What is the value you’re passing to the primary key (presumably «pk_OrderID»)? You can set it up to auto increment, and then there should never be a problem with duplicating the value — the DB will take care of that. If you need to specify a value yourself, you’ll need to write code to determine what the max value for that field is, and then increment that.
If you have a column named «ID» or such that is not shown in the query, that’s fine as long as it is set up to autoincrement — but it’s probably not, or you shouldn’t get that err msg. Also, you would be better off writing an easier-on-the-eye query and using params. As the lad of nine years hence inferred, you’re leaving your database open to SQL injection attacks if you simply plop in user-entered values. For example, you could have a method like this:
internal static int GetItemIDForUnitAndItemCode(string qry, string unit, string itemCode)
{
int itemId;
using (SqlConnection sqlConn = new SqlConnection(ReportRunnerConstsAndUtils.CPSConnStr))
{
using (SqlCommand cmd = new SqlCommand(qry, sqlConn))
{
cmd.CommandType = CommandType.Text;
cmd.Parameters.Add("@Unit", SqlDbType.VarChar, 25).Value = unit;
cmd.Parameters.Add("@ItemCode", SqlDbType.VarChar, 25).Value = itemCode;
sqlConn.Open();
itemId = Convert.ToInt32(cmd.ExecuteScalar());
}
}
return itemId;
}
…that is called like so:
int itemId = SQLDBHelper.GetItemIDForUnitAndItemCode(GetItemIDForUnitAndItemCodeQuery, _unit, itemCode);
You don’t have to, but I store the query separately:
public static readonly String GetItemIDForUnitAndItemCodeQuery = "SELECT PoisonToe FROM Platypi WHERE Unit = @Unit AND ItemCode = @ItemCode";
You can verify that you’re not about to insert an already-existing value by (pseudocode):
bool alreadyExists = IDAlreadyExists(query, value) > 0;
The query is something like «SELECT COUNT FROM TABLE WHERE BLA = @CANDIDATEIDVAL» and the value is the ID you’re potentially about to insert:
if (alreadyExists) // keep inc'ing and checking until false, then use that id value
Justin wants to know if this will work:
string exists = "SELECT 1 from AC_Shipping_Addresses where pk_OrderID = " _Order.OrderNumber; if (exists > 0)...
What seems would work to me is:
string existsQuery = string.format("SELECT 1 from AC_Shipping_Addresses where pk_OrderID = {0}", _Order.OrderNumber);
// Or, better yet:
string existsQuery = "SELECT COUNT(*) from AC_Shipping_Addresses where pk_OrderID = @OrderNumber";
// Now run that query after applying a value to the OrderNumber query param (use code similar to that above); then, if the result is > 0, there is such a record.
- Remove From My Forums
-
Question
-
Dear All,
I’m trying to insert records from multiple tables into a new table but I get the following error message: Violation of PRIMARY KEY constraint ‘table name’. Cannot insert duplicate key in object. Would any please let me know what I should do to resolve the
error.Thank you in advance!
Answers
-
You can’t not insert duplicate keys, as the error message already says.
Without knowing your table design and the data you want to insert and those data already are in the table, it’s inpossible to suggest a solution for it.
Olaf Helper
* cogito ergo sum * errare humanum est * quote erat demonstrandum *
Wenn ich denke, ist das ein Fehler und das beweise ich täglich
Blog
Xing-
Proposed as answer by
Friday, May 18, 2012 11:05 AM
-
Marked as answer by
Iric Wen
Monday, May 28, 2012 1:37 AM
-
Proposed as answer by
-
Hi, the error message is pretty clear.. Your table has a primary key (that uniquely identifies each record) that can’t have duplicates. What you would like to do to «resolve» this? Find out which records are causing this? Remove the primary key?
David.
-
Marked as answer by
Iric Wen
Monday, May 28, 2012 1:37 AM
-
Marked as answer by
-
Apparently you query is generating duplicates. This may be bcause there is an error in your SELECT. It would be trivial error like
A JOIN B ON a.col = a.col
(Don’t laugh. I do that every once in a while.)
It could also be a deeper misunderstanding of the table relations.
To find the duplicate keys you can wrap your original SELECT in a CTE like this:
WITH CTE AS (
SELECT …,
row_number() OVER(PARTITION BY keycol1, keycol2, …
ORDER BY (SELECT 1)) AS rowno
FROM …
)
SELECT * FROM CTE
WHERE rowno >= 2keycol1 etc should be the columns in the result set that maps to the key columns in the target table.
Erland Sommarskog, SQL Server MVP, esquel@sommarskog.se
-
Proposed as answer by
Iric Wen
Tuesday, May 22, 2012 7:40 AM -
Marked as answer by
Iric Wen
Monday, May 28, 2012 1:37 AM
-
Proposed as answer by
We have encountered this strange error three times over the past few days, after being error free for 8 weeks, and I’m stumped.
This is the error message:
Executing the query "EXEC dbo.MergeTransactions" failed with the following error: "Cannot insert duplicate key row in object 'sales.Transactions' with unique index 'NCI_Transactions_ClientID_TransactionDate'. The duplicate key value is (1001, 2018-12-14 19:16:29.00, 304050920).".
The index we have is not unique. If you notice, the duplicate key value in the error message doesn’t even line up with the index. Strange thing is if I rerun the proc, it succeeds.
This is the most recent link I could find that has my issues but I don’t see a solution.
Error: Cannot insert duplicate key row in… a non-unique index?!
A couple things about my scenario:
- The proc is updating the TransactionID (part of the primary key) — I think this is what is causing the error but don’t know why? We’ll be removing that logic.
- Change tracking is enabled on the table
- Doing transaction read uncommitted
There are 45 fields for each table, I mainly listed the ones used in indexes. I’m updating the TransactionID (clustered key) in the update statement (unnecessarily). Strange that we haven’t had any issues for months until last week. And it’s only happening sporadically via SSIS.
Table
USE [DB]
GO
/****** Object: Table [sales].[Transactions] Script Date: 5/29/2019 1:37:49 PM ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[sales].[Transactions]') AND type in (N'U'))
BEGIN
CREATE TABLE [sales].[Transactions]
(
[TransactionID] [bigint] NOT NULL,
[ClientID] [int] NOT NULL,
[TransactionDate] [datetime2](2) NOT NULL,
/* snip*/
[BusinessUserID] [varchar](150) NOT NULL,
[BusinessTransactionID] [varchar](150) NOT NULL,
[InsertDate] [datetime2](2) NOT NULL,
[UpdateDate] [datetime2](2) NOT NULL,
CONSTRAINT [PK_Transactions_TransactionID] PRIMARY KEY CLUSTERED
(
[TransactionID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, DATA_COMPRESSION=PAGE) ON [DB_Data]
) ON [DB_Data]
END
GO
USE [DB]
IF NOT EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[sales].[Transactions]') AND name = N'NCI_Transactions_ClientID_TransactionDate')
begin
CREATE NONCLUSTERED INDEX [NCI_Transactions_ClientID_TransactionDate] ON [sales].[Transactions]
(
[ClientID] ASC,
[TransactionDate] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, DATA_COMPRESSION = PAGE) ON [DB_Data]
END
IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[sales].[DF_Transactions_Units]') AND type = 'D')
BEGIN
ALTER TABLE [sales].[Transactions] ADD CONSTRAINT [DF_Transactions_Units] DEFAULT ((0)) FOR [Units]
END
GO
IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[sales].[DF_Transactions_ISOCurrencyCode]') AND type = 'D')
BEGIN
ALTER TABLE [sales].[Transactions] ADD CONSTRAINT [DF_Transactions_ISOCurrencyCode] DEFAULT ('USD') FOR [ISOCurrencyCode]
END
GO
IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[sales].[DF_Transactions_InsertDate]') AND type = 'D')
BEGIN
ALTER TABLE [sales].[Transactions] ADD CONSTRAINT [DF_Transactions_InsertDate] DEFAULT (sysdatetime()) FOR [InsertDate]
END
GO
IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[sales].[DF_Transactions_UpdateDate]') AND type = 'D')
BEGIN
ALTER TABLE [sales].[Transactions] ADD CONSTRAINT [DF_Transactions_UpdateDate] DEFAULT (sysdatetime()) FOR [UpdateDate]
END
GO
temporary table
same columns as the mgdata. including the relevant fields. Also has a non-unique clustered index
(
[BusinessTransactionID] [varchar](150) NULL,
[BusinessUserID] [varchar](150) NULL,
[PostalCode] [varchar](25) NULL,
[TransactionDate] [datetime2](2) NULL,
[Units] [int] NOT NULL,
[StartDate] [datetime2](2) NULL,
[EndDate] [datetime2](2) NULL,
[TransactionID] [bigint] NULL,
[ClientID] [int] NULL,
)
CREATE CLUSTERED INDEX ##workingTransactionsMG_idx ON #workingTransactions (TransactionID)
It is populated in batches (500k rows at a time), something like this
IF OBJECT_ID(N'tempdb.dbo.#workingTransactions') IS NOT NULL DROP TABLE #workingTransactions;
select fields
into #workingTransactions
from import.Transactions
where importrowid between two number ranges -- pseudocode
Primary Key
CONSTRAINT [PK_Transactions_TransactionID] PRIMARY KEY CLUSTERED
(
[TransactionID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, DATA_COMPRESSION=PAGE) ON [Data]
) ON [Data]
Non-clustered index
CREATE NONCLUSTERED INDEX [NCI_Transactions_ClientID_TransactionDate] ON [sales].[Transactions]
(
[ClientID] ASC,
[TransactionDate] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, DATA_COMPRESSION = PAGE)
sample update statement
-- updates every field
update t
set
t.transactionid = s.transactionid,
t.[CityCode]=s.[CityCode],
t.TransactionDate=s.[TransactionDate],
t.[ClientID]=s.[ClientID],
t.[PackageMonths] = s.[PackageMonths],
t.UpdateDate = @UpdateDate
FROM #workingTransactions s
JOIN [DB].[sales].[Transactions] t
ON s.[TransactionID] = t.[TransactionID]
WHERE CAST(HASHBYTES('SHA2_256 ',CONCAT( S.[BusinessTransactionID],'|',S.[BusinessUserID],'|', etc)
<> CAST(HASHBYTES('SHA2_256 ',CONCAT( T.[BusinessTransactionID],'|',T.[BusinessUserID],'|', etc)
My question is, what is going on under the hood? And what is the solution? For reference, the link above mentions this:
At this point, I have a few theories:
- Bug related to memory pressure or large parallel update plan, but I would expect a different type of error and so far I cannot correlate
low resources will timeframe of these isolated and sporadic errors.- A bug in UPDATE statement or data is causing an actual duplicate violation on the primary key, but some obscure SQL Server bug is
resulting in and error message that cites the wrong index name.- Dirty reads resulting from read uncommitted isolation causing a large parallel update to double insert. But ETL developers claim
default read committed is used, and it’s hard to determine exactly
what isolation level the process is actually used at runtime.I suspect that if I tweak the execution plan as a work-around, perhaps
MAXDOP (1) hint or using session trace flag to disable spool
operation, the error will just go away, but it’s unclear how this
would impact performance
Version
Microsoft SQL Server 2017 (RTM-CU13) (KB4466404) — 14.0.3048.4 (X64)
Nov 30 2018 12:57:58
Copyright (C) 2017 Microsoft Corporation
Enterprise Edition (64-bit) on Windows Server 2016 Standard 10.0 (Build 14393: )
|
SQL Server Error Messages — Msg 2601 Error Message Server: Msg 2601, Level 16, State 1, Line 1 Cannot insert duplicate key row in object '<Object Name>' with unique index '<Index Name>'. Causes A unique index guarantees that the index key contains no duplicate values and therefore every row in the table in some way unique. A unique index is created by including the argument UNIQUE when creating an index using the CREATE INDEX statement. The CREATE INDEX statement creates a relational index on a specified table or view and the index can be created before there is data in the table. |
As the error message suggests, when inserting data into a table that contains a unique index and the data in the column or columns participating in the unique index already exist in the table, this error message will be raised.
To illustrate, here’s a simple table that contains a unique index on one of its columns:
CREATE TABLE [dbo].[Currency] (
[CurrencyCode] CHAR(3),
[CurrencyName] VARCHAR(50)
)
GO
CREATE UNIQUE INDEX [IX_Currency_CurrencyCode] ON [dbo].[Currency] ( [CurrencyCode] )
GO
The following script populates the table with data of currency codes:
INSERT INTO [dbo].[Currency] ( [CurrencyCode], [CurrencyName] ) VALUES ( 'USD', 'U.S. Dollar' ) INSERT INTO [dbo].[Currency] ( [CurrencyCode], [CurrencyName] ) VALUES ( 'EUR', 'Euro' ) INSERT INTO [dbo].[Currency] ( [CurrencyCode], [CurrencyName] ) VALUES ( 'GBP', 'Pound Sterling' ) INSERT INTO [dbo].[Currency] ( [CurrencyCode], [CurrencyName] ) VALUES ( 'INR', 'Indian Rupee' )
If by accident the same script is executed, the following error message will be generated for each INSERT statement executed:
Msg 2601, Level 14, State 1, Line 2 Cannot insert duplicate key row in object 'dbo.Currency' with unique index 'IX_Currency_CurrencyCode'.
Another way of encountering this error is when inserting data to a table and the data are coming from another table. Here’s a script that illustrates this scenario.
CREATE TABLE [dbo].[Currency_New] (
[CurrencyCode] CHAR(3),
[CurrencyName] VARCHAR(50)
)
GO
INSERT INTO [dbo].[Currency_New] ( [CurrencyCode], [CurrencyName] )
VALUES ( 'CAD', 'Canadian Dollar' )
INSERT INTO [dbo].[Currency_New] ( [CurrencyCode], [CurrencyName] )
VALUES ( 'SWF', 'Swiss Franc' )
INSERT INTO [dbo].[Currency_New] ( [CurrencyCode], [CurrencyName] )
VALUES ( 'AUD', 'Australian Dollar' )
INSERT INTO [dbo].[Currency_New] ( [CurrencyCode], [CurrencyName] )
VALUES ( 'CAD', 'Canadian Dollar' )
INSERT INTO [dbo].[Currency_New] ( [CurrencyCode], [CurrencyName] )
VALUES ( 'JPY', 'Japanese Yen' )
INSERT INTO [dbo].[Currency] ( [CurrencyCode], [CurrencyName] )
SELECT [CurrencyCode], [CurrencyName]
FROM [dbo].[Currency_New] A
WHERE NOT EXISTS (SELECT 'X' FROM [dbo].[Currency] B
WHERE A.[CurrencyCode] = B.[CurrencyCode])
GO
Msg 2601, Level 14, State 1, Line 2 Cannot insert duplicate key row in object 'dbo.Currency' with unique index 'IX_Currency_CurrencyCode'.
As can be seen from the script, the source table ([dbo].[Currency_New]) contains duplicate entries for the Canadian Dollar currency (CAD).
Solution / Work Around:
When inserting literal values into a table that contains a unique index in one of its columns that serves as the table’s key, there are a couple of ways of avoiding this error message. The first method is with the use of an IF statement that checks for the existence of the new data before performing an INSERT. If the row does not yet exist in the destination table, then it can be inserted.
Here’s how the script will look like:
IF NOT EXISTS (SELECT 'X' FROM [dbo].[Currency]
WHERE [CurrencyCode] = 'USD')
INSERT INTO [dbo].[Currency] ( [CurrencyCode], [CurrencyName] )
VALUES ( 'USD', 'U.S. Dollar' )
GO
The validation must be done for each set of literal values that needs to be inserted into the table.
Another way of checking for the existence of row in a table is still with the use of the NOT EXISTS statement but instead of using it in an IF statement, it can be used in the WHERE clause of a SELECT statement, as can be seen in the following script:
INSERT INTO [dbo].[Currency] ( [CurrencyCode], [CurrencyName] )
SELECT 'USD', 'U.S. Dollar'
WHERE NOT EXISTS (SELECT 'X' FROM [dbo].[Currency]
WHERE [CurrencyCode] = 'USD')
GO
Instead of using the VALUES clause of the INSERT statement, a SELECT statement is used to insert the data into the table. Since the data is not coming from any table, the FROM clause of the SELECT statement need not be included. Similar to the first option, this has to be done for each row of data that will be inserted into the destination table.
In the case of inserting data coming from another table and the source table contains duplicates, there are also a couple of ways of avoiding this error from being raised. The first option is simply to add the DISTINCT clause in the SELECT statement to make sure that only distinct rows will be inserted into the destination table.
Here’s an updated version of the script with the DISTINCT clause:
INSERT INTO [dbo].[Currency] ( [CurrencyCode], [CurrencyName] )
SELECT DISTINCT [CurrencyCode], [CurrencyName]
FROM [dbo].[Currency_New] [New]
WHERE NOT EXISTS (SELECT 'X' FROM [dbo].[Currency] [Old]
WHERE [New].[CurrencyCode] = [Old].[CurrencyCode])
GO
Alternatively, the MERGE statement can be used instead of the INSERT INTO … SELECT WHERE NOT EXISTS statement. The MERGE statement performs insert, update or delete operations on a target table based on the results of a join with a source table.
Here’s how the script will look like using the MERGE statement.
MERGE [dbo].[Currency] AS [Target]
USING (SELECT DISTINCT [CurrencyCode], [CurrencyName]
FROM [dbo].[Currency_New]) AS [Source]
ON [Target].[CurrencyCode] = [Source].[CurrencyCode]
WHEN MATCHED THEN
UPDATE SET [CurrencyName] = [Source].[CurrencyName]
WHEN NOT MATCHED THEN
INSERT ( [CurrencyCode], [CurrencyName] )
VALUES ( [Source].[CurrencyCode], [Source].[CurrencyName] );
GO
As can be seen in this MERGE statement, a DISTINCT clause is still needed in the source table. If the DISTINCT clause is not included, the following error message will be raised:
Msg 8672, Level 16, State 1, Line 2 The MERGE statement attempted to UPDATE or DELETE the same row more than once. This happens when a target row matches more than one source row. A MERGE statement cannot UPDATE/DELETE the same row of the target table multiple times. Refine the ON clause to ensure a target row matches at most one source row, or use the GROUP BY clause to group the source rows.
О чем статья
В этой статье будет описано, что делать, если при работе с 1С:Предприятие 8.1 Вам встретилось сообщение, содержащее строки:
Cannot insert duplicate key row in object
или
Попытка вставки неуникального значения в уникальный индекс.
Что такое индекс?
Подобно содержанию в книге, индекс в базе данных позволяет быстро искать конкретные сведения в таблице.
Индексы представляют собой структуру, позволяющую выполнять ускоренный доступ к строкам таблицы на основе значений одного или более ее столбцов.
Индекс содержит ключи, построенные из одного или нескольких столбцов таблицы или представления, и указатели, которые сопоставляются с местом хранения заданных данных.
Индексы сокращают объем данных, которые необходимо считать, чтобы возвратить результирующий набор.
Хотя индекс и связан с конкретным столбцом (или столбцами) таблицы, все же он является самостоятельным объектом базы данных.
Индексы таблиц в базе данных 1С:Предприятие создаются неявным образом при создании объектов конфигурации, а также при тех или иных настройках объектов конфигурации.
Физическая сущность индексов в MS SQL Server 2005.
Физически данные хранятся на 8Кб страницах. Сразу после создания, пока таблица не имеет индексов, таблица выглядит как куча (heap) данных. Записи не имеют определенного порядка хранения.
Когда вы хотите получить доступ к данным, SQL Server будет производить сканирование таблицы (table scan). SQL Server сканирует всю таблицу, что бы найти искомые записи.
Отсюда становятся понятными базовые функции индексов:
— увеличение скорости доступа к данным,
— поддержка уникальности данных.
Несмотря на достоинства, индексы так же имеют и ряд недостатков. Первый из них – индексы занимают дополнительное место на диске и в оперативной памяти. Каждый раз когда вы создаете индекс, вы сохраняете ключи в порядке убывания или возрастания, которые могут иметь многоуровневую структуру. И чем больше/длиннее ключ, тем больше размер индекса. Второй недостаток – замедляются операции вставки, обновления и удаления записей.
В среде MS SQL Server 2005 реализовано несколько типов индексов:
- некластерные индексы;
- кластерные (или кластеризованные) индексы;
- уникальные индексы;
- индексы с включенными столбцами
- индексированные представления
- полнотекстовый
- XML
Уникальный индекс
Уникальность значений в индексируемом столбце гарантируют уникальные индексы. При их наличии сервер не разрешит вставить новое или изменить существующее значение таким образом, чтобы в результате этой операции в столбце появились два одинаковых значения.
Уникальный индекс является своеобразной надстройкой и может быть реализован как для кластерного, так и для некластерного индекса. В одной таблице может существовать один уникальный кластерный и множество уникальных некластерных индексов.
Уникальные индексы следует определять только тогда, когда это действительно необходимо. Для обеспечения целостности данных в столбце можно определить ограничение целостности UNIQUE или PRIMARY KEY, а не прибегать к уникальным индексам. Их использование только для обеспечения целостности данных является неоправданной тратой пространства в базе данных. Кроме того, на их поддержание тратится и процессорное время.
1С:Предприятие 8.1 начиная с версии 8.1 активно использует кластерные уникальные индексы. Это означает, что при конвертации с 8.0 или переходе с 8.1.7 можно получить ошибку неуникального индекса.

Если неуникальность заключается в датах с нулевыми значениями, то проблема решается созданием базы с параметром смещения равным 2000.
Что делать?
1. Если проблема загрузкой базы данных, то:
1.1. Если Вы делаете загрузку (используйете dt-файл) в базу MS SQL Server, то при создании базы перед загрузкой укажите смещение дат — 2000.

Если уже база создана со смещением 0, то создайте новую с 2000.
1.2. Если есть возможность в файловом варианте работать с базой, то выполните Тестирование и Исправление, а также Конфигурация — Проверка конфигурации — Проверка логической целостности конфигурации + Поиск некорректных ссылок.
1.3. Если нет файлового варианта, попробуйте загрузить из DT в клиент-серверный вариант с DB2 (который менее требователен к уникальности), и затем выполнить Тестирование и Исправление, а также Конфигурация — Проверка конфигурации — Проверка логической целостности конфигурации + Поиск некорректных ссылок.
1.4. Для локализации проблемы можно определить данные объекта, загрузка которого не удалась. Для этого надо включить во время загрузки трассировку в утилите Profiler или включите запись втехнологический журнал событий DBMSSQL и EXCP.
1.5. Если доступна узел (планы обменов), то выполнить обмен. Можно также дополнительно перед обменом выполнить пункт 2.3.5
2. Если проблема неуникальности проявляется во время работы пользователей:
2.1. Найти с помощью метода пункта 1.4 проблемный запрос.
2.1.2. Иногда ошибка возникает во время исполнения запросов, например:
Данная ошибка возникает из-за того что в модуле регистра накопления «Рабочее время работников организаций» в процедуре «ЗарегистрироватьПерерасчеты» в запросе не стоит служебное слово «РАЗЛИЧНЫЕ».
Т.е. должно быть:
Запрос = Новый Запрос(
«ВЫБРАТЬ РАЗЛИЧНЫЕ
| Основные.ФизЛицо,
. . . . .
В последних выпущенных релизах ЗУП и УПП ошибка не возникает, т.к. там стоит «РАЗЛИЧНЫЕ».
2.2. После нахождения проблемного индекса из предыдущего пункта, необходимо найти неуникальную запись.
2.2.1. «Рыба» скрипта для определения неуникальных записей с помощью SQL:
SELECT COUNT(*) Counter, <перечисление всех полей соответствующего индекса> from <имя таблицы>
GROUP BY <перечисление всех полей соответствующего индекса>
HAVING Counter > 1
2.2.2 Пример. Индекс в ошибке называется «_Document140_VT1385_IntKeyIndNG».
Перечень полей таблицы:
_Document140_IDRRef, _KeyField, _LineNo1386, _Fld1387, _Fld1388, _Fld1389, _Fld1390, _Fld1391RRef, _Fld1392RRef, _Fld1393_TYPE, _Fld1393_RTRef, _Fld1393_RRRef, _Fld1394,
_Fld1395, _Fld1396RRef, _Fld1397, _Fld1398, _Fld1399RRef, _Fld22260_TYPE, _Fld22260_RTRef, _Fld22260_RRRef, _Fld22261_TYPE, _Fld22261_RTRef, _Fld22261_RRRef
Перед выполнением приведенной ниже процедуры сделайте резервную копию базы данных.
Выполните в MS SQL Server Query Analizer:
select count(*), _Document140_IDRRef, _KeyField
from _Document140_VT1385
group by _Document140_IDRRef, _KeyField
having count(*) > 1
С его помощью узнайте значения колонок _Document140_IDRRef, _KeyField, дублирующихся записей (id, key).
При помощи запроса:
select *
from _Document140_VT1385
where _Document140_IDRRef = id1 and _KeyField = key1 or _Document140_IDRRef = id2 and _KeyField = key2 or …
посмотрите на значения других колонок дублирующихся записей.
Если обе записи имеют осмысленные значения и эти значения разные, то исправьте значение _KeyField на уникальное. Для этого определите максимальное занятое значение _KeyField (keymax):
select max(_KeyField)
from _Document140_VT1385
where _Document140_IDRRef = id1
Замените значение _KeyField в одной из повторяющихся записей на правильное:
update _Document140_VT1385
set _KeyField = keymax + 1
where _Document140_IDRRef = id1 and _LineNo1386 = lineno1
Здесь _LineNo1386 = — дополнительное условие, которое позволяет выбрать одну из двух повторяющихся записей.
Если одна (или обе) из повторяющихся записей имеет очевидно неправильное значение, то ее нужно удалить:
delete from _Document140_VT1385
where _Document140_IDRRef = id1 and _LineNo1386 = lineno1
Если повторяющиеся записи имеют одинаковые значения во всех колонках, то из них нужно оставить одну:
select distinct *
into #tmp1
from _Document140_VT1385
where _Document140_IDRRef = id1 and _KeyField = key1
delete from _Document140_VT1385
where _Document140_IDRRef = id1 and _KeyField = key1
insert into _Document140_VT1385
select #tmp1
drop table #tmp1
Описанную процедуру необходимо выполнить для каждой пары повторяющихся записей.
2.2.3. Второй пример:
SELECT COUNT(*) AS Expr2, _IDRRef AS Expr1, _Description
FROM _Reference8_
GROUP BY _IDRRef, _Description
HAVING (COUNT(*) > 1)
2.3.4 Пример определения неуникальных записей с помощью запроса 1С:Предприятие:
ВЫБРАТЬ Справочник.Ссылка
ИЗ Справочник.Справочник КАК Справочник
СГРУППИРОВАТЬ ПО Справочник.Ссылка
ИМЕЮЩИЕ КОЛИЧЕСТВО(*) > 1
или для бухгалтерии
ВЫБРАТЬ
Подзапрос.Период,
Подзапрос.Регистратор,
<измерения>,
СУММА(Подзапрос.КоличествоЗаписей) КАК КоличествоЗаписей
ИЗ
(ВЫБРАТЬ
Хозрасчетный.Период КАК Период,
Хозрасчетный.Регистратор КАК Регистратор,
<измерения>,
1 КАК КоличествоЗаписей
ИЗ
РегистрБухгалтерии.Хозрасчетный КАК Хозрасчетный) КАК Подзапрос
СГРУППИРОВАТЬ ПО
Подзапрос.Период,
Подзапрос.Регистратор,
<измерения>
ИМЕЮЩИЕ
СУММА(Подзапрос.КоличествоЗаписей) > 1
2.3.5 Сделать индекс субд не уникальным. Заксриптовать индекс с помощью Management Studio.
Далее удалить текущий индекс, скорректировать текст и создать скриптом неуникальный индекс.
2.3.6 Частный случай при обмене в РБД. Ошибка приходится на «вспомогательные» таблицы, связанные с расчетом итогов или аналитики. Например:
Ошибка при вызове метода контекста (Записать): Попытка вставки неуникального значения в уникальный индекс:
Microsoft OLE DB Provider for SQL Server: Cannot insert duplicate key row in object ‘dbo._AccntRegED10319’ with unique index ‘_Accnt10319_ByPeriod_TRNRN’.
HRESULT=80040E2F, SQLSrvr: Error state=1, Severity=E, native=2601, line=1
В этом случаи перед загрузкой выключить использование итогов, загрузить сообщение, включить использование итогов и пересчитать.
A common coding strategy is to have multiple application servers attempt to insert the same data into the same table at the same time and rely on the database unique constraint to prevent duplication. The “duplicate key violates unique constraint” error notifies the caller that a retry is needed. This seems like an intuitive approach, but relying on this optimistic insert can quickly have a negative performance impact on your database. In this post, we examine the performance impact, storage impact, and autovacuum considerations for both the normal INSERT and INSERT..ON CONFLICT clauses. This information applies to PostgreSQL whether self-managed or hosted in Amazon Relational Database Service (Amazon RDS) for PostgreSQL or Amazon Aurora PostgreSQL-Compatible Edition.
Understanding the differences between INSERT and INSERT..ON CONFLICT
In PostgreSQL, an insert statement can contain several clauses, such as simple insert with the values to be put into a table, an insert with the ON CONFLICT DO NOTHING clause, or an insert with the ON CONFLICT DO UPDATE SET clause. The usage and requirements for all these types differ, and they all have a different impact on the performance of the database.
Let’s compare the case of attempting to insert a duplicate value with and without the ON CONFLICT DO NOTHING clause. The following table outlines the advantages of the ON CONFLICT DO NOTHING clause.
| .. | Regular INSERT | INSERT..ON CONFLICT DO NOTHING |
| Dead tuples generated | Yes | No |
| Transaction ID used up | Yes | No |
| Autovacuum has more cleanup | Yes | No |
| FreeStorageSpace used up | Yes | No |
Let’s look at simple examples of each type of insert, starting with a regular INSERT:
postgres=> CREATE TABLE blog (
id int PRIMARY KEY,
name varchar(20)
);
CREATE TABLE
postgres=> INSERT INTO blog
VALUES (1,'AWS Blog1');
INSERT 0 1The INSERT 0 1 depicts that one row was inserted successfully.
Now if we insert the same value of id again, it errors out with a duplicate key violation because of the unique primary key:
postgres=> INSERT INTO blog
VALUES (1, 'AWS Blog1');
ERROR: duplicate key value violates unique constraint "blog_pkey"
DETAIL: Key (n)=(1) already exists.The following code shows how the INSERT… ON CONFLICT clause handles this violation error when inserting data:
postgres=> INSERT INTO blog
VALUES (1,'AWS Blog1')
ON CONFLICT DO NOTHING;
INSERT 0 0The INSERT 0 0 indicates that while nothing was inserted in the table, the query didn’t error out. Although the end results appear identical (no rows inserted), there are important differences when you use the ON CONFLICT DO NOTHING clause.
In the following sections, we examine the performance impact, bloat considerations, transaction ID acceleration and autovacuum impact, and finally storage impact of a regular INSERT vs. INSERT..ON CONFLICT.
Performance impact
The following excerpt of the commit message adding the INSERT..ON CONFLICT clause describes the improvement:
“This is implemented using a new infrastructure called ‘speculative insertion’. It is an optimistic variant of regular insertion that first does a pre-check for existing tuples and then attempts an insert. If a violating tuple was inserted concurrently, the speculatively inserted tuple is deleted and a new attempt is made. If the pre-check finds a matching tuple the alternative DO NOTHING or DO UPDATE action is taken. If the insertion succeeds without detecting a conflict, the tuple is deemed inserted.”
This pre-check avoids the overhead of inserting a tuple into the heap to later delete it in case it turns out to be a duplicate. The heap_insert () function is used to insert a tuple into a heap. Back in version 9.5, this code was modified (along with a lot of other code) to incorporate speculative inserts. HEAP_INSERT_IS_SPECULATIVE is used on so-called speculative insertions, which can be backed out afterwards without canceling the whole transaction. Other sessions can wait for the speculative insertion to be confirmed, turning it into a regular tuple, or canceled, as if it never existed and therefore never made visible. This change eliminates the overhead of performing the insert, finding out that it is a duplicate, and marking it as a dead tuple.
For example, the following is a simple select query on a table that attempted 1 million regular inserts that were duplicates:
postgres=> SELECT count(*) FROM blog;
-[ RECORD 1 ]
count | 1
Time: 54.135 msFor comparison, the following is a simple select query on a table that used the INSERT..ON CONFLICT statement:
postgres=> SELECT count(*) FROM blog;
-[ RECORD 1 ]
count | 1
Time: 0.761 msThe difference in time is because of the 1 million dead tuples generated in the first case by the regular duplicate inserts. To count the actual visible rows, the entire table has to be scanned, and when it’s full of dead tuples, it takes considerably longer. On the other hand, in the case of INSERT..ON CONFLICT DO NOTHING, because of the pre-check, no dead tuples are generated, and the count(*) completes much faster, as expected for just one row in the table.
Bloat considerations
In PostgreSQL, when a row is updated, the actual process is to mark the original row deleted (old value) and then insert a new row (new value). This causes dead tuple generation, and if not cleared up by vacuum can cause bloat. This bloat can lead to unnecessary space utilization and performance loss as queries scan these dead rows.
As discussed earlier, in a regular insert, there is no duplicate key pre-check before attempting to insert the tuple into the heap. Therefore, if it’s a duplicate value, it’s similar to first inserting a row and then deleting it. The result is a dead tuple, which must then be handled by vacuum.
In this example, with the pg_stat_user_tables view, we can see these dead tuples are generated when an insert fails due to a duplicate key violation:
postgres=> SELECT relname, n_dead_tup, n_live_tup
FROM pg_stat_user_tables
WHERE relname = 'blog';
-[ RECORD 1 ]-------+-------
relname | blog
n_live_tup | 7
n_dead_tup | 4As we can see, n_dead_tup currently is 4. We attempt inserting five duplicate values:
postgres=> DO $$
BEGIN
FOR r IN 1..5 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1');
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
RAISE NOTICE 'duplicate row';
END;
END LOOP;
END;
$$;
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
DOWe now observe five additional dead tuples generated:
postgres=> SELECT relname, n_dead_tup, n_live_tup
FROM pg_stat_user_tables
WHERE relname = 'blog';
-[ RECORD 1 ]-------+-------
relname | blog
n_live_tup | 7
n_dead_tup | 9This highlights that even though no rows were successfully inserted, there is an increase in dead tuples (n_dead_tup).
Now, we run the following insert with the ON CONFLICT DO NOTHING clause five times:
DO $$
BEGIN
FOR r IN 1..5 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1') ON CONFLICT DO NOTHING;
END;
END LOOP;
END;
$$;Again, checking pg_stat_user_tables, we observe that there is no increase in n_dead_tup and therefore no dead tuples generated:
postgres=> SELECT relname, n_dead_tup, n_live_tup
FROM pg_stat_user_tables
WHERE relname = 'blog';
-[ RECORD 1 ]-------+-------
relname | blog
n_live_tup | 7
n_dead_tup | 9In the normal insert, we see dead tuples increasing, whereas no dead tuples are generated when we use the ON CONFLICT DO NOTHING clause. These dead tuples result in unnecessary table bloat as well as consumption of FreeStorageSpace.
Transaction ID usage acceleration and autovacuum impact
A PostgreSQL database can have two billion “in-flight” unvacuumed transactions before PostgreSQL takes dramatic action to avoid data loss. If the number of unvacuumed transactions reaches (2^31 – 10,000,000), the log starts warning that vacuuming is needed. If the number of unvacuumed transactions reaches (2^31 – 1,000,000), PostgreSQL sets the database to read-only mode and requires an offline, single-user, standalone vacuum. This is when the database reaches a “Transaction ID wraparound”, which is described in more detail in the PostgreSQL documentation. This vacuum requires multiple hours or days of downtime (depending on database size). More details on how to avoid this situation are described in Implement an Early Warning System for Transaction ID Wraparound in Amazon RDS for PostgreSQL.
Now let’s look at how these two different inserts impact the transaction ID usage by running some tests. All tests after this point are run on two different identical instances: one for regular INSERT testing and another one for the INSERT..ON CONFLICT clause.
Duplicate key with regular inserts
In the case of regular inserts, when the inserts error out, the transaction is canceled. This means if the application inserts 100 duplicate key values, 100 transaction IDs are consumed. This could lead to autovacuum runs to prevent wraparound in peak hours, which consumes resources that could otherwise be used for user workload.
For testing the impact of this, we ran a script using pgbench to repeatedly insert multiple key values into the blog table:
DO $$
BEGIN
FOR r in 1..1000000 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1');
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
RAISE NOTICE 'duplicate row';
END;
END LOOP;
END;
$$;The script runs the INSERT statement 1 million times, and if it throws an error, prints out duplicate row.
We used the following pgbench command to run it through multiple connections:
pgbench --host=iocblog.abcedfgxymxvb.eu-west-1.rds.amazonaws.com --port=5432 --username=postgres -c 1000 -f script postgresWe observed multiple notice messages, because all were duplicate values:
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate rowFor this test, we modified some autovacuum parameters. First, we set log_autovacuum_min_duration to 0, to log all autovacuum actions. Secondly, we set rds.force_autovacuum_logging_level to debug5 in order to log detailed information about each run.
As the script did more and more loops, the transaction ID usage increased, as shown in the following visualization.

On this test instance, only our contrived workload was being run. We used Amazon CloudWatch to observe that as soon as MaximumUsedTransactionIds hit autovacuum_freeze_max_age (default 200 million), autovacuum worker was launched to prevent wraparound. The following is a snapshot of pg_stat_activity for that time:
postgres=> select * from pg_stat_activity where query like '%autovacuum%';
-[ RECORD 1 ]----+--------------------------------------------------------------------
datid | 14007
datname | postgres
pid | 3049
usesysid |
usename |
application_name |
client_addr |
client_hostname |
client_port |
backend_start | 2020-11-26 12:22:37.364145+00
xact_start | 2020-11-26 12:22:37.403818+00
query_start | 2020-11-26 12:22:37.403818+00
state_change | 2020-11-26 12:22:37.403818+00
wait_event_type | LWLock
wait_event | ProcArrayLock
state | active
backend_xid |
backend_xmin | 205602359
query | autovacuum: VACUUM public.blog (to prevent wraparound)
backend_type | autovacuum workerWhen we observe the query output and the graph, we can see that the autovacuum started at the time MaximumUsedTransactionIds reached 200 million (around 12:22 UTC; this was expected so as to prevent transaction ID wraparound). During the same time, we observed the following in postgresql.log:
2020-11-26 12:22:37 UTC::@:[3049]:DEBUG: blog: vac: 5971078 (threshold 50), anl: 0 (threshold 50)
.
.
2020-11-26 12:22:45 UTC::@:[3202]:WARNING: oldest xmin is far in the past
2020-11-26 12:22:45 UTC::@:[3202]:HINT: Close open transactions soon to avoid wraparound problems.
You might also need to commit or roll back old prepared transactions, or drop stale replication slots.The preceding code shows autovacuum running and having to act on 5.9 million dead tuples in the table. The warning about wraparound problems is because of the script generating the dead tuples, and advancing the transaction IDs. As time passed, autovacuum finally completed cleaning up the dead tuples:
2020-11-26 13:05:28 UTC::@:[62084]:LOG: automatic aggressive vacuum of table "postgres.public.blog": index scans: 2
pages: 0 removed, 1409317 remain, 48218 skipped due to pins, 0 skipped frozen
tuples: 115870210 removed, 96438 remain, 0 are dead but not yet removable, oldest xmin: 460304384
buffer usage: 4132095 hits, 21 misses, 1732480 dirtied
avg read rate: 0.000 MB/s, avg write rate: 37.730 MB/s
system usage: CPU: user: 22.71 s, system: 1.23 s, elapsed: 358.73 sAutovacuum had to act on approximately 115 million tuples. This is what we observed on an idle system with only a script running to insert duplicate values. The table here was pretty simple, with only two columns and two live rows. For bigger production tables, which realistically have more columns and more data, it could be much worse. Let’s now see how to avoid this by using INSERT..ON CONFLICT.
Duplicate key with INSERT..ON CONFLICT
We modified the same script as in the previous section to include the ON CONFLICT DO NOTHING clause:
DO $$
BEGIN
FOR r IN 1..1000000 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1') ON CONFLICT DO NOTHING;
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
RAISE NOTICE 'duplicate row';
END;
END LOOP;
END;
$$;We ran the script on the instance in the following steps:
// Check the live rows in the table
postgres=> SELECT * FROM blog;
n | name
---+-----------
1 | AWS Blog1
2 | AWS Blog2
(2 rows)
postgres=> timing
Timing is on.
postgres=> SELECT now();
now
-------------------------------
2020-11-29 22:25:26.426271+00
(1 row)
Time: 2.689 ms
// Check the current transaction ID of the database (before running the script) :
postgres=> SELECT txid_current();
txid_current
--------------
16373267
(1 row)
//Run the script in another session as follows :
pgbench --host=iocblog2.abcdefghivb.eu-west-1.rds.amazonaws.com --port=5432 --username=postgres -c 1000 -f script2 postgres
Password:
starting vacuum...end.
//After some time later, go to previous session and check transaction ID along with pg_stat_activity. It increased by 4 transactions (which were the ones including our testing).
postgres=> SELECT now();
-[ RECORD 1 ]----------------------
now | 2020-11-29 22:56:59.241092+00
Time: 8.692 ms
postgres=> SELECT txid_current();
-[ RECORD 1 ]+---------
txid_current | 16373271
Time: 234.526 ms
//The following query shows the 1001 active transactions which are active because of the script, but aren't causing a spike in transaction IDs.
postgres=> SELECT now();
-[ RECORD 1 ]----------------------
now | 2020-11-29 22:59:44.373064+00
Time: 7.297 ms
postgres=> SELECT COUNT(*)
FROM pg_stat_activity
WHERE query like '%blog%'
AND backend_type='client backend';
-[ RECORD 1 ]
count | 1001
Time: 181.370 ms
postgres=> SELECT now();
-[ RECORD 1 ]----------------------
now | 2020-11-29 22:59:52.661102+00
Time: 6.212 ms
postgres=> SELECT txid_current();
-[ RECORD 1 ]+---------
txid_current | 16373273
Time: 741.437 msThe preceding testing shows that if we use INSERT..ON CONFLICT, the transaction IDs aren’t consumed. The following visualization shows the MaximumUsedTransactionIds metric.

There is still one more benefit to examine by using this clause: storage space.
Storage space considerations
In the case of the normal insert, the dead tuples that are generated result in unnecessary space consumption. Even in our small test workload, we were able to quickly end up in a storage full situation. If this happens in a production system, a scale storage is required.
Duplicate key with regular inserts
As discussed earlier, the tuples are inserted into the heap and checked if they are valid as per the constraint. If it fails, it’s marked as deleted. We can observe the impact on the FreeStorageSpace metric.
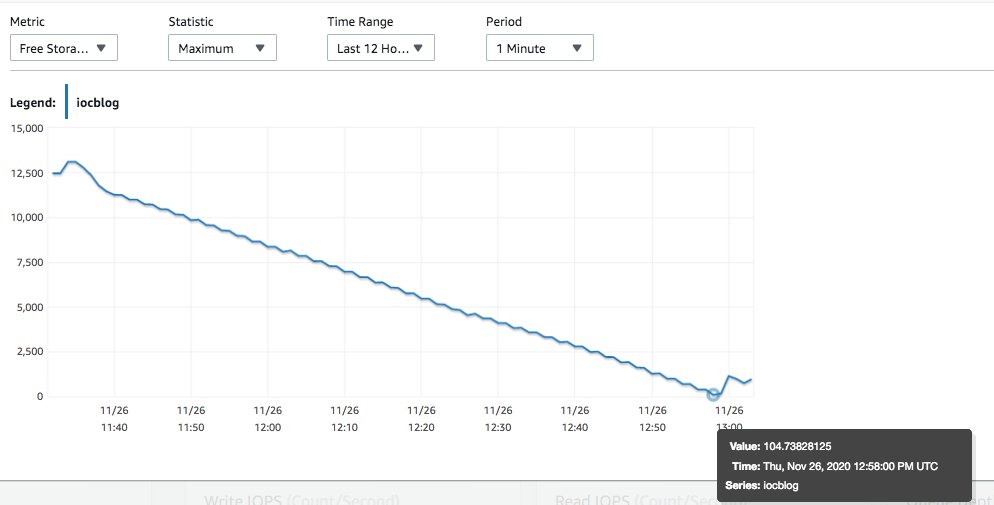
FreeStorageSpace went down all the way to a few MBs because these dead rows consume disk space. We used the following queries to monitor the script, they show that while there are only two visible tuples, space is consumed by the dead rows.
postgres=> select count(*) from blog;
-[ RECORD 1 ]
count | 2
postgres=> select pg_size_pretty (pg_table_size('blog'));
-[ RECORD 1 ]--+------
pg_size_pretty | 5718 MB
(1 row)In our small instance, we went into Storage-full state during our script execution.

Duplicate key with INSERT..ON CONFLICT
For comparison, when we ran the script using INSERT..ON CONFLICT, there was absolutely no drop in storage. This is because the transaction is prechecked and the tuple isn’t inserted in the table. With no dead tuples generated, no space is taken up by them, and the instance doesn’t run out of storage space due to duplicate inserts.

Summary
Let’s recap each of the considerations we discussed in the previous sections.
| .. | Regular INSERT | INSERT..ON CONFLICT DO NOTHING |
| Bloat considerations | Dead tuples generated for each conflicting tuples inserted in the relation. | Pre-check before inserting into the heap ensures no duplicates are inserted. Therefore, no dead tuples are generated. |
| Transaction ID considerations | Each failed insert causes the transaction to cancel, which causes consumption of 1 transaction ID. If too many duplicate values are inserted, this can spike up quickly. | The transaction can be backed out and not canceled in the case of a duplicate, and therefore, a transaction ID is not consumed. |
| Autovacuum Impact | As transaction IDs increase, autovacuum to prevent wraparound is triggered, consuming resources to clean up the dead rows. | No dead tuples, no transaction ID consumption, no autovacuum to prevent wraparound is triggered. |
| FreeStorageSpace considerations | The dead tuples also cause storage consumption. | No dead tuples generated, so no extra space is consumed. |
In this post, we showed you some of the issues that duplicate key violations can cause in a PostgreSQL database. They can cause wasted disk storage, high transaction ID usage and unnecessary Autovacuum work.
We offered an alternative approach using the “INSERT..ON CONFLICT“ clause which avoid these problems. It is recommended to use this alternative if you are constantly observing high volumes of the “duplicate key violates unique constraint” error in your logs. You might need to make some application code changes while using this option to see whether the INSERT succeeded or failed. This can not be determined by the error anymore (as there will be none generated) but by checking the number of rows affected with the insert query.
If you have any questions, let us know in the comments section.
About the Authors
 Divya Sharma is a Database Specialist Solutions architect at AWS, focusing on RDS/Aurora PostgreSQL. She has helped multiple enterprise customers move their databases to AWS, providing assistance on PostgreSQL performance and best practices.
Divya Sharma is a Database Specialist Solutions architect at AWS, focusing on RDS/Aurora PostgreSQL. She has helped multiple enterprise customers move their databases to AWS, providing assistance on PostgreSQL performance and best practices.
 Shawn McCoy is a Senior Database Engineer for RDS & Aurora PostgreSQL. After being an Oracle DBA for many years he became one of the founding engineers for the launch of RDS PostgreSQL in 2013. Since then he has been improving the service to help customers succeed and scale their applications.
Shawn McCoy is a Senior Database Engineer for RDS & Aurora PostgreSQL. After being an Oracle DBA for many years he became one of the founding engineers for the launch of RDS PostgreSQL in 2013. Since then he has been improving the service to help customers succeed and scale their applications.
[Solved] How to solve MySQL error code: 1062 duplicate entry?
January 21, 2016 /
Error Message:
Error Code: 1062. Duplicate entry ‘%s’ for key %d
Example:
Error Code: 1062. Duplicate entry ‘1’ for key ‘PRIMARY’
Possible Reason:
Case 1: Duplicate value.
The data you are trying to insert is already present in the column primary key. The primary key column is unique and it will not accept the duplicate entry.
Case 2: Unique data field.
You are trying to add a column to an existing table which contains data and set it as unique.
Case 3: Data type –upper limit.
The auto_increment field reached its maximum range.
 |
| MySQL NUMERICAL DATA TYPE — STORAGE & RANGE |
Solution:
Case 1: Duplicate value.
Set the primary key column as AUTO_INCREMENT.
ALTER TABLE ‘table_name’ ADD ‘column_name’ INT NOT NULL AUTO_INCREMENT PRIMARY KEY;
Now, when you are trying to insert values, ignore the primary key column. Also you can insert NULL value to primary key column to generate sequence number. If no value specified MySQL will assign sequence number automatically.
Case 2: Unique data field.
Create the new column without the assigning it as unique field, then insert the data and now set it as unique field now. It will work now!!!
Case 3: Data type-upper limit.
When the data type reached its upper limit, for example, if you were assigned your primary key column as TINYINT, once the last record is with the id 127, when you insert a new record the id should be 128. But 128 is out of range for TINYINT so MySQL reduce it inside the valid range and tries to insert it with the id 127, therefore it produces the duplicate key error.
In order to solve this, you can alter the index field, setting it into signed / unsigned INT/ BIGINT depending on the requirement, so that the maximum range will increase. You can do that by using the following command:
ALTER TABLE ‘table_name’ MODIFY ‘column_name’ INT UNSIGNED NOT NULL AUTO_INCREMENT;
You can use the following function to retrieve the most recently automatically generated AUTO_INCREMENT value:
mysql> SELECT LAST_INSERT_ID();
Final workaround:
After applying all the above mentioned solutions and still if you are facing this error code: 1062 Duplicate entry error, you can try the following workaround.
Step 1: Backup database:
You can backup your database by using following command:
mysqldump database_name > database_name.sql
Step 2: Drop and recreate database:
Drop the database using the following command:
DROP DATABASE database_name;
Create the database using the following command:
CREATE DATABASE database_name;
Step 3: Import database:
You can import your database by using following command:
mysql database_name < database_name.sql;
After applying this workaround, the duplicate entry error will be solved. I hope this post will help you to understand and solve the MySQL Error code: 1062. Duplicate entry error. If you still facing this issue, you can contact me through the contact me page. I can help you to solve this issue.