Построение
математической модели — это скорее
искусство, чем наука, и, прежде всего,
требует глубоких знаний предметной
области. Социально-экономические системы
имеют чрезвычайно сложную структуру,
со многими явными и неявными взаимосвязями
между элементами системы, подвержены
влиянию многих скрытых факторов,
относятся к классу так называемых
больших систем. Стечением
времени меняются не только их
характеристики, учитываемые в модели
в виде отдельных параметров, но и
структура самих уравнений, которые
описывают процесс. Для их адекватного
описания требуется соответствующий
математический аппарат. Однако, даже
самые сложные математические методы
не в состоянии описать реальную систему
во всех ее деталях, да это и не нужно.
Модель не должна быть слишком сложной.
Излишняя детализация и учет второстепенных
факторов затрудняет
исследование
и не дает существенной информации об
изучаемой системе. Если модель слишком
сложна, то ее трудно использовать и
интерпретировать на практике.
Относительная
простота — важная характеристика
удачно построенной модели.
С другой стороны, слишком упрощенная
модель не будет адекватно описывать
реальную систему. Таким образом, сложность
модели должна соответствовать сложности
изучаемого экономического объекта.
В связи
с этим возникает необходимость
формулировки некоторых разумных
упрощающих гипотез (предположений),
исключения из анализа второстепенных
факторов и т. п., с тем, чтобы была
возможность описать процесс математически.
При этом существенные для
данного
социально-экономического процесса
характерные черты
должны
быть учтены в модели в соответствии с
поставленной целью исследования.
Другой
характерной проблемой, с которой
сталкивается эконометрист, является
то, что часто приходится довольствоваться
неточными
данными,
которые имеются в наличии и быстро
устаревают. Этих данных не всегда
хватает, а провести управляемый
эксперимент с целью получения
дополнительной информации невозможно.
В подобном случае целесообразно сочетание
количественных методов с привлечением
экспертных знаний и суждений.
Таким
образом, при создании эконометрической
модели возникают следующие вопросы.
1.
Какую модель желательно построить —
статическую или динамическую (с
учетом фактора времени), нелинейную или
линеаризованную? Как учесть влияние
внешней среды (возмущений)? (Ответ на
эти вопросы определяет желаемую точность
и сложность модели, выбор адекватного
математического аппарата и т. д.)
2.
Достаточно
ли имеющихся данных, необходимых для
построения адекватной модели,
насколько они достоверны? Существует
ли возможность получения дополнительной
информации, если это необходимо? Следует
ли привлечь экспертную информацию?
3. Как
оценить качество модели, т. е. определить,
насколько адекватно (правильно) она
описывает поведение реального объекта?
В
рамках эконометрического подхода
существует мощный арсенал средств,
который включает многие современные
эффективные
математические методы,
такие, например, как аппарат
нейронных сетей,
и разработанные на их основе компьютерные
технологии, в известной степени помогающие
справиться с этими проблемами. Но
решающая
роль принадлежит специалисту —
эконометристу.
Окончательный успех зависит от его
способности к неформальному анализу
проблемной ситуации, адекватной оценке
возможностей современных эконометрических
методов, от их правильного применения
и интерпретации полученных результатов.
Построив
удачную математическую модель и оценив
ее количественно с использованием
эконометрических методов, экономист-аналитик
получает в распоряжение эффективнейшее
средство анализа и прогноза, а
управляющий-практик — инструмент для
обоснования управленческих решений.
Такие модели широко применяются на
практике.
Практически
величина y
складывается из двух слагаемых:
![]()
,
где
![]()
— фактическое
значение, результат признака;
![]()
— теоретическое
значение результата признака, найденное
из математической модели или уравнения
регрессии;
![]()
— СВ, характерное
отклонение реального значения результата
признака от теоретического.
СВ
![]()
называется
возмущением. Она включает влияние
неучтённых в модели факторов, случайных
ошибок и особенно измерения. Её присутствие
в модели порождено тремя источниками:
-
спецификацией
модели; -
выборочным
характером исходных данных; -
особенностями
измерения.
От правильно
выбранной спецификации модели зависит
величина случайных ошибок: они тем
меньше, чем больше теоретические
значения результативного признака
![]()
подходит к фактическим данным y.
К ошибкам спецификации
будут относиться не только неправильный
выбор той или иной математической
функции для
,
но и недоучет в УР какого-либо существенного
фактора (например, использование парной
регрессии вместо множественной).
Наряду с ошибками
спецификации могут иметь место ошибки
выборки (неоднородность данных в исходной
статистической совокупности). Если
совокупность неоднородна, то УР не имеет
практического смысла.
Для получения
хорошего результата обычно исключают
из совокупности единицы с аномальными
значениями исследуемых признаков, то
есть результаты регрессии представляют
собой выборочные характеристики.
Наибольшую опасность
в практическом использовании методов
регрессии представляют ошибки
измерения.
Если ошибки спецификации можно уменьшить,
изменяя форму модели, а ошибки выборки
– увеличивая объём исходных данных, то
ошибки измерения практически сводят
на нет все усилия по количественной
оценке связи между признаками. Особенно
велика роль ошибок измерения при
исследовании на макроуровне.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
04.08.2019218.11 Кб0kv.doc
- #
- #
- #
В этой главе мы сконцентрируемся на том, как при помощи эконометрики получать корректные ответы на вопросы о причинно-следственных связях. Чтобы это сделать, нужно верно специфицировать вашу модель. Под верной спецификацией будем понимать такую, которая позволяет получить состоятельные оценки коэффициентов при интересующих вас переменных. А также получить состоятельные стандартные ошибки для тестирования гипотез.
Глава будет устроена так: мы будем перечислять типичные ловушки, которые приводят к неверной спецификации. Далее для каждой такой ловушки мы будем указывать возможные способы избежать её и устранить проблему.
В каких-то случаях мы будем опираться на уже знакомые вам концепции и понятия. В некоторых же ситуациях мы будем, наоборот, ссылаться на более продвинутые методы и модели, с которыми нам ещё предстоит разобраться в следующих главах учебника (надеемся, это станет для вас дополнительной мотивацией все-таки дочитать его до конца).
Напомним, что в предыдущей главе мы сформулировали два важных определения:
- Эндогенный регрессор — регрессор, который коррелирован со случайными ошибками модели.
- Экзогенный регрессор — регрессор, который не коррелирован со случайными ошибками модели.
Кроме того, в той же главе мы выяснили, что для состоятельности оценки коэффициента при переменной необходимо, чтобы эта переменная была экзогенной (точнее, необходимо выполнение предпосылки №4 линейной регрессионной модели со стохастическими регрессорами из главы 6). Если же регрессор эндогенный, результаты вашего моделирования нельзя интерпретировать в терминах причинно-следственных связей. Нарушение предпосылки №4 об экзогенности регрессора — это самая частая проблема при проведении прикладных исследований на пространственных и панельных данных. Поэтому важно понимать, в каких случаях вам следует опасаться её возникновения. Есть следующие типичные ситуации:
- Эндогенность регрессора из-за пропуска существенной переменной. В качестве важного частного случая тут также следует указать проблему эндогенности из-за самоотбора.
- Эндогенность регрессора из-за выбора неверной функциональной формы связи.
- Эндогенность регрессора из-за двусторонней причинно-следственной связи.
- Эндогенность регрессора из-за ошибок измерения.
В последующих четырех параграфах главы мы подробно обсудим каждый из этих пунктов. В пятом параграфе мы поговорим о других (помимо эндогенности) проблемах, которые могут делать выводы эконометрических исследований необоснованными. В каждом случае мы также укажем основные возможные пути преодоления перечисленных трудностей.
-
7.1. Эндогенность из-за пропуска существенной переменной
-
7.2. Эндогенность из-за выбора неверной функциональной формы связи
-
7.3. Эндогенность из-за двусторонней причинно-следственной связи
-
7.4. Эндогенность из-за ошибок измерения
-
7.5. Другие (помимо эндогенности) потенциальные угрозы обоснованности выводов эконометрического исследования
-
7.6. Чек-лист эконометриста
-
Задания для самостоятельного решения
Набор инструментов Пространственная статистика предоставляет эффективные инструменты количественного анализа пространственных структурных закономерностей. Инструмент Анализ горячих точек, например, поможет найти ответы на следующие вопросы:
- Есть ли в США места, где постоянно наблюдается высокая смертность среди молодежи?
- Где находятся «горячие точки» по местам преступлений, вызовов 911 (см. рисунок ниже) или пожаров?
- Где находятся места, в которых количество дорожных происшествий превышает обычный городской уровень?

Каждый из вопросов спрашивает «где»? Следующий логический вопрос для такого типа анализа – «почему»?
- Почему в некоторых местах США наблюдается повышенная смертность молодежи? Какова причина этого?
- Можем ли мы промоделировать характеристики мест, на которые приходится больше всего преступлений, звонков в 911, или пожаров, чтобы помочь сократить эти случаи?
- От каких факторов зависит повышенное число дорожных происшествий? Имеются ли какие-либо возможности для снижения числа дорожных происшествий в городе вообще, и в особо неблагополучных районах в частности?
Инструменты в наборе инструментов Моделирование пространственных отношений помогут вам ответить на вторую серию вопросов «почему». К этим инструментам относятся Метод наименьших квадратов и Географически взвешенная регрессия.
Пространственные отношения
Регрессионный анализ позволяет вам моделировать, проверять и исследовать пространственные отношения и помогает вам объяснить факторы, стоящие за наблюдаемыми пространственными структурными закономерностями. Вы также можете захотеть понять, почему люди постоянно умирают молодыми в некоторых регионах страны, и какие факторы особенно влияют на особенно высокий уровень диабета. При моделирование пространственных отношений, однако, регрессионный анализ также может быть пригоден для прогнозирования. Моделирование факторов, которые влияют на долю выпускников колледжей, на пример, позволяют вам сделать прогноз о потенциальной рабочей силе и их навыках. Вы также можете использовать регрессионный анализ для прогнозирования осадков или качества воздуха в случаях, где интерполяция невозможна из-за малого количества станций наблюдения (к примеру, часто отсутствую измерительные приборы вдоль горных хребтов и в долинах).
МНК – наиболее известный метод регрессионного анализа. Это также подходящая отправная точка для всех способов пространственного регрессионного анализа. Данный метод позволяет построить глобальную модель переменной или процесса, которые вы хотите изучить или спрогнозировать (уровень смертности/осадки). Он создает уравнение регрессии, отражающее происходящий процесс. Географически взвешенная регрессия (ГВР) — один из нескольких методов пространственного регрессионного анализа, все чаще использующегося в географии и других дисциплинах. Метод ГВР (географически взвешенная регрессия) создает локальную модель переменной или процесса, которые вы прогнозируете или изучаете, применяя уравнение регрессии к каждому пространственному объекту в наборе данных. При подходящем использовании, эти методы являются мощным и надежным статистическим средством для проверки и оценки линейных взаимосвязей.
Линейные взаимосвязи могут быть положительными или отрицательными. Если вы обнаружили, что количество поисково-спасательных операций увеличивается при возрастании среднесуточной температуры, такое отношение является положительным; имеется положительная корреляция. Другой способ описать эту положительную взаимосвязь — сказать, что количество поисково-спасательных операций уменьшается при уменьшении среднесуточной температуры. Соответственно, если вы установили, что число преступлений уменьшается при увеличении числа полицейских патрулей, данное отношение является отрицательным. Также, можно выразить это отрицательное отношение, сказав, что количество преступлений увеличивается при уменьшении количества патрулей. На рисунке ниже показаны положительные и отрицательные отношения, а также случаи, когда две переменные не связаны отношениями:

Корреляционные анализы, и связанные с ними графики, отображенные выше, показывают силу взаимосвязи между двумя переменными. С другой стороны, регрессионные анализы дают больше информации: они пытаются продемонстрировать степень, с которой 1 или более переменных потенциально вызывают положительные или негативные изменения в другой переменной.
Применения регрессионного анализа
Регрессионный анализ может использоваться в большом количестве приложений:
- Моделирование числа поступивших в среднюю школу для лучшего понимания факторов, удерживающих детей в том же учебном заведении.
- Моделирование дорожных аварий как функции скорости, дорожных условий, погоды и т.д., чтобы проинформировать полицию и снизить несчастные случаи.
- Моделирование потерь от пожаров как функции от таких переменных как степень вовлеченности пожарных департаментов, время обработки вызова, или цена собственности. Если вы обнаружили, что время реагирования на вызов является ключевым фактором, возможно, существует необходимость создания новых пожарных станций. Если вы обнаружили, что вовлеченность – главный фактор, возможно, вам нужно увеличить оборудование и количество пожарных, отправляемых на пожар.
Существует три первостепенных причины, по которым обычно используют регрессионный анализ:
- Смоделировать некоторые явления, чтобы лучше понять их и, возможно, использовать это понимание для оказания влияния на политику и принятие решений о наиболее подходящих действиях. Основная цель — измерить экстент, который при изменениях в одной или более переменных связанно вызывает изменения и в другой. Пример. Требуется понять ключевые характеристики ареала обитания некоторых видов птиц (например, осадки, ресурсы питания, растительность, хищники) для разработки законодательства, направленного на защиту этих видов.
- Смоделировать некоторые явления, чтобы предсказать значения в других местах или в другое время. Основная цель — построить прогнозную модель, которая является как устойчивой, так и точной. Пример: Даны прогнозы населения и типичные погодные условия. Каким будет объем потребляемой электроэнергии в следующем году?
- Вы также можете использовать регрессионный анализ для исследования гипотез. Предположим, что вы моделируете бытовые преступления для их лучшего понимания и возможно, вам удается внедрить политические меры, чтобы остановить их. Как только вы начинаете ваш анализ, вы, возможно, имеете вопросы или гипотезы, которые вы хотите проверить:
- «Теория разбитого окна» указывает на то, что испорченная общественная собственность (граффити, разрушенные объекты и т.д.) притягивает иные преступления. Имеется ли положительное отношение между вандализмом и взломами в квартиры?
- Имеется ли связь между нелегальным использованием наркотических средств и взломами в квартиры (могут ли наркоманы воровать, чтобы поддерживать свое существование)?
- Совершаются ли взломы с целью ограбления? Возможно ли, что будет больше случаев в домохозяйствах с большей долей пожилых людей и женщин?
- Люди больше подвержены риску ограбления, если они живут в богатой или бедной местности?
Вы можете использовать регрессионный анализ, чтобы исследовать эти взаимосвязи и ответить на ваши вопросы.
Термины и концепции регрессионного анализа
Невозможно обсуждать регрессионный анализ без предварительного знакомства с основными терминами и концепциями, характерными для регрессионной статистики:
Уравнение регрессии. Это математическая формула, применяемая к независимым переменным, чтобы лучше спрогнозировать зависимую переменную, которую необходимо смоделировать. К сожалению, для тех ученых, кто думает, что х и у это только координаты, независимая переменная в регрессионном анализе всегда обозначается как y, а зависимая – всегда X. Каждая независимая переменная связана с коэффициентами регрессии, описывающими силу и знак взаимосвязи между этими двумя переменными. Уравнение регрессии может выглядеть следующим образом (у – зависимая переменная, Х – независимые переменные, β – коэффициенты регрессии), ниже приводится описание каждого из этих компонентов уравнения регрессии):

- Зависимая переменная (y) – это переменная, описывающая процесс, который вы пытаетесь предсказать или понять (бытовые кражи, осадки). В уравнении регрессии эта переменная всегда находится слева от знака равенства. В то время, как вы можете использовать регрессию для предсказания зависимой величины, вы всегда начинаете с набора хорошо известных у-значений и используете их для калибровки регрессионной модели. Известные у-значения часто называют наблюдаемыми величинами.
- Независимые переменные (X) это переменные, используемые для моделирования или прогнозирования значений зависимых переменных. В уравнении регрессии они располагаются справа от знака равенства и часто называются независимыми переменными. Зависимая переменная – это функция независимых переменных. Если вас интересует прогнозирование годового оборота определенного магазина, вы можете включить в модель независимые переменные, отражающие, например, число потенциальных покупателей, расстояние до конкурирующих магазинов, заметность магазина и структуру спроса местных жителей.
- Коэффициенты регрессии (β) – это коэффициенты, которые рассчитываются в результате выполнения регрессионного анализа. Вычисляются величины для каждой независимой переменной, которые представляют силу и тип взаимосвязи независимой переменной по отношению к зависимой. Предположим, что вы моделируете частоту пожаров как функцию от солнечной радиации, растительного покрова, осадков и экспозиции склона. Вы можете ожидать положительную взаимосвязь между частотой пожаров и солнечной радиацией (другими словами, чем больше солнца, тем чаще встречаются пожары). Если отношение положительно, знак связанного коэффициента также положителен. Вы можете ожидать негативную связь между частотой пожаров и осадками (другими словами, для мест с большим количеством осадков характерно меньше лесных пожаров). Коэффициенты отрицательных отношений имеют знак минуса. Когда взаимосвязь сильная, значения коэффициентов достаточно большие (относительно единиц независимой переменной, с которой они связаны). Слабая взаимосвязь описывается коэффициентами с величинами около 0; β0 – это отрезок, отсекаемый линией регрессии.Он представляет ожидаемое значение зависимой величины, если все независимые переменные равны 0.
P-значения. Большинство регрессионных методов выполняют статистический тест для расчета вероятности, называемой р-значением, для коэффициентов, связанной с каждой независимой переменной. Нулевая гипотеза данного статистического теста предполагает, что коэффициент незначительно отличается от нуля (другими словами, для всех целей и задач, коэффициент равен нулю, и связанная независимая переменная не может объяснить вашу модель). Маленькие величины р-значений отражают маленькие вероятности и предполагают, что коэффициент действительно важен для вашей модели со значением, существенно отличающимся от 0 (другими словами, маленькие величины р-значений свидетельствуют о том, что коэффициент не равен 0). Вы бы сказали, что коэффициент с р-значением, равным 0,01, например, статистически значимый для 99 % доверительного интервала; связанные переменные являются эффективным предсказателем. Переменные с коэффициентами около 0 не помогают предсказать или смоделировать зависимые величины; они практически всегда удаляются из регрессионного уравнения, если только нет веских причин сохранить их.
R
2/R-квадрат: Статистические показатели составной R-квадрат и скорректированный R-квадрат вычисляются из регрессионного уравнения, чтобы качественно оценить модель. Значение R-квадрат лежит в пределах от 0 до 100 процентов. Если ваша модель описывает наблюдаемые зависимые переменные идеально, R-квадрат равен 1.0 (и вы, несомненно, сделали ошибку; возможно, вы использовали модификацию величины у для предсказания у). Вероятнее всего, вы увидите значения R-квадрат в районе 0,49, например, вы можете интерпретировать подобный результат как «Это модель объясняет 49 % вариации зависимой величины». Чтобы понять, как работает R-квадрат, постройте график, отражающий наблюдаемые и оцениваемые значения у, отсортированные по оцениваемым величинам. Обратите внимание на количество совпадений. Этот график визуально отображает, насколько хорошо вычисленные значения модели объясняют изменения наблюдаемых значений зависимых переменных. Просмотрите иллюстрацию. Скорректированный R-квадрат всегда немного меньше, чем множественный R-квадрат, т.к. он отражает всю сложность модели (количество переменных) и связан с набором исходных данных. Следовательно, скорректированный R-квадрат является более точной мерой для оценки результатов работы модели.
Невязки: Существует необъяснимое количество зависимых величин, представленных в уравнении регрессии как случайные ошибки ε. См. рисунок. Известные значения зависимой переменной используются для построения и настройки модели регрессии. Используя известные величины зависимой переменной (Y) и известные значений для всех независимых переменных (Хs), регрессионный инструмент создаст уравнение, которое предскажет те известные у-значения как можно лучше. Однако предсказанные значения редко точно совпадают с наблюдаемыми величинами. Разница между наблюдаемыми и предсказываемыми значениями у называется невязка или отклонение. Величина отклонений регрессионного уравнения — одно из измерений качества работы модели. Большие отклонения говорят о ненадлежащем качестве модели.
Создание регрессионной модели представляет собой итерационный процесс, направленный на поиск эффективных независимых переменных, чтобы объяснить зависимые переменные, которые вы пытаетесь смоделировать или понять, запуская инструмент регрессии, чтобы определить, какие величины являются эффективными предсказателями. Затем пошаговое удаление и/или добавление переменных до тех пор, пока вы не найдете наилучшим образом подходящую регрессионную модель. Т.к. процесс создания модели часто исследовательский, он никогда не должен становиться простым «подгоном» данных. Он должен учитывать теоретические аспекты, мнение экспертов в этой области и здравый смысл. Вы должным быть способны определить ожидаемую взаимосвязь между каждой потенциальной независимой переменной и зависимой величиной до непосредственного анализа, и должны задать себе дополнительные вопросы, когда эти связи не совпадают.
Особенности регрессионного анализа
Регрессия МНК – это простой метод анализа с хорошо проработанной теорией, предоставляющий эффективные возможности диагностики, которые помогут вам интерпретировать результаты и устранять неполадки. Однако, МНК надежен и эффективен, если ваши данные и регрессионная модель удовлетворяют всем предположениям, требуемым для этого метода (смотри таблицу внизу). Пространственные данные часто нарушают предположения и требования МНК, поэтому важно использовать инструменты регрессии в союзе с подходящими инструментами диагностики, которые позволяют оценить, является ли регрессия подходящим методом для вашего анализа, а приведенная структура данных и модель может быть применена.
Как регрессионная модель может не работать
Серьезной преградой для многих регрессионных моделей является ошибка спецификации. Модель ошибки спецификации — это такая неполная модель, в которой отсутствуют важные независимые переменные, поэтому она неадекватно представляет то, что мы пытаемся моделировать или предсказывать (зависимую величину, у). Другими словами, регрессионная модель не рассказывает вам всю историю. Ошибка спецификации становится очевидной, когда в отклонениях вашей регрессионной модели наблюдается статистически значимая пространственная автокорреляция, или другими словами, когда отклонения вашей модели кластеризуются в пространстве (недооценки – в одной области изучаемой территории, а переоценки – в другой). Благодаря картографированию отклонений регрессии или коэффициентов, связанных с географически взвешенной регрессией, вы сможете обратить ваше внимание на какие-то нюансы, которые вы упустили ранее. Запуск Анализа горячих точек по отклонениям регрессии также может раскрыть разные пространственные режимы, которые можно моделировать при помощи метода наименьших квадратов с региональными показателями или исправлять с использованием географически взвешенной регрессии. Предположим, когда вы картографируете отклонения вашей регрессионной модели, вы видите, что модель всегда заново предсказывает значения в горах, и, наоборот, в долинах, что может значить, что отсутствуют данные о рельефе. Однако может случиться так, что отсутствующие переменные слишком сложны для моделирования или их невозможно подсчитать или слишком трудно измерить. В этих случаях, вы можете воспользоваться ГВР (географически взвешенной регрессией) или другой пространственной регрессией, чтобы получить хорошую модель.
В следующей таблице перечислены типичные проблемы с регрессионными моделями и инструменты в ArcGIS:
Типичные проблемы с регрессией, последствия и решения
|
Ошибки спецификации относительно независимых переменных. |
Когда ключевые независимые переменные отсутствуют в регрессионном анализе, коэффициентам и связанным с ними р-значениям нельзя доверять. |
Создайте карту и проверьте невязки МНК и коэффициенты ГВР или запустите Анализ горячих точек по регрессионным невязкам МНК, чтобы увидеть, насколько это позволяет судить о возможных отсутствующих переменных. |
|
Нелинейные взаимосвязи. Просмотрите иллюстрацию. |
МНК и ГВР – линейные методы. Если взаимосвязи между любыми независимыми величинами и зависимыми – нелинейны, результирующая модель будет работать плохо. |
Создайте диаграмму рассеяния, чтобы выявить взаимосвязи между показателями в модели.Уделите особое внимание взаимосвязям, включающим зависимые переменные. Обычно криволинейность может быть устранена трансформированием величин. Просмотрите иллюстрацию. Альтернативно, используйте нелинейный метод регрессии. |
|
Выбросы данных. Просмотрите иллюстрацию. |
Существенные выбросы могут увести результаты взаимоотношений регрессионной модели далеко от реальности, внося ошибку в коэффициенты регрессии. |
Создайте диаграмму рассеяния и другие графики (гистограммы), чтобы проверить экстремальные значения данных. Скорректировать или удалить выбросы, если они представляют ошибки. Когда выбросы соответствуют действительности, они не могут быть удалены. Запустить регрессию с и без выбросов, чтобы оценить, как это влияет на результат. |
|
Нестационарность. Вы можете обнаружить, что входящая переменная, может иметь сильную зависимость в регионе А, и в то время быть незначительной или даже поменять знак в регионе B (см. рисунок). |
Если взаимосвязь между вашими зависимыми и независимыми величинами противоречит в пределах вашей области изучения, рассчитанные стандартные ошибки будут искусственно раздуты. |
Инструмент МНК в ArcGIS автоматически тестирует проблемы, связанные с нестационарностью (региональными вариациями) и вычисляет устойчивые стандартные значения ошибок. Просмотрите иллюстрацию. Когда вероятности, связанные с тестом Koenker, малы (например, < 0,05), у вас есть статистически значимая региональная вариация и вам необходимо учитывать устойчивые вероятности, чтобы определить, является ли независимая переменная статистически значимой или нет. Как правило, результаты моделирования можно улучшить с помощью инструмента Географически взвешенная регрессия. |
|
Мультиколлинеарность. Одна или несколько независимых переменных излишни. Просмотрите иллюстрацию. |
Мультиколлинеарность ведет к переоценке и нестабильной/ненадежной модели. |
Инструмент МНК в ArcGIS автоматически проверяет избыточность. Каждой независимой переменной присваивается рассчитанная величина фактора, увеличивающего дисперсию. Когда это значение велико (например, > 7,5), избыток является проблемой и излишние показатели должны быть удалены из модели или модифицированы путем создания взаимосвязанных величин или увеличением размера выборки. Просмотрите иллюстрацию. |
|
Противоречивая вариация в отклонениях. Может произойти, что модель хорошо работает для маленьких величин, но становится ненадежна для больших значений. Просмотрите иллюстрацию. |
Когда модель плохо предсказывает некоторые группы значений, результаты будут носить ошибочный характер. |
Инструмент МНК в ArcGIS автоматически выполняет тест на несистемность вариаций в отклонениях (называемая гетероскедастичность или неоднородность дисперсии) и вычисляет стандартные ошибки, которые устойчивы к этой проблеме. Когда вероятности, связанные с тестом Koenker, малы (например, 0,05), необходимо учитывать устойчивые вероятности, чтобы определить, является ли независимая переменная статистически значимой или нет. Просмотрите иллюстрацию. |
|
Пространственно автокоррелированные отклонения. Просмотрите иллюстрацию. |
Когда наблюдается пространственная кластеризация в отклонениях, полученных в результате работы модели, это означает, что имеется переоценённый тип систематических отклонений, модель работает ненадежно. |
Запустите инструмент Пространственная автокорреляция (Spatial Autocorrelation) по отклонениям, чтобы убедиться, что в них не наблюдается статистически значимой пространственной автокорреляции. Статистически значимая пространственная автокорреляция практически всегда является симптомом ошибки спецификации (отсутствует ключевой показатель в модели). Просмотрите иллюстрацию. |
|
Нормальное распределение систематической ошибки. Просмотрите иллюстрацию. |
Когда невязки регрессионной модели распределены ненормально со средним, близким к 0, р-значения, связанные с коэффициентами, ненадежны. |
Инструмент МНК в ArcGIS автоматически выполняет тест на нормальность распределения отклонений. Когда статистический показатель Жака-Бера является значимым (например, 0,05), скорее всего в вашей модели отсутствует ключевой показатель (ошибка спецификации) или некоторые отношения, которые вы моделируете, являются нелинейными. Проверьте карту отклонений и возможно карту с коэффициентами ГВР, чтобы определить, какие ключевые показатели отсутствуют. Просмотр диаграмм рассеяния и поиск нелинейных отношений. |
Важно протестировать модель на каждую из проблем, перечисленных выше. Результаты могут быть на 100 % неправильны, если игнорируются проблемы, упомянутые выше.
Пространственная регрессия
Для пространственных данных характерно 2 свойства, которые затрудняют (не делают невозможным) применение традиционных (непространственных) методов, таких как МНК:
- Географические объекты довольно часто пространственно автокоррелированы. Это означает, что объекты, расположенные ближе друг к другу более похожи между собой, чем удаленные объекты. Это создает переоцененный тип систематических ошибок для традиционных моделей регрессии.
- География важна, и часто наиболее важные процессы нестационарны. Эти процессы протекают по-разному в разных частях области изучения. Эта характеристика пространственных данных может относиться как к региональным вариациям, так и к нестационарности.
Настоящие методы пространственной регрессии были разработаны, чтобы устойчиво справляться с этими двумя характеристиками пространственных данных и даже использовать эти свойства пространственных данных, чтобы улучшать моделирование взаимосвязей. Некоторые методы пространственной регрессии эффективно имеют дело с 1 характеристикой (пространственная автокорреляция), другие – со второй (нестационарность). В настоящее время, нет методов пространственной регрессии, которые эффективны с обеими характеристиками. Для правильно настроенной модели ГВР пространственная автокорреляция обычно не является проблемой.
Пространственная автокорреляция
Существует большая разница в том, как традиционные и пространственные статистические методы смотрят на пространственную автокорреляцию. Традиционные статистические методы видят ее как плохую вещь, которая должна быть устранена, т.к. пространственная автокорреляция ухудшает предположения многих традиционных статистических методов. Для географа или ГИС-аналитика, однако, пространственная автокорреляция является доказательством важности пространственных процессов; это интегральная компонента данных. Удаляя пространство, мы удаляем пространственный контекст данных; это как только половина истории. Пространственные процессы и доказательство пространственных взаимосвязей в данных представляют собой особый интерес, и поэтому пользователи ГИС с радостью используют инструменты пространственного анализа данных. Однако, чтобы избежать переоцененный тип систематических ошибок в вашей модели, вы должны определить полный набор независимых переменных, которые эффективно опишут структуру ваших данных. Если вы не можете определить все эти переменные, скорее всего, вы увидите существенную пространственную автокорреляцию среди отклонений модели. К сожалению, вы не можете доверять результатам регрессии, пока все не устранено. Используйте инструмент Пространственная автокорреляция, чтобы выполнить тест на статистически значимую пространственную автокорреляцию для отклонений в вашей регрессии.
Как минимум существует 3 направления, как поступать с пространственной автокорреляцией в невязках регрессионных моделей.
- Изменять размер выборки до тех пор, пока не удастся устранить статистически значимую пространственную автокорреляцию. Это не гарантирует, что в анализе будет полностью устранена проблема пространственной автокорреляции, но она значительно меньше, когда пространственная автокорреляция удалена из зависимых и независимых переменных. Это традиционный статистический подход к устранению пространственной автокорреляции и только подходит, если пространственная автокорреляция является результатом избыточности данных.
- Изолируйте пространственные и непространственные компоненты каждой входящей величины, используя методы фильтрации в пространственной регрессии. Пространство удалено из каждой величины, но затем его возвращают обратно в регрессионную модель в качестве новой переменной, отвечающей за пространственные эффекты/пространственную структуру. ArcGIS в настоящее время не предоставляет возможности проведения подобного рода анализа.
- Внедрите пространственную автокорреляцию в регрессионную модель, используя пространственные эконометрические регрессионные модели. Пространственные эконометрические регрессионные модели будут добавлены в ArcGIS в следующем релизе.
Региональные вариации
Глобальные модели, подобные МНК, создают уравнения, наилучшим образом описывающие общие связи в данных в пределах изучаемой территории. Когда те взаимосвязи противоречивы в пределах территории изучения, МНК хорошо моделирует эти взаимосвязи. Когда те взаимосвязи ведут себя по-разному в разных частях области изучения, регрессионное уравнение представляет средние результаты, и в случае, когда те взаимосвязи представляют 2 экстремальных значения, глобальное среднее не моделирует хорошо эти значения. Когда ваши независимые переменные испытывают нестационарность (региональные вариации), глобальные модели не подходят, а необходимо использовать устойчивые методы регрессионного анализа. Идеально, вы сможете определить полный набор независимых переменных, чтобы справиться с региональными вариациями в ваших зависимых переменных. Если вы не сможете определить все пространственные переменные, вы снова заметите статистически значимую пространственную автокорреляцию в ваших отклонениях и/или более низкие, чем ожидалось, значения R-квадрат. К сожалению, вы не можете доверять результатам регрессии, пока все не устранено.
Существует как минимум 4 способа работы с региональными вариациями в МНК регрессионных моделях:
- Включить переменную в модель, которая объяснит региональные вариации. Если вы видите, что ваша модель всегда «перепредсказывает» на севере и «недопредсказывает» на юге, добавьте набор региональных значений:1 для северных объектов, и 0 для южных объектов.
- Используйте методы, которые включают региональные вариации в регрессионную модель, такие как Географически взвешенная регрессия.
- Примите во внимание устойчивые стандартные отклонения регрессии и вероятности, чтобы определить, являются ли коэффициенты статистически значимыми. ГВР рекомендуется
- Изменить/сократить размер области изучения так, чтобы процессы в пределах новой области изучения были стационарными (не испытывали региональные вариации).
Дополнительные ресурсы
Для большей информации по использованию регрессионных инструментов, см.:
- Более подробно о регрессии МНК
- Более подробно о Географически взвешенной регрессии
Связанные разделы
- Как работает Географически взвешенная регрессия (ГВР)
- Что вам не говорят о регрессионном анализе
- Интерпретация результатов инструмента Исследовательская регрессия
- Как работает инструмент Исследовательская регрессия (Exploratory Regression)
Отзыв по этому разделу?
4.
Использование
предварительной информации о значениях некоторых параметров. Иногда значения некоторых неизвестных параметров
модели могут быть определены по пробным выборочным наблюдениям, тогда
мультиколлинеарность может быть устранена путем установления значений параметра
у одной коррелирующих переменных. Ограниченность метода – в сложности получения
предварительных значений параметров с высокой точностью.
5.
Преобразование переменных. Для устранения мультиколлинеарности можно
преобразовать переменные, например, путем линеаризации или получения
относительных показателей, а также перехода от номинальных к реальным
показателям (особенно в макроэкономических исследованиях).
При построении модели множественной регрессии с точки
зрения обеспечения ее высокого качества возникают следующие вопросы:
1.
Каковы признаки качественной
модели?
2.
Какие ошибки спецификации могут
быть?
3.
Каковы последствия ошибок
спецификации?
4.
Какие существуют методы
обнаружения и устранения ошибок спецификации?
Рассмотрим основные признаки качественной модели
множественной регрессии:
1.
Простота. Из двух моделей примерно одинаковых статистических
свойств более качественной является та, которая содержит меньше переменных, или
же более простая по аналитической форме.
2.
Однозначность. Метод вычисления коэффициентов должен быть одинаков
для любых наборов данных.
3.
Максимальное соответствие. Этот признак говорит о том, что основным критерием
качества модели является коэффициент детерминации, отражающий объясненную
моделью вариацию зависимой переменной. Для практического использования выбирают
модель, для которой расчетное значение F-критерия для
коэффициента детерминации б четыре раза больше табличного.
4.
Согласованность с теорией. Получаемые значения коэффициентов должны быть
интерпретируемы с точки зрения экономических явлений и процессов. К примеру,
если строится линейная регрессионная модель спроса на товар, то соответствующий
коэффициент при цене товара должен быть отрицательным.
5.
Хорошие прогнозные качества.
Обязательным условием построения
качественной модели является возможность ее использования для прогнозирования.
Одной из основных ошибок, допускаемых при построении
регрессионной модели, является ошибка спецификации (рис. 4.3).
Под ошибкой спецификации понимается неправильный выбор функциональной формы
модели или набора объясняющих переменных.
Различают следующие виды ошибок спецификации:
1.
Невключение в модель полезной
(значимой) переменной.
2.
Добавление в модель лишней
(незначимой) переменной
3.
Выбор неправильной функциональной
формы модели
Последствия ошибки первого вида (невключение в
модель значимой переменной) заключаются в том, что полученные по МНК оценки
параметров являются смещенными и несостоятельными, а значение коэффициента
детерминации значительно снижаются.
При добавлении в модель лишней переменной
(ошибка второго вида) ухудшаются статистические свойства оценок
коэффициентов, возрастают их дисперсии, что ухудшает прогнозные качества модели
и затрудняет содержательную интерпретацию параметров, однако по сравнению с
другими ошибками ее последствия менее серьезны.
Если же осуществлен неверный выбор
функциональной формы модели, то есть допущена ошибка третьего вида, то
получаемые оценки будут смещенными, качество модели в целом и отдельных
коэффициентов будет невысоким. Это может существенно сказаться на прогнозных
качествах модели.
Ошибки спецификации первого вида можно обнаружить только
по невысокому качеству модели, низким значениям R2.
Обнаружение ошибок спецификации второго вида, если лишней
является только одна переменная, осуществляется на основе расчета t — статистики для коэффициентов. При лишней переменной коэффициент
будет статистически незначим.
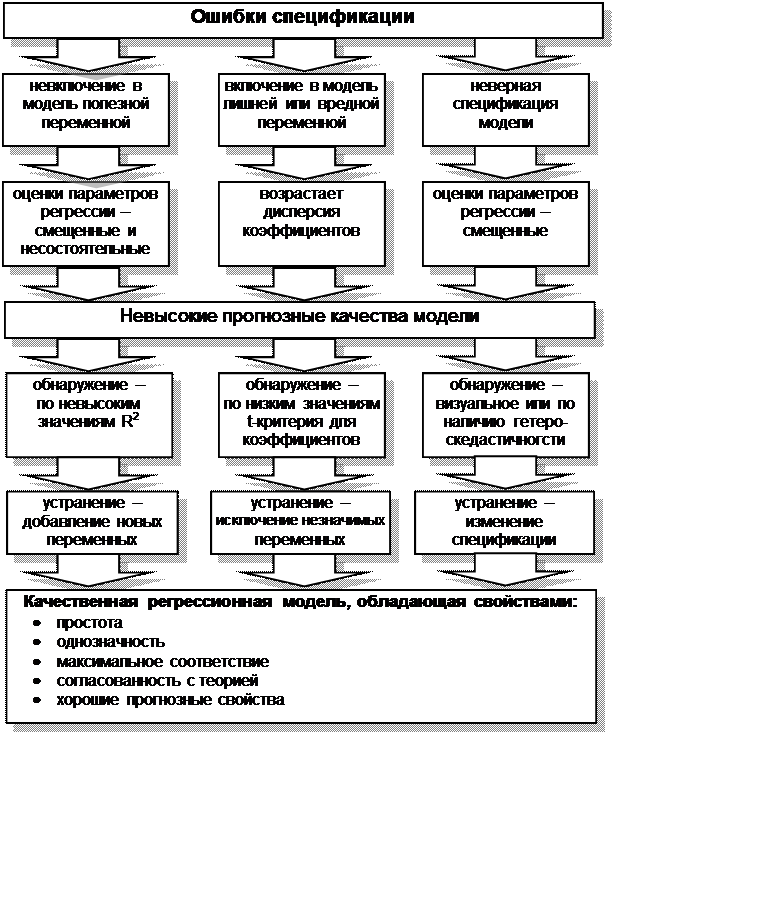
Рис. 4.3 Ошибки спецификации и свойства качественной
регрессионной модели