Типы ошибок
JavaScript — это обычный алгоритмический язык программирования. Поэтому принципы поиска и исправления ошибок,
предложенные в этой теме, подходят и для других языков.
Ошибки делятся на два типа:
- Синтаксические
- Алгоритмические
Синтаксические — это ошибки, которые нарушают правила написания программы. Из-за них код становится
непонятным браузеру. Поэтому скрипт перестаёт выполняться или вообще не запускается. Например — пропущенная
буква в названии переменной или функции, незакрытая скобка или кавычка.
При алгоритмических ошибках программа выполняется, но работает не так как нужно и производит не
те действия, которые ожидает от неё программист.
Поиск синтаксических ошибок
Если Вы неправильно написали имя переменной или функции, то об этом вы можете узнать с помощью средств
отладки, которые будут рассмотрены далее.
Неправильно расставить кавычки вообще маловероятно, потому что в
текстовых редакторах текст в кавычках обычно выделяется своим цветом.
Найти незакрытую скобку помогут текстовые редакторы для
программирования. Соответсвующие скобки обычно выделяются определённым цветом.
Это работает со всеми видами скобок.
Поиск алгоритмических ошибок
Искать алгоритмические ошибки намного сложнее, потому что
они никак не проявляются. Чтобы найти такую ошибку,
нужно выбрать значимое место скрипта. Это могут быть последние
строки программы, отдельной функции или другая важная чать программы.
Затем нужно ответить на два вопроса:
- Доходит ли выполнение программы до этого места?
- Какое значение имеют переменные, имеющие отношение к ошибке?
Ответы на оба вопроса вы получаете, если выводите на экран значения важных переменных в выбранном месте
программы.
Выполнение программы может не дойти до определённого места из-за того, что не выполняется условие в
операторе if. Поэтому нужно смотреть значения выражений в ближайшем операторе
if. Если в нём сравниваются переменные, то нужно вывести на экран значения этих
переменных перед оператором. А если сравниваются выражения, то вывести на экран значения этих выражений.
Если выполнение программы дошло до выбранного места, но программа работает неправильно, значит какая-то
переменная имеет не то значение, какое должна иметь. Когда вы поймёте, какая это переменная, то нужно отследить
как меняется её значение по ходу всего выполнения. Нужно внимательно посмотреть те строки кода, в которых она
получает новые значения. Если визуально найти ошибку не удалось, то можно после каждого изменения значения
выводить переменную на экран. Так Вы найдёте строку, в которой нарушается алгоритм программы.
Средства отладки JavaScript кода
В браузерах есть средства отладки, которые помогают найти и исправить ошибки в JavaScript коде.
Мы используем «Инструменты
разработчика» браузера FireFox, которые уже рассматривались
в теме про отладку CSS. Нам будут полезны две вкладки панели инструментов — «Консоль» и «Отладчик».

Консоль браузера используется не только для скриптов, поэтому в ней есть несколько кнопок, для включения и
отключения разного вида информации. Пока вы не разберётесь с ними,
лучше их все включить.

Если скрипт содержит синтаксическую ошибку, то информация
об этом выводится в консоль. Указывается строка, в которой
находится ошибка. Только номер строки не всегда совпадает с номером в редакторе. Но можно кликнуть на цифру
и откроется код скрипта. В нём номер будет совпадать.

В консоль можно вывести данные из скрипта. Текст или значения переменных. Для этого в JavaScript есть
метод console.log(). Пример:
+
|
9 |
let num = 10;
console.log('значение равно ', num);
|
Результат будет выглядеть так:

Справа указана строка, которая вывела эту информацию.
В консоль можно вывести не только переменные, но также массивы и объекты. Сначала они выводятся в свёрнутом
виде. Их можно развернуть и посмотреть все данные, которые они содержат. Удобно отображаются DOM-объекты,
то есть, элементы страницы. Пример:
|
10 |
let div = document.querySelector('div');
console.log(div);
|
В консоли DOM-объект выглядит так:

Вкладка «Отладчик» панели инструментов
позволяет приостановить выполнение скрипта на любой строке и
посмотреть, какие значения имеют переменные на этом этапе. Вкладка разделена на три части. В левой части
показаны файлы, в которых содержатся скрипты.

Кликните на нужном файле и в средней части вкладки отобразиться код файла. Строки кода пронумерованы. Можно
кликнуть на номерах нужных строк и они будут выделены синим цветом. На этих строках выполнение скрипта будет
приостанавливаться. Такие строки называются точки останова. Они перечислены также в правой части вкладки.

Когда вы выбрали нужные строки, запустите страницу заново. Скрипт остановится на первой выбранной строке и
можно будет посмотреть, как выглядит страница в этот момент. Также можно узнать какие значения имеют
переменные. В правой части вкладки нужно нажать «+», написать имя переменной и нажать Enter. Затем можно
добавить другую переменную.

Когда Вы посмотрели всё, что нужно, переходите к следующей точке останова. Нажмите кнопку «Возобновить».
Скрипт продолжит выполнение, дойдёт до следующей выбранной строки и вновь остановится.

Таким образом проходятся все точки останова, пока скрипт не выполнится. Если выбранная строка находится
внутри цикла, то скрипт останавливается на каждой итерации. Когда Вы
нашли ошибку, не забудьте отменить точки останова, чтобы скрипт выполнялся как обычно.
Рассмотренный инструмент позволяет быстро отследить изменение значений переменных по ходу всей программы.
Он полезен, когда трудно понять, в какой части скрипта находится ошибка. Вы можете выбрать сразу несколько
строк и посмотреть, как ведёт себя программа в этих строках.
Аннотация: Лекция носит факультативный характер. Здесь мы рассматриваем виды допускаемых в программировании ошибок, способы тестирования и отладки программ, инструменты встроенного отладчика.
Цель лекции
Освоить работу с встроенным отладчиком, изучить категории ошибок, способы их обнаружения и устранения.
Тестирование и отладка программы
Чем больше опыта имеет программист, тем меньше ошибок в коде он совершает. Но, хотите верьте, хотите нет, даже самый опытный программист всё же допускает ошибки. И любая современная среда разработки программ должна иметь собственные инструменты для отладки приложений, а также для своевременного обнаружения и исправления возможных ошибок. Программные ошибки на программистском сленге называют багами (англ. bug — жук), а программы отладки кода — дебаггерами (англ. debugger — отладчик). Lazarus, как современная среда разработки приложений, имеет собственный встроенный отладчик, работу с которым мы разберем на этой лекции.
Ошибки, которые может допустить программист, условно делятся на три группы:
- Синтаксические
- Времени выполнения (run-time errors)
- Алгоритмические
Синтаксические ошибки
Синтаксические ошибки легче всего обнаружить и исправить — их обнаруживает компилятор, не давая скомпилировать и запустить программу. Причем компилятор устанавливает курсор на ошибку, или после неё, а в окне сообщений выводит соответствующее сообщение, например, такое:
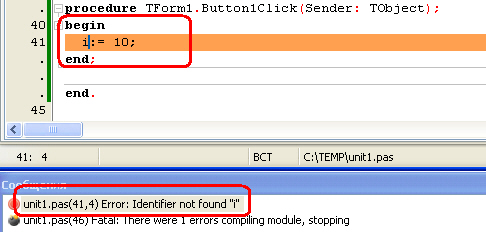
Рис.
27.1.
Найденная компилятором синтаксическая ошибка — нет объявления переменной i
Подобные ошибки могут возникнуть при неправильном написании директивы или имени функции (процедуры); при попытке обратиться к переменной или константе, которую не объявляли (
рис.
27.1); при попытке вызвать функцию (процедуру, переменную, константу) из модуля, который не был подключен в разделе uses; при других аналогичных недосмотрах программиста.
Как уже говорилось, компилятор при нахождении подобной ошибки приостанавливает процесс компиляции, выводит сообщение о найденной ошибке и устанавливает курсор на допущенную ошибку, или после неё. Программисту остается только внести исправления в код программы и выполнить повторную компиляцию.
Ошибки времени выполнения
Ошибки времени выполнения (run-time errors) тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы, или во время тестирования. Если такую программу запустить из среды Lazarus, то она скомпилируется, но при попытке загрузки, или в момент совершения ошибки, приостановит свою работу, выведя на экран соответствующее сообщение. Например, такое:

Рис.
27.2.
Сообщение Lazarus об ошибке времени выполнения
В данном случае программа при загрузке должна была считать в память отсутствующий текстовый файл MyFile.txt. Поскольку программа вызвала ошибку, она не запустилась, но в среде Lazarus процесс отладки продолжается, о чем свидетельствует сообщение в скобках в заголовке главного меню, после названия проекта. Программисту в подобных случаях нужно сбросить отладчик командой меню «Запуск -> Сбросить отладчик«, после чего можно продолжить работу над проектом.
Ошибка времени выполнения может возникнуть не только при загрузке программы, но и во время её работы. Например, если бы попытка чтения несуществующего файла была сделана не при загрузке программы, а при нажатии на кнопку, то программа бы нормально запустилась и работала, пока пользователь не нажмет на эту кнопку.
Если программу запустить из самой Windows, при возникновении этой ошибки появится такое же сообщение. При этом если нажать «OK«, программа даже может запуститься, но корректно работать все равно не будет.
Ошибки времени выполнения бывают не только явными, но и неявными, при которых программа продолжает свою работу, не выводя никаких сообщений, а программист даже не догадывается о наличии ошибки. Примером неявной ошибки может служить так называемая утечка памяти. Утечка памяти возникает в случаях, когда программист забывает освободить выделенную под объект память. Например, мы объявляем переменную типа TStringList, и работаем с ней:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
end;
В данном примере программист допустил типичную для начинающих ошибку — не освободил класс TStringList. Это не приведет к сбою или аварийному завершению программы, но в итоге можно бесполезно израсходовать очень много памяти. Конечно, эта память будет освобождена после выгрузки программы (за этим следит операционная система), но утечка памяти во время выполнения программы тоже может привести к неприятным последствиям, потребляя все больше и больше ресурсов и излишне нагружая процессор. В подобных случаях после работы с объектом программисту нужно не забывать освобождать память:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
MySL.Free; //освободили объект
end;
Однако ошибки времени выполнения могут случиться и во время работы с объектом. Если есть такой риск, программист должен не забывать про возможность обработки исключительных ситуаций. В данном случае вышеприведенный код правильней будет оформить таким образом:
begin
try
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
finally
MySL.Free; //освободили объект, даже если была ошибка
end;
end;
Итак, во избежание ошибок времени выполнения программист должен не забывать делать проверку на правильность ввода пользователем допустимых значений, заключать опасный код в блоки try…finally…end или try…except…end, делать проверку на существование открываемого файла функцией FileExists и вообще соблюдать предусмотрительность во всех слабых местах программы. Не полагайтесь на пользователя, ведь недаром говорят, что если в программе можно допустить ошибку, пользователь эту возможность непременно найдет.
Алгоритмические ошибки
Если вы не допустили ни синтаксических ошибок, ни ошибок времени выполнения, программа скомпилировалась, запустилась и работает нормально, то это еще не означает, что в программе нет ошибок. Убедиться в этом можно только в процессе её тестирования.
Тестирование — процесс проверки работоспособности программы путем ввода в неё различных, даже намеренно ошибочных данных, и последующей контрольной проверке выводимого результата.
Если программа работает правильно с одними наборами исходных данных, и неправильно с другими, то это свидетельствует о наличии алгоритмической ошибки. Алгоритмические ошибки иногда называют логическими, обычно они связаны с неверной реализацией алгоритма программы: вместо «+» ошибочно поставили «-«, вместо «/» — «*», вместо деления значения на 0,01 разделили на 0,001 и т.п. Такие ошибки обычно не обнаруживаются во время компиляции, программа нормально запускается, работает, а при анализе выводимого результата выясняется, что он неверный. При этом компилятор не укажет программисту на ошибку — чтобы найти и устранить её, приходится анализировать код, пошагово «прокручивать» его выполнение, следя за результатом. Такой процесс называется отладкой.
Отладка — процесс поиска и устранения ошибок, чаще алгоритмических. Хотя отладчик позволяет справиться и с ошибками времени выполнения, которые не обнаруживаются явно.

Visual
Г Л АВ А 8
Отладка программы
Успешное завершение процесса построения не означает, что в программе нет ошибок. Убедиться, что программа работает правильно, можно только в процессе проверки ее работоспособности, который называется тестированием.
Обычно программа редко сразу начинает работать так, как надо, или работает правильно только на некотором ограниченном наборе исходных данных. Это свидетельствует о том, что в программе есть алгоритмические ошибки. Процесс поиска и устранение ошибок называется отладкой.
Классификация ошибок
Ошибки, которые могут быть в программе, принято делить на три группы:
синтаксические;
ошибки времени выполнения;
алгоритмические.
Синтаксические ошибки, их также называют ошибками времени компиляции
(Compile-time error), наиболее легко устранимы. Их обнаруживает компилятор, а программисту остается только внести изменения в текст программы и выполнить повторную компиляцию.
Ошибки времени выполнения, они называются исключениями (exception), тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы и во время тестирования.
При возникновении исключения в программе, запущенной из среды разработки, на экране появляется окно, в котором отображаются сведения о типе исключения и информационное сообщение, поясняющее причину его возникновения. На рис. 8.1 приведен пример сообщения об исключении FileNotFoundException, причина которого — отсутствие (недоступность) файла, нужного программе.
Если программа запущена из операционной системы, то при возникновении исключения на экране также появляется сообщение об ошибке (рис. 8.2). Сделав в этом окне щелчок на кнопке Показать подробности проблемы, можно увидеть тип исключения (рис. 8.3).

|
254 |
Часть II. Практикум программирования |
Рис. 8.1. Пример сообщения об ошибке (программа запущена из Microsoft Visual C#)
Рис. 8.2. Сообщение об ошибке при запуске программы из операционной системы
Рис. 8.3. Подробная информация об исключении при запуске программы из операционной системы
|
Глава 8. Отладка программы |
255 |
С алгоритмическими ошибками дело обстоит иначе. Компилятор обнаружить их не может. Поэтому даже в том случае, если в программе есть алгоритмические ошибки, компиляция завершается успешно. Убедиться в том, что программа работает правильно и в ней нет алгоритмических ошибок, можно только в процессе тестирования программы. Если программа работает не так как надо, а результат ее работы не соответствует ожидаемому, то, скорее всего, в ней есть алгоритмические ошибки. Процесс поиска алгоритмических ошибок может быть достаточно трудоемким. Чтобы найти алгоритмическую ошибку, программисту приходится анализировать алгоритм, вручную «прокручивать» процесс его выполнения.
Предотвращение и обработка ошибок
Как было сказано ранее, в программе во время ее работы могут возникать исключения (ошибки). Наиболее часто исключения возникают вследствие действий пользователя. Он, например, может ввести неверные данные или, что бывает довольно часто, удалить нужный программе файл.
Нарушение в работе программы называется исключением. Стандартную обработку исключений, которая в общем случае заключается в отображении сообщения об ошибке, берет на себя автоматически добавляемый в выполняемую программу код. Вместе с тем программист может (и должен) обеспечить явную обработку исключений. Для этого в текст программы необходимо поместить инструкции, обеспечивающие обработку возможных исключений.
Инструкция обработки исключения в общем виде выглядит так:
try
{
// здесь инструкции, выполнение которых может вызвать исключение
}
// начало секции обработки исключений catch (ExceptionType_1 e)
{
// инструкции обработки исключения ExceptionType_1
}
catch (ExceptionType_2 e)
{
// инструкции обработки исключения ExceptionType_2
}
catch (ExceptionType_k e)
{
// инструкции обработки исключения ExceptionType_k
}
Здесь:
try — ключевое слово, показывающее, что далее следуют инструкции, при выполнении которых возможно возникновение исключений, и что обработку этих исключений берет на себя программа;

|
256 |
Часть II. Практикум программирования |
catch — ключевое слово, обозначающее начало секции обработки исключения указанного типа. Инструкции этой секции будут выполнены при возникновении исключения указанного типа;
ExceptionType_i — тип исключения.
Следует обратить внимание, после обработки исключения, инструкции секции try, следующие за вызвавшей исключение инструкцией, не выполняются.
В качестве примера в листинге 8.1 приведен конструктор формы программы «Диаграмма», в который включены инструкции, обеспечивающие обработку наиболее вероятных исключений: FileNotFoundException (Не найден файл) и FormatException (Неверный формат данных). Первое исключение возникает, если недоступен файл, второе — если в файле неверные данные (например, дробные числа записаны с использованием точки). Обработка исключения заключается в выводе сообщения о возникновении ошибки.
Листинг 8.1. Пример обработки исключений
public Form1()
{
InitializeComponent();
// чтение данных из файла в массив
System.IO.StreamReader sr; // поток для чтения try
{
//Создаем поток для чтения.
//Application.StartupPath возвращает путь
//к каталогу, из которого была запущена программа sr = new System.IO.StreamReader(
Application.StartupPath + «\usd.dat»);
//создаем массив d = new double[10];
//читаем данные из файла int i = 0;
string t = sr.ReadLine();
while ((t != null) && (i < d.Length))
{
// записываем считанное число в массив d[i++] = Convert.ToDouble(t);
t = sr.ReadLine();
}
// закрываем поток sr.Close();
|
Глава 8. Отладка программы |
257 |
// задаем функцию обработки события Paint this.Paint += new PaintEventHandler(drawDiagram);
}
//обработка исключений:
//файл данных не найден
catch (System.IO.FileNotFoundException ex)
{
MessageBox.Show(ex.Message + «n» + «(«+ ex.GetType().ToString() +»)»,
«График»,
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
// неверный формат данных
catch (System.FormatException ex)
{
MessageBox.Show(«Неверный формат данных.n(» + ex.Message,
«График»,
MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
Основной характеристикой исключения является его тип. В табл. 8.1 перечислены наиболее часто возникающие исключения и указаны причины, которые могут привести к их возникновению.
|
Таблица 8.1. Типичные исключения |
|
|
Тип исключения |
Исключение, причина |
|
System.FormatException |
Ошибка формата. Возникает при выполнении преобразо- |
|
вания, если преобразуемая величина не может быть при- |
|
|
ведена к требуемому виду. Наиболее часто возникает при |
|
|
попытке преобразовать строку символов в число, если |
|
|
строка содержит неверные символы. Например, при пре- |
|
|
образовании строки в дробное значение, если в качестве |
|
|
десятичного разделителя вместо запятой (при стандарт- |
|
|
ной для России настройке OC) поставлена точка |
|
|
System. |
Выход значения индекса за границу области допустимого |
|
IndexOutOfRangeException |
значения. Возникает при обращении к несуществующему |
|
элементу массива |
|
|
System.IO. |
Нет файла. Причина — отсутствие требуемого файла |
|
FileNotFoundException |
в указанном каталоге |
|
System.IO. |
Нет каталога. Причина — отсутствие требуемого каталога |
|
DirectoryFoundException |
|
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Введение
В данной статье рассказывается о простом алгоритме поиска ошибок в коде MQL. Часто после написания
программы возникают проблемы при компиляции, вызванные ошибками в коде. Это
могут быть самые различные ошибки, но в любом случае возникает необходимость
оперативного обнаружения участка кода, где допущена ошибка.
Нередко у людей уходит немало времени и масса нервов на поиски какой-нибудь
лишней скобки. Однако есть способ быстрого обнаружения ошибок, который основан
на использовании комментирования. Об этом методе я и расскажу в данной статье.
Концепция
Написать достаточно большой код без единой ошибки – весьма приятно. Но, к
сожалению, так выходит не всегда. Есть даже шутка, что ни одна программа не
была написана без единой ошибки. Я не рассматриваю здесь ошибки, которые
приводят к неверному исполнению кода. Здесь пойдёт речь об ошибках, из-за
которых становится невозможной компиляция.
Весьма распространённые ошибки – вставка лишней скобки в сложном условии,
нехватка скобки, не выставление двоеточия, запятой (при объявлении переменных)
и т.д. Часто при компиляции мы можем сразу увидеть, в какой строке допущена
подобная ошибка. Но бывают и случаи, когда найти такую ошибку не так просто. Ни
компилятор, ни зоркий глаз нам не могут помочь сходу найти ошибку. В
таких случаях, как правило, начинающие (и не очень) программисты начинают
«обходить» весь код, пытаясь визуально определить ошибку. И снова, и
снова, пока нервы не иссякнут, и не будет сказано «проще заново написать!».
Однако MQL, как и
другие языки программирования, предлагает потрясающий инструмент –
комментирование. Используя его можно «убирать», «отключать»
какие-то участки кода. Обычно комментирование используют именно для вставки
каких-то комментариев, или же отключения неиспользуемых участков кода. Комментирование
можно также успешно применять и при поиске ошибок.
Алгоритм поиска ошибок
Поиск ошибок обычно сводится к определению участка кода, где допущена
ошибка, а затем, в этом участке, визуально находится ошибка. Думаю, вряд ли кто-то
будет сомневаться в том, что исследовать «на глаз» 5-10 строчек кода
проще и быстрей, чем 100-500.
При использовании комментирования задача предельно проста. Сначала
нужно закомментировать различные участки кода (иногда чуть ли не весь код), тем
самым «отключив» его. Затем, по очереди комментирование снимается с
этих участков кода. После очередного снятия комментирования совершается
попытка компиляции. Если компиляция прошла успешно – ошибка не в этом участке
кода. Затем открывается следующий участок кода и т.д. Когда находится проблемный
участок кода, визуально ищется ошибка, затем устраняется. Опять происходит попытка
компиляции. Если всё прошло успешно, — ошибка устранена.
В случае возникновения новых ошибок, процедура повторяется до
их устранения. Данный подход очень полезен при написании достаточно больших программ,
но и нередко оправдывает себя и при написании относительно небольших кодов.
Весьма важно правильно определять участки кода, которые необходимо
комментировать. Если это условие (или иная логическая конструкция) – то оно
должно комментироваться полно. Если комментируется участок кода, где
объявляются переменные, важно, чтобы не был открыт участок, где происходит
обращение к этим переменным. Иначе говоря, комментирование должно применяться
по логике программирования. Несоблюдения такого подхода приводит к
возникновению новых, вводящих в заблуждение, ошибок при компиляции.
Пример
Приведу пример практического поиска ошибки в коде. Допустим, у нас есть некоторый код:
#property copyright "" #property link "" extern int Level1=6; extern int Level2=2; extern double Lots=0.1; extern int TP=7; extern int SL=5000; extern int Profit_stop=10; int start() { int pos_sell=0; for (int i_op_sell=OrdersTotal()-1; i_op_sell>=0; i_op_sell--) { if (!OrderSelect(i_op_sell,SELECT_BY_POS,MODE_TRADES)) break; if (Symbol()==OrderSymbol()&&(OrderType()==OP_SELLSTOP||OrderType()==OP_SELL)&&(OrderComment()=="sar_ao")) { pos_sell=1; break; } } int pos_buy=0; for (int i_op_buy=OrdersTotal()-1; i_op_buy>=0; i_op_buy--) { if (!OrderSelect(i_op_buy,SELECT_BY_POS,MODE_TRADES)) break; if (Symbol()==OrderSymbol()&&(OrderType()==OP_BUYSTOP||OrderType()==OP_BUY)&&(OrderComment()=="sar_ao")) { pos_buy=1; break; } } double stop_open; for (int ia=OrdersTotal()-1; ia>=0; ia--) { if (!OrderSelect(ia,SELECT_BY_POS,MODE_TRADES)) break; if ((OrderType()==OP_BUY)&&(Symbol()==OrderSymbol())&&(OrderComment()=="sar_ao")) { stop_open=OrderOpenPrice(); if (NormalizeDouble(Bid,Digits)-stop_open<=Profit_stop*Point) continue; OrderModify(OrderTicket(),OrderOpenPrice(),OrderOpenPrice()+1*Point,OrderTakeProfit(),OrderExpiration(),CLR_NONE); } if ((OrderType()==OP_SELL)&&(Symbol()==OrderSymbol())&&(OrderComment()=="sar_ao")) { stop_open=OrderOpenPrice(); if (stop_open-NormalizeDouble(Ask,Digits)<=Profit_stop*Point) continue; OrderModify(OrderTicket(),OrderOpenPrice(),OrderOpenPrice()-1*Point,OrderTakeProfit(),OrderExpiration(),CLR_NONE); } } int i; bool trend_UP=true,trend_DOWN=true; if(!pos_buy) { for(i=Level1; i>=0; i--) { if(Open[i]<iSAR(NULL,0,0.02,0.1,i)) { trend_UP=false; break; } } for(i=Level2*2; i>=0; i--) { if(i>Level2) { if(iAO(NULL, 0, i+1)<=iAO(NULL, 0, i)) { trend_UP=false; break; } } if(i<Level2) { if(iAO(NULL, 0, i+1)>=iAO(NULL, 0, i)) { trend_UP=false; break; } } } } else { trend_UP=false; } if(!pos_sell) { for(i=Level1; i>=0; i--) { { if(Open[i]>iSAR(NULL,0,0.02,0.1,i)) { trend_DOWN=false; break; } } for(i=Level2*2; i>=0; i--) { if(i>Level2) { if(iAO(NULL, 0, i+1)>=iAO(NULL, 0, i)) { trend_DOWN=false; break; } } if(i<Level2) { if(iAO(NULL, 0, i+1)<=iAO(NULL, 0, i)) { trend_DOWN=false; break; } } } } else { trend_DOWN=false; } if(Open[0]>iSAR(NULL,0,0.02,0.2,0)) { ObjectDelete("sell"); } if(Open[0]<iSAR(NULL,0,0.02,0.2,0)) { ObjectDelete("buy"); } double MA_1; MA_1=iStochastic(NULL,0,5,3,3,MODE_SMA,0,MODE_SIGNAL,0); if(trend_UP && MA_1<50 && Open[1]<Close[1] && !pos_buy && ObjectFind("buy") != 0) { OrderSend(Symbol(),OP_BUY, Lots,Ask,2,Ask-SL*Point,Ask+TP*Point,"sar_ao",0,0,Blue); ObjectCreate("buy", OBJ_ARROW, 0, Time[0], Bid); ObjectSet("buy", OBJPROP_STYLE, STYLE_DOT); ObjectSet("buy", OBJPROP_ARROWCODE, SYMBOL_ARROWUP); ObjectSet("buy", OBJPROP_COLOR, LightSeaGreen); } if(trend_DOWN && MA_1>50 && Open[1]>Close[1] && !pos_sell && ObjectFind("sell") != 0) { OrderSend(Symbol(),OP_SELL, Lots,Bid,2,Bid+SL*Point,Bid-TP*Point,"sar_ao",0,0,Red); ObjectCreate("sell", OBJ_ARROW, 0, Time[0], Bid); ObjectSet("sell", OBJPROP_STYLE, STYLE_DOT); ObjectSet("sell", OBJPROP_ARROWCODE, SYMBOL_ARROWDOWN); ObjectSet("sell", OBJPROP_COLOR, Red); } return(0); }
При попытке его компиляции мы видим сообщение об ошибке:

Оперативно определить участок кода, где допущена ошибка, не представляется
возможным. Прибегаем к комментированию. Комментируем все логические
конструкции:
#property copyright "" #property link "" extern int Level1=6; extern int Level2=2; extern double Lots=0.1; extern int TP=7; extern int SL=5000; extern int Profit_stop=10; int start() { double MA_1; MA_1=iStochastic(NULL,0,5,3,3,MODE_SMA,0,MODE_SIGNAL,0); return(0); }
Легко можно убедиться, что такой код компилируется без проблем. Значит, участок кода, где допущена ошибка «скрыт». По очереди открываем участки кода /* … */, пытаемся откомпилировать.
Компиляция будет происходить благополучно, пока мы не дойдём до участка кода:
if(!pos_sell) { for(i=Level1; i>=0; i--) { { if(Open[i]>iSAR(NULL,0,0.02,0.1,i)) { trend_DOWN=false; break; } } for(i=Level2*2; i>=0; i--) { if(i>Level2) { if(iAO(NULL, 0, i+1)>=iAO(NULL, 0, i)) { trend_DOWN=false; break; } } if(i<Level2) { if(iAO(NULL, 0, i+1)<=iAO(NULL, 0, i)) { trend_DOWN=false; break; } } } } else { trend_DOWN=false; }
Следовательно, ошибка именно в этой логической конструкции. При детальном «осмотре» данного участка кода, можно увидеть, что поставлена лишняя фигурная скобка в данной конструкции:
for(i=Level1; i>=0; i--) { { if(Open[i]>iSAR(NULL,0,0.02,0.1,i)) { trend_DOWN=false; break; } }
Если убрать её, код благополучно откомпилируется.
Убрав оставшиеся комментарии, мы убедимся в том, что других ошибок в коде нет. Значит, цель достигнута — ошибка в коде была найдена достаточно оперативно.
Заключение
На практическом примере было показано, как именно используется данный алгоритм
поиска ошибок. В данном примере используется весьма немаленький код (194 строки),
и на его «обход» могло бы уйти достаточно много времени. Именно
возможность комментирования экономит достаточно много времени у многих
программистов, которые сталкиваются с задачей поиска ошибок.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Алгоритмическая ошибка
Cтраница 1
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формализованного автоматического контроля, чем предыдущие типы ошибок. К алгоритмическим следует отнести прежде всего ошибки, обусловленные некорректной постановкой функциональных задач, когда в спецификациях не полностью оговорены все условия, необходимые для получения правильного результата. Эти условия формируются и уточняются в значительной части в процессе тестирования и выявления ошибок в результатах функционирования программ. Ошибки, обусловленные неполным учетом всех условий решения задач, являются наиболее частыми в этой группе и составляют до 70 % всех алгоритмических ошибок или около 30 % общего количества ошибок на начальных этапах проектирования.
[1]
Алгоритмические ошибки и ошибки кодирования, связанные с некорректной формулировкой и реализацией алгоритмов программным путем.
[2]
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формального автоматического контроля, чем все предыдущие типы ошибок. Это определяется прежде всего отсутствием для большинства логических управляющих алгоритмов строго формализованной постановки задач, которую можно использовать в качестве эталона для сравнения результатов функционирования разработанных алгоритмов. Разработка управляющих алгоритмов осуществляется обычно при наличии большого количества параметров и в условиях значительной неопределенности самой исходной постановки задачи. Эти условия формируются в значительной части в процессе выявления ошибок по результатам функционирования алгоритмов. Ошибки некорректной постановки задач приводят к сокращению полного перечня маршрутов обработки информации, необходимых для получения всей гаммы числовых и логических решений, или к появлению маршрутов обработки информации, дающих неправильный результат. Таким образом, область получающихся выходных результатов изменяется.
[3]
Алгоритмические ошибки представляют собой ошибки в программной трактовке алгоритма, например недоучет всех вариантов работы алгоритма.
[4]
К алгоритмическим ошибкам следует отнести также ошибки связей модулей и функциональных групп программ.
[5]
К алгоритмическим ошибкам следует отнести также ошибки сопряжения алгоритмических блоков, когда информация, необходимая для функционирования некоторого блока, оказывается неполностью подготовленной блоками, предшествующими по моменту включения. Этот тип ошибок также можно квалифицировать как ошибки некорректной постановки задачи, однако в данном случае некорректность может проявляться при определенной временной последовательности функционирования алгоритмических блоков.
[6]
С алгоритмическими ошибками дело обстоит иначе. Компиляция программы, в которой есть алгоритмическая ошибка, завершается успешно. При пробных запусках программа ведет себя нормально, однако при анализе результата выясняется, что он неверный. Для того чтобы устранить алгоритмическую ошибку, приходится анализировать алгоритм, вручную прокручивать его выполнение.
[8]
Особую часть алгоритмических ошибок составляют просчеты в использовании доступных ресурсов ВС. Одновременная разработка множества модулей различными специалистами затрудняет оптимальное распределение ограниченных ресурсов ЭВМ по всем задачам, так как отсутствуют достоверные данные потребных ресурсов для решения каждой из них. В результате возникает либо недоиспользование, либо ( в подавляющем большинстве случаев) нехватка каких-то ресурсов ЭВМ для решения задач в первоначальном варианте. Наиболее крупные просчеты обычно происходят при оценке времени реализации различных групп программ и при распределении производительности ЭВМ.
[9]
Этот побочный эффект может привести к алгоритмическим ошибкам при работе программы. Для того чтобы избавить программиста от необходимости помнить о таком побочном эффекте, достаточно в начале макрокоманды сохранять, а после выполнения восстанавливать содержимое этих регистров. Для этих целей в СМ ЭВМ обычно используется стек. Необходимо отметить, что в отдельных случаях сохранение регистров не обязательно.
[10]
В предыдущем параграфе был рассмотрен характер формирования алгоритмической ошибки вычислений при отсутствии искажающих воздействий со стороны окружающей среды и вычислительной системы. В реальных условиях на процесс смены состояний АлСУ и ошибку выходных сигналов существенное влияние оказывают искажающие воздействия, которые по отношению к управляющему объекту могут быть как внешними, так и внутренними. Внешние воздействия, источником которых является внешняя ( по отношению к управляющему объекту) среда, связаны с ошибками определения параметров управляемого процесса, отказами и сбоями в работе датчиков информации, каналов связи и преобразующих устройств. Внутренние воздействия, источниками которых являются ЦВМ или комплексы ЦВМ, используемые для реализации алгоритмической системы, обусловлены сбоями, частичными отказами и прерываниями.
[11]
Кроме того, значительные трудности представляет разделение системных и алгоритмических ошибок и выделение доработок, которые не следует квалифицировать как ошибки.
[12]
Однако формула ( 29) позволяет судить о характере формирования алгоритмической ошибки в реальных системах и сделать важный вывод о несостоятельности попыток оценки качества АлСУ всякого рода контрольными просчетами.
[13]
Защита от перегрузки ЭВМ по пропускной способности предполагает обнаружение и снижение влияния последствий алгоритмических ошибок, обусловленных неправильным определением необходимой пропускной способности ЭВМ для работы в реальном времени. Кроме того, перегрузки могут быть следствием неправильного функционирования источников информации и превышения интенсивности потоков сообщений расчетного, нормального, уровня. Последствия обычно сводятся к прекращению решения некоторых функциональных задач, обладающих низким приоритетом.
[14]
В настоящее время структурные методы контроля ориентированы в основном на обнаружение и доказательство отсутствия технологических и некоторых алгоритмических ошибок в записи программ, которые выполняются на этапе программной отладки.
[15]
Страницы:
1
2
3