
Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
Выборка. Типы выборок. Расчет ошибки выборки
Калькуляторы
Калькулятор расчета ошибки и размера выборки
Калькулятор расчета статистической значимости различий
Генеральная совокупность
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих
определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и
времени. Примеры генеральных совокупностей
- Все жители Москвы (10,6 млн. человек по данным переписи 2002 года)
- Мужчины-Москвичи (4,9 млн. человек по данным переписи 2002 года)
- Юридические лица России (2,2 млн. на начало 2005 года)
- Розничные торговые точки, осуществляющие продажу продуктов питания (20 тысяч на начало 2008 года) и
т.д.
Выборка (Выборочная совокупность)
Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать заключение обо всей
генеральной совокупности. Для того чтобы заключение, полученное путем изучения выборки, можно было распространить на
всю генеральную совокупность, выборка должна обладать свойством репрезентативности.
Репрезентативность выборки
Свойство выборки корректно отражать генеральную совокупность. Одна и та же выборка может быть репрезентативной и
нерепрезентативной для разных генеральных совокупностей.
Пример:
- Выборка, целиком состоящая из москвичей, владеющих автомобилем, не репрезентирует все население
Москвы. - Выборка из российских предприятий численностью до 100 человек не репрезентирует все предприятия России.
- Выборка из москвичей, совершающих покупки на рынке, не репрезентирует покупательское поведение всех москвичей.
В то же время, указанные выборки (при соблюдении прочих условий) могут отлично репрезентировать
москвичей-автовладельцев, небольшие и средние российские предприятия и покупателей, совершающих покупки на рынках
соответственно.
Важно понимать, что репрезентативность выборки и ошибка выборки – разные явления. Репрезентативность, в отличие от
ошибки никак не зависит от размера выборки.
Пример:
Как бы мы не увеличивали количество опрошенных москвичей-автовладельцев, мы не сможем репрезентировать этой выборкой
всех москвичей.
Ошибка выборки (доверительный интервал)
Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности.
Ошибка выборки бывает двух видов – статистическая и систематическая. Статистическая ошибка зависит от размера
выборки. Чем больше размер выборки, тем она ниже.
Пример:
Для простой случайной выборки размером 400 единиц максимальная статистическая ошибка (с 95% доверительной
вероятностью) составляет 5%, для выборки в 600 единиц – 4%, для выборки в 1100 единиц – 3% Обычно, когда говорят об
ошибке выборки, подразумевают именно статистическую ошибку.
Систематическая ошибка зависит от различных факторов, оказывающих постоянное воздействие на исследование и смещающих
результаты исследования в определенную сторону.
Пример:
- Использование любых вероятностных выборок занижает долю людей с высоким доходом, ведущих активный образ жизни.
Происходит это в силу того, что таких людей гораздо сложней застать в каком-либо определенном месте (например,
дома). - Проблема респондентов, отказывающихся отвечать на вопросы
анкеты (доля «отказников» в Москве, для разных опросов,
колеблется от 50% до 80%)
В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот
или перевзвешиванием данных, но в большинстве реальных исследований даже оценить ее бывает достаточно проблематично.
Типы выборок
Выборки делятся на два типа:
- вероятностные
- невероятностные
1. Вероятностные выборки
1.1 Случайная выборка (простой случайный отбор)
Такая выборка предполагает однородность генеральной совокупности, одинаковую вероятность доступности всех элементов,
наличие полного списка всех элементов. При отборе элементов, как правило, используется таблица случайных чисел.
1.2 Механическая (систематическая) выборка
Разновидность случайной выборки, упорядоченная по какому-либо признаку (алфавитный порядок, номер телефона, дата
рождения и т.д.). Первый элемент отбирается случайно, затем, с шагом ‘n’ отбирается каждый ‘k’-ый элемент. Размер
генеральной совокупности, при этом – N=n*k
1.3 Стратифицированная (районированная)
Применяется в случае неоднородности генеральной совокупности. Генеральная совокупность разбивается на группы
(страты). В каждой страте отбор осуществляется случайным или механическим образом.
1.4 Серийная (гнездовая или кластерная) выборка
При серийной выборке единицами отбора выступают не сами объекты, а группы (кластеры или гнёзда). Группы отбираются
случайным образом. Объекты внутри групп обследуются сплошняком.
2.Невероятностные выборки
Отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям – доступности,
типичности, равного представительства и т.д..
2.1. Квотная выборка
Изначально выделяется некоторое количество групп объектов (например, мужчины в возрасте 20-30 лет, 31-45 лет и 46-60
лет; лица с доходом до 30 тысяч рублей, с доходом от 30 до 60 тысяч рублей и с доходом свыше 60 тысяч рублей) Для
каждой группы задается количество объектов, которые должны быть обследованы. Количество объектов, которые должны
попасть в каждую из групп, задается, чаще всего, либо пропорционально заранее известной доле группы в генеральной
совокупности, либо одинаковым для каждой группы. Внутри групп объекты отбираются произвольно. Квотные выборки
используются в маркетинговых исследованиях достаточно
часто.
2.2. Метод снежного кома
Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег,
знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за
исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда
необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, имеющих высокий доход,
респондентов, принадлежащих к одной профессиональной группе, респондентов, имеющих какие-либо схожие хобби/увлечения
и т.д.)
2.3 Стихийная выборка
Опрашиваются наиболее доступные респонденты. Типичные примеры стихийных выборок – опросы в газетах/журналах, анкеты, отданные респондентам на самозаполнение, большинство
интернет-опросов. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром –
активностью респондентов.
2.4 Выборка типичных случаев
Отбираются единицы генеральной совокупности, обладающие средним (типичным) значением признака. При этом возникает
проблема выбора признака и определения его типичного значения.
Курс лекций по теории статистики
Более подробную информацию по выборочным наблюдениям можно получить просмотрев видеокурс по теории статистики:
Выборочное наблюдение Способы формирование выборки
Специальные виды отбора
Калькулятор расчета ошибки и размера выборки (для простой случайной выборки)
Пояснения к полям:
Доверительная вероятность
Вероятность того, что доверительный интервал накроет неизвестное истинное значение параметра, оцениваемого по
выборочным данным. В практике исследований чаще всего используют 95%-ую доверительную вероятность
Ошибка выборки (доверительный интервал)
Интервал, вычисленный по выборочным данным, который с заданной вероятностью (доверительной) накрывает неизвестное
истинное значение оцениваемого параметра распределения.
Доля признака
Ожидаемая доля признака, для которого рассчитывается ошибка. В случае, если данные о доле признака отсутствуют,
необходимо использовать значение равное 50, при котором достигается максимальная ошибка.
Калькулятор расчета статистической значимости различий
Калькулятор позволяет проверить есть ли статистически значимая разница между долями признака, полученными из
независимых выборок.
Например, если до начала рекламной кампании марку знали 55% респондентов, а по окончании – 60% — есть ли между этими
долями статистически значимая разница, или же эта разница укладывается в ошибку выборки?
Примечание. Эта процедура может законно использоваться, только если обе выборки удовлетворяют следующему условию:
произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, должны быть не меньше 5.
Оставить свои комментарии по затронутой теме Вы можете на наших страницах в Facebook и Вконтакте.
При перепечатке материалов ссылка на маркетинговое агентство обязательна
FDF Group © 2023
Разработка сайта — Монохром
Sample size determination is the act of choosing the number of observations or replicates to include in a statistical sample. The sample size is an important feature of any empirical study in which the goal is to make inferences about a population from a sample. In practice, the sample size used in a study is usually determined based on the cost, time, or convenience of collecting the data, and the need for it to offer sufficient statistical power. In complicated studies there may be several different sample sizes: for example, in a stratified survey there would be different sizes for each stratum. In a census, data is sought for an entire population, hence the intended sample size is equal to the population. In experimental design, where a study may be divided into different treatment groups, there may be different sample sizes for each group.
Sample sizes may be chosen in several ways:
- using experience – small samples, though sometimes unavoidable, can result in wide confidence intervals and risk of errors in statistical hypothesis testing.
- using a target variance for an estimate to be derived from the sample eventually obtained, i.e., if a high precision is required (narrow confidence interval) this translates to a low target variance of the estimator.
- using a target for the power of a statistical test to be applied once the sample is collected.
- using a confidence level, i.e. the larger the required confidence level, the larger the sample size (given a constant precision requirement).
Introduction[edit]
Larger sample sizes generally lead to increased precision when estimating unknown parameters. For example, if we wish to know the proportion of a certain species of fish that is infected with a pathogen, we would generally have a more precise estimate of this proportion if we sampled and examined 200 rather than 100 fish. Several fundamental facts of mathematical statistics describe this phenomenon, including the law of large numbers and the central limit theorem.
In some situations, the increase in precision for larger sample sizes is minimal, or even non-existent. This can result from the presence of systematic errors or strong dependence in the data, or if the data follows a heavy-tailed distribution.
Sample sizes may be evaluated by the quality of the resulting estimates. For example, if a proportion is being estimated, one may wish to have the 95% confidence interval be less than 0.06 units wide. Alternatively, sample size may be assessed based on the power of a hypothesis test. For example, if we are comparing the support for a certain political candidate among women with the support for that candidate among men, we may wish to have 80% power to detect a difference in the support levels of 0.04 units.
Estimation[edit]
Estimation of a proportion[edit]
A relatively simple situation is estimation of a proportion. For example, we may wish to estimate the proportion of residents in a community who are at least 65 years old.
The estimator of a proportion is  , where X is the number of ‘positive’ e.g., the number of people out of the n sampled people who are at least 65 years old). When the observations are independent, this estimator has a (scaled) binomial distribution (and is also the sample mean of data from a Bernoulli distribution). The maximum variance of this distribution is 0.25, which occurs when the true parameter is p = 0.5. In practice, since p is unknown, the maximum variance is often used for sample size assessments. If a reasonable estimate for p is known the quantity
, where X is the number of ‘positive’ e.g., the number of people out of the n sampled people who are at least 65 years old). When the observations are independent, this estimator has a (scaled) binomial distribution (and is also the sample mean of data from a Bernoulli distribution). The maximum variance of this distribution is 0.25, which occurs when the true parameter is p = 0.5. In practice, since p is unknown, the maximum variance is often used for sample size assessments. If a reasonable estimate for p is known the quantity  may be used in place of 0.25.
may be used in place of 0.25.
For sufficiently large n, the distribution of  will be closely approximated by a normal distribution.[1] Using this and the Wald method for the binomial distribution, yields a confidence interval of the form
will be closely approximated by a normal distribution.[1] Using this and the Wald method for the binomial distribution, yields a confidence interval of the form
 ,
,- where Z is a standard Z-score for the desired level of confidence (1.96 for a 95% confidence interval).

If we wish to have a confidence interval that is W units total in width (W/2 on each side of the sample mean), we will solve

for n, yielding the sample size

sample sizes for binomial proportions given different confidence levels and margins of error
 , in the case of using .5 as the most conservative estimate of the proportion. (Note: W/2 = margin of error.)
, in the case of using .5 as the most conservative estimate of the proportion. (Note: W/2 = margin of error.)
In the figure below one can observe how sample sizes for binomial proportions change given different confidence levels and margins of error.
Otherwise, the formula would be  , which yields
, which yields  .
.
For example, if we are interested in estimating the proportion of the US population who supports a particular presidential candidate, and we want the width of 95% confidence interval to be at most 2 percentage points (0.02), then we would need a sample size of (1.96)2/ (0.022) = 9604. It is reasonable to use the 0.5 estimate for p in this case because the presidential races are often close to 50/50, and it is also prudent to use a conservative estimate. The margin of error in this case is 1 percentage point (half of 0.02).
The foregoing is commonly simplified

will form a 95% confidence interval for the true proportion. If this interval needs to be no more than W units wide, the equation

can be solved for n, yielding[2][3] n = 4/W2 = 1/B2 where B is the error bound on the estimate, i.e., the estimate is usually given as within ± B. For B = 10% one requires n = 100, for B = 5% one needs n = 400, for B = 3% the requirement approximates to n = 1000, while for B = 1% a sample size of n = 10000 is required. These numbers are quoted often in news reports of opinion polls and other sample surveys. However, the results reported may not be the exact value as numbers are preferably rounded up. Knowing that the value of the n is the minimum number of sample points needed to acquire the desired result, the number of respondents then must lie on or above the minimum.
Estimation of a mean[edit]
When estimating the population mean using an independent and identically distributed (iid) sample of size n, where each data value has variance σ2, the standard error of the sample mean is:

This expression describes quantitatively how the estimate becomes more precise as the sample size increases. Using the central limit theorem to justify approximating the sample mean with a normal distribution yields a confidence interval of the form
- ,
- where Z is a standard Z-score for the desired level of confidence (1.96 for a 95% confidence interval).

If we wish to have a confidence interval that is W units total in width (W/2 being the margin of error on each side of the sample mean), we would solve

for n, yielding the sample size
 .
.
For example, if we are interested in estimating the amount by which a drug lowers a subject’s blood pressure with a 95% confidence interval that is six units wide, and we know that the standard deviation of blood pressure in the population is 15, then the required sample size is  , which would be rounded up to 97, because the obtained value is the minimum sample size, and sample sizes must be integers and must lie on or above the calculated minimum.
, which would be rounded up to 97, because the obtained value is the minimum sample size, and sample sizes must be integers and must lie on or above the calculated minimum.
Required sample sizes for hypothesis tests [edit]
A common problem faced by statisticians is calculating the sample size required to yield a certain power for a test, given a predetermined Type I error rate α. As follows, this can be estimated by pre-determined tables for certain values, by Mead’s resource equation, or, more generally, by the cumulative distribution function:
Tables[edit]
| [4]
Power |
Cohen’s d | ||
|---|---|---|---|
| 0.2 | 0.5 | 0.8 | |
| 0.25 | 84 | 14 | 6 |
| 0.50 | 193 | 32 | 13 |
| 0.60 | 246 | 40 | 16 |
| 0.70 | 310 | 50 | 20 |
| 0.80 | 393 | 64 | 26 |
| 0.90 | 526 | 85 | 34 |
| 0.95 | 651 | 105 | 42 |
| 0.99 | 920 | 148 | 58 |
The table shown on the right can be used in a two-sample t-test to estimate the sample sizes of an experimental group and a control group that are of equal size, that is, the total number of individuals in the trial is twice that of the number given, and the desired significance level is 0.05.[4] The parameters used are:
- The desired statistical power of the trial, shown in column to the left.
- Cohen’s d (= effect size), which is the expected difference between the means of the target values between the experimental group and the control group, divided by the expected standard deviation.
Mead’s resource equation[edit]
Mead’s resource equation is often used for estimating sample sizes of laboratory animals, as well as in many other laboratory experiments. It may not be as accurate as using other methods in estimating sample size, but gives a hint of what is the appropriate sample size where parameters such as expected standard deviations or expected differences in values between groups are unknown or very hard to estimate.[5]
All the parameters in the equation are in fact the degrees of freedom of the number of their concepts, and hence, their numbers are subtracted by 1 before insertion into the equation.
The equation is:[5]

where:
- N is the total number of individuals or units in the study (minus 1)
- B is the blocking component, representing environmental effects allowed for in the design (minus 1)
- T is the treatment component, corresponding to the number of treatment groups (including control group) being used, or the number of questions being asked (minus 1)
- E is the degrees of freedom of the error component and should be somewhere between 10 and 20.
For example, if a study using laboratory animals is planned with four treatment groups (T=3), with eight animals per group, making 32 animals total (N=31), without any further stratification (B=0), then E would equal 28, which is above the cutoff of 20, indicating that sample size may be a bit too large, and six animals per group might be more appropriate.[6]
Cumulative distribution function[edit]
Let Xi, i = 1, 2, …, n be independent observations taken from a normal distribution with unknown mean μ and known variance σ2. Consider two hypotheses, a null hypothesis:

and an alternative hypothesis:

for some ‘smallest significant difference’ μ* > 0. This is the smallest value for which we care about observing a difference. Now, if we wish to (1) reject H0 with a probability of at least 1 − β when
Ha is true (i.e. a power of 1 − β), and (2) reject H0 with probability α when H0 is true, then we need the following:
If zα is the upper α percentage point of the standard normal distribution, then

and so
- ‘Reject H0 if our sample average () is more than ‘


is a decision rule which satisfies (2). (This is a 1-tailed test.)
Now we wish for this to happen with a probability at least 1 − β when
Ha is true. In this case, our sample average will come from Normal distribution with mean μ*. Therefore, we require

Through careful manipulation, this can be shown (see Statistical power Example) to happen when

where  is the normal cumulative distribution function.
is the normal cumulative distribution function.
Stratified sample size[edit]
With more complicated sampling techniques, such as stratified sampling, the sample can often be split up into sub-samples. Typically, if there are H such sub-samples (from H different strata) then each of them will have a sample size nh, h = 1, 2, …, H. These nh must conform to the rule that n1 + n2 + … + nH = n (i.e., that the total sample size is given by the sum of the sub-sample sizes). Selecting these nh optimally can be done in various ways, using (for example) Neyman’s optimal allocation.
There are many reasons to use stratified sampling:[7] to decrease variances of sample estimates, to use partly non-random methods, or to study strata individually. A useful, partly non-random method would be to sample individuals where easily accessible, but, where not, sample clusters to save travel costs.[8]
In general, for H strata, a weighted sample mean is

with
- [9]

The weights,  , frequently, but not always, represent the proportions of the population elements in the strata, and
, frequently, but not always, represent the proportions of the population elements in the strata, and  . For a fixed sample size, that is
. For a fixed sample size, that is  ,
,
- [10]

which can be made a minimum if the sampling rate within each stratum is made
proportional to the standard deviation within each stratum:  , where
, where  and
and  is a constant such that
is a constant such that  .
.
An «optimum allocation» is reached when the sampling rates within the strata
are made directly proportional to the standard deviations within the strata
and inversely proportional to the square root of the sampling cost per element
within the strata,  :
:
- [11]

where  is a constant such that , or, more generally, when
is a constant such that , or, more generally, when
- [12]

Qualitative research[edit]
Sample size determination in qualitative studies takes a different approach. It is generally a subjective judgment, taken as the research proceeds.[13] One approach is to continue to include further participants or material until saturation is reached.[14] The number needed to reach saturation has been investigated empirically.[15][16][17][18]
There is a paucity of reliable guidance on estimating sample sizes before starting the research, with a range of suggestions given.[16][19][20][21] A tool akin to a quantitative power calculation, based on the negative binomial distribution, has been suggested for thematic analysis.[22][21]
See also[edit]
- Design of experiments
- Engineering response surface example under Stepwise regression
- Cohen’s h
References[edit]
- ^ NIST/SEMATECH, «7.2.4.2. Sample sizes required», e-Handbook of Statistical Methods.
- ^ «Inference for Regression». utdallas.edu.
- ^ «Confidence Interval for a Proportion» Archived 2011-08-23 at the Wayback Machine
- ^ a b Chapter 13, page 215, in: Kenny, David A. (1987). Statistics for the social and behavioral sciences. Boston: Little, Brown. ISBN 978-0-316-48915-7.
- ^ a b Kirkwood, James; Robert Hubrecht (2010). The UFAW Handbook on the Care and Management of Laboratory and Other Research Animals. Wiley-Blackwell. p. 29. ISBN 978-1-4051-7523-4. online Page 29
- ^ Isogenic.info > Resource equation by Michael FW Festing. Updated Sept. 2006
- ^ Kish (1965, Section 3.1)
- ^ Kish (1965), p. 148.
- ^ Kish (1965), p. 78.
- ^ Kish (1965), p. 81.
- ^ Kish (1965), p. 93.
- ^ Kish (1965), p. 94.
- ^ Sandelowski, M. (1995). Sample size in qualitative research. Research in Nursing & Health, 18, 179–183
- ^ Glaser, B. (1965). The constant comparative method of qualitative analysis. Social Problems, 12, 436–445
- ^ Francis, Jill J.; Johnston, Marie; Robertson, Clare; Glidewell, Liz; Entwistle, Vikki; Eccles, Martin P.; Grimshaw, Jeremy M. (2010). «What is an adequate sample size? Operationalising data saturation for theory-based interview studies» (PDF). Psychology & Health. 25 (10): 1229–1245. doi:10.1080/08870440903194015. PMID 20204937. S2CID 28152749.
- ^ a b Guest, Greg; Bunce, Arwen; Johnson, Laura (2006). «How Many Interviews Are Enough?». Field Methods. 18: 59–82. doi:10.1177/1525822X05279903. S2CID 62237589.
- ^ Wright, Adam; Maloney, Francine L.; Feblowitz, Joshua C. (2011). «Clinician attitudes toward and use of electronic problem lists: A thematic analysis». BMC Medical Informatics and Decision Making. 11: 36. doi:10.1186/1472-6947-11-36. PMC 3120635. PMID 21612639.
- ^ Mason, Mark (2010). «Sample Size and Saturation in PhD Studies Using Qualitative Interviews». Forum Qualitative Sozialforschung. 11 (3): 8.
- ^ Emmel, N. (2013). Sampling and choosing cases in qualitative research: A realist approach. London: Sage.
- ^ Onwuegbuzie, Anthony J.; Leech, Nancy L. (2007). «A Call for Qualitative Power Analyses». Quality & Quantity. 41: 105–121. doi:10.1007/s11135-005-1098-1. S2CID 62179911.
- ^ a b Fugard AJB; Potts HWW (10 February 2015). «Supporting thinking on sample sizes for thematic analyses: A quantitative tool» (PDF). International Journal of Social Research Methodology. 18 (6): 669–684. doi:10.1080/13645579.2015.1005453. S2CID 59047474.
- ^ Galvin R (2015). How many interviews are enough? Do qualitative interviews in building energy consumption research produce reliable knowledge? Journal of Building Engineering, 1:2–12.
General references[edit]
- Bartlett, J. E., II; Kotrlik, J. W.; Higgins, C. (2001). «Organizational research: Determining appropriate sample size for survey research» (PDF). Information Technology, Learning, and Performance Journal. 19 (1): 43–50.
- Kish, L. (1965). Survey Sampling. Wiley. ISBN 978-0-471-48900-9.
- Smith, Scott (8 April 2013). «Determining Sample Size: How to Ensure You Get the Correct Sample Size». Qualtrics. Retrieved 19 September 2018.
- Israel, Glenn D. (1992). «Determining Sample Size». University of Florida, PEOD-6. Retrieved 29 June 2019.
- Rens van de Schoot, Milica Miočević (eds.). 2020. Small Sample Size Solutions (Open Access): A Guide for Applied Researchers and Practitioners. Routledge.
Further reading[edit]
- NIST: Selecting Sample Sizes
- ASTM E122-07: Standard Practice for Calculating Sample Size to Estimate, With Specified Precision, the Average for a Characteristic of a Lot or Process
External links[edit]
- A MATLAB script implementing Cochran’s sample size formula
Sample size determination is the act of choosing the number of observations or replicates to include in a statistical sample. The sample size is an important feature of any empirical study in which the goal is to make inferences about a population from a sample. In practice, the sample size used in a study is usually determined based on the cost, time, or convenience of collecting the data, and the need for it to offer sufficient statistical power. In complicated studies there may be several different sample sizes: for example, in a stratified survey there would be different sizes for each stratum. In a census, data is sought for an entire population, hence the intended sample size is equal to the population. In experimental design, where a study may be divided into different treatment groups, there may be different sample sizes for each group.
Sample sizes may be chosen in several ways:
- using experience – small samples, though sometimes unavoidable, can result in wide confidence intervals and risk of errors in statistical hypothesis testing.
- using a target variance for an estimate to be derived from the sample eventually obtained, i.e., if a high precision is required (narrow confidence interval) this translates to a low target variance of the estimator.
- using a target for the power of a statistical test to be applied once the sample is collected.
- using a confidence level, i.e. the larger the required confidence level, the larger the sample size (given a constant precision requirement).
Introduction[edit]
Larger sample sizes generally lead to increased precision when estimating unknown parameters. For example, if we wish to know the proportion of a certain species of fish that is infected with a pathogen, we would generally have a more precise estimate of this proportion if we sampled and examined 200 rather than 100 fish. Several fundamental facts of mathematical statistics describe this phenomenon, including the law of large numbers and the central limit theorem.
In some situations, the increase in precision for larger sample sizes is minimal, or even non-existent. This can result from the presence of systematic errors or strong dependence in the data, or if the data follows a heavy-tailed distribution.
Sample sizes may be evaluated by the quality of the resulting estimates. For example, if a proportion is being estimated, one may wish to have the 95% confidence interval be less than 0.06 units wide. Alternatively, sample size may be assessed based on the power of a hypothesis test. For example, if we are comparing the support for a certain political candidate among women with the support for that candidate among men, we may wish to have 80% power to detect a difference in the support levels of 0.04 units.
Estimation[edit]
Estimation of a proportion[edit]
A relatively simple situation is estimation of a proportion. For example, we may wish to estimate the proportion of residents in a community who are at least 65 years old.
The estimator of a proportion is , where X is the number of ‘positive’ e.g., the number of people out of the n sampled people who are at least 65 years old). When the observations are independent, this estimator has a (scaled) binomial distribution (and is also the sample mean of data from a Bernoulli distribution). The maximum variance of this distribution is 0.25, which occurs when the true parameter is p = 0.5. In practice, since p is unknown, the maximum variance is often used for sample size assessments. If a reasonable estimate for p is known the quantity may be used in place of 0.25.
For sufficiently large n, the distribution of will be closely approximated by a normal distribution.[1] Using this and the Wald method for the binomial distribution, yields a confidence interval of the form
- ,
- where Z is a standard Z-score for the desired level of confidence (1.96 for a 95% confidence interval).
If we wish to have a confidence interval that is W units total in width (W/2 on each side of the sample mean), we will solve
for n, yielding the sample size
sample sizes for binomial proportions given different confidence levels and margins of error
, in the case of using .5 as the most conservative estimate of the proportion. (Note: W/2 = margin of error.)
In the figure below one can observe how sample sizes for binomial proportions change given different confidence levels and margins of error.
Otherwise, the formula would be , which yields .
For example, if we are interested in estimating the proportion of the US population who supports a particular presidential candidate, and we want the width of 95% confidence interval to be at most 2 percentage points (0.02), then we would need a sample size of (1.96)2/ (0.022) = 9604. It is reasonable to use the 0.5 estimate for p in this case because the presidential races are often close to 50/50, and it is also prudent to use a conservative estimate. The margin of error in this case is 1 percentage point (half of 0.02).
The foregoing is commonly simplified
will form a 95% confidence interval for the true proportion. If this interval needs to be no more than W units wide, the equation
can be solved for n, yielding[2][3] n = 4/W2 = 1/B2 where B is the error bound on the estimate, i.e., the estimate is usually given as within ± B. For B = 10% one requires n = 100, for B = 5% one needs n = 400, for B = 3% the requirement approximates to n = 1000, while for B = 1% a sample size of n = 10000 is required. These numbers are quoted often in news reports of opinion polls and other sample surveys. However, the results reported may not be the exact value as numbers are preferably rounded up. Knowing that the value of the n is the minimum number of sample points needed to acquire the desired result, the number of respondents then must lie on or above the minimum.
Estimation of a mean[edit]
When estimating the population mean using an independent and identically distributed (iid) sample of size n, where each data value has variance σ2, the standard error of the sample mean is:
This expression describes quantitatively how the estimate becomes more precise as the sample size increases. Using the central limit theorem to justify approximating the sample mean with a normal distribution yields a confidence interval of the form
- ,
- where Z is a standard Z-score for the desired level of confidence (1.96 for a 95% confidence interval).
If we wish to have a confidence interval that is W units total in width (W/2 being the margin of error on each side of the sample mean), we would solve
for n, yielding the sample size
.
For example, if we are interested in estimating the amount by which a drug lowers a subject’s blood pressure with a 95% confidence interval that is six units wide, and we know that the standard deviation of blood pressure in the population is 15, then the required sample size is , which would be rounded up to 97, because the obtained value is the minimum sample size, and sample sizes must be integers and must lie on or above the calculated minimum.
Required sample sizes for hypothesis tests [edit]
A common problem faced by statisticians is calculating the sample size required to yield a certain power for a test, given a predetermined Type I error rate α. As follows, this can be estimated by pre-determined tables for certain values, by Mead’s resource equation, or, more generally, by the cumulative distribution function:
Tables[edit]
| [4]
Power |
Cohen’s d | ||
|---|---|---|---|
| 0.2 | 0.5 | 0.8 | |
| 0.25 | 84 | 14 | 6 |
| 0.50 | 193 | 32 | 13 |
| 0.60 | 246 | 40 | 16 |
| 0.70 | 310 | 50 | 20 |
| 0.80 | 393 | 64 | 26 |
| 0.90 | 526 | 85 | 34 |
| 0.95 | 651 | 105 | 42 |
| 0.99 | 920 | 148 | 58 |
The table shown on the right can be used in a two-sample t-test to estimate the sample sizes of an experimental group and a control group that are of equal size, that is, the total number of individuals in the trial is twice that of the number given, and the desired significance level is 0.05.[4] The parameters used are:
- The desired statistical power of the trial, shown in column to the left.
- Cohen’s d (= effect size), which is the expected difference between the means of the target values between the experimental group and the control group, divided by the expected standard deviation.
Mead’s resource equation[edit]
Mead’s resource equation is often used for estimating sample sizes of laboratory animals, as well as in many other laboratory experiments. It may not be as accurate as using other methods in estimating sample size, but gives a hint of what is the appropriate sample size where parameters such as expected standard deviations or expected differences in values between groups are unknown or very hard to estimate.[5]
All the parameters in the equation are in fact the degrees of freedom of the number of their concepts, and hence, their numbers are subtracted by 1 before insertion into the equation.
The equation is:[5]
where:
- N is the total number of individuals or units in the study (minus 1)
- B is the blocking component, representing environmental effects allowed for in the design (minus 1)
- T is the treatment component, corresponding to the number of treatment groups (including control group) being used, or the number of questions being asked (minus 1)
- E is the degrees of freedom of the error component and should be somewhere between 10 and 20.
For example, if a study using laboratory animals is planned with four treatment groups (T=3), with eight animals per group, making 32 animals total (N=31), without any further stratification (B=0), then E would equal 28, which is above the cutoff of 20, indicating that sample size may be a bit too large, and six animals per group might be more appropriate.[6]
Cumulative distribution function[edit]
Let Xi, i = 1, 2, …, n be independent observations taken from a normal distribution with unknown mean μ and known variance σ2. Consider two hypotheses, a null hypothesis:
and an alternative hypothesis:
for some ‘smallest significant difference’ μ* > 0. This is the smallest value for which we care about observing a difference. Now, if we wish to (1) reject H0 with a probability of at least 1 − β when
Ha is true (i.e. a power of 1 − β), and (2) reject H0 with probability α when H0 is true, then we need the following:
If zα is the upper α percentage point of the standard normal distribution, then
and so
- ‘Reject H0 if our sample average () is more than ‘
is a decision rule which satisfies (2). (This is a 1-tailed test.)
Now we wish for this to happen with a probability at least 1 − β when
Ha is true. In this case, our sample average will come from Normal distribution with mean μ*. Therefore, we require
Through careful manipulation, this can be shown (see Statistical power Example) to happen when
where is the normal cumulative distribution function.
Stratified sample size[edit]
With more complicated sampling techniques, such as stratified sampling, the sample can often be split up into sub-samples. Typically, if there are H such sub-samples (from H different strata) then each of them will have a sample size nh, h = 1, 2, …, H. These nh must conform to the rule that n1 + n2 + … + nH = n (i.e., that the total sample size is given by the sum of the sub-sample sizes). Selecting these nh optimally can be done in various ways, using (for example) Neyman’s optimal allocation.
There are many reasons to use stratified sampling:[7] to decrease variances of sample estimates, to use partly non-random methods, or to study strata individually. A useful, partly non-random method would be to sample individuals where easily accessible, but, where not, sample clusters to save travel costs.[8]
In general, for H strata, a weighted sample mean is
with
- [9]
The weights, , frequently, but not always, represent the proportions of the population elements in the strata, and . For a fixed sample size, that is ,
- [10]
which can be made a minimum if the sampling rate within each stratum is made
proportional to the standard deviation within each stratum: , where and is a constant such that .
An «optimum allocation» is reached when the sampling rates within the strata
are made directly proportional to the standard deviations within the strata
and inversely proportional to the square root of the sampling cost per element
within the strata, :
- [11]
where is a constant such that , or, more generally, when
- [12]
Qualitative research[edit]
Sample size determination in qualitative studies takes a different approach. It is generally a subjective judgment, taken as the research proceeds.[13] One approach is to continue to include further participants or material until saturation is reached.[14] The number needed to reach saturation has been investigated empirically.[15][16][17][18]
There is a paucity of reliable guidance on estimating sample sizes before starting the research, with a range of suggestions given.[16][19][20][21] A tool akin to a quantitative power calculation, based on the negative binomial distribution, has been suggested for thematic analysis.[22][21]
See also[edit]
- Design of experiments
- Engineering response surface example under Stepwise regression
- Cohen’s h
References[edit]
- ^ NIST/SEMATECH, «7.2.4.2. Sample sizes required», e-Handbook of Statistical Methods.
- ^ «Inference for Regression». utdallas.edu.
- ^ «Confidence Interval for a Proportion» Archived 2011-08-23 at the Wayback Machine
- ^ a b Chapter 13, page 215, in: Kenny, David A. (1987). Statistics for the social and behavioral sciences. Boston: Little, Brown. ISBN 978-0-316-48915-7.
- ^ a b Kirkwood, James; Robert Hubrecht (2010). The UFAW Handbook on the Care and Management of Laboratory and Other Research Animals. Wiley-Blackwell. p. 29. ISBN 978-1-4051-7523-4. online Page 29
- ^ Isogenic.info > Resource equation by Michael FW Festing. Updated Sept. 2006
- ^ Kish (1965, Section 3.1)
- ^ Kish (1965), p. 148.
- ^ Kish (1965), p. 78.
- ^ Kish (1965), p. 81.
- ^ Kish (1965), p. 93.
- ^ Kish (1965), p. 94.
- ^ Sandelowski, M. (1995). Sample size in qualitative research. Research in Nursing & Health, 18, 179–183
- ^ Glaser, B. (1965). The constant comparative method of qualitative analysis. Social Problems, 12, 436–445
- ^ Francis, Jill J.; Johnston, Marie; Robertson, Clare; Glidewell, Liz; Entwistle, Vikki; Eccles, Martin P.; Grimshaw, Jeremy M. (2010). «What is an adequate sample size? Operationalising data saturation for theory-based interview studies» (PDF). Psychology & Health. 25 (10): 1229–1245. doi:10.1080/08870440903194015. PMID 20204937. S2CID 28152749.
- ^ a b Guest, Greg; Bunce, Arwen; Johnson, Laura (2006). «How Many Interviews Are Enough?». Field Methods. 18: 59–82. doi:10.1177/1525822X05279903. S2CID 62237589.
- ^ Wright, Adam; Maloney, Francine L.; Feblowitz, Joshua C. (2011). «Clinician attitudes toward and use of electronic problem lists: A thematic analysis». BMC Medical Informatics and Decision Making. 11: 36. doi:10.1186/1472-6947-11-36. PMC 3120635. PMID 21612639.
- ^ Mason, Mark (2010). «Sample Size and Saturation in PhD Studies Using Qualitative Interviews». Forum Qualitative Sozialforschung. 11 (3): 8.
- ^ Emmel, N. (2013). Sampling and choosing cases in qualitative research: A realist approach. London: Sage.
- ^ Onwuegbuzie, Anthony J.; Leech, Nancy L. (2007). «A Call for Qualitative Power Analyses». Quality & Quantity. 41: 105–121. doi:10.1007/s11135-005-1098-1. S2CID 62179911.
- ^ a b Fugard AJB; Potts HWW (10 February 2015). «Supporting thinking on sample sizes for thematic analyses: A quantitative tool» (PDF). International Journal of Social Research Methodology. 18 (6): 669–684. doi:10.1080/13645579.2015.1005453. S2CID 59047474.
- ^ Galvin R (2015). How many interviews are enough? Do qualitative interviews in building energy consumption research produce reliable knowledge? Journal of Building Engineering, 1:2–12.
General references[edit]
- Bartlett, J. E., II; Kotrlik, J. W.; Higgins, C. (2001). «Organizational research: Determining appropriate sample size for survey research» (PDF). Information Technology, Learning, and Performance Journal. 19 (1): 43–50.
- Kish, L. (1965). Survey Sampling. Wiley. ISBN 978-0-471-48900-9.
- Smith, Scott (8 April 2013). «Determining Sample Size: How to Ensure You Get the Correct Sample Size». Qualtrics. Retrieved 19 September 2018.
- Israel, Glenn D. (1992). «Determining Sample Size». University of Florida, PEOD-6. Retrieved 29 June 2019.
- Rens van de Schoot, Milica Miočević (eds.). 2020. Small Sample Size Solutions (Open Access): A Guide for Applied Researchers and Practitioners. Routledge.
Further reading[edit]
- NIST: Selecting Sample Sizes
- ASTM E122-07: Standard Practice for Calculating Sample Size to Estimate, With Specified Precision, the Average for a Characteristic of a Lot or Process
External links[edit]
- A MATLAB script implementing Cochran’s sample size formula
Размер
выборки
– это количество элементов, которые
необходимо отобрать из генеральной
совокупности для проведения выборочного
исследования.
Определение
размера выборки для вероятностного
метода отбора представляет собой сложный
процесс, включающий ряд этапов: 1) оценка
факторов, влияющих на объем выборки; 2)
выбор метода расчета размера выборки;
3) расчет размера выборки; 4) оценка
стандартного отклонения среднего в
выборочной совокупности; 5) расчет
предельной ошибки выборки; 6) оценка
среднего значения признака в генеральной
совокупности (см. рис. 4.8).
В
случае применения детерминированного
метода отбора используются только
приблизительные методы расчета размера
выборки и оценить объективно точность
результатов исследования не представляется
возможным.
1.
Оценка факторов, влияющих на размер
выборки.
К наиболее важным факторам, определяющим
объем выборки, относятся следующие:
важность принимаемого решения, характер
исследования, бюджет исследования,
стоимость сбора информации, число групп
и подгрупп в генеральной совокупности,
коэффициенты охвата и завершенности,
размер генеральной совокупности и
требуемая точность исследования (см.
рис. 4.9). На размер ошибки выборки и,
соответственно, точность результатов
исследования влияют применяемая
процедура отбора и степень вариации
признака в совокупности.
Как
правило, для
принятия важных решений
необходима детальная, максимально
точная информация. Ее получение
предусматривает создание больших
выборок, но при увеличении объема выборки
возрастает и стоимость каждой
дополнительной единицы информации.
На
величину объема выборки влияет также
характер
исследования.
В поисковых исследованиях, изучающих
качественные характеристики, объем
выборки, как правило, невелик. Для
исследований, предусматривающих
статистическое заключение, таких как
дескриптивные, необходим больший объем
выборки. Кроме того, большие выборки
нужны, когда информация собирается
с учетом большого количества переменных.
Большой объем выборки позволяет снизить
общий эффект от ошибок выборки по всем
переменным.
Принимая
решения об объеме выборки, нужно учитывать
фактор ограниченности ресурсов или
располагаемый
бюджет исследования.
В любом исследовательском проекте
существуют временные и финансовые
ограничения. При жестких бюджетных
ограничениях исследователь будет стоять
перед выбором: использовать более
дешевые методы сбора информации или
ограничить размер выборки, допуская
снижение точности результатов.
Р
исунок
4.8.
Этапы расчета необходимого размера
выборки и оценки значения признака в
генеральной совокупности
Р
исунок
4.9.
Факторы, учитываемые при определении
размера выборки и взаимосвязи между
ними
Чем
больше размер выборки
(чем
он ближе к размерам генеральной
совокупности в целом), тем надежнее и
достовернее полученные данные, однако
стоимость
сбора информации
(включающая в себя расходы на размножение
инструментария, оплату труда интервьюеров,
супервайзеров и операторов компьютерного
набора данных) при этом значительно
возрастает;
При
проведении углубленного анализа данных
с использованием разнообразных
методов многомерного статистического
анализа необходим большой объем выборки.
Это же касается данных, которые
анализируются с особой точностью. Таким
образом, для
анализа данных на уровне группы или
подгруппы
потребуется больший объем выборки, чем
для анализа общей или генеральной
совокупности.
К примеру, мы хотим
исследовать потребительское поведение
населения города. Перед нами – структура
генеральной совокупности, которая
представляет распределение в целом
населения города и по трем квотным
признакам: район города, пол, возраст.
Совершенно очевидно, что если в
исследовании ставится задача изучить
мнения населения города в целом — это
одна ситуация; если в том числе и по
возрастным группам – это другая (здесь
мы имеем 3 группы); если необходимо
выявить распределения мнений по
возрастным и половым группам — это третья
ситуация (здесь мы имеем уже шесть
групп); наконец, если в исследовании нас
интересует распределение информации
по возрастным, половым группам и районам
города (к примеру, мы хотим определить,
как к покупкам того или иного товара
относятся молодые женщины, проживающие
во Фрунзенском районе г. Минска), то
здесь мы имеем дело уже с четвертой
ситуацией (54 группы). Для получения
репрезентативной информации в последним
случае необходимо обеспечить
представительство в минимальной из
этих пятидесяти четырех групп 25-30 чел.
Следовательно, минимальный объем
выборочной совокупности здесь будет
находиться в пределах 1600 чел.
Статистически
определенный объем выборки представляет
собой конечный, или чистый объем выборки,
который необходимо получить, чтобы
обеспечить расчет параметров с желательной
степенью точности и заданным уровнем
достоверности. При проведении опросов
он выражается в количестве завершенных
интервью. Для получения конечного объема
выборки необходимо связаться с большим
количеством потенциальных респондентов.
Другими словами, начальный объем выборки
должен намного превышать конечный,
поскольку коэффициенты охвата и
завершенности обычно составляют меньше
100%.
Коэффициентом
охвата
называется степень наличия или процент
людей, подходящих для участия в
исследовании. Коэффициент охвата
определяет, какое количество контактов
с людьми необходимо осуществить, чтобы
в итоге получить объем выборки,
соответствующий заданным критериям.
Предположим,
что для исследования характеристик
моющих средств необходимо создать
выборку из женщин – глав семьи в возрасте
от 25 до 55 лет. Приблизительно 75% женщин
в возрасте от 20 до 60 лет, к которым можно
обратиться, – это женщины – главы семьи
в возрасте от 25 до 55 лет. Это означает,
что, в среднем, необходимо обратиться
к 1,33 женщин, чтобы получить одного
подходящего респондента. Дополнительные
критерии для отбора респондентов
(например, каким образом использовался
продукт) увеличивают необходимое
количество контактов. Предположим, что
дополнительным критерием является
использование женщиной моющего средства
для пола в течение последних двух
месяцев. Предполагается, что 60% женщин,
к которым обратятся исследователи,
будут соответствовать этому критерию.
Тогда коэффициент охвата составит 0,75
х 0,60 = 0,45. Таким образом, конечный объем
выборки следует увеличить на 2,22 (1/0,45).
Точно
так же при определении объема выборки
необходимо учитывать ожидаемые отказы
людей, соответствующих критериям
исследования. Коэффициент
завершенности
указывает на процент респондентов,
соответствующих критериям отбора,
которые полностью прошли интервью.
Например, если исследователь предполагает,
что коэффициент завершенности интервью
составит 80% от числа подходящих
респондентов, необходимое количество
контактов следует умножить на коэффициент
1,25. Применение коэффициентов охвата и
завершенности означает, что число
контактов с потенциальными респондентами,
т.е. начальный объем выборки, должно
быть в 2,22 х 1,25 (или 2,77) раз больше
необходимого объема выборки.
Заранее
заданная точность
результатов исследования или допустимая
ошибка выборки
позволяют рассчитать необходимый размер
выборочной совокупности, используя
статистические методы, которые будут
рассмотрены далее.
Ошибкой
выборочного исследования
называется
любая ошибка, возникающая в результате
опроса или наблюдения и являющаяся
следствием использования выборки, а не
всей генеральной совокупности. Ошибки
выборочного исследования обусловлены
процедурой формирования выборки и
объемом выборки. Крупные выборки
порождают меньшую ошибку выборочного
исследования, чем малые.
Чтобы
извлечь выборку, как уже отмечалось в
предыдущем параграфе, сначала необходимо
определит: основу
выборки,
представляющую собой сводный список
все членов генеральной совокупности.
Как известно, списки не всегда полно
представляют генеральную совокупность,
поскольку в ней постоянно происходят
изменения: одни члены появляются, другие
– уходят. Кроме того, списки не застрахованы
от ошибок и опечаток. Таким образом,
ошибка
основы выборки
выражается
в неправильном описании всей генеральной
совокупности. Независимо от способа
формирования выборки, исследователь
должен учитывать ошибку основы. Иногда
в распоряжении исследователя оказывается
основа, лишь приблизительно описывающая
всю генеральную совокупность, однако,
если альтернативы нет, приходится
использовать и такие списки. Исследователь
должен тщательно выбирать основу
выборки, стремясь минимизировать
ошибки. Кроме того, исследователь должен
предупредить клиента о том, что
используемая основа выборки может
содержать ошибки.
Далее
будет идти речь только о случайных
ошибках выборочного
исследования, которые не связанны с
основой выборки и могут быть оценены
статистически. Иначе говоря, будем
предполагать, что основа выборки является
достаточно качественной и обеспечивает
низкий уровень ошибок, так что мы можем
извлечь из нее репрезентативную выборку.
Ошибка
выборки
зависит
не
только от ее величины, но и от
степени различий между отдельными
единицами внутри данной генеральной
совокупности.
Например, если нужно узнать, средний
размер потребления пива молодежью г.
Минска в возрасте 18-25 лет, то обнаружится,
что внутри имеющейся генеральной
совокупности нормы потребления у
различных людей существенно различны
(гетерогенная
генеральная
совокупность). Если же необходимо узнать
размер потребления хлеба в той же
генеральной совокупности, то он будет
различаться значительно меньше
(гомогенная
генеральная
совокупность). Чем больше различия
(гетерогенность) внутри генеральной
совокупности, тем больше возможная
ошибка выборки.
Некоторые
методы выборочного исследования
минимизируют ошибку выборки, другие –
никак на нее не влияют.
Например, использование стратифицированного
отбора может дать выигрыш в точности
при оценивании характеристик всей
совокупности. Часто неоднородную
совокупность удается расслоить на
подсовокупности (страты), каждая из
которых внутренне однородна. Если каждая
страта однородна в том смысле, что
результаты измерений в ней мало изменяются
от единицы к единице, то можно получить
точную оценку среднего значения для
любой страты по небольшой выборке в
этой страте. Затем эти оценки можно
объединить в одну точную оценку для
всей совокупности.
2. Выбор метода
расчета размера выборки.
Если специалист из опыта знает, какой
размер выборки следует использовать,
или же существуют различные ограничения
(например, связанные с бюджетом),
используют приблизительные
методы расчета размера выборки,
к которым относятся следующие:
— произвольный
метод расчета.
В этом случае объем выборки определяется
на уровне 5-10 % от генеральной совокупности.
— по
эмпирическим правилам.
Рекомендуется
выбирать размер выборки таким образом,
чтобы при ее разделении на группы в
каждой группе было не меньше 100 элементов.
Кроме сопоставления основных групп
анализ часто может потребовать
использования подгрупп. Размеры таких
подгрупп должны составлять от 20 до 50
человек. Это основано на том, что для
подгрупп требуется меньшая точность.
Если
одна из групп или подгрупп составляет
сравнительно небольшой процент
совокупности, то будет разумно использовать
непропорциональную выборку. Допустим,
что только 10% совокупности смотрит
образовательные телепередачи, и мнения
представителей этой группы требуется
сопоставить с мнениями других членов
совокупности. Если используются
телефонные интервью, контакты с жителями
могут устанавливаться случайно до тех
пор, пока не будут набраны 100 человек,
которые не смотрят образовательные
телепередачи. Далее опрос продолжается,
однако уже опрашиваются лишь те
респонденты, кто образовательные
телепередачи смотрит. В результате
будет получена выборка из 200 человек,
половина из которых смотрят образовательные
телепередачи.
— традиционный
метод расчета
связан с проведением периодических
ежегодных исследований, охватывающих,
например, 500, 1000 или 1500 респондентов.
— на
основе опыта сопоставимых исследований.
Таблица
4.7 дает представление об объемах выборок,
используемых в различных маркетинговых
исследованиях. Эти величины установлены
опытным путем и могут использоваться
в качестве ориентировочных данных,
особенно при детерминированных методах
формирования выборки.
— затратный
метод основан
на размере расходов, которые допустимо
затратить на проведение исследования.
Статистический
метод определения объема выборки
основан на традиционном статистическом
заключении. В соответствии с этим методом
заранее определяется уровень (степень)
точности.
Рассмотрение
данного метода начнем с краткой
характеристики базовых
понятий математической статистики.
Наиболее
важным понятием, позволяющим делать
заключения о свойствах генеральной
совокупности на основе выборочных
методов является кривая нормального
распределения.
Таблица
4.7.
Объемы выборок, используемых в
маркетинговых исследованиях
|
Вид исследования |
Минимальный объем |
Обычный диапазон |
|
Исследование, цель которого |
500 |
1000-2500 |
|
Исследование, цель которого |
200 |
300-500 |
|
Тестирование товара |
200 |
300-500 |
|
Пробный маркетинг |
200 |
300-500 |
|
Теле- радио- и печатная |
150 |
200-300 |
|
Аудит на пробном рынке |
10 магазинов |
10-20 магазинов |
|
Фокус-группы |
2 группы |
10-15 групп |
Кривая нормального
распределения
– это теоретическая модель, представляющая
собой абсолютно симметричный и гладкий
вид полигона частот. Она имеет форму
колокола и одну вершину, а ее концы
уходят в бесконечность в обоих
направлениях. Важнейшим свойством,
которым обладает кривая нормального
распределения, является то, что расстояние
по абсциссе (горизонтальная ось)
распределения, измеренное в единицах
стандартного отклонения от среднего
арифметического распределения, всегда
дает одинаковую общую площадь под
кривой: между ±1 стандартным отклонением
находится 68,3% площади; между ±2 стандартными
отклонениями – 95,4% площади; между ±3
стандартными отклонениями – 99,7% площади
(см. рис. 4.10).


Рисунок
4.10. Области
под теоретической кривой нормального
распределения
C
понятием кривой нормального распределения
связана центральная
предельная теорема, которая
гласит:
«Если
из генеральной совокупности, имеющей
любое распределение со средним μ
и
стандартным отклонением σ,
многократно извлекать случайные выборки
объема n,
то
при большом n
распределение всех возможных выборочных
средних будет стремиться к нормальному
распределению со средним μ
и
стандартным
отклонением σ
/![]()
».
Таким
образом, центральная предельная теорема
позволяет распространять данные,
полученные в результате выборочного
исследования на всю генеральную
совокупность с определенной степенью
допущения при условии достаточно
большого объема выборки.
Конечно,
остается вопрос о том, что же такое
большой объем выборки. Полезное
эмпирическое правило гласит: если объем
выборки (n)
равен
100 или более, то применима центральная
предельная теорема и вы можете принять
допущение о нормальности распределения
всех возможных выборочных средних. Если
же n
меньше
100, то вы должны иметь веские доказательства
нормальности распределения генеральной
совокупности, и только после этого вы
можете полагать, что распределение,
которому подчиняются выборочные
статистики, является нормальным.
Следовательно, нормальность распределения
выборочных статистик гарантируется
путем использования довольно больших
выборок.
3.
Выбор требуемой степени точности и
достоверности результатов исследования.
При проведении любого выборочного
опроса или наблюдения перед исследователем
ставится задача оценить, каково истинное
значение во всей генеральной совокупности
либо среднего
значения
абсолютного
признака (доход
потребителей, размер потребления
конкретного товара), либо доли
единиц в совокупности, обладающих
каким-либо
признаком
(доля постоянных потребителей конкретного
товара; доля потребителей, удовлетворенных
уровнем обслуживания). Точность
выборки
в первом случае будет представлена в
виде абсолютной величины со знаком ±
(например, ±100 тыс. руб.; ±1 кг), или в виде
процента, во втором случае – только в
виде процента с тем же знаком (например,
±1% или ±5%).
Интерпретация
точности выборки подчиняется следующей
логике: если объем выборки обеспечивает
точность ±5%, то результаты опроса или
наблюдения, полученные с помощью выборки,
отличаются от результатов полной
переписи не более чем на 5%.
Еще одним фактором,
влияющим на объем выборки является
заданная исследователем степень
достоверности
(надежности)
оценки,
то есть степень
уверенности в том, что оценка близка к
истинному значению.
Для выборки
фиксированного объема степень точности
и степень достоверности являются
связанными величинами. На деле определение
объема выборки предполагает достижение
известного баланса между двумя этими
принципами.
Зависимость
точности выборки от ее объема для 95,4% и
99,7% уровня надежности представлена на
рисунке 4.11. Объем выборок на графике
колеблется от 50 до 2000. График демонстрирует,
что при увеличении объема выборки
ее ошибка уменьшается. Однако, как видим,
зависимость ошибки выборки от ее объема
не является прямолинейной. Иначе говоря,
удвоение объема выборки, не приводит к
существенному уменьшению ошибки.
Р
исунок
4.11. Зависимость
точности и достоверности от объема
выборки
Если
объем выборки превышает 500, ошибка
выборки для 95,4% надежности падает ниже
±4% и продолжает очень медленно снижаться.
С другой стороны, анализ графика в
области малых выборок показывает, что
относительно небольшое изменение объема
выборки позволяет значительно повысить
их точность. Например, если объем выборки
равен 50, то ее уровень точности равен
±13,9%, а увеличение их объема до 250 позволяет
уменьшить ошибку выборки до ±6,2%. Иными
словами, точность выборки, объем которой
равен 25 примерно вдвое выше, чем точность
выборки, объем которой равен 50. Однако
в области крупных выборок это правило
не выполняется.
4. Определение
t
параметра, связанного с уровнем
надежности.
Определить значение t,
связанное с уровнем надежности можно
воспользовавшись таблицей 1 приложения.
Как видно по данным таблицы, при объеме
выборки больше 100 для 95,4% надежности
t≈2,
для 99,7% надежности t≈3.
5. Поиск информации
об уровне стандартного отклонения
среднего значения признака в генеральной
совокупности.
Здесь возможны
две различные ситуации: 1) стандартное
отклонение среднего значения признака
(σ)
в генеральной совокупности известно и
2) стандартное отклонение среднего
значения признака в генеральной
совокупности неизвестно.
В
первом случае можно приступить к расчету
объема
выборки с помощью формулы стандартной
ошибки выборки.
6.
Определение
объема выборки с помощью формулы
стандартной ошибки с учетом корректировки
на охват и завершенность.
Принято различать
среднюю и предельную ошибки выборки.
Предельная ошибка выборки определяется
следующим образом:
![]()
где
∆
— предельная ошибка выборки;
t
– параметр, связанный с уровнем
надежности;
μ
– средняя ошибка выборки.
Формулы расчета
средней ошибки
выборки для средней и для доли с учетом
способа отбора приведены в таблице 4.8.
Доверительные
интервалы для генеральной средней
можно установить на основе соотношений
![]()
Доверительные
интервалы для генеральной доли
устанавливаются на основе соотношений
![]()
Далее
для вычисления объема выборки применяется
формула
вычисление объема выборки по заданному
доверительному интервалу.
Формулы
расчета численности выборки
для определения средней и доли с учетом
способа отбора приведены в таблице 4.9.
Например,
для обследования, преследующего цель
выявить мнение потребителей о новом
товаре, в регионе, насчитывающем 10 тыс.
семей, необходимо провести анкетирование.
Условно принимается, что в каждой
квартире проживает одна семья и на нее
будет выделена одна анкета. Предварительные
исследования установили, что дисперсия
среднего размера покупки составляет
24 тыс. руб.; σ2
= 2; предельная ошибка не должна превышать
0,5 тыс. руб. Отсюда численность выборки
(п)
составит:
![]()
Эта
величина округляется до 400 семей
(квартир), т.е. установлена 4%-я выборка.
Однако практика показывает, что некоторая
часть анкет не возвращается (предположим
каждая пятая), поэтому увеличиваем число
анкет до 500. Следовательно, необходимо
включить в выборку каждую 20-ю квартиру
(10000 : 500).
Все
вышеприведенные формулы применимы для
большой выборки.
Кроме большой выборки используются так
называемые малые
выборки (n
< 30), которые могут иметь место в случаях
нецелесообразности использования
больших выборок.
При
расчете ошибок малой
выборки
необходимо учесть два момента:
1) формула средней
ошибки имеет вид
![]()
2)
при определении доверительных интервалов
исследуемого показателя в генеральной
совокупности или при нахождении
вероятности допуска той или иной ошибки
необходимо использовать таблицы
вероятности Стьюдента. При этом
вероятность
определяется
в зависимости от объема выборки и t
(см. табл.
прил. 1).
Таблица 4.8.
Формулы определения стандартной ошибки
выборки при различных способах отбора
|
Виды выборки Способы отбора |
Повторная выборка |
Бесповторная выборка |
|
Для средней |
||
|
Простая случайная выборка |
|
|
|
Стратифицированная |
|
|
|
Кластерная, |
— |
|
|
Для доли |
||
|
Простая случайная выборка |
|
|
|
Стратифицированная |
|
|
|
Кластерная, |
— |
— |
В
таблице используются следующие условные
обозначения:
N
– объем генеральной совокупности;
п
– объем выборочной совокупности;
![]()
– средняя в
генеральной совокупности;
![]()
–
средняя в выборочной
совокупности;
р
– доля единиц в генеральной совокупности;
w
– доля единиц в выборочной совокупности;
![]()
– генеральная
дисперсия (заменяется на выборочную
(S2) в случае, если она
не известна);
![]()
– межсерийная
дисперсия
![]()
;
r
— число отобранных серий;
R—
число серий в генеральной совокупности.
Таблица 4.9.
Формулы определения численности выборки
(n)
при различных способах отбора
|
Виды выборки Способы отбора |
Повторная выборка |
Бесповторная выборка |
|
Для средней |
||
|
Простая случайная выборка |
|
|
|
Стратифицированная |
|
|
|
Кластерная, |
— |
|
|
Для доли |
||
|
Простая случайная выборка |
|
|
|
Стратифицированная |
|
|
|
Кластерная, |
— |
— |

Например, для
разработки бизнес-плана нового ресторана,
который открывается в центральной части
г. Минска необходимо узнать ожидаемый
диапазон расходов одного посетителя в
вечернее время. Удалось получить
информацию о том, что стандартное
отклонение расходов посетителей близкого
по уровню и месту расположения ресторана
составляет 30$. Существует возможность
опросить около 26 посетителей ресторана.
С какой достоверностью можно получить
результат при заданной точности ±10$?
Рассчитаем среднюю
ошибку выборки:
![]()
Тогда
![]()
Из
таблицы приложения 1 для n=26
и t=1,66
можно определить, что при допуске ошибки
±10$ достоверность
результатов составит менее 90%. Более
точное значение достоверности для тех
же параметров можно получить, например,
при помощи функции СТЬЮДРАСП в Microsoft
Excel
— 89,2%.
С 95,4% надежностью
будет обеспечена меньшая точность:
![]()
7. Отбор
произвольной пробной выборки.
В случае если стандартное
отклонение среднего значения признака
в генеральной совокупности неизвестно,
необходимо сформировать произвольную
пробную выборку.
8. Расчет
стандартного отклонения средней в
выборочной совокупности.
На основе полученных данных рассчитывается
стандартное отклонение признака в
выборочной совокупности и, затем –
необходимый размер выборки по приведенным
выше формулам.
9. Расчет точности
полученных результатов по формуле
предельной ошибки выборки.По
данным, собранным в ходе проведенного
выборочного исследования, рассчитывается
точность результатов. Если полученная
точность не устраивает исследователя,
может возникнуть необходимость увеличить
размер выборки с учетом рассчитанного
стандартного отклонения и коэффициентов
отклика и завершенности.
Предположим, что
в предыдущем примере не было возможности
узнать стандартное отклонение расходов
посетителей ресторана. По данным опроса
30 случайно отобранных респондентов
получены следующие данные: 25$ – 2 чел.;
30$ – 3 чел.; 45$ – 7 чел.; 55$ – 6 чел.; 70$ – 3
чел.; 85$ – 5 чел.; 110$ – 2 чел.; 150$ – 2 чел.
Определяем среднее
значение по формуле средней взвешенной:

Далее
рассчитываем дисперсию (квадрат
стандартного отклонения) расходов
посетителей ресторана по выборочной
совокупности.

Тогда
точность полученных результатов с
достоверностью 95,4%:
![]()
Для
того, чтобы обеспечить заданную точность
(±10$) рассчитываем
необходимый размер выборки:
![]()
В
целом, для принятия взвешенного решения
по размеру выборки наряду со статистическими
методами расчета следует применить
рассмотренные ранее приблизительные
методы и сравнить полученные результаты.
10. Оценка значения
признака в генеральной совокупности.
Основными
методами распространения выборочного
наблюдения на генеральную совокупность
являются прямой пересчет и способ
коэффициентов.
Прямой
пересчет есть
произведение среднего значения признака
на объем генеральной совокупности.
Однако большое число факторов не
позволяет в полной мере использовать
точечную оценку прямого пересчета при
распространении результатов выборки
на генеральную совокупность. На практике
чаще пользуются интервальной оценкой,
которая дает возможность учитывать
размер предельной ошибки выборки,
которая рассчитана для средней или для
доли признака.
Оценка
среднего по совокупности при использовании
стратифицированной выборки является
взвешенным средним средних значений
по каждой страте выборки.
Например,
производителю пива для оценки емкости
внутреннего рынка в частности необходимо
определить долю потребителей пива в
общей численности населения региона в
возрасте от 20 до 60 лет с точностью ±5%.
Можно предположить, что данный показатель
будет варьировать по полу и возрасту.
В таблице 4.10 представлена информация
о численности и структуре населения
региона в возрасте от 20 до 60 лет.
Таблица
4.10. Численность
населения региона в возрасте от 20 до 60
лет
|
Возрастные категории населения |
Всего, тыс. чел. |
В том числе |
|
|
мужчины |
женщины |
||
|
20-29 |
1576,0 |
802,0 |
774,0 |
|
30-39 |
1357,3 |
671,4 |
685,9 |
|
40-49 |
1559,6 |
751,9 |
807,7 |
|
50-59 |
1276,1 |
582,7 |
693,4 |
|
Всего |
5769,0 |
2807,9 |
2961,1 |
Ранее
проведенный опрос 200 респондентов в
возрасте от 20 до 60 лет показал, что доля
потребителей пива в общей численности
населения региона составляет 83%. По
имеющейся информации был рассчитан
необходимый объем выборки:
![]()
С
учетом необходимости обеспечить
необходимый минимальный размер подгрупп
округляем полученный результат до 300
человек и рассчитываем объем выборки
для каждой из страт по полу и возрасту
пропорционально соответствующей
численности населения. Результаты
расчета представлены в таблице 4.11.
Таблица
4.11. Структура
населения региона в возрасте от 20 до 60
лет и численность выборки.
|
Возрастные категории населения |
В % к общей численности населения |
Численность выборки |
|||
|
всего |
мужчины |
женщины |
мужчины |
женщины |
|
|
20-29 |
27,3 |
13,9 |
13,4 |
42 |
40 |
|
30-39 |
23,6 |
11,7 |
11,9 |
35 |
36 |
|
40-49 |
27,0 |
13,0 |
14,0 |
39 |
42 |
|
50-59 |
22,1 |
10,1 |
12,0 |
30 |
36 |
|
Всего |
100,0 |
48,7 |
51,3 |
146 |
154 |
В
результате опроса получены данные,
представленные в таблице 4.12.
Таблица
4.12. Доля
потребителей пива в общей численности
населения в разрезе возрастных категорий
по данным выборочного опроса.
|
Возрастные категории населения |
Доля потребителей пива |
|
|
мужчины |
женщины |
|
|
20-29 |
0,812 |
0,795 |
|
30-39 |
0,855 |
0,743 |
|
40-49 |
0,848 |
0,683 |
|
50-59 |
0,867 |
0,542 |
Определяем долю
потребителей пива по формуле средней
взвешенной:
![]()
Средняя
ошибка выборки:
![]()
Предельная ошибка
выборки для 95,4% надежности составит:
![]()
Таким
образом, с 95,4% надежностью можно
утверждать, что доля потребителей пива
в общей численности населения региона
в возрасте от 20 до 60 лет находится в
интервале от 71,8% (76,6% — 4,8%) до 81,4% (76,6% +
4,8%).
Опрос
обычно не ограничивается одним вопросом
–
иногда их сотни. Поэтому повторять
подобный процесс для каждого вопроса
смысла не имеет. Разумный подход –
выбрать несколько репрезентативных
вопросов и по ним определить размер. В
этот набор следует включить наиболее
критичные вопросы с максимальным уровнем
ожидаемой дисперсии.
В таком случае
может оказаться полезным подход
к расчету объема выборки, основанный
на сценарии максимально возможной
вариации признака в совокупности. Как
видно на рисунке 6, вариант,
когда w=
0,5 (50%) является наиболее консервативным,
поскольку он порождает максимальный
размер ошибки и, соответственно,
максимальный объем выборки. Следовательно,
его следует выбирать, когда изменчивость
не известна. Тогда формула размера
выборки упрощается:
![]()
Для 95% уровня
надежности и 5% уровня точности:
![]()
Р
исунок
4.12.
График
![]()
Использование
номограмм для
расчета
объема выборки. Стремление
упростить процедуру расчета объема
выборки приводит к созданию таблиц,
шкал или программ, которые ориентированы
на обеспечение статистической
надежности информации, но при этом не
обременяют пользователя знаниями
специальных формул из области статистики.
Например, существует калькулятор выборки
(www.
shortway.
to/few/calculator,
htm).
Номограмма является
графическим способом определения
размера выборки. Номограмма включает
три шкалы (рис. 7). На шкале слева
устанавливается разметка показателя
среднеквадратического отклонения
или распределения доли признака. На
правой шкале наносится разметка точности
измерения в виде допустимой ошибки при
заданной доверительной вероятности
95,4% или 99,7%. На средней шкале делается
разметка, соответствующая требуемому
объему выборки. На правой и левой
шкалах делаются отметки на уровне
желаемых значений показателей (доли
признака и допустимой ошибки). Линейкой
эти две отметки соединяются, на пересечении
линейки со средней шкалой делается
отметка, соответствующая тому объему
выборки, который отвечает пожеланиям
исследователя.
Объем выборки и репрезентативность
Планируем исследования и эксперименты
Если суп хорошо перемешать, то достаточно одной ложки, чтобы сделать вывод о вкусе всей кастрюли — Д.Гэллоп.
Для того, чтобы оценить любое явление, не обязательно изучать все объекты (генеральную совокупность). Для оценки здоровья человека не нужно анализировать всю кровь, достаточно небольшой пробирки. Чтобы понять настроения россиян можно не опрашивать 146 миллионов, а ограничиться несколькими тысячами. Оценка не сильно потеряет в точности.
По части судить о целом
О возможности судить о целом по части миру рассказал российский математик П.Л. Чебышев. «Закон больших чисел» простым языком можно сформулировать так: количественные закономерности массовых явлений проявляются только при
достаточном числе наблюдений
. Чем больше выборка, тем лучше случайные отклонения компенсируют друг друга и проявляется общая тенденция.
А.М. Ляпунов чуть позже сформулировал центральную предельную теорему. Она стала фундаментом для создания формул, которые позволяют рассчитать вероятность ошибки (при оценке среднего по выборке) и размер выборки, необходимый для достижения заданной точности.
Строгие формулировки:
Еще раз: чтобы корректно оценивать популяцию по выборке, нам нужна не обычная выборка, а репрезентативная выборка достаточного размера. Начнем с определения этого самого размера.
Как рассчитать объем выборки
Достаточный размер выборки зависит от следующих составляющих:
- изменчивость признака (чем разнообразней показания, тем больше наблюдений нужно, чтобы это уловить);
- размер эффекта (чем меньшие эффекты мы стремимся зафиксировать, тем больше наблюдений необходимо);
- уровень доверия (уровень вероятности при который мы готовы отвергнуть нулевую гипотезу)
ЗАПОМНИТЕ
Объем выборки зависит от изменчивости признака и планируемой строгости эксперимента
Формулы для расчета объема выборки:

Формулы расчета объема выборки
Ошибка выборки значительно возрастает, когда наблюдений меньше ста. Для исследований в которых используется 30-100 объектов применяется особая статистическая методология: критерии, основанные на распределении Стьюдента или бутстрэп-анализ. И наконец, статистика совсем слаба, когда наблюдений меньше 30.

График зависимости ошибки выборки от ее объема при оценке доли признака в г.с.
Чем больше неопределенность, тем больше ошибка. Максимальная неопределенность при оценке доли — 50% (например, 50% респондентов считают концепцию хорошей, а другие 50% плохой). Если 90% опрошенных концепция понравится — это, наоборот, пример согласованности. В таких случаях оценить долю признака по выборке проще.
Репрезентативность
Репрезентативность — это степень соответствия характеристик выборки характеристикам генеральной совокупности. Только данные по репрезентативным выборкам можно экстраполировать на всю популяцию.
Репрезентативность достигается за счет случайного отбора. Случайный отбор — хорошо. Детерминированный отбор — плохо. Он искажает структуру выборки и как следствие результат измерений. Нельзя судить о среднем росте россиян по росту ста баскетболистов, которые тренируются во дворе вашего дома, просто потому что вам так удобно.

Идеальная выборка — это когда каждый человек имеет равную вероятность попасть в число опрошенных. Полностью случайный отбор трудно достижим (это очень дорого), но к нему нужно стремиться. Сам метод сбора данных может деформировать выборку (онлайн опросы отсекают пенсионеров, опрос по стационарным телефонам — экономических активных мужчин). Представьте, как будут различаться рейтинги, если провести электоральный опрос в «Вконтакте» и в бумажной газете «Лечебные письма».
Типы выборок
Существует методология, которая позволяет сократить детерминированность при формировании выборки и приблизиться к случайному отбору.
Стратифицированная выборка. Выделяются объективно существующие страты и из каждой страты отбираются единицы пропорционально их доле в генеральной совокупности. Например для опроса россиян страты могут быть определены пропорцией населения в регионах. После чего респонденты внутри каждого региона отбираются случайным образом.
Механический отбор. Все объекты сортируются по порядковым номерам, после чего осуществляется отбор с шагом n. Например, можно отсортировать телефонные номера потенциальных участников исследования и звонить каждому 100-му.
Серийная выборка (гнездовая, кластерная). Объективно существующие группы отбираются случайным образом. Объекты внутри групп обследуются полностью. Например вскрывается один контейнер продукции и каждый товар проверяется на брак.
Метод снежного кома. У каждого респондента запрашиваются контакты его знакомых, которые подходят под условия отбора. Условия случайности отбора грубо нарушается, но это один из способов провести исследование среди труднодостижимых групп. Как быть иначе, если ваша цель — опросить любителей стальных гоночных велосипедов выпущенных не позже 1987 года.
Стихийная выборка (выборка по удобству). Применяется, когда низкая цена получения данных — это главный приоритет. Для повышения качества стихийной выборки на неё накладываются квоты. Заранее рассчитываются пропорции признаков в выборке так, чтобы они соответствовали структуре генеральной совокупности. В социологии такими признаками служат пол, возраст, профессия, семейный статус, регион проживания…
Хотите систематизировать свои знания по аналитике?
Встречайте «Анализ данных для хулиганов»
Онлайн пособие о том, как создавать великолепные продукты и эффективно управлять маркетингом на основе данных⚡
Методики / Фреймворки / Шаблоны для скачивания

Статистика знает все. И Ильф и Е. Петров, «12 Стульев»
Представьте себе, что вы строите крупный торговый центр и желаете оценить автомобильный поток въезда на территорию парковки. Нет, давайте другой пример… они все равно этого никогда не будут делать. Вам необходимо оценить вкусовые предпочтения посетителей вашего портала, для чего необходимо провести среди них опрос. Как увязать количество данных и возможную погрешность? Ничего сложного — чем больше ваша выборка, тем меньше погрешность. Однако и здесь есть нюансы.
Теоретический минимум
Не будет лишним освежить память, эти термины нам пригодятся далее.
- Популяция – Множество всех объектов, среди которых проводится исследования.
- Выборка – Подмножество, часть объектов из всей популяции, которая непосредственно участвует в исследовании.
- Ошибка первого рода — (α) Вероятность отвергнуть нулевую гипотезу, в то время как она верна.
- Ошибка второго рода — (β) Вероятность не отвергнуть нулевую гипотезу, в то время как она ложна.
- 1 — β — Статистическая мощность критерия.
- μ0 и μ1 — Средние значения при нулевой и альтернативной гипотезе.

Уже в самих определениях ошибки первого и второго рода имеется простор для дебатов и толкований. Как с ними определиться и какую выбрать в качестве нулевой? Если вы исследуете уровень загрязнения почвы или вод, то как сформулируете нулевую гипотезу: загрязнение присутствует, или нет загрязнения? А ведь от этого зависит объем выборки из общей популяции объектов.
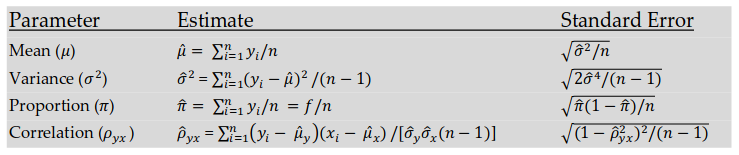
Исходная популяция, также как и выборка может иметь любое распределение, однако среднее значение имеет нормальное или гауссово распределение благодаря Центральной Предельной Теореме.
Относительно параметров распределения и среднего значения в частности возможно несколько типов умозаключений. Первое из них называется доверительным интервалом. Он указывает на интервал возможных значений параметра, с указанным коэффициентом доверия. Так например 100(1-α)% доверительный интервал для μ будет таким (Ур. 1).

- df — Степень свободы = n — 1, от английского «degrees of freedom».
- — Двусторонняя критическая величина,
t-критерий Стьюдента.
 — Двусторонняя критическая величина,
— Двусторонняя критическая величина, Второе из умозаключений — проверка гипотезы. Оно может быть примерно таким.
- H0: μ = h
- H1: μ > h
- H2: μ < h
С доверительным интервалом 100(1-α) для μ можно сделать выбор в пользу H1 и H2 :
- Если нижний предел доверительного интервала
100(1-α) < h, то тогда отвергаем H0 в пользу H2. - Если верхний предел доверительного интервала
100(1-α)> h, то тогда отвергаем H0 в пользу H1. - Если доверительного интервала
100(1-α)включает в себя h, то тогда мы не может отвергнуть H0 и такой результат считается неопределенным.
Если нам нужно проверить значение μ для одной выборки из общей совокупности, то критерий обретет вид.
Где  .
.
Доверительный интервал, погрешность и размер выборки
Возьмем самое первое уравнение и выразим оттуда ширину доверительного интервала (Ур. 2).

В некоторых случаях мы можем заменить t-статистику Стьюдента на z стандартного нормального распределения. Еще одним упрощением заменим половину от w на погрешность измерения E. Тогда наше уравнения примет вид (Ур. 3).

Как видим погрешность действительно уменьшается вместе с ростом количества входных данных. Откуда легко вывести искомое (Ур. 4).
![$n = left[frac{z_{alpha/2}*sigma}{E}right]^2$](https://habrastorage.org/getpro/habr/formulas/ab7/fd5/3c2/ab7fd53c29d17e7a5cfc343b0fa7ea8a.svg)
Практика — считаем с R
Проверим гипотезу о том, что среднее значение данной выборки количества насекомых в ловушке равно 1.
- H0: μ = 1
- H1: μ > 1
| Насекомые | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| Ловушки | 10 | 9 | 5 | 5 | 1 | 2 | 1 |
> x <- read.table("/tmp/tcounts.txt")
> y = unlist(x, use.names="false")
> mean(z);sd(z)
[1] 1.636364
[1] 1.654883Обратите внимание, что среднее и стандартное отклонение практически равны, что естественно для распределения Пуассона. Доверительный интервал 95% для t-статистики Стьюдента и df=32.
> qt(.975, 32)
[1] 2.036933и наконец получаем критический интервал для среднего значения: 1.05 — 2.22.
> μ=mean(z)
> st = qt(.975, 32)
> μ + st * sd(z)/sqrt(33)
[1] 2.223159
> μ - st * sd(z)/sqrt(33)
[1] 1.049568В итоге, следует отбраковать H0 и принять H1 так как с вероятностью 95%, μ > 1.
В том же самом примере, если принять, что нам известно действительное стандартное отклонение — σ, а не ее оценка полученная с помощью случайной выборки, можно рассчитать необходимое n для данной погрешности. Посчитаем для E=0.5.
> za2 = qnorm(.975)
> (za2*sd(z)/.5)^2
[1] 42.08144Поправка на ветер
На самом деле нет никаких причин, полагать, что нам будет известна σ (дисперсия), в то время как μ (среднее) нам еще только предстоит оценить. Из-за этого уравнение 4 имеет мало практической пользы, кроме особо рафинированных примеров из области комбинаторики, а реалистичное уравнение для n несколько сложнее при неизвестной σ (Ур. 5).

Обратите внимание, что σ в последнем уравнении не с шапкой (^), а тильдой (~). Это следствие того, что в самом начале у нас нет даже оценочного стандартного отклонения случайной выборки —  , и вместо нее мы используем запланированное —
, и вместо нее мы используем запланированное —  . Откуда же мы берем последнее? Можно сказать, что с потолка: экспертная оценка, грубые прикидки, прошлый опыт и т. д.
. Откуда же мы берем последнее? Можно сказать, что с потолка: экспертная оценка, грубые прикидки, прошлый опыт и т. д.
А что на счет второго слагаемого правой стороны 5-го уравнения, откуда оно взялось? Так как  , необходима поправка Гюнтера.
, необходима поправка Гюнтера.
Помимо уравнений 4 и 5 есть еще несколько приблизительно-оценочных формул, но это уже заслуживает отдельного поста.
Использованные материалы
- Sample sizes
- Hypothesis testing