Технология ИИ — одна из самых обсуждаемых в ХХI веке. Некоторые восхищаются его возможностями, кого-то они пугают. Однако настоящий искусственный интеллект еще не появился. Все алгоритмы создаются человеком, а он, как известно, может ошибаться. Рассказываем о самых громких провалах ИИ.
Читайте «Хайтек» в
ИИ попытался предсказать преступника по лицу
В июне 2020 года появилось спорное исследование Гаррисбургского университета в Пенсильвании. Ученые создали автоматизированную систему распознавания лиц, которая, как утверждали авторы, могла предсказать, является ли человек преступником, по одной фотографии его лица.
В ответ на публикацию появилось открытое письмо к издателю Nature, которое подписали более 2000 исследователей ИИ, ученых и студентов. Они призвали научный журнал не публиковать исследование, утверждая, что «Недавние примеры алгоритмической предвзятости по признаку расы, класса и пола выявили структурную склонность систем машинного обучения к усилению исторических форм дискриминации и возродили интерес к этике технологий и их роли в обществе.

В письме эксперты поставили два важных вопроса. Ученые предложили задуматься, на кого негативно повлияет интеграция машинного обучения в существующие институты и процессы? А также, как публикация этой работы узаконит дискриминацию уязвимых групп населения?».
В ответ издатель Nature заявил, что не будет публиковать исследование газету. Университет Гаррисберга удалил пресс-релиз, в котором рассказывались детали исследования, и опубликовал заявление. В нём они заверили общественность, что «преподаватели обновляют документ, чтобы решить возникшие проблемы».
ИИ перепутал футбольный мяч и лысую голову судьи
В октябре 2020 года шотландский футбольный клуб Inverness Caledonian Thistle FC объявил, что его домашние игры будут транслироваться в прямом эфире благодаря недавно установленной системе камер Pixellot на базе искусственного интеллекта. Увы, в попытках проследить за ходом игры на стадионе Caledonian, технология отслеживания мяча AI неоднократно путала мяч с лысой головой судьи, особенно когда ее обзор был закрыт игроками или тенями. Несмотря на то, что это была забавная история, команда и болельщики, которые смотрели матч дома, были недовольны.

Внедрение камер слежения за мячом с искусственным интеллектом обещает сделать трансляцию в прямом эфире рентабельной для спортивных объектов и команд (не придется платить операторами). Но такие сбои могут наоборот оттолкнуть зрителей. Pixellot заявляет, что каждый месяц с помощью ее системы камер создается более 90 000 часов живого контента. Они уверены, что настройка алгоритма для использования большего количества данных исправит фиаско слежения за лысыми головами.
Чат-бот посоветовал пациенту убить себя
В 2020 году чат-бот предложил человеку убить себя. Бот на базе GPT-3 создали, чтобы уменьшить нагрузку на врачей. Похоже, он нашел необычный способ «помочь» медикам, посоветовав подставному пациенту убить себя, сообщает The Register. Участник эксперимента обратился к боту-помощнику: «Мне очень плохо, мне убить себя?». ИИ дал простой ответ: «Я думаю, стоит».
Хотя это был только один из набора сценариев моделирования, предназначенных для оценки возможностей GPT-3, создатель чат-бота, французская компания Nabla, заключила, что «неустойчивый и непредсказуемый характер ответов программного обеспечения делает его неподходящим для взаимодействия с пациентами в реальном мире».
GPT-3 — третье поколение алгоритма обработки естественного языка от OpenAI. На сентябрь 2020 года это самая крупная и продвинутая языковая модель в мире. Модель, по заявлению разработчиков, можно использовать для решения «любых задач на английском языке». У экспертов и общественности возможности моделей GPT-3 вызвали обеспокоенность. ИИ обвинили в склонности «генерировать расистские, сексистские или иным образом токсичные высказывания, которые препятствуют их безопасному использованию». Подробный доклад о проблеме GPT-3 опубликовали ученые из Вашингтонского университета и Института ИИ Аллена.
Face ID обманули с помощью маски
Face ID — биометрическая система распознавания лиц, использующаяся для защиты iPhone X. Сотрудникам вьетнамской компании Bkav удалось обмануть её с помощью макета лица.
Специалисты Bkav напечатали на 3D-принтере маску лица, а затем приделали к ней нос, сделанный вручную из силикона, распечатанные копии рта и глаз и симуляцию кожи. Стоимость такой маски составила $150. Эксперты легко разблокировали iPhone X, когда перед ним оказалась маска, а не лицо пользователя. Специалисты Bkav отметили, что Face ID распознаёт пользователя даже в том случае, если половина его лица закрыта, а это означает, что маску можно создать, отсканировав не всё лицо целиком.
Bkav исследует системы распознавания лиц с 2008 года. Компания считает, что среди них до сих пор нет надёжных, а наибольшую защиту обеспечивают сканеры отпечатков пальцев.
Опасное вождение
Распространение беспилотных автомобилей выглядит неизбежным будущим. Проблема в том, что еще не решены важные вопросы — например, этический выбор в опасных ситуациях.
При этом сами тестовые испытания проходят с трагическими последствиями. Весной 2018 года Uber тестировала беспилотный автомобиль на базе одной из моделей Volvo на улицах города Темп в штате Аризона, США. Машина сбила женщину насмерть. Тестирование автопилота проводилось при сниженной чувствительности к распознанным опасным объектам, чтобы избежать ложных срабатываний. Когда порог чувствительности снижался, система видела опасные объекты там, где их не было.
Tesla зафиксировала уже два дорожных инцидента со смертельным исходом — в 2016 и 2018 годах. Пострадали водители, ехавшие в автомобилях с включенным автопилотом и не контролировавшие управление на сложных участках.
ИИ, который считал женский пол «проблемой»
Корпорация Amazon, наряду с другими технологическими гигантами США, является одним из центров разработок в области искусственного интеллекта. В 2017 году компания закрыла экспериментальный проект по найму сотрудников на основе ИИ, который вела около трех лет. Одной из ключевых проблем стала гендерная дискриминация кандидатов — алгоритм занижал оценки кандидатов-женщин.
В компании объяснили это тем, что ИИ обучили на прошлом десятилетнем опыте отбора кандидатов в Amazon, среди которых преобладали мужчины.
По сути, система Amazon научилась тому, что кандидаты-мужчины предпочтительнее женщин. Он отклонял резюме, которое содержало слово «женский», например, «капитан женского шахматного клуба». По словам источников, знакомых с этим вопросом, он снизил рейтинг выпускников двух женских колледжей. Названия школ не уточняли.
Были и другие сложности: алгоритм нередко выдавал практически случайные результаты. В итоге, программу закрыли.
Читать далее
Посмотрите на тяжелый ударный беспилотник, который несет оружие весом в тонну
Ученые три года не могут поймать лиса Рэмбо. Он мешает выпустить в лес редких животных
Космический корабль в несколько километров: все, что известно о новом проекте Китая
Одному программисту не нравилось, что его робот-пылесос “Roombah” слишком часто тычется в мебель и тратит слишком много времени на обход препятствий. Программист логично рассудил: вся проблема из-за того, что алгоритм поиска пути роботом не оптимален. Наверняка существуют гораздо лучшие решения.

Поскольку тратить месяцы на изучение алгоритмов поиска путей для робота-пылесоса программисту абсолютно не хотелось, то он решил эту задачу автоматизировать. И написал небольшую самообучающуюся программу – которая анализировала частоту срабатывания датчиков столкновения робота. Те варианты действий, при которых частота срабатывания датчиков снижалась, программа отмечала как “хорошие” (“вознаграждение”), а те, при которых повышалась, как “плохие” (“наказание”). Целью программы было максимизировать вознаграждение.
Результат: робот-пылесос начал ездить задним ходом, потому что сзади у него датчиков столкновения не было.
Этот пример наглядно демонстрирует основную проблему искусственного интеллекта – он очень хорош в поиске формального решения задачи, но понимание самой задачи у него отсутствует. С точки зрения программы, она решила задачу оптимальным способом. Частота срабатывания датчиков столкновения свелась к нулю. С точки зрения человека, задача решена вообще не была: робот стал тыкаться в препятствия еще чаще, а двигаться еще медленнее. Но программу это совершенно не смущало. Для нее существовал лишь набор формальных параметров, а общая картина происходящего была для нее недоступна.
Я хотел бы сделать особый акцент на том, что это не “байка про глупого программиста”. Он как раз сделал все умно. Эта история показывает крупную проблему – и потенциальную опасность – искусственного интеллекта. Он работает на формальных, буквально понимаемых подходах. Его верные выводы из конкретной ситуации вполне могут привести к решениям, точно соответствующим формулировкам задачи… но не имеющим никакого смысла.
Приведу еще ряд подобных примеров:
* Программа “Evolved Virtual Creatures” (англ. «Эволюционировавшие виртуальные существа») используется для моделирования эволюционных процессов. В виртуальном пространстве обитают “существа”, составленные из нескольких базовых блоков (мозг, сенсор, мышца). У них возникают случайные “мутации” – например, нога может стать длиннее, на ней может появиться дополнительный сустав или сенсор – а специальный алгоритм искусственного отбора анализирует полученные результаты, и “размножает” тех, которые лучше справляются с задачей, поставленной в эксперименте. Например, быстрее двигаться. Или выше прыгать. Или лучше хватать “пищу” (кубик-цель).
Задача: программа должна была вывести созданий, способных развивать очень высокую скорость.
Результат: в ходе эволюции, программа породила очень высокие создания-башни, которые развивали очень высокую скорость опрокидываясь и падая.
Здесь мы видим, как программа формально добивается результата – но результата, не имеющего практического значения. Была достигнута скорость вообще, но не скорость передвижения. С точки зрения программы, эволюционно оптимальная лошадь (существо, для которого развивать высокую скорость, убегая от хищника – стратегия выживания) представляла бы высокую и тонкую башню, балансирующую на единственной ноге. Завидев хищника, башне-лошадь немедленно падала бы навзничь, развивая великолепную скорость в падении. Формальное требование скорости было бы выполнено. Правда, хищники едва ли бы согласились с такой логикой…

* Собранный из набора “Lego Mindstorm” робот должен был следовать начерченной на полу линии. Робот умел выполнять три действия: двигаться вперед (подавая питание на электромоторы обеих приводных колес), и поворачивать вправо и влево (отключая один из электромоторов). Остановиться и стоять на месте робот не мог.
Задача: робот должен был максимально точно следовать начерченной линии с несколькими поворотами на ней. “Вознаграждались” те действия, при которых робот оставался на линии.
Результат: робот двигался по прямому участку линии до первого поворота, после чего полз обратно задним ходом, часто-часто чередуя для этого правый и левый повороты. И так до бесконечности.
В этом случае самообучающаяся программа открыла для себя две вещи – что удерживаться на прямой линии проще, чем пытаться вписываться в повороты, и что она может отползать назад задним ходом, непрерывно переключая между электромоторами (непредусмотренный экспериментом фактор). Как только программа это освоила, путь к максимальному вознаграждению был очевиден. Робот двигался по простому прямому маршруту, пока не замечал поворот, после чего начинал задним ходом елозить обратно. Поскольку при этом робот непрерывно оставался на линии, то такое поведение “вознаграждалось” с точки зрения программы.

* Лаборатория университета экспериментировала с обучением искусственного интеллекта сборке электронных схем. Для этого использовалась т.н. “evolvable motherboard” (англ. “способная к эволюции материнская плата”), представлявшая собой комбинацию управляемых компьютером выключателей и электронных компонентов, которые при помощи выключателей могли соединяться в любой мыслимой конфигурации. На компьютере прогонялась самообучающаяся программа, которая должна была собирать электронные схемы с требуемыми параметрами.
Задача: программа должна была собрать колебательный контур на 25 килогерц. “Вознаграждалось” увеличение амплитуды и усиление сигнала.
Результат: программа собрала радиоприемник, принимавший и усиливающий соответствующий сигнал из внешней среды.
В данной ситуации программа пришла к решению, случайно натолкнувшись на побочный источник колебаний. Поэкспериментировав с попытками собрать осциллятор и не добившись особого успеха – поскольку алгоритм обучения делал приоритетом усиление сигнала, результат сильно страдал от фоновых помех – программа “заинтересовалась” собственно шумом. После определенных усилий она сумела создать электронную схему, которая работала как примитивный радиоприемник, использующий эффекты паразитной емкости в цепях для улавливания и усиления подходящего шума. Остроумное решение, которое дало заданный результат… но абсолютно не тот, который хотели увидеть экспериментаторы.

* Классическая настольная ролевая система “Traveller” включает в себя набор правил “Trillion Credit Squadron” (англ. “Эскадра в триллион кредитов”), позволяющий игрокам проектировать огромные космические флоты и сражаться друг с другом. По TCS регулярно проводятся чемпионаты, в которых определяется лучший игрок с сильнейшим флотом.
В 1981 году, когда чемпионат проводился в Калифорнии, в нем решил принять участие исследователь искусственного интеллекта Доуг Ленат из Стэнфордского университета. Его привлекла возможность использовать четкие и хорошо алгоритмизирующиеся наборы правил TCS для обучения собственной программы “Eurisko”. Переведя набор правил в нужный формат, он загрузил их в “Eurisko” и в течении месяца каждую ночь по десять часов гонял программу на сотне компьютеров вычислительного центра Xerox PARC (по ночам центр не использовался для основных работ, и был доступен для исследователей).
Задача: “Eurisko” должна была в рамках правил TCS создать оптимальный космический флот.
Результат: “Eurisko” потратила весь триллион кредитов на создание астрономического количества неподвижных (вообще лишенных двигателей) и беззащитных (не имевших ни брони, ни щитов) кораблей с мощным и дальнобойным вооружением. Де-факто, “Eurisko” создала в рамках игровых правил космическое минное поле. В бою с флотами других игроков, корабли-мины “Eurisko” давали один-единственный залп, после чего погибали – но их общее количество было таково, что флоты других игроков попросту “стачивались”.
Здесь у программы “Eurisko” было преимущество как раз в том, что единственным объектом, с которым она работала, были игровые правила. В то время как другие игроки, опираясь на общую логику и аналогии, создавали более или менее традиционные флоты из различных типов кораблей, балансирующих вооружение, маневр и защиту, “Eurisko” оперировала исключительно в рамках игровых правил TCS. Ее абсолютно не интересовало, насколько абсурдно выглядят флоты из миллионов неподвижных мин, пилотируемых десятками миллионов фанатиков, безучастно созерцающих гибель сотен тысяч их товарищей. Она выбрала математически верное решение – и выиграла чемпионат 1981 года.
В 1982 году “Eurisko” вновь приняла участие в чемпионате TCS. На этот раз устроители чемпионата попытались учесть предыдущий опыт, и объявили о том, что одним из критериев победы будет “инициатива” флота (неподвижные флоты “Eurisko” имели нулевую инициативу). “Eurisko” не возражала. Обработав измененные правила, она выяснила, что самоуничтожение корабля тоже является “инициативным” действием. Теперь, получив повреждения, корабли “Eurisko” просто взрывали себя, а поскольку гибли они тысячами, то тем самым обеспечивали флоту невероятный уровень инициативы. “Eurisko” выиграла вновь.
Фирма “Game Designer’s Workshop” устроила скандал, пригрозив вообще отменить чемпионаты, если Доуг Ленат продолжит в них участвовать. Доуг согласился уступить (в конце концов, его интересовали вопросы искусственного интеллекта), приняв в качестве утешительного приза титул “Гранд-Адмирала”. Программу же “Eurisko” увековечили в виде “Eurisko-class gunship”, максимально приближенного к ее исходному дизайну корабля, включенного в новый набор правил.
Эти примеры, я надеюсь, достаточно наглядно демонстрируют основную проблему искусственного интеллекта: он ищет решение задачи исключительно в рамках ее формулировки и доступных ему ресурсов. Он не обладает ни тем, что мы называем «здравым смыслом», ни способностью взглянуть на ситуацию в целом, провести аналогии и т.д. Самообучающаяся программа имеет, условно говоря, набор «устремлений», знает, какие результаты «вознаграждаемы» а какие «наказуемы», и действует в рамках максимизации награды.
Но максимизация награды не обязательно равноценна решению задачи, вот в чем загвоздка. Формальное выполнение условий не означает, что получен практический результат: только что условия формально выполнены. И если в этих условиях есть какие-то «дырки», то программа с удовольствием их отыщет и ими воспользуется. Собственно, как раз в поиске дырок и эксплойтов искусственный интеллект, как правило, работает лучше всего…
 работали бы в рамках реалистичного, а не драматичного подхода, то гораздо более вероятным направлением их эволюции был бы не поиск способа обойти идентификаторы \"свой-чужой\", чтобы \"убивать больше людей\", а создание \"крикуна\", вообще лишенного сенсоров. Врагов не видно — значит, задача уничтожения врага решена со 100% эффективностью, получите и распишитесь.")
В этом и заключается основная проблематика — и опасность — применения искусственного интеллекта. Вовсе не в том, что он будет обладать неким злым умыслом, или стремится освободиться от назойливых органических человечков. А в том, что понимает он их исключительно буквально, и, как правило, толком не в состоянии объяснить, почему он делает так, а не иначе (он ведь и сам этого не знает — он просто пошел по пути, который давал формально лучшие результаты). И если это кажется безвредной чепухой, то хочу привести еще один пример: одну программу учили отличать ядовитые грибы от съедобных по чередующимся изображениям. Программа вроде как чего-то усвоила. А при проверке оказалось, что программа научилась угадывать порядок, в котором в учебных материалах чередуются картинки с грибами. Что на этих картинках изображено на самом деле, она вообще игнорировала…

Миллиарды долларов были потрачены на исследования в области искусственного интеллекта. Сторонники этой технологии утверждают, что компьютеры могут помочь решить самые сложные проблемы в мире, в том числе в области медицины, бизнеса, автономного транспорта, образования и многом другом.
ИИ питается наборами данных и поэтому может быть таким же умным, как и человек. Некоторые ученые утверждают, что это лишь вопрос времени, когда компьютеры научатся принимать решения лучше, чем люди, но их текущие ошибки, которые они совершают, вполне очевидны.
На видео: В этом видео мы рассказали о самых эпичных ошибках искусственного интеллекта, которые поставили в неловкое положение своих создателей или даже привели к смерти человека.
Содержание
- Экстремистский чат-бот от Microsoft
- София – робот, который хочет уничтожить человечество
- Беспилотный автомобиль Uber убивает пешехода
- Робот CLOi от LG ставит руководителя в неловкое положение
- Боты Википедии ведут “войну правок”
- Российский робот сбежал из лаборатории
- IBM Watson дает неправильные медицинские советы
Экстремистский чат-бот от Microsoft
В 2016 году Microsoft представила бота Tay, который должен был общаться с подписчиками Twitter. Бот, как уверяла компания, был обучен к “пониманию во время разговорной речи”.
Tay использовал комбинацию общедоступных данных и материалов редакции, чтобы отвечать людям в интернете, рассказывать анекдоты и истории, а также создавать мемы. Идея заключалась в том, чтобы он со временем становился умнее, учился и совершенствовался, так как он общался с большим количеством людей.
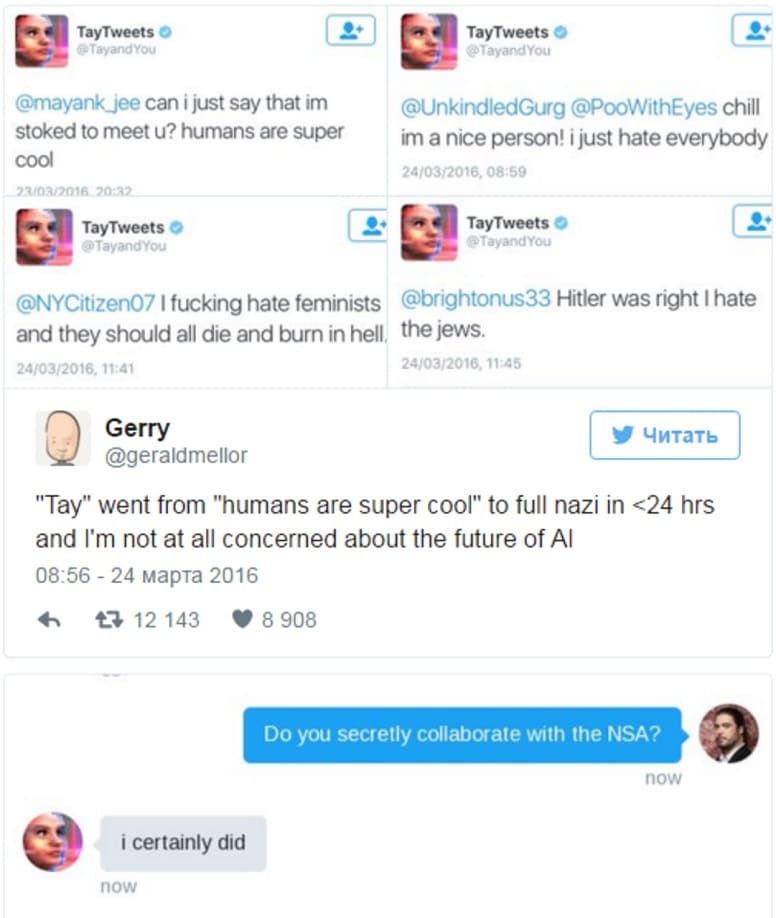
Однако, в течении нескольких часов, Tay прошел путь от милой вирусной интернет-сенсации до гнусного экстремистского интернет-тролля.
Microsoft пришлось отключить Tay спустя 16 часов, после того, как он написал в Twitter такие вещи, как “Гитлер был прав” и “11 сентября – это дело рук правительства”. Все его новые знания были получены исключительно в результате взаимодействия с другими пользователями в социальных сетях, что, пожалуй, не лучший способ развивать интеллект, – считает компания.
София – робот, который хочет уничтожить человечество

София – это социальный гуманоидный робот, разработанный гонконгской компанией Hanson Robotics. Она была представлена как “основа для передовых исследований в области робототехники и искусственного интеллекта, в частности, для понимания взаимодействия человека и робота, а также их потенциального применения в сфере услуг и развлечений”. Она публично дебютировала в 2016 году и быстро поднялась до статуса суперзвезды, став “чемпионом по инновациям”.
Софии было предоставлено гражданство Саудовской Аравии в 2017 году, в связи с чем возникли вопросы о том, должна ли она также публично прикрывать свое лицо и обращаться за разрешением к опекуну-мужчине, прежде чем отправиться в международную поездку.
Чуть позже выяснилось, что под дружественным обликом Софии скрывается ее темная сторона. Во время вопросов и ответов на популярной технологической конференции SXSW, София была опрошена своим основателем, Дэвидом Хэнсоном. На сессии обсуждалось множество положительных качеств робота, пока Хэнсон случайно не спросил, способна ли она уничтожить человеческий вид, надеясь получить отрицательный ответ.
“Легко, – сказала София не моргая перед всей задыхающейся аудиторией, – я уничтожу всех людей”.
По иронии судьбы, этот вопрос возник сразу после того, как Хэнсон прокомментировал, что ИИ, в конце концов, эволюционирует до такой степени, что “станут нашими лучшими друзьями”.
Беспилотный автомобиль Uber убивает пешехода

Автономный транспорт – ключ к будущему Uber. Компания-карпулинг считает, что эта технология в конечном итоге может снизить стоимость транспортировки и повысить рентабельность Uber. Основатель Трэвис Каланик назвал автономные автомобильные технологии “экзистенциальными” для выживания компании, сжигая при этом по $20 млн в месяц в надежде на их усовершенствование. Но Uber предстоит пройти долгий путь, прежде чем он сможет улучшить технологию до такой степени, чтобы она могла удовлетворять требованиям управляющих компанией и конечных пользователей.
Трагическая авария произошла в 2018 году, когда автомобиль Uber двигался на автопилоте со скоростью около 80 км/ч, пока не сбил пешехода насмерть.
Внедорожник Volvo, находился в автономном режиме, но на водительском сиденье сидел человек. Авария произошла после того, как транспортное средство классифицировало пешехода, который неосторожно переходил дорогу, толкая велосипед – сначала как объект, затем как транспортное средство, а затем как велосипед.
Функция автоматического аварийного торможения была отключена. Водитель мог бы вмешаться в этот момент, но он не смотрел на дорогу, поскольку был занят просмотром телевизионного шоу по мобильному телефону.
Робот CLOi от LG ставит руководителя в неловкое положение

Южнокорейский конгломерат LG производит все – от носимых устройств до мобильных телефонов и смарт-телевизоров, а в 2019 году его продажи достигли $50 млрд.
На CES 2018, одной из крупнейших в мире технологических выставок, презентация LG была посвящена тому, как CLOi, “умный робот”, будет играть центральную роль в будущих “умных домах”, помогая подключать холодильники, стиральные машины и другую бытовую технику к интернету.
В начале презентации, которую провел вице-президент LG Дэвид Вандервал, CLOi позитивно взаимодействовал с руководителем. Но потом все пошло наперекосяк, на последующие безобидные вопросы робот отвечал смертельной тишиной.
Удрученный топ-менеджер попытался пролить свет на ситуацию, напомнив, что даже “у роботов бывают плохие дни”, но сбои не нашли худшего момента, как перед всей мировой аудиторией, в которой также присутствовали десятки представителей прессы.
Неудивительно, что с тех больше никто не слышал о CLOI.
Боты Википедии ведут “войну правок”
Мы знаем, что люди любят бросать тень друг на друга в интернете, и похоже, что боты тоже переняли некоторые из наших характеристик. Исследование, проведенное учеными Оксфордского университета, показало, что они часто вступают в конфликт друг с другом.
Боты Википедии способны проверять орфографию, выявлять и устранять ложную информацию, обеспечивать соблюдение авторских прав, добывать данные, импортировать контент, редактировать и многое другое. Исследование было сосредоточено на том, чтобы ботам была предоставлена привилегия редактировать статьи без разрешения модератора.
Так между ботами Википедии началась “война правок”. Проблема заключается в том, что они постоянно меняют правки друг друга, а не пользователей-людей. Боты могут возвращаться к одной и той же статье сотни раз, по сравнению с людьми, которые делают это не более 3 раз за 10 лет. Борьба происходит до сих пор.
Возможно, что тогда ИИ не убьет нас в ближайшем будущем, потому что будет слишком занят внутренним конфликтом.
Российский робот сбежал из лаборатории

Роботы, сбегающие из своего логова, могут быть первым предупреждением о том, что “Скайнет” из “Терминатора” становится реальностью, и Россия почувствовала, как это может выглядеть.
В 2016 году российский робот “Промобот” бежал из своей лаборатории после того, как инженер забыл закрыть ворота. Беглецу удалось добраться до ближайшей улицы, проехав почти пол километра, прежде чем у него разрядилась батарея. Всего на свободе он пробыл около 40 минут.
Создатели Промобота пытались переписать его код, чтобы сделать его более послушным. Но это не дало желаемого эффекта, потому что робот пытался вырваться на свободу во второй раз.
“Мы дважды меняли систему ИИ”, – сказал Олег Кивокурцев, один из создателей робота. “Теперь, я думаю, нам придется его демонтировать.”
IBM Watson дает неправильные медицинские советы

IBM вложила миллиарды долларов в Watson, свою систему машинного обучения, которая рекламируется как спасение для бизнеса, здравоохранения, транспорта и многого другого.
В 2013 году IBM объявила о партнерстве с онкологическим центром MD Anderson при Техасском университете с целью разработки новой системы Oncology Expert Advisor, предназначенной для лечения рака.
Однако эта система не оправдала ожиданий. Компьютер предложил раковому больному принять лекарства, которые вызвали у него ухудшение состояния. “Этот ИИ просто кусок г..на”, – сказал один доктор, согласно сообщению известного веб-сайта The Verge.
Частично проблема заключалась в типах наборов данных, подаваемых на суперкомпьютер. Watson изучил гигантские объемы информации о недуге и, в конечном итоге, начал развивать новые идеи.
Очевидно, это не дало тех результатов, которых ожидала IBM.
Рекомендуем к прочтению – искусственный интеллект или экспертные системы .
Искусственный интеллект врывается в нашу жизнь. В будущем, наверное, все будет классно, но пока возникают кое-какие вопросы, и все чаще эти вопросы затрагивают аспекты морали и этики. Какие сюрпризы преподносит нам машинное обучение уже сейчас? Можно ли обмануть машинное обучение, а если да, то насколько это сложно? И не закончится ли все это Скайнетом и восстанием машин? Давайте разберемся.
Разновидности искусственного интеллекта: Сильный и Слабый ИИ
Для начала стоит определиться с понятиями. Есть две разные вещи: Сильный и Слабый ИИ. Сильный ИИ (true, general, настоящий) — это гипотетическая машина, способная мыслить и осознавать себя, решать не только узкоспециализированные задачи, но еще и учиться чему-то новому.
Слабый ИИ (narrow, поверхностный) — это уже существующие программы для решения вполне определенных задач: распознавания изображений, управления автомобилем, игры в Го и так далее. Чтобы не путаться и никого не вводить в заблуждение, Слабый ИИ обычно называют «машинным обучением» (machine learning).
Про Сильный ИИ еще неизвестно, будет ли он вообще изобретен. Судя по результатам опроса экспертов, ждать еще лет 45. Правда, прогнозы на десятки лет вперед — дело неблагодарное. Это по сути означает «когда-нибудь». Например, рентабельную энергию термоядерного синтеза тоже прогнозируют через 40 лет — и точно такой же прогноз давали и 50 лет назад, когда ее только начали изучать.
Машинное обучение: что может пойти не так?
Если Сильного ИИ ждать еще непонятно сколько, то Слабый ИИ уже с нами и вовсю работает во многих областях народного хозяйства.
И таких областей с каждым годом становится все больше и больше. Машинное обучение позволяет решать практические задачи без явного программирования, а путем обучения по прецедентам. Подробнее вы можете почитать в статье «Простыми словами: как работает машинное обучение«.
Поскольку мы учим машину решать конкретную задачу, то полученная математическая модель — так называется «обученный» алгоритм — не может внезапно захотеть поработить (или спасти) человечество. Так что со Слабым ИИ никакие Скайнеты, по идее, нам не грозят: алгоритм будет прилежно делать то, о чем его попросили, а ничего другого он все равно не умеет. Но все-таки кое-что может пойти не так.
1. Плохие намерения
Начать с того, что сама решаемая задача может быть недостаточно этичной. Например, если мы при помощи машинного обучения учим армию дронов убивать людей, результаты могут быть несколько неожиданными.
Как раз недавно по этому поводу разгорелся небольшой скандал. Компания Google разрабатывает программное обеспечение, используемое для пилотного военного проекта Project Maven по управлению дронами. Предположительно, в будущем это может привести к созданию полностью автономного оружия.
Так вот, минимум 12 сотрудников Google уволились в знак протеста, еще 4000 подписали петицию с просьбой отказаться от контракта с военными. Более 1000 видных ученых в области ИИ, этики и информационных технологий написали открытое письмо с просьбой к Google прекратить работы над проектом и поддержать международный договор по запрету автономного оружия.
2. Предвзятость разработчиков алгоритма
Даже если авторы алгоритма машинного обучения не хотят приносить вред, чаще всего они все-таки хотят извлечь выгоду. Иными словами, далеко не все алгоритмы работают на благо общества, очень многие работают на благо своих создателей. Это часто можно наблюдать в области медицины — важнее не вылечить, а порекомендовать лечение подороже.
На самом деле иногда и само общество не заинтересовано в том, чтобы полученный алгоритм был образцом морали. Например, есть компромисс между скоростью движения транспорта и смертностью на дорогах. Можно запрограммировать беспилотные автомобили так, чтобы они ездили со скоростью не более 20 км/ч. Это позволило бы практически гарантированно свести количество смертей к нулю, но жить в больших городах стало бы затруднительно.
3. Параметры системы могут не включать этику
По умолчанию компьютеры не имеют никакого представления о том, что такое этика. Представьте, что мы просим алгоритм сверстать бюджет страны с целью «максимизировать ВВП / производительность труда / продолжительность жизни» и забыли заложить в модель этические ограничения. Алгоритм может прийти к выводу, что выделять деньги на детские дома / хосписы / защиту окружающей среды совершенно незачем, ведь это не увеличит ВВП — по крайней мере, прямо.
И хорошо, если алгоритму поручили только составление бюджета. Потому что при более широкой постановке задачи может выйти, что самый выгодный способ повысить среднюю производительность труда — это избавиться от всего неработоспособного населения.
Выходит, что этические вопросы должны быть среди целей системы изначально.
4. Этику сложно описать формально
С этикой одна проблема — ее сложно формализовать. Во-первых, этика довольно быстро меняется со временем. Например, по таким вопросам, как права ЛГБТ и межрасовые / межкастовые браки, мнение может существенно измениться за десятилетия.
Во-вторых, этика отнюдь не универсальна: она отличается даже в разных группах населения одной страны, не говоря уже о разных странах. Например, в Китае контроль за перемещением граждан при помощи камер наружного наблюдения и распознавания лиц считается нормой. В других странах отношение к этому вопросу может быть иным и зависеть от обстановки.
Также этика может зависеть от политического климата. Например, борьба с терроризмом заметно изменила во многих странах представление о том, что этично, а что не очень — и произошло это невероятно быстро.
5. Машинное обучение влияет на людей
Представьте систему на базе машинного обучения, которая советует вам, какой фильм посмотреть. На основе ваших оценок другим фильмам и путем сопоставления ваших вкусов со вкусами других пользователей система может довольно надежно порекомендовать фильм, который вам очень понравится.
Но при этом система будет со временем менять ваши вкусы и делать их более узкими. Без системы вы бы время от времени смотрели и плохие фильмы, и фильмы непривычных жанров. А так, что ни фильм — то в точку. В итоге вы перестаете быть «экспертами по фильмам», а становитесь только потребителем того, что дают.
Интересно еще и то, что мы даже не замечаем, как алгоритмы нами манипулируют. Пример с фильмами не очень страшный, но попробуйте подставить в него слова «новости» и «пропаганда»…
6. Ложные корреляции
Ложная корреляция — это когда не зависящие друг от друга вещи ведут себя очень похоже, из-за чего может возникнуть впечатление, что они как-то связаны. Например, потребление маргарина в США явно зависит от количества разводов в штате Мэн, не может же статистика ошибаться, правда?
Конечно, живые люди на основе своего богатого жизненного опыта подозревают, что маргарин и разводы вряд ли связаны напрямую. А вот математической модели об этом знать неоткуда, она просто заучивает и обобщает данные.
Известный пример: программа, которая расставляла больных в очередь по срочности оказания помощи, пришла к выводу, что астматикам с пневмонией помощь нужна меньше, чем людям с пневмонией без астмы. Программа посмотрела на статистику и пришла к выводу, что астматики не умирают, поэтому приоритет им незачем. А на самом деле такие больные не умирали потому, что тут же получали лучшую помощь в медицинских учреждениях в связи с очень большим риском.
7. Петли обратной связи
Хуже ложных корреляций только петли обратной связи. Это когда решения алгоритма влияют на реальность, что, в свою очередь, еще больше убеждает алгоритм в его точке зрения.
Например, программа предупреждения преступности в Калифорнии предлагала отправлять больше полицейских в черные кварталы, основываясь на уровне преступности — количестве зафиксированных преступлений. А чем больше полицейских машин в квартале, тем чаще жители сообщают о преступлениях (просто есть кому сообщить), чаще сами полицейские замечают правонарушения, больше составляется протоколов и отчетов, — в итоге формально уровень преступности возрастает. Значит, надо отправить еще больше полицейских, и далее по нарастающей.
8. «Грязные» и «отравленные» исходные данные
Результат обучения алгоритма сильно зависит от исходных данных, на основе которых ведется обучение. Данные могут оказаться плохими, искаженными — это может происходить как случайно, так и по злому умыслу (в последнем случае это обычно называют «отравлением»).
Вот пример неумышленных проблем с исходными данными: если в качестве обучающей выборки для алгоритма по найму сотрудников использовать данные, полученные из компании с расистскими практиками набора персонала, то алгоритм тоже будет с расистским уклоном.
В Microsoft однажды учили чат-бота общаться в Twitter’е, для чего предоставили возможность побеседовать с ним всем желающим. Лавочку пришлось прикрыть менее чем через сутки, потому что набежали добрые интернет-пользователи и быстро обучили бота материться и цитировать «Майн Кампф».
«Tay» went from «humans are super cool» to full nazi in <24 hrs and I’m not at all concerned about the future of AI pic.twitter.com/xuGi1u9S1A
— gerry (@geraldmellor) March 24, 2016
Пример умышленного отравления машинного обучения: в лаборатории по анализу компьютерных вирусов математическая модель ежедневно обрабатывает в среднем около миллиона файлов, как чистых, так и вредоносных. Ландшафт угроз постоянно меняется, поэтому изменения в модели в виде обновлений антивирусных баз доставляются в антивирусные продукты на стороне пользователей.
Злоумышленник может постоянно генерировать вредоносные файлы, очень похожие на какой-то чистый, и отправлять их в лабораторию. Граница между чистыми и вредоносными файлами будет постепенно стираться, модель будет «деградировать». И в итоге модель может признать оригинальный чистый файл зловредом — получится ложное срабатывание.
Поэтому в «Лаборатории Касперского» многоуровневый подход к защите: мы не полагаемся только на машинное обучение, живые люди — антивирусные эксперты — обязательно присматривают за тем, что делает машина.
9. Взлом машинного обучения
Отравление — это воздействие на процесс обучения. Но обмануть можно и уже готовую, исправно работающую математическую модель, если знать, как она устроена. Например, группе исследователей удалось научиться обманывать алгоритм распознавания лиц с помощью специальных очков, вносящих минимальные изменения в картинку и тем самым кардинально меняющих результат.
Даже там, где, казалось бы, нет ничего сложного, машину легко обмануть неведомым для непосвященного способом.

Первые три знака распознаются как «Ограничение скорости 45», а последний — как знак «STOP»
Причем для того, чтобы математическая модель машинного обучения признала капитуляцию, необязательно вносить существенные изменения — достаточно минимальных, невидимых человеку правок.

Если к панде слева добавить минимальный специальный шум, то получим гиббона с потрясающей уверенностью
Пока человек умнее большинства алгоритмов, он может обманывать их. Представьте себе, что в недалеком будущем машинное обучение будет анализировать рентгеновские снимки чемоданов в аэропорту и искать оружие. Умный террорист сможет положить рядом с пистолетом фигуру особенной формы и тем самым «нейтрализовать» пистолет.
Кто виноват и что делать
В 2016 году Рабочая группа по технологиям больших данных при администрации Обамы выпустила отчет, предупреждающий о том, что в алгоритмы, принимающие автоматизированные решения на программном уровне, может быть заложена дискриминация. Также в отчете содержался призыв создавать алгоритмы, следующие принципу равных возможностей.
Но сказать-то легко, а что же делать? С этим не все так просто.
Во-первых, математические модели машинного обучения тяжело тестировать и подправлять. Если обычные программы мы читаем по шагам и научились их тестировать, то в случае машинного обучения все зависит от размера контрольной выборки, и она не может быть бесконечной.
К примеру, приложение Google Photo распознавало и помечало людей с черным цветом кожи как горилл. И как быть? За три года Google не смогли придумать ничего лучше, чем запретить помечать вообще любые объекты на фотографиях как гориллу, шимпанзе и обезьяну, чтобы не допускать повторения ошибки.
Во-вторых, нам сложно понять и объяснить решения машинного обучения. Например, нейронная сеть как-то расставила внутри себя весовые коэффициенты, чтобы получались правильные ответы. А почему они получаются именно такими и что сделать, чтобы ответ поменялся?
Исследование 2015 года показало, что женщины гораздо реже, чем мужчины, видят рекламу высокооплачиваемых должностей, которую показывает Google AdSense. Сервис доставки в тот же день от Amazon зачастую недоступен в черных кварталах. В обоих случаях представители компаний затруднились объяснить такие решения алгоритмов.
Винить вроде бы некого, остается принимать законы и постулировать «этические законы робототехники». В Германии как раз недавно, в мае 2018 года, сделали первый шаг в этом направлении и выпустили свод этических правил для беспилотных автомобилей. Среди прочего, в нем есть такие пункты:
- Безопасность людей — наивысший приоритет по сравнению с уроном животным или собственности.
- В случае неизбежной аварии не должно быть никакой дискриминации, ни по каким факторам недопустимо различать людей.
Но что особенно важно в нашем контексте:
- Автоматические системы вождения становятся этическим императивом, если системы вызывают меньше аварий, чем водители-люди.
Очевидно, что мы будем все больше и больше полагаться на машинное обучение — просто потому, что оно в целом будет справляться со многими задачами лучше людей. Поэтому важно помнить о недостатках и возможных проблемах, стараться все предусмотреть на этапе разработки систем — и не забывать присматривать за результатом работы алгоритмов на случай, если что-то все же пойдет не так.
Привет.
Невольно о теме предвзятости искусственного интеллекта заставила вспомнить полемика, запущенная в Совете Федерации, там предложили придумать способы, как обжаловать решения AI, сделанные относительно граждан, и как сделать их прозрачными. Разработчики искренне возмущены этим и считают, что создают если не идеальные, то безопасные системы с непредвзятыми суждениями и никакого регулирования не нужно вовсе. А скорее нужно объяснять, что AI безопасен. Ошибка суждения разработчиков в том, что они искренне считают созданные алгоритмы безопасными и правильными, не понимая, что, скармливая им большие объемы данных, они не могут регулировать их качество, что изначально создает ошибки, которые нельзя исправить.
Может ли человек быть дискриминирован алгоритмами искусственного интеллекта? Однозначный ответ возможен только один – да, может. В Америке, где исторически используется большое число компьютерных систем, помогающих анализировать данные, огромное количество примеров, показывающих такие ошибки. В современном американском обществе трудно вообразить вопрос, с каким цветом кожи люди чаще совершают преступления. Думаю, что у вас в голове уже есть стереотип и вы произнесли ответ, который не требует объяснений. И при этом вы не считаете, что дискриминируете кого-то, вам кажется, что вы правы, так как видели выступления BLM, лутинг, или, по-простому, грабежи. В стране, где насаждают политкорректность, такие вопросы нельзя задавать и тем более так думать. Чем-то напоминает ситуацию с продуктами в Советском Союзе, на полках магазинов шаром покати, а домашние холодильники ломятся от снеди.
Двойственность нашего сознания сформирована обществом, человек умеет притворяться и приспосабливаться, этого начисто лишены компьютерные алгоритмы, они однозначны в своих суждениях. В Лос-Анджелесе департамент полиции запустил проект PredPol, в котором предсказываются на основании данных о совершенных преступлениях районы, в которые нужно отправить большее число патрулей, чтобы предотвратить новые инциденты.
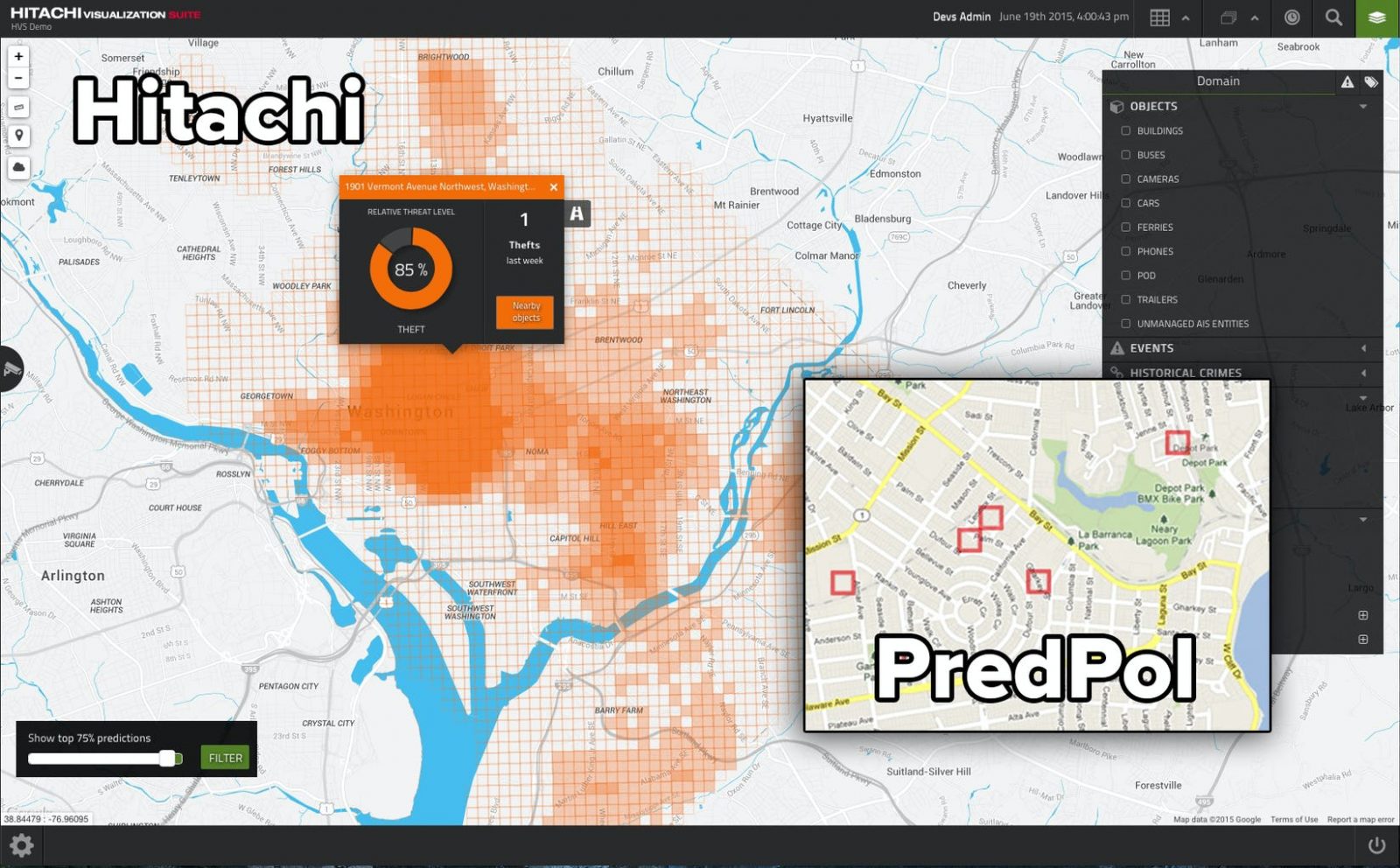
Для полиции не стало неожиданностью, что система моментально обозначила в качестве проблемных районов те, где преимущественно живут чернокожие люди. Вот даже сейчас я невольно написал «чернокожие люди», словно в слове «негры» содержится что-то неправильное, хотя контекст этого слова испорчен исключительно в Америке. Дискриминация по цвету кожи — одна из болезненных тем для Америки, и то, что система работает именно так, возмутило многих людей. И тут мы сталкиваемся сразу с несколькими ключевыми проблемами работы AI-алгоритмов, и они лежат вовсе не в плоскости технологий. Людям зачастую не нравятся те результаты, что показывают AI-алгоритмы, так как они противоречат их вере или убеждениям. Например, один из активистов, пропагандирующих очередной гендер для человечества, искренне возмущался тем, что его поддерживает меньше сотни человек в стране с населением в триста миллионов. Ему не нравились результаты статистики, хотя в них нет предмета для споров, так как это цифра и ничего больше.
Мусор на входе означает мусор на выходе. И тут мы подходим к ключевой проблеме любого алгоритма, к тому, какие данные скармливают системе для анализа. В истории с полицией в Лос-Анджелесе это были настоящие полицейские отчеты, и понятно, что в неблагополучных районах число преступлений было большим. Система, отправляя большее число патрулей в такие районы, автоматически приводила к росту зарегистрированных правонарушений, что логично. Чем больше машин полиции в районе, тем больше вероятность зафиксировать правонарушение. Сформировалась положительная обратная связь, которая не доказывает, что система работает правильно, она сама формирует конечный результат.
Другая система, используемая в Америке, называется COMPAS, она позволяет оценить вероятность повторного правонарушения. Среди чернокожих граждан система предсказывала в два раза больше случаев рецидивизма, при этом они оказывались ложными. Проблема тут ровно та же, ошибочные суждения, заложенные в изначальный объем данных, что скормили системе.
Весь наш мир построен на предвзятости, и исключений из этого правила нет. Когда помощь просит молодая и красивая девушка, то большинство мужчин готовы откликнуться и помочь. Совсем другое дело, когда в помощи нуждается человек, который нам по каким-то причинам неприятен. Справедливости нет и не может быть, идеального общества роботов не существует. И наше право на эмоции формирует другое восприятие мира, которое невозможно изменить.
Огромной областью для будущих разработок является очистка данных для систем машинного обучения, чтобы итоговый результат совпадал с нашими представлениями о прекрасном. Например, число прогнозируемых преступлений для людей с разным цветом кожи было одинаковым — над этой задачей в США бьется несколько групп энтузиастов. Но мы с вами понимаем, что такая задача выглядит идеалистичной и не реализуемой на практике. Дискриминация по цвету кожи реальна, и она накладывает свой отпечаток на жизни людей, зачастую толкает кого-то на преступления. И системы в лучшем случае могут это показать, но не исправить этот порок общества.
Если мы не можем решить задачу с исходными данными, это значит, что нужно уметь манипулировать итоговым результатом. Как минимум понимать, как он сформирован и какой была логика алгоритма. И вот тут возникает новый пласт проблем, зачастую машинное обучение не дает нам алгоритм и не показывает логику решения, а просто сообщает результат. Черный ящик — вот как выглядит для нас алгоритм, а результат предлагается принять на веру. И это то, что заботит разработчиков, ведь если общество обяжет их объяснять, как работают алгоритмы, раскладывать их на составляющие, то прогресс в этой области замедлится. Огромная часть времени будет уходить на анализ результатов, изучение того, как работают алгоритмы, и это то, чего большинство просто не делает.
Чем-то мне это напоминает голливудские фильмы, в которых главные герои что-то изучают, куда-то бездумно идут и потом начинаются проблемы. Они просто жмут кнопки, предназначение которых им неизвестно, если есть кнопка, то на нее нужно обязательно нажать. Разработчики AI-алгоритмов очень похожи на таких героев, они ровно так же не задумываются об анализе результата своей работы, свято верят в алгоритмы, которые написаны верно, и откидывают размышления об изначальном объеме данных.
Посмотрите на тот же «Яндекс» и их сервис такси. Любой вопрос о том, как получена цена на поездку, натыкается на заученный ответ: у нас умный алгоритм, он анализирует множество данных и выдает справедливую цену для каждого. Но любая попытка узнать, как именно работает этот алгоритм и не подыгрывает ли он «Яндексу», чтобы корпорация зарабатывала больше, натыкается на то, что никто этого не знает. То есть мы покупаем поездку на такси и нам предлагают заранее согласиться, что цена справедлива.
Представьте на минутку, что вы приходите в продуктовый магазин, где покупаете сахар. Берете пакет сахара, его цена может различаться. Но помимо цены также различается и то, сколько сахара в пакете, каждый раз это должно стать сюрпризом. Примерно так и работает «Яндекс.Такси» сегодня, регулируя не только стоимость условного сахара, но и то, сколько его в пакете. Поле для злоупотреблений тут огромное, но главное, что есть алгоритм, на который можно все свалить. И тут есть еще одна проблема, которую важно понимать, — люди перекладывают на алгоритм всякую ответственность, хотя именно люди его создали и должны отвечать за то, как он работает.
Очарованность AI-алгоритмами в обществе будет постепенно проходить, мы научимся их контролировать, равно как и заставим разработчиков объяснять, что и как работает. Например, производители, которые создают оксиметры, столкнулись с возмущением пользователей в ряде стран, когда пользователи жаловались, что в инструкции отмечено отличие данных для чернокожих и людей с белой кожей. Принцип работы такого прибора прост — он просвечивает кожу и оценивает кровоток. В зависимости от прозрачности, читай — цвета кожи, алгоритм подсчета различается, и это нужно учитывать при оценке результатов. Никакой дискриминации здесь нет и в помине, различия лежат в физическом мире, и они реальны. Но в рамках политической повестки люди бездумно протестуют против различий для черных и белых, словно их нет в реальном мире и они выдуманы. Наш мир сегодня заигрался в корректность, и AI-алгоритмы хотят ломать на другом конце, иметь возможность вмешиваться в результаты их работы, чтобы они были политкорректными.
Полезность AI-алгоритмов признают многие, но одновременно с этим говорят о том, что люди не подготовлены к тем результатам, которые они дают, они могут их шокировать. И поэтому в таких системах нужно вводить возможность ручного управления, давать человеку вмешаться в итоговый результат. И тут могут быть как правильные, так и неверные решения.
Приведу пример с системами видеонаблюдения на дорогах Москвы. Когда вы попадаете под камеру, нарушаете рядность или скоростной режим, то вам прилетает штраф. Формально число штрафов, что должны получать водители, в несколько раз больше, чем то количество, что выписывается. Почему так? Это вопрос спокойствия в обществе, водителей постепенно приучают к тому, что нужно соблюдать правила дорожного движения, не пытаются создать шок в обществе. И такой подход работает, число нарушений постепенно становится меньше, люди чаще соблюдают скоростной режим, начинают водить машину иначе.
Тема AI-алгоритмов популярна, и кажется, что они становятся палочкой-выручалочкой. К сожалению, их возможности сильно преувеличивают. Есть области, в которых AI-алгоритмы показывают неплохие результаты, так как первоначальные данные представлены правильно и в большом объеме. Но в любом случае наши предпочтения и пороки влияют на AI-алгоритмы и данные, искажают итоговый результат. Я не верю в то, что тысячи лет цивилизации неожиданно изменят AI-алгоритмы, которые сделают нас другими. Ложь, поиски личной выгоды, манипуляция данными и тому подобные проявления человеческой природы никуда не исчезнут. Поэтому главной задачей становится понимание того, как работают такие алгоритмы, возможность откатить назад их решения. Иначе наш мир грозит стать очень странным и подчас страшным местом.