяет неравенству (7.11) и имеет избыточность ![]()
Если информационные символы с занимают в комбинация первые четыре места, то последующие три контрольных символа образуются по общему правилу (7.9) как суммы:
![]() (7.14)
(7.14)
Декодирование осуществляется путем трех проверок на четность (7.10):
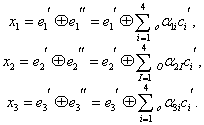 (7.15)
(7.15)
Так как х равно 0 или 1, то всего может быть восемь контрольных чисел Х=х1х2х3: 000, 100, 010, 001, 011, 101, 110 и 111. Первое из них имеет место в случае правильного приема, а остальные семь появляются при наличии искажений и должны использоваться для определения местоположения одиночной ошибки в семизначной комбинации. Выясним, каким образом устанавливается взаимосвязь между контрольными числами я искаженными символами. Если искажен один из контрольных символов: ![]() или
или ![]() , то, как следует из (7.15), контрольное число примет соответственно одно из трех значений: 100, 010 или 001. Остальные четыре контрольных числа используются для выявления ошибок в информационных символах.
, то, как следует из (7.15), контрольное число примет соответственно одно из трех значений: 100, 010 или 001. Остальные четыре контрольных числа используются для выявления ошибок в информационных символах.
Таблица 7.1

Порядок присвоения контрольных чисел ошибочным информационным символам может устанавливаться любой, например, как показано в табл. 7.1. Нетрудно показать, что этому распределению контрольных чисел соответствуют коэффициенты ![]() , приведенные в табл. 7.2.
, приведенные в табл. 7.2.
Таблица 7.2
Если подставить коэффициенты ![]() в выражение (7.15), то получим:
в выражение (7.15), то получим:
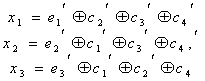 (7.16)
(7.16)
При искажении одного из информационных символов становятся равными единице те суммы х, в которые входит этот символ. Легко проверить, что получающееся в этом случае контрольное число![]() согласуется с табл. 7.1.Нетрудно заметить, что первые четыре контрольные числа табл. 7.1 совпадают со столбцами табл. 7.2. Это свойство дает возможность при выбранном распределении контрольных чисел составить таблицу коэффициентов
согласуется с табл. 7.1.Нетрудно заметить, что первые четыре контрольные числа табл. 7.1 совпадают со столбцами табл. 7.2. Это свойство дает возможность при выбранном распределении контрольных чисел составить таблицу коэффициентов ![]() . Таким образом, при одиночной ошибке можно вычислить контрольное число, позволяющее по табл. 7.1 определить тот символ кодовой комбинации, который претерпел искажения. Исправление искаженного символа двоичной системы состоит в простой замене 0 на 1 или 1 на 0. B качестве примера рассмотрим передачу комбинации, в которой информационными символами являются
. Таким образом, при одиночной ошибке можно вычислить контрольное число, позволяющее по табл. 7.1 определить тот символ кодовой комбинации, который претерпел искажения. Исправление искаженного символа двоичной системы состоит в простой замене 0 на 1 или 1 на 0. B качестве примера рассмотрим передачу комбинации, в которой информационными символами являются ![]() , Используя ф-лу (7.14) и табл. 7.2, вычислим контрольные символы:
, Используя ф-лу (7.14) и табл. 7.2, вычислим контрольные символы:
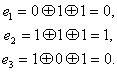
Передаваемая комбинация при этом будет ![]() . Предположим, что принята комбинация — 1001, 010 (искажен символ
. Предположим, что принята комбинация — 1001, 010 (искажен символ ![]() ). Подставляя соответствующие значения в (7.16), получим:
). Подставляя соответствующие значения в (7.16), получим:
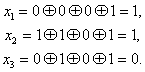
Вычисленное таким образом контрольное число ![]() 110 позволяет согласно табл. 7.1 исправить ошибку в символе.
110 позволяет согласно табл. 7.1 исправить ошибку в символе.
Здесь был рассмотрен простейший способ построения и декодирования кодовых комбинаций, в которых первые места отводились информационным символам, а соответствие между контрольными числами и ошибками определялось таблице. Вместе с тем существует более изящный метод отыскания одиночных ошибок, предложенный впервые самим Хэммингом. При этом методе код строится так, что контрольное число в двоичной системе счисления сразу указывает номер искаженного символа. Правда, в этом случае контрольные символы необходимо располагать среди информационных, что усложняет процесс кодирования. Для кода (7.4) символы в комбинации должны размещаться в следующем порядке: ![]() , а контрольное число вычисляться по формулам:
, а контрольное число вычисляться по формулам:
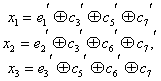 (7.17)
(7.17)
Так, если произошла ошибка в информационном символе с’5 то контрольное число ![]() , что соответствует числу 5 в двоичной системе.
, что соответствует числу 5 в двоичной системе.
В заключение отметим, что в коде (7.4) при появлении многократных ошибок контрольное число также может отличаться от нуля. Однако декодирование в этом случае будет проведено неправильно, так как оно рассчитано на исправление лишь одиночных ошибок.
7.6. Циклические коды
Важное место среди систематических кодов занимают циклические коды. Свойство цикличности состоит в том, что циклическая перестановка всех символов кодовой комбинации ![]() дает другую комбинацию
дает другую комбинацию ![]() также принадлежащую этому коду. При такой перестановке символы кодовой комбинации перемещаются слева направо на одну позицию, причем крайний правый символ переносится на место крайнего левого символа. Например,
также принадлежащую этому коду. При такой перестановке символы кодовой комбинации перемещаются слева направо на одну позицию, причем крайний правый символ переносится на место крайнего левого символа. Например, ![]()
![]()
![]()
![]() .
.
Комбинации циклического кода, выражаемые двоичными числами, для удобства преобразований обычно определяют в виде полиномов, коэффициенты которых равны 0 или 1. Примером этому может служить следующая запись:
![]()
Помимо цикличности, кодовые комбинации обладают другим важным свойством. Если их представить в виде полиномов, то все они делятся без остатка на так называемый порождающий полином G(z) степени ![]() , где k—значность первичного кода без избыточности, а п-значность циклического кода
, где k—значность первичного кода без избыточности, а п-значность циклического кода
Построение комбинаций циклических кодов возможно путем умножения комбинации первичного кода A*(z) ,на порождающий полином G(z):
A(z)=A*(z)G(z).
Умножение производится по модулю zn и в данном случае сводится к умножению по обычным правилам с приведением подобных членов по модулю два.
В полученной таким способом комбинации A(z) в явном виде не содержатся информационные символы, однако они всегда могут быть выделены в результате обратной операции: деления A(z) на G(z).
Другой способ кодирования, позволяющий представить кодовую комбинацию в виде информационных и контрольных символов, заключается в следующем. К комбинации первичного кода дописывается справа г нулей, что эквивалентно повышению полинома A*(z) на ,г разрядов, т. е. умножению его на гг. Затем произведение zrA*(z) делится на порождающий полином. B общем случае результат деления состоит из целого числа Q(z) и остатка R(z). Отсюда
![]()
Вычисленный остаток К(г) я используется для образования комбинации циклического кода в виде суммы
A(z)=zrA*(z)@R(z).
Так как сложение и вычитание по модулю два дают один и тот же результат, то нетрудно заметить, что A(z) = Q(z)G(z), т. е. полученная комбинация удовлетворяет требованию делимости на порождающий полином. Степень полинома R{z) не превышает r—1, поэтому он замещает нули в комбинации z![]() A*(z).
A*(z).
Для примера рассмотрим циклический код c n = 7, k=4, r=3 и G(z)=z3-z+1=1011. Необходимо закодировать комбинацию A*(z)=z*+1 = 1001. Тогда z![]() A*(z)=z
A*(z)=z![]() +z
+z![]() = 1001000. Для определения остатка делим z3A*(z) на G(z):
= 1001000. Для определения остатка делим z3A*(z) на G(z):
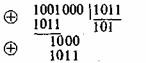
Окончательно получаем
В А(z) высшие четыре разряда занимают информационные символы, а остальные при — контрольные.
Контрольные символы в циклическом коде могут быть вычислены по общим ф-лам (7.9), однако здесь определение коэффициентов ![]() затрудняется необходимостью выполнять требования делимости А(z) на порождающий полином G(z).
затрудняется необходимостью выполнять требования делимости А(z) на порождающий полином G(z).
Процедура декодирования принятых комбинаций также основана на использовании полиномов G(z). Если ошибок в процессе передачи не было, то деление принятой комбинации A(z) на G(z) дает целое число. При наличии корректируемых ошибок в результате деления образуется остаток, который и позволяет обнаружить или исправить ошибки.
Кодирующие и декодирующие устройства циклических кодов в большинстве случаев обладают сравнительной простотой, что следует считать одним из основных их преимуществ. Другим важным достоинством этих кодов является их способность корректировать пачки ошибок, возникающие в реальных каналах, где действуют импульсные и сосредоточенные помехи или наблюдаются замирания сигнала.
В теории кодирования весом кодовых комбинаций принято называть .количество единиц, которое они содержат. Если все комбинации кода имеют одинаковый вес, то такой код называется кодом с постоянным весом. Коды с постоянным весом относятся к классу блочных неразделимых кодов, так как здесь не представляется возможным выделить информационные и контрольные символы. Из кодов этого типа наибольшее распространение получил обнаруживающий семизначный код 3/4, каждая разрешенная комбинация которого имеет три единицы и четыре нуля. Известен также код 2/5. Примером комбинаций кода 3/4 могут служить следующие семизначные последовательности: 1011000, 0101010, 0001110 и т. д.
Декодирование принятых комбинаций сводится к определению их веса. Если он отличается от заданного, то комбинация принята с ошибкой. Этот код обнаруживает все ошибки нечетной краткости и часть ошибок четной кратности. Не обнаруживаются только так называемые ошибки смещения, сохраняющие неизменным вес комбинации. Ошибки смещения характеризуются тем, что число искаженных единиц всегда равно числу искаженных нулей. Можно показать, что вероятность необнаруженной ошибки для кода 3/4 равна:
![]() при
при ![]() (7.18)
(7.18)
В этом коде из общего числа комбинаций М = 27=128 разрешенными являются лишь ![]() , поэтому в соответствии с (7.6) коэффициент избыточности
, поэтому в соответствии с (7.6) коэффициент избыточности
![]()
Код 3/4 находит применение при частотной манипуляции в каналах с селективными замираниями, где вероятность ошибок смещения невелика.
7.8. Непрерывные коды
Из непрерывных кодов, исправляющих ошибки, наиболее известны коды Финка—Хагельбаргера, в которых контрольные символы образуются путем линейной операции над двумя или более информационными символами. Принцип построения этих кодов рассмотрим на примере простейшего цепного кода. Контрольные символы в цепном коде формируются путем суммирования двух информационных символов, расположенных один относительно другого на определенном расстоянии:
![]() ;
;![]() (7.19)
(7.19)
Расстояние между информационными символами l=k—i определяет основные свойства кода и называется шагом сложения. Число контрольных символов при таком способе кодирования равно числу информационных символов, поэтому избыточность кода ![]() =0,5. Процесс образования последовательности контрольных символов показан на рис.7. символы разметаются между информационными символами с задержкой на два шага сложения.
=0,5. Процесс образования последовательности контрольных символов показан на рис.7. символы разметаются между информационными символами с задержкой на два шага сложения.
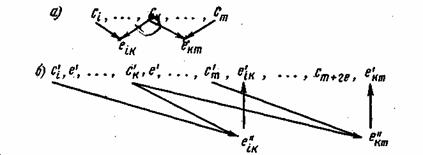
Рис. 7.3. Образование и размещение контрольных символов в цепном коде Финка—Хагельбаргера
При декодировании из принятых информационных символов по тому же правилу (7.19) формируется вспомогательная последовательность контрольных символов е», которая сравнивается с принятой последовательностью контрольных символов е’ (рис. 7.36). Если произошла ошибка в информационном символе, например, c‘k, то это вызовет искажения сразу двух символов e«k и e«km, что и обнаружится в результате их сравнения с ![]() и e‘km. Отсюда по общему индексу k легко определить и исправить ошибочно принятый информационный символ с’
и e‘km. Отсюда по общему индексу k легко определить и исправить ошибочно принятый информационный символ с’![]() Ошибка в принятом контрольном символе, например, e‘k приводит к несовпадению контрольных последовательностей лишь в одном месте. Исправление такой ошибки не требуется.
Ошибка в принятом контрольном символе, например, e‘k приводит к несовпадению контрольных последовательностей лишь в одном месте. Исправление такой ошибки не требуется.
Важное преимущество непрерывных кодов состоит в их способности исправлять не только одиночные ошибки, но я группы (пакеты) ошибок. Если задержка контрольных символов выбрана равной 2l, то можно показать, что максимальная длина исправляемого пакета ошибок также равна 2l при интервале между пакетами не менее 6l+1. Таким образом, возможность исправления длинных пакетов связана с увеличением шага сложения, а следовательно, и с усложнением кодирующих и декодирующих устройств.
Вопросы для повторения
1. Как могут быть классифицированы корректирующие коды?
2. Каким образом исправляются ошибки в кодах, которые только их обнаруживают?
3. В чем состоят основные принципы корректирования ошибок?
4. Дайте определение кодового расстояния.
5. При каких условиях код может обнаруживать или исправлять ошибки?
6. Как используется корректирующий код в системах со стиранием?
7. Какие характеристики определяют корректирующие способности кода?
8. Как осуществляется построение кодовых комбинаций в систематических кодах?
9. На чем основан принцип корректирования ошибок с использованием контрольного числа?
10. Объясните метод построения кода с четным числом единиц.
11. Как осуществляется процедура кодирования в семизначном коде Хэмминга?
12. Почему семизначный код 3/4 не обнаруживает ошибки смещения?
13. Каким образом производится непрерывное кодирование?
14. От чего зависит длина пакета исправляемых ошибок в коде Финка—Хагельбаргера?
|
|

Макеты страниц
Пусть задан некоторый блоковый код длины и, состоящий из  комбинаций (блоков, слов, векторов)
комбинаций (блоков, слов, векторов)  Для упрощения определений и доказательств будем всюду считать, что входной X и выходной У алфавиты канала совпадают. В общем случае канал может иметь память и задаваться вероятностями
Для упрощения определений и доказательств будем всюду считать, что входной X и выходной У алфавиты канала совпадают. В общем случае канал может иметь память и задаваться вероятностями  переходов входных блоков х в выходные у.
переходов входных блоков х в выходные у.
Определение 1. Расстоянием Хэмминга  между двумя комбинациями
между двумя комбинациями  будем называть число позиций этих комбинаций, в которых отдельные кодовые символы
будем называть число позиций этих комбинаций, в которых отдельные кодовые символы  не совпадают. Очевидно, что
не совпадают. Очевидно, что  для любых и что
для любых и что  для любых
для любых 
Определение 2. Образцом ошибки  будем называть двоичный блок длины
будем называть двоичный блок длины  который имеет единицы в тех позициях, в которых символы переданного х и принятого у блоков отличаются друг от друга, и нули — в остальных позициях.
который имеет единицы в тех позициях, в которых символы переданного х и принятого у блоков отличаются друг от друга, и нули — в остальных позициях.
Ранее в гл. 2 были сформулированы аксиомы, которым должно удовлетворять абстрактное определение понятия расстояния в функциональных пространствах сигналов. Покажем, что расстояние Хэмминга удовлетворяет этим аксиомам на пространстве  -ичных последовательностей произвольной длины
-ичных последовательностей произвольной длины  Первые требования:
Первые требования:  удовлетворяются очевидным образом. Остаётся проверить лишь справедливость «неравенства треугольника»:
удовлетворяются очевидным образом. Остаётся проверить лишь справедливость «неравенства треугольника»:

Предположим, что  отличаются друг от друга в позициях
отличаются друг от друга в позициях  где
где  в позициях
в позициях  где
где  Тогда легко убедиться, что х и у не могут различаться в каких-либо позициях, отличных от
Тогда легко убедиться, что х и у не могут различаться в каких-либо позициях, отличных от  а если
а если  то в этой позиции они могут и совпадать. Поэтому р(х,у)
то в этой позиции они могут и совпадать. Поэтому р(х,у)  что и эквивалентно неравенству (7.30).
что и эквивалентно неравенству (7.30).
Определение 3. Весом Хэмминга  блока (вектора) х (аналогично для
блока (вектора) х (аналогично для  ) будем называть число ненулевых символов этих блоков.
) будем называть число ненулевых символов этих блоков.
Определение 4. Кратностью образца ошибки  (или короче — кратностью ошибки) будем называть его вес Хэмминга
(или короче — кратностью ошибки) будем называть его вес Хэмминга  (По существу это число ошибок, которое произошло при передаче блока
(По существу это число ошибок, которое произошло при передаче блока 
Декодирование в заданном канале связи по максимуму правдоподобия — это принятие решения о передаче такого кодового блока  для которого условная вероятность
для которого условная вероятность  максимальна, где у — принятый блок. Это правило получения оценки можно записать в следующей компактной форме:
максимальна, где у — принятый блок. Это правило получения оценки можно записать в следующей компактной форме:

Как понятно из гл. 5, такое правило приводит к максимально возможной средней вероятности правильного приёма кодовых блоков при равновероятной посылке этих блоков по каналу связи. (Если последнее условие не выполняется то оптимальное декодирование должно соответствовать правилу максимальной апостериорной вероятности.)
Определение 5. Декодированием по минимуму расстояния Хэмминга будем называть следующее правило (алгоритм) принятия решения:

(По существу, правило (7.32) означает, что считается переданной та кодовая комбинация, которая отличается от принятой в наименьшем числе позиций.)
Покажем, что для  без памяти правила (7.31) и (7.32) совпадают, т.е. декодирование по минимуму расстояния Хэмминга совпадает с декодированием по максимуму правдоподобия. Действительно, в соответствии с определением
без памяти правила (7.31) и (7.32) совпадают, т.е. декодирование по минимуму расстояния Хэмминга совпадает с декодированием по максимуму правдоподобия. Действительно, в соответствии с определением  без памяти
без памяти

где  длина блоков
длина блоков  Легко убедиться, что (7.33) является монотонно убывающей функцией
Легко убедиться, что (7.33) является монотонно убывающей функцией  при
при  что и доказывает эквивалентность (7.31) и (7.32) для данного каната связи.
что и доказывает эквивалентность (7.31) и (7.32) для данного каната связи.
В случае использования произвольного канала связи, например несимметричного или с памятью, декодирование по минимуму расстояния Хэмминга не обязательно будет оптимальной процедурой, однако ввиду простаты (7.32) этот алгоритм часто используется и в данных случаях.
Если канал симметричен, но имеет память, то он может быть преобразован в  без памяти, а следовательно, для него окажется оптимальным хэмминговский алгоритм декодирования после следующего преобразования канала связи, который называют перемежением символов или декорреляциеи. Как показано на рис. 7.2, кодовые блоки, содержащие
без памяти, а следовательно, для него окажется оптимальным хэмминговский алгоритм декодирования после следующего преобразования канала связи, который называют перемежением символов или декорреляциеи. Как показано на рис. 7.2, кодовые блоки, содержащие  символов, номера которых отмечены верхними индексами
символов, номера которых отмечены верхними индексами  после их формирования предварительно заносятся в буферную память. После окончания формирования последнего
после их формирования предварительно заносятся в буферную память. После окончания формирования последнего  блока начинается передача символов этих блоков в канал связи «по столбцам» матрицы, находящейся в буферной памяти, т.е. последовательно передаются символы
блока начинается передача символов этих блоков в канал связи «по столбцам» матрицы, находящейся в буферной памяти, т.е. последовательно передаются символы  На приёме эти символы запоминаются в виде последовательных строк матрицы. После заполнения всех таких строк начинается декодирование по столбцам последовательных кодовых блоков с номерами (1), (2),
На приёме эти символы запоминаются в виде последовательных строк матрицы. После заполнения всех таких строк начинается декодирование по столбцам последовательных кодовых блоков с номерами (1), (2),  Видно, что каждая пара смежных символов в любом из кодовых блоков передаётся в канале связи с разнесением во времени
Видно, что каждая пара смежных символов в любом из кодовых блоков передаётся в канале связи с разнесением во времени  где
где  — длительность канального символа. Если параметр
— длительность канального символа. Если параметр  выбран достаточно большим, а зависимость между ошибками (память канала) убывает при разнесении передаваемых символов, то после такой процедуры можно практически полностью устранить память в канале связи.
выбран достаточно большим, а зависимость между ошибками (память канала) убывает при разнесении передаваемых символов, то после такой процедуры можно практически полностью устранить память в канале связи.

Рис. 7.2. Процедура перемещения символов
Определение 6. Минимальным кодовым расстоянием  для заданного кода V будем называть минимальное расстояние по Хэммингу между всеми парами его несовпадающих кодовых комбинаций, т.е.
для заданного кода V будем называть минимальное расстояние по Хэммингу между всеми парами его несовпадающих кодовых комбинаций, т.е.

Избыточный код V может использоваться в канале связи с помехами не только для декодирования (распознавания) действительно передававшихся сообщений,  фактически для исправления ошибок, но и для обнаружения ошибок. Естественным алгоритмом декодирования с обнаружением ошибок является принятие решения об отсутствии ошибок, когда принятая комбинация у совпадает с одной из разрешённых кодовых комбинациях, т.е.
фактически для исправления ошибок, но и для обнаружения ошибок. Естественным алгоритмом декодирования с обнаружением ошибок является принятие решения об отсутствии ошибок, когда принятая комбинация у совпадает с одной из разрешённых кодовых комбинациях, т.е.  и обнаружение ошибок, если для всех
и обнаружение ошибок, если для всех  Очевидно, что в этом случае возможны ошибки декодирования, а именно принятие решения об отсутствии ошибки, в то время как они в действительности имеют место. Будем называть это событие необнаруженной ошибкой, а его вероятность — вероятностью необнаруженной ошибки, обозначая её через
Очевидно, что в этом случае возможны ошибки декодирования, а именно принятие решения об отсутствии ошибки, в то время как они в действительности имеют место. Будем называть это событие необнаруженной ошибкой, а его вероятность — вероятностью необнаруженной ошибки, обозначая её через  или
или  для заданного кода
для заданного кода  При рассмотренном выше алгоритме обнаружения ошибок необнаруженная ошибка может появиться тогда, и только тогда, когда передаваемая по каналу связи кодовая комбинация под воздействием помех перейдёт на выходе в какую-либо другую кодовую (разрешённую) комбинацию. Поэтому при равновероятном выборе кодовых комбинаций
При рассмотренном выше алгоритме обнаружения ошибок необнаруженная ошибка может появиться тогда, и только тогда, когда передаваемая по каналу связи кодовая комбинация под воздействием помех перейдёт на выходе в какую-либо другую кодовую (разрешённую) комбинацию. Поэтому при равновероятном выборе кодовых комбинаций

Определение 7. Будем говорить, что код К гарантированно обнаруживает или исправляет ошибки кратности не больше  при использовании некоторого алгоритма обнаружения или исправления ошибок, если кодовые слова после применения этих алгоритмов не будут содержать необнаруженных или неисправленных ошибок, когда кратность ошибки в канале связи не превосходит 1. (Данный код может исправлять или обнаруживать ошибки и большей кратности, но это может иметь место не для всех образцов ошибок). Возможности кода обнаруживать ошибки определяются следующей теоремой.
при использовании некоторого алгоритма обнаружения или исправления ошибок, если кодовые слова после применения этих алгоритмов не будут содержать необнаруженных или неисправленных ошибок, когда кратность ошибки в канале связи не превосходит 1. (Данный код может исправлять или обнаруживать ошибки и большей кратности, но это может иметь место не для всех образцов ошибок). Возможности кода обнаруживать ошибки определяются следующей теоремой.
Теорема 7.3. Если код имеет минимальное расстояние  то он гарантированно обнаруживает ошибки кратности не более чем
то он гарантированно обнаруживает ошибки кратности не более чем 
Доказательство. Как было отмечено ранее, ошибка оказывается необнаруженной тогда, и только тогда, когда под воздействием помех в канале связи передававшаяся кодовая комбинация переходит в какую-либо другую кодовую комбинацию. Но для этого необходимо, чтобы образец ошибок имел кратность не меньше  поскольку все кодовые комбинации по определению понятия минимального кодового расстояния отличаются друг от друга не меньше, чем в
поскольку все кодовые комбинации по определению понятия минимального кодового расстояния отличаются друг от друга не меньше, чем в  позициях.
позициях.
Определение 8. Будем называть функцией кратности ошибки  в данном канале связи вероятность появления
в данном канале связи вероятность появления  ошибок на кодовом блоке длины
ошибок на кодовом блоке длины  . В частном случае
. В частном случае  без памяти
без памяти

Теорема 7.3 позволяет получить верхнюю границу для вероятности необнаруженной ошибки кодом V с минимальным расстоянием 

(Неравенство в (7.37) возникает потому, что код с минимальным расстоянием  может, вообще говоря, обнаруживать ошибки и кратности большей, чем
может, вообще говоря, обнаруживать ошибки и кратности большей, чем  Подставляя (7.36) в (7.37), получаем, что для
Подставляя (7.36) в (7.37), получаем, что для  (в частном случае
(в частном случае  без памяти
без памяти

Возможности кода по исправлению ошибок определяются следующей теоремой.
Теорема 7.4. Если код имеет минимальное расстояние  то при декодировании по минимуму расстояния Хэмминга он гарантированно исправляет ошибки кратности
то при декодировании по минимуму расстояния Хэмминга он гарантированно исправляет ошибки кратности  не более, чем
не более, чем  где
где  означает целую часть х.
означает целую часть х.
Доказательство. Пусть передавалось кодовое слово х, и принято слово у, причём по условию теоремы  Предположим, что существует кодовое слово
Предположим, что существует кодовое слово  которое находится от принятого слова у на расстоянии Хэмминга не большим, чем слово и, следовательно, может произойти ошибочное декодирование этого слова вместо слова
которое находится от принятого слова у на расстоянии Хэмминга не большим, чем слово и, следовательно, может произойти ошибочное декодирование этого слова вместо слова  Этот факт означает, что
Этот факт означает, что  Применяя неравенство треугольника (7.30) к словам
Применяя неравенство треугольника (7.30) к словам  получаем
получаем

С другой стороны, выполнение (7.39) невозможно, поскольку по определению  для данного кода
для данного кода  Следовательно, действительно передававшееся кодовое слово х, будет декодировано верно, и теорема доказана.
Следовательно, действительно передававшееся кодовое слово х, будет декодировано верно, и теорема доказана.
Теорема 7.4 позволяет построить верхнюю границу вероятности ошибочного декодирования при использовании алгоритма Хэмминга в произвольном канале связи:

В частном случае  без памяти получаем из (7.36) и (7.40)
без памяти получаем из (7.36) и (7.40)

Определение 9. Будем называть алгоритмом совместного исправления ошибок кратности до  и обнаружения ошибок при использовании кода V с минимальным расстоянием
и обнаружения ошибок при использовании кода V с минимальным расстоянием  алгоритм, который по принятому слову у декодирует кодовое слово
алгоритм, который по принятому слову у декодирует кодовое слово  если
если  и обнаруживает наличие ошибки, если
и обнаруживает наличие ошибки, если  для всех кодовых слов
для всех кодовых слов 
Свойства кода с заданными параметрами  по совместному исправлению и обнаружению ошибок определяются следующей теоремой.
по совместному исправлению и обнаружению ошибок определяются следующей теоремой.
Теорема 7.5. Если код имеет минимальное расстояние  то использование алгоритма совместного исправления ошибок кратности до
то использование алгоритма совместного исправления ошибок кратности до  включительно и обнаружения ошибок, обеспечивает гарантированное исправление ошибок кратности не больше
включительно и обнаружения ошибок, обеспечивает гарантированное исправление ошибок кратности не больше  и обнаруживает число ошибок кратности не более
и обнаруживает число ошибок кратности не более 
Доказательство утверждения о гарантированном исправлении ошибок очевидно, а доказательство утверждения о гарантированном обнаружении ошибок производится аналогично доказательству теорем 7.3 и 7.4.
Теорема 7.5 позволяет получить верхнюю границу для вероятности необнаруженной ошибки  и нижнюю границу для вероятности правильного декодирования
и нижнюю границу для вероятности правильного декодирования  при использовании кодов с данным алгоритмом совместного исправления и обнаружения ошибок
при использовании кодов с данным алгоритмом совместного исправления и обнаружения ошибок

(Подставляя (7.36) в эти неравенства, получаем соответствующие границы для частного случая канала  без памяти.)
без памяти.)
В некоторых случаях на выходе канала могут появляться дополнительные пометки о ненадёжности принятых символов, что приводит к их стиранию. Это может происходить из-за низкого отношения сигнал-шум, соответствующего данному тактовому интервалу.
В качестве признака отсутствия стирания символа на  тактовом интервале при оптимальном когерентном приёме противоположных сигналов
тактовом интервале при оптимальном когерентном приёме противоположных сигналов  на фоне белого шума можно использовать превышение некоторого порога абсолютным значением корреляционного интеграла
на фоне белого шума можно использовать превышение некоторого порога абсолютным значением корреляционного интеграла  где
где  принимаемый непрерывный сигнал,
принимаемый непрерывный сигнал,  длительность элемента сигнала (тактовый интервал, см. гл. 5).
длительность элемента сигнала (тактовый интервал, см. гл. 5).
Определение 10. Будем называть алгоритмом исправления стираний и ошибок такой метод декодирования, который измеряет расстояние Хэмминга между принятым блоком у и всеми кодовыми словами в нестёртых позициях и декодирует то кодовое слово, для которого это расстояние минимально
Исправляющая способность алгоритма совместного исправления стираний и ошибок определяется теоремой.
Теорема 7.6. Если код имеет минимальное расстояние  то он может одновременно исправить
то он может одновременно исправить  стираний и
стираний и  ошибок при выполнении следующего условия,
ошибок при выполнении следующего условия,

Доказательство производится совершенно аналогично доказательству теоремы 7.4 с учётом того очевидного факта, что код  с длиной блоков
с длиной блоков  образованный из комбинаций исходного кода V при вычеркивании
образованный из комбинаций исходного кода V при вычеркивании  стёртых позиций, имеет минимальное расстояние не менее, чем
стёртых позиций, имеет минимальное расстояние не менее, чем 
Зная совместные функции кратности ошибок и стираний в канале связи, можно рассчитать верхнюю границу для  используя (7.44).
используя (7.44).
Заметим, что алгоритм исправления ошибок и стираний является промежуточным вариантом между так называемым жёстким декодированием (в дискретном канале) и мягким декодированием (в полунепрерывном канале). Более подробно эта проблема обсуждается в п. 7.3.10.
Полученные границы для  показывают, что желательно иметь код с наибольшим возможным значением минимального расстояния
показывают, что желательно иметь код с наибольшим возможным значением минимального расстояния  Однако интуиция подсказывает нам, что мы можем добиться увеличения
Однако интуиция подсказывает нам, что мы можем добиться увеличения  при фиксированной длине блока
при фиксированной длине блока  только уменьшая скорость кода
только уменьшая скорость кода  Хотелось бы иметь точные формулы, определяющие
Хотелось бы иметь точные формулы, определяющие  как функцию
как функцию  или хотя бы верхние и нижние границы для этого параметра. Кроме того, для обеспечения
или хотя бы верхние и нижние границы для этого параметра. Кроме того, для обеспечения  что было обещано теоремой кодирования Шеннона, придется увеличивать и длины кодовых блоков
что было обещано теоремой кодирования Шеннона, придется увеличивать и длины кодовых блоков  но при этом количество комбинаций кода
но при этом количество комбинаций кода  экспоненциально возрастает. Это неизбежно вызовет большие трудности при реализации процедур кодирования и декодирования. (Действительно, при кодировании нужно запомнить
экспоненциально возрастает. Это неизбежно вызовет большие трудности при реализации процедур кодирования и декодирования. (Действительно, при кодировании нужно запомнить  комбинаций и извлекать из памяти каждый раз новую комбинацию, соответствующую поступившему сообщению, а при декодировании вычислить
комбинаций и извлекать из памяти каждый раз новую комбинацию, соответствующую поступившему сообщению, а при декодировании вычислить  хэмминговских расстояний и находить среди них минимальное.) Поэтому мы нуждаемся в более конструктивном (регулярном) задании кода, чем его описание таблицей кодовых комбинаций. Эту проблему удаётся решить при переходе к специальному классу так называемых линейных кодов, который описан в следующем разделе.
хэмминговских расстояний и находить среди них минимальное.) Поэтому мы нуждаемся в более конструктивном (регулярном) задании кода, чем его описание таблицей кодовых комбинаций. Эту проблему удаётся решить при переходе к специальному классу так называемых линейных кодов, который описан в следующем разделе.
Однако, прежде чем перейти к его рассмотрению, сделаем ещё одно замечание. Сравнение границ (7.37) и (7.40) показывает, что в любых каналах связи и для любых кодов  причём это неравенство справедливо не только для границ, но и для точных значений соответствующих вероятностей ошибок. Однако этот факт ещё не означает, что всегда целесообразно использовать обнаружение ошибок, а не их исправление. Действительно, после обнаружения ошибок в блоке он оказывается стёртым, а следовательно, не может быть выдан получателю. Обычно его доставка осуществляется при помощи повторной передачи, что требует затрат дополнительного времени.
причём это неравенство справедливо не только для границ, но и для точных значений соответствующих вероятностей ошибок. Однако этот факт ещё не означает, что всегда целесообразно использовать обнаружение ошибок, а не их исправление. Действительно, после обнаружения ошибок в блоке он оказывается стёртым, а следовательно, не может быть выдан получателю. Обычно его доставка осуществляется при помощи повторной передачи, что требует затрат дополнительного времени.
К вопросам получения более точных оценок для  и
и  а также к сравнению систем с обнаружением и исправлением ошибок мы ещё вернёмся в следующем разделе.
а также к сравнению систем с обнаружением и исправлением ошибок мы ещё вернёмся в следующем разделе.
Оглавление
- ПРЕДИСЛОВИЕ
- ГЛАВА 1. ОБЩИЕ СВЕДЕНИЯ О СИСТЕМАХ ЭЛЕКТРОСВЯЗИ
- 1.2. СИСТЕМЫ, КАНАЛЫ И СЕТИ СВЯЗИ
- 1.3. ПОМЕХИ И ИСКАЖЕНИЯ В КАНАЛЕ
- 1.4. КОДИРОВАНИЕ И МОДУЛЯЦИЯ
- 1.5. ДЕМОДУЛЯЦИЯ И ДЕКОДИРОВАНИЕ
- 1.6. ЦИФРОВОЕ КОДИРОВАНИЕ НЕПРЕРЫВНЫХ СООБЩЕНИЙ
- 1.7. ОСНОВНЫЕ ХАРАКТЕРИСТИКИ СИСТЕМЫ СВЯЗИ
- ГЛАВА 2. МАТЕМАТИЧЕСКИЕ МОДЕЛИ СООБЩЕНИЙ, СИГНАЛОВ И ПОМЕХ
- 2.1. КЛАССИФИКАЦИЯ СООБЩЕНИЙ, СИГНАЛОВ И ПОМЕХ
- 2.2. ФУНКЦИОНАЛЬНЫЕ ПРОСТРАНСТВА И ИХ БАЗИСЫ
- 2.3. РАЗЛОЖЕНИЕ СИГНАЛОВ В ОБОБЩЁННЫЙ РЯД ФУРЬЕ
- Спектральное представление периодических колебаний.
- Спектральное представление непериодических функций.
- 2.4. ДИСКРЕТИЗАЦИЯ СИГНАЛОВ ВО ВРЕМЕНИ
- Спектральная трактовка дискретизации.
- Теорема отсчётов.
- Восстановление непрерывной функции по отсчётам.
- 2.5. СЛУЧАЙНЫЕ ПРОЦЕССЫ И ИХ ОСНОВНЫЕ ХАРАКТЕРИСТИКИ
- Плотность вероятности и интегральная функция распределения (ИФР).
- Числовые характеристики.
- Нормальное (гауссовское) распределение.
- Равномерное распределение.
- Распределение вероятностей мгновенных значений гармонического колебания.
- Распределения вероятностей дискретных случайных величин
- Распределение Пуассона.
- Стационарные случайные процессы.
- Эргодические процессы.
- Спектральная плотность мощности случайного процесса.
- Функция корреляции случайного процесса с ограниченным спектром.
- 2.6. ПРЕДСТАВЛЕНИЕ СЛУЧАЙНЫХ ПРОЦЕССОВ РЯДАМИ И ДИФФЕРЕНЦИАЛЬНЫМИ УРАВНЕНИЯМИ
- Разложение по гармоническим функциям.
- Разложение в ряд Котельникова.
- Случайные процессы, определяемые двумерной плотностью вероятности.
- Представление случайных процессов дифференциальными уравнениями.
- 2.7. ОГИБАЮЩАЯ И ФАЗА СИГНАЛА. АНАЛИТИЧЕСКИЙ СИГНАЛ. КВАДРАТУРНЫЕ КОМПОНЕНТЫ УЗКОПОЛОСНОГО СИГНАЛА
- Корреляционная функция узкополосного случайного процесса.
- 2.8. НЕКОТОРЫЕ МОДЕЛИ НЕПРЕРЫВНЫХ И ДИСКРЕТНЫХ ИСТОЧНИКОВ (СООБЩЕНИЙ, СИГНАЛОВ И ПОМЕХ)
- Некоторые модели источников (сообщений, сигналов, помех).
- Модели речевого сообщения.
- Модель стохастического дискретного источника.
- ВЫВОДЫ
- ГЛАВА 3. ОСНОВЫ ТЕОРИИ МОДУЛЯЦИИ И ДЕТЕКТИРОВАНИЯ
- 3.1. ПРЕОБРАЗОВАНИЕ КОЛЕБАНИЙ В ПАРАМЕТРИЧЕСКИХ И НЕЛИНЕЙНЫХ ЦЕПЯХ
- 3.2. ФОРМИРОВАНИЕ И ДЕТЕКТИРОВАНИЕ СИГНАЛОВ АМПЛИТУДНОЙ МОДУЛЯЦИИ
- 3.3. ФОРМИРОВАНИЕ И ДЕТЕКТИРОВАНИЕ СИГНАЛОВ УГЛОВОЙ МОДУЛЯЦИИ
- 3.4. ФОРМИРОВАНИЕ И ДЕТЕКТИРОВАНИЕ СИГНАЛОВ ОДНОПОЛОСНОЙ МОДУЛЯЦИИ
- 3.5. ФОРМИРОВАНИЕ И ДЕТЕКТИРОВАНИЕ СИГНАЛОВ, МОДУЛИРОВАННЫХ ДИСКРЕТНЫМИ СООБЩЕНИЯМИ
- Цифровая амплитудная модуляция (ЦАМ).
- Цифровая фазовая модуляция (ЦФМ).
- Цифровая частотная модуляция (ЦЧМ).
- 3.6. МОДУЛЯЦИЯ И ДЕТЕКТИРОВАНИЕ ПРИ ИМПУЛЬСНОМ ПЕРЕНОСЧИКЕ
- 3.7. ФУНКЦИЯ КОРРЕЛЯЦИИ И СПЕКТРАЛЬНАЯ ПЛОТНОСТЬ МОЩНОСТИ МОДУЛИРОВАННЫХ СИГНАЛОВ ПРИ МОДУЛЯЦИИ СЛУЧАЙНЫМ ПРОЦЕССОМ
- 3.8. ПОМЕХОУСТОЙЧИВОСТЬ АМПЛИТУДНОЙ И УГЛОВОЙ МОДУЛЯЦИИ
- ВЫВОДЫ
- ГЛАВА 4. МАТЕМАТИЧЕСКИЕ МОДЕЛИ КАНАЛОВ СВЯЗИ. ПРЕОБРАЗОВАНИЕ СИГНАЛОВ В КАНАЛАХ СВЯЗИ
- 4.2. ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ МОДЕЛИ КАНАЛОВ СВЯЗИ
- 4.3. ПРЕОБРАЗОВАНИЯ СИГНАЛОВ В ЛИНЕЙНЫХ И НЕЛИНЕЙНЫХ КАНАЛАХ
- 4.3.2. ПРЕОБРАЗОВАНИЕ УЗКОПОЛОСНЫХ СИГНАЛОВ В УЗКОПОЛОСНЫХ ЛИНЕЙНЫХ СТАЦИОНАРНЫХ КАНАЛАХ
- 4.3.3. ПРЕОБРАЗОВАНИЯ ЭНЕРГЕТИЧЕСКИХ ХАРАКТЕРИСТИК ДЕТЕРМИНИРОВАННЫХ СИГНАЛОВ
- 4.3.4. ПРЕОБРАЗОВАНИЕ СЛУЧАЙНЫХ СИГНАЛОВ В ДЕТЕРМИНИРОВАННЫХ ЛИНЕЙНЫХ КАНАЛАХ
- 4.3.5. ПРЕОБРАЗОВАНИЕ СЛУЧАЙНЫХ СИГНАЛОВ В ДЕТЕРМИНИРОВАННЫХ НЕЛИНЕЙНЫХ КАНАЛАХ
- 4.3.6. ПРОХОЖДЕНИЕ СИГНАЛОВ ЧЕРЕЗ СЛУЧАЙНЫЕ КАНАЛЫ СВЯЗИ
- 4.3.7. АДДИТИВНЫЕ ПОМЕХИ В КАНАЛЕ
- 4.3.8. КВАНТОВЫЙ ШУМ
- 4.4. МОДЕЛИ НЕПРЕРЫВНЫХ КАНАЛОВ СВЯЗИ
- 4.4.2. КАНАЛ С АДДИТИВНЫМ ГАУССОВСКИМ ШУМОМ
- 4.4.3. КАНАЛ С НЕОПРЕДЕЛЁННОЙ ФАЗОЙ СИГНАЛА И АДДИТИВНЫМ ШУМОМ
- 4.4.4. КАНАЛ С МЕЖСИМВОЛЬНОЙ ИНТЕРФЕРЕНЦИЕЙ (МСИ) И АДДИТИВНЫМ ШУМОМ
- 4.5. МОДЕЛИ ДИСКРЕТНЫХ КАНАЛОВ СВЯЗИ
- 4.5.1. НЕКОТОРЫЕ МОДЕЛИ ДИСКРЕТНЫХ КАНАЛОВ С ПАМЯТЬЮ
- 4.5.2. МОДЕЛЬ ДИСКРЕТНО-НЕПРЕРЫВНОГО КАНАЛА
- 4.6. МОДЕЛИ НЕПРЕРЫВНЫХ КАНАЛОВ СВЯЗИ, ЗАДАННЫЕ ДИФФЕРЕНЦИАЛЬНЫМИ УРАВНЕНИМИ
- ВЫВОДЫ
- ГЛАВА 5. ТЕОРИЯ ПОМЕХОУСТОЙЧИВОСТИ СИСТЕМ ПЕРЕДАЧИ ДИСКРЕТНЫХ СООБЩЕНИЙ
- 5.2. КРИТЕРИИ КАЧЕСТВА И ПРАВИЛА ПРИЁМА ДИСКРЕТНЫХ СООБЩЕНИЙ
- 5.3. ОПТИМАЛЬНЫЕ АЛГОРИТМЫ ПРИЁМА ПРИ ПОЛНОСТЬЮ ИЗВЕСТНЫХ СИГНАЛАХ (КОГЕРЕНТНЫЙ ПРИЁМ)
- 5.4. ОПТИМАЛЬНЫЙ ПРИЁМНИК С СОГЛАСОВАННЫМ ФИЛЬТРОМ
- 5.5. ПОМЕХОУСТОЙЧИВОСТЬ ОПТИМАЛЬНОГО КОГЕРЕНТНОГО ПРИЁМА
- 5.6. ОБРАБОТКА СИГНАЛОВ В КАНАЛАХ С МЕЖСИМВОЛЬНОЙ ИНТЕРФЕРЕНЦИЕЙ
- 5.7. ПРИЁМ СИГНАЛОВ С НЕОПРЕДЕЛЁННОЙ ФАЗОЙ (НЕКОГЕРЕНТНЫЙ ПРИЁМ)
- 5.8. ПРИЁМ ДИСКРЕТНЫХ СООБЩЕНИЙ В УСЛОВИЯХ ФЛУКТУАЦИИ ФАЗ И АМПЛИТУД СИГНАЛОВ
- 5.9. ПРИЁМ ДИСКРЕТНЫХ СООБЩЕНИЙ В КАНАЛАХ С СОСРЕДОТОЧЕННЫМИ ПО СПЕКТРУ И ИМПУЛЬСНЫМИ ПОМЕХАМИ
- 5.10. ПОМЕХОУСТОЙЧИВОСТЬ ПРИЁМА ДИСКРЕТНЫХ СООБЩЕНИЙ В ОПТИЧЕСКОМ ДИАПАЗОНЕ ВОЛН
- 5.11. СРАВНЕНИЕ ПОМЕХОУСТОЙЧИВОСТИ СИСТЕМ ПЕРЕДАЧИ ДИСКРЕТНЫХ СООБЩЕНИЙ
- ВЫВОДЫ
- ГЛАВА 6. ПОТЕНЦИАЛЬНЫЕ ВОЗМОЖНОСТИ ПЕРЕДАЧИ СООБЩЕНИЙ ПО КАНАЛАМ СВЯЗИ (ОСНОВЫ ТЕОРИИ ИНФОРМАЦИИ)
- 6.1. ПРОБЛЕМА ОБЕСПЕЧЕНИЯ СКОЛЬ УГОДНО ВЫСОКОЙ ВЕРНОСТИ ПЕРЕДАЧИ ДИСКРЕТНЫХ СООБЩЕНИЙ В КАНАЛАХ С ПОМЕХАМИ
- 6.2. ПОТЕНЦИАЛЬНЫЕ ВОЗМОЖНОСТИ ДИСКРЕТНЫХ КАНАЛОВ СВЯЗИ
- 6.2.2. ОСНОВНОЙ ПОНЯТИЙНЫЙ АППАРАТ ТЕОРИИ ИНФОРМАЦИИ
- Энтропия источника сообщений.
- Количество информации, передаваемой по каналу связи (взаимная информация).
- 6.2.3. ТЕОРЕМЫ КОДИРОВАНИЯ ШЕННОНА ДЛЯ ДИСКРЕТНОГО КАНАЛА СВЯЗИ
- Теорема о свойстве асимптотической равновероятности (САР).
- Теорема кодирования в дискретном канале с помехами.
- 6.3. ПОТЕНЦИАЛЬНЫЕ ВОЗМОЖНОСТИ НЕПРЕРЫВНЫХ КАНАЛОВ СВЯЗИ ПРИ ПЕРЕДАЧЕ ДИСКРЕТНЫХ СООБЩЕНИЙ
- 6.3.2. КОЛИЧЕСТВО ИНФОРМАЦИИ, ПЕРЕДАВАЕМОЙ ПО НЕПРЕРЫВНОМУ КАНАЛУ СВЯЗИ, РАСЧЁТ ЕГО ПРОПУСКНОЙ СПОСОБНОСТИ
- 6.3.3. ТЕОРЕМА КОДИРОВАНИЯ ДЛЯ НЕПРЕРЫВНОГО КАНАЛА СВЯЗИ
- 6.3.4. ПОТЕНЦИАЛЬНЫЕ ВОЗМОЖНОСТИ КАНАЛОВ СО МНОГИМИ ПОЛЬЗОВАТЕЛЯМИ
- ВЫВОДЫ
- ГЛАВА 7. КОДИРОВАНИЕ ИСТОЧНИКОВ И КАНАЛОВ СВЯЗИ
- 7.2. КОНСТРУКТИВНЫЕ МЕТОДЫ КОДИРОВАНИЯ ИСТОЧНИКОВ СООБЩЕНИЙ
- 7.3. ПОМЕХОУСТОЙЧИВОЕ (КАНАЛЬНОЕ) КОДИРОВАНИЕ
- 7.3.1. ВЕРОЯТНОСТЬ ОШИБКИ ОПТИМАЛЬНОГО ДЕКОДИРОВАНИЯ ДЛЯ КОДОВ С ФИКСИРОВАННОЙ ДЛИНОЙ БЛОКОВ (ЭКСПОНЕНТЫ ВЕРОЯТНОСТЕЙ ОШИБОК)
- 7.3.2. КОДЫ С ГАРАНТИРОВАННЫМ ОБНАРУЖЕНИЕМ И ИСПРАВЛЕНИЕМ ОШИБОК
- 7.3.3. ЛИНЕЙНЫЕ ДВОИЧНЫЕ КОДЫ ДЛЯ ОБНАРУЖЕНИЯ И ИСПРАВЛЕНИЯ ОШИБОК
- 7.3.4. ВАЖНЫЕ ПОДКЛАССЫ ЛИНЕЙНЫХ ДВОИЧНЫХ КОДОВ
- 7.3.5. КОНСТРУКТИВНЫЕ АЛГОРИТМЫ ИСПРАВЛЕНИЯ ОШИБОК ЛИНЕЙНЫМИ КОДАМИ
- 7.3.6. ОБОБЩЕНИЕ ТЕОРИИ КОДИРОВАНИЯ НА НЕДВОИЧНЫЕ КОДЫ
- 7.3.7 ИТЕРАТИВНЫЕ И КАСКАДНЫЕ КОДЫ
- 7.3.8. КОДИРОВАНИЕ В КАНАЛАХ С ПАМЯТЬЮ
- 7.3.9. СИСТЕМЫ С ОБРАТНОЙ СВЯЗЬЮ
- 7.3.10. ЗАКЛЮЧЕНИЕ ПО § 7.3. ОБЪЕДИНЕНИЕ ОПЕРАЦИЙ ДЕМОДУЛЯЦИИ И ДЕКОДИРОВАНИЯ. ДЕКОДИРОВАНИЕ С МЯГКИМ РЕШЕНИЕМ
- 7.4. СВЕРТОЧНЫЕ (РЕШЕТЧАТЫЕ) КОДЫ
- ВЫВОДЫ
- ГЛАВА 8. ТЕОРИЯ ПОМЕХОУСТОЙЧИВОСТИ ПЕРЕДАЧИ НЕПРЕРЫВНЫХ СООБЩЕНИЙ
- 8.1. КРИТЕРИИ ПОМЕХОУСТОЙЧИВОСТИ ПРИЁМА НЕПРЕРЫВНЫХ СООБЩЕНИЙ
- 8.2. ОПТИМАЛЬНАЯ ОЦЕНКА ОТДЕЛЬНЫХ ПАРАМЕТРОВ СИГНАЛА
- 8.3. ОПТИМАЛЬНАЯ ДЕМОДУЛЯЦИЯ НЕПРЕРЫВНЫХ СИГНАЛОВ
- 8.4. ПОМЕХОУСТОЙЧИВОСТЬ СИСТЕМ ПЕРЕДАЧИ НЕПРЕРЫВНЫХ СООБЩЕНИЙ ПРИ СЛАБЫХ ПОМЕХАХ
- 8.5. ПОРОГ ПОМЕХОУСТОЙЧИВОСТИ. АНОМАЛЬНЫЕ ОШИБКИ
- 8.6. ОПТИМАЛЬНАЯ ЛИНЕЙНАЯ ФИЛЬТРАЦИЯ НЕПРЕРЫВНЫХ СИГНАЛОВ. ФИЛЬТР КОЛМОГОРОВА-ВИНЕРА
- 8.7. ОПТИМАЛЬНАЯ ЛИНЕЙНАЯ ФИЛЬТРАЦИЯ НЕПРЕРЫВНЫХ СООБЩЕНИЙ. ФИЛЬТР КАЛМАНА
- 8.8. ТЕОРИЯ НЕЛИНЕЙНОЙ ФИЛЬТРАЦИИ
- 8.9. ОБЩИЕ СВЕДЕНИЯ О ЦИФРОВОЙ ПЕРЕДАЧЕ НЕПРЕРЫВНЫХ СООБЩЕНИЙ
- 8.10. ПОМЕХОУСТОЙЧИВОСТЬ ИМПУЛЬСНО-КОДОВОЙ МОДУЛЯЦИИ
- 8.11. КОДИРОВАНИЕ С ПРЕДСКАЗАНИЕМ
- ВЫВОДЫ
- ГЛАВА 9. ПРИНЦИПЫ МНОГОКАНАЛЬНОЙ СВЯЗИ И РАСПРЕДЕЛЕНИЯ ИНФОРМАЦИИ
- Основные положения линейной теории разделения сигналов.
- Условие линейного разделения сигналов.
- 9.2. ЧАСТОТНОЕ, ВРЕМЕННОЕ И ФАЗОВОЕ РАЗДЕЛЕНИЕ СИГНАЛОВ
- Временной способ разделения каналов.
- Разделение сигналов по фазе.
- 9.3. РАЗДЕЛЕНИЕ СИГНАЛОВ ПО ФОРМЕ. СИСТЕМЫ ПЕРЕДАЧИ С ШУМОПОДОБНЫМИ СИГНАЛАМИ
- Системы передачи с шумоподобными сигналами (ШПС).
- Примеры шумоподобных сигналов.
- 9.4. КОМБИНАЦИОННОЕ РАЗДЕЛЕНИЕ СИГНАЛОВ
- 9.5. ПРОПУСКНАЯ СПОСОБНОСТЬ СИСТЕМ МНОГОКАНАЛЬНОЙ СВЯЗИ
- Влияние взаимных помех при разделении сигналов на пропускную способность многоканальных систем.
- 9.6. ПРИНЦИПЫ ПОСТРОЕНИЯ СЕТЕЙ СВЯЗИ
- 9.6.1. СЕТЬ РАСПРЕДЕЛЕНИЯ ИНФОРМАЦИИ И ЕЁ ЭЛЕМЕНТЫ
- 9.6.2. МЕТОДЫ КОММУТАЦИИ В СЕТЯХ СВЯЗИ
- 9.6.3. МНОГОУРОВНЕВАЯ АРХИТЕКТУРА СВЯЗИ И ПРОТОКОЛЫ
- 9.6.4. ПЕРСПЕКТИВЫ РАЗВИТИЯ СЕТЕЙ СВЯЗИ
- ВЫВОДЫ
- ГЛАВА 10. ОСНОВЫ ЦИФРОВОЙ ОБРАБОТКИ СИГНАЛОВ
- 10.1. СПЕКТР ДИСКРЕТНОГО СИГНАЛА
- 10.2. АЛГОРИТМ БЫСТРОГО ПРЕОБРАЗОВАНИЯ ФУРЬЕ
- 10.3. ВРЕМЕННЫЕ И СПЕКТРАЛЬНЫЕ МЕТОДЫ ИССЛЕДОВАНИЯ ЛИНЕЙНЫХ СТАЦИОНАРНЫХ ЦИФРОВЫХ ФИЛЬТРОВ
- 10.4. ИСПОЛЬЗОВАНИЕ z-ПРЕОБРАЗОВАНИЯ В ТЕОРИИ СТАЦИОНАРНЫХ ЛИНЕЙНЫХ ЦИФРОВЫХ ФИЛЬТРОВ
- 10.5. ОСНОВЫ РЕАЛИЗАЦИИ ЦИФРОВЫХ ФИЛЬТРОВ
- 10.6. УЧЁТ ПОГРЕШНОСТИ ЦИФРОВОЙ ФИЛЬТРАЦИИ ИЗ-ЗА КВАНТОВАНИЯ СИГНАЛОВ ПО УРОВНЯМ
- ВЫВОДЫ
- ГЛАВА 11. АНАЛИЗ ЭФФЕКТИВНОСТИ И ОПТИМИЗАЦИЯ СИСТЕМ СВЯЗИ
- 11.2. ХАРАКТЕРИСТИКИ И ПОКАЗАТЕЛИ ЭФФЕКТИВНОСТИ СИСТЕМ ПЕРЕДАЧИ ИНФОРМАЦИИ
- Эффективность систем передачи дискретных сообщений.
- Эффективность аналоговых систем передачи и отдельных разновидностей систем разделения сигналов.
- 11.3. ВЫБОР СИГНАЛОВ И ПОМЕХОУСТОЙЧИВЫХ КОДОВ
- Корректирующие коды.
- Сигнально-кодовые конструкции (СКК).
- 11.4. КОМПЕНСАЦИЯ ПОМЕХ И ИСКАЖЕНИЙ В КАНАЛЕ
- 11.5. СОКРАЩЕНИЕ ИЗБЫТОЧНОСТИ. СЖАТИЕ ДАННЫХ
- 11.6. ОПТИМИЗАЦИЯ СИСТЕМ СВЯЗИ
- ВЫВОДЫ
- ЗАКЛЮЧЕНИЕ
- СПИСОК ЛИТЕРАТУРЫ