

Заметил, что хосты очень плохо мониторятся через IPMI, никак не мог понять в чём дело. И вот сегодня звёзды сложились так, что удалось подметить некоторую закономерность в поведении хостов.
С помощью ipmitool получаем значения сенсоров одного из хостов. Получение информации о сенсорах IPMI с помощью ipmitool. В примере ниже это my_server_dns_name, не суть важно:
root@zabbix:~# ipmitool -I lanplus -H my_server_dns_name -U my_user -P my_password sensor list
***
FAN1 | 3200.000 | RPM | ok | 300.000 | 500.000 | 700.000 | 25300.000 | 25400.000 | 25500.000
FAN2 | 3100.000 | RPM | ok | 300.000 | 500.000 | 700.000 | 25300.000 | 25400.000 | 25500.000
FAN3 | 3100.000 | RPM | ok | 300.000 | 500.000 | 700.000 | 25300.000 | 25400.000 | 25500.000
FAN4 | na | | na | na | na | na | na | na | na
FAN5 | 3200.000 | RPM | ok | 300.000 | 500.000 | 700.000 | 25300.000 | 25400.000 | 25500.000
FAN6 | 3100.000 | RPM | ok | 300.000 | 500.000 | 700.000 | 25300.000 | 25400.000 | 25500.000
***
В качестве примера я оставил только сенсоры вентиляторов.
Если присмотреться, то четвёртого вентилятора нет, — это первый пункт, который следует взять на заметку. Вентилятора и правда нет, вот такой сервер. В шаблоне заббикса, который используется для этого хоста, имеются все сенсоры вентиляторов с первого по шестой и все в статусе enabled, — это второй пункт для заметки.
Третий пункт: в заббиксе относительно нормально отображаются значения первых трёх вентиляторов, хотя график всё равно рваный. А пятый и шестой почти не отображаются или не отображаются вовсе. Думал, что IPMI сервис плохо работает на серверах, но нет.
Случайно заметил в логах zabbix-сервера такую картину:
1174:20180816 IPMI agent item "ipmi.supermicro.fan4" on host "server1" failed: first network error, wait for 15 seconds
1174:20180816 IPMI agent item "ipmi.supermicro.fan4" on host "server2" failed: first network error, wait for 15 seconds
1174:20180816 resuming IPMI agent checks on host "server55": connection restored
1174:20180816 resuming IPMI agent checks on host "server66": connection restored
1174:20180816 IPMI agent item "ipmi.supermicro.fan4" on host "server3" failed: first network error, wait for 15 seconds
Это четвёртый пункт. Странность заключается в том, что сенсор один и тот же, а сервера разные.
Если обобщить все странности, то получается следующее:
- Zabbix-сервер имеет таблицу IPMI сенсоров и бежит циклом по этим сенсорам в алфавитном порядке.
- Берет FAN1, получает значение этого сенсора для каждого хоста, которому это значение нужно получить.
- Пишет полученные значения, потом берет следующий сенсор FAN2, потом FAN3, пока всё в порядке.
- Доходит до сенсора в состоянии «na» — у нас это FAN 4 — не находит его на server1 и пишет «first network error, wait for 15 seconds».
- И получение IPMI сенсоров для server1 останавливается на 15 секунд, для всех IPMI сенсоров!
- Дальше zabbix-сервер пытается найти FAN4 у server2, если его не находит, то » wait for 15 seconds».
- Пробегает по всем остальным хостам, уже не важно находит он у них FAN4 или нет, хосты заканчиваются.
- Zabbix-сервер берет FAN5, бежит по серверам, доходит до server1. А хост-то всё ещё » wait for 15 seconds», 15 секунд не прошли, заббикс пропускает этот сервер.
- В итоге для server1 значение FAN5 не записывается, хотя сенсор прекрасно работает.
- С FAN6 та же история, если 15 секунд не прошли, то значение не записывается.
- Потом 15 секунд простоя истекают, хост дальше нормально мониторится.
В результате имеем дырки не меньше 15 секунд в значениях у работающих IPMI сенсоров, рваные графики и даже вовсе пустые значения.
Что делать? Избавляться от «na» сенсоров. Проанализируем наши шаблоны. Если все сервера внутри шаблона имеют одинаковую конфигурацию, то ставим все сенсоры «na» в disabled. Если сервера имеют разную конфигурацию (у кого-то сенсор работает, у кого-то нет), то ставим все сенсоры «na» в disabled уже на каждом конкретном хосте.
Сделал так в рамках одного из шаблонов, — провалы прекратились, полёт нормальный.
Диагностика работы сервера и агента Zabbix. Самые простые способы найти причины неработоспособности.
Проблемы, проблемы, проблемы…
В предыдущей статье мы рассматривали процесс установки Zabbix. Сегодня мы коснемся основных способов диагностики работы сервера и агента Zabbix, а также решение некоторых возникающих проблем.
Ничего сверхестественного. Только базовая информация, которая дает представление о том куда нужно двигаться при наличии проблем в работе мониторинга на базе Zabbix.
Как себя чувствует сервер
Бывает, что на сервере возникают какие-либо проблемы, связанные как с самой службой Zabbix-сервера, так и с его взаимодействием с агентами или связанными компонентами. Первый источник информации, который может помочь в поиске причин проблем — это логи Zabbix-сервера. Еще одним важным источником данных может быть сама система мониторинга, которая мониторит сама себя.
Логи наше все
Логи по традиции мира *.nix хранятся в текстовых файлах и располагаются в каталоге ‘/var/log/zabbix’.
[ypermitin@zabbix zabbix]$ ls
zabbix_agentd.log zabbix_agentd.log-20201011 zabbix_server.log-20201004.gz
zabbix_agentd.log-20201004.gz zabbix_server.log zabbix_server.log-20201011
В этом же каталоге можно увидеть файлы логов Zabbix-агента. Чаще всего на сервере Zabbix для отслеживания работы сервера установлен агент. Да, Zabbix-сервер следит сам за собой.
Прочитать содержимое можно стандартными для Linux способами:
- Смотрим файл логов с возможностью прокрутки.
less /var/log/zabbix/zabbix_server.log
- Просмотр файла логов в реальном времени.
tail -f /var/log/zabbix/zabbix_server.log
- Смотрим первые записи
head /var/log/zabbix/zabbix_server.log
- Смотрим последние события
tail -n 30 /var/log/zabbix/zabbix_server.log
- Получаем только записи с ошибками
grep -i error /var/log/zabbix/zabbix_server.log
В общем, это самые простые способы прочитать содержимое файла логов. Если Вы знаете что нужно искать, то grep Вам в помощью. В противном случае в бой вступает tail, но можно выполнять анализ и более сложными способами.
Вот, например, вывод последних 10 событий из файла логов.
[ypermitin@zabbix zabbix]$ tail -n 10 /var/log/zabbix/zabbix_server.log
1370:20201016:230008.844 housekeeper [deleted 4601 hist/trends, 0 items/triggers, 0 events, 0 problems, 0 sessions, 0 alarms, 0 audit items in 0.047217 sec, idle for 1 hour(s)]
1370:20201017:000346.901 executing housekeeper
1370:20201017:000346.958 housekeeper [deleted 4857 hist/trends, 0 items/triggers, 0 events, 0 problems, 0 sessions, 0 alarms, 0 audit items in 0.053027 sec, idle for 1 hour(s)]
1386:20201017:002028.428 Zabbix agent item "system.swap.size[,free]" on host "YY-COMP" failed: first network error, wait for 15 seconds
1394:20201017:002043.521 Zabbix agent item "system.uptime" on host "YY-COMP" failed: another network error, wait for 15 seconds
1394:20201017:002058.554 Zabbix agent item "agent.ping" on host "YY-COMP" failed: another network error, wait for 15 seconds
1394:20201017:002113.579 temporarily disabling Zabbix agent checks on host "YY-COMP": host unavailable
1394:20201017:003815.366 enabling Zabbix agent checks on host "YY-COMP": host became available
1370:20201017:010352.434 executing housekeeper
1370:20201017:010352.503 housekeeper [deleted 4599 hist/trends, 0 items/triggers, 0 events, 0 problems, 0 sessions, 0 alarms, 0 audit items in 0.063396 sec, idle for 1 hour(s)]
Здесь мы видим события процесса housekeeper, который отвечает за удаление устаревшей информации из базы данных мониторинга. Далее идут более интересные события об ошибке связи с хостом “YY-COMP”, а также события последующего восстановления соединения с агентом этого хоста.
1386:20201017:002028.428 Zabbix agent item "system.swap.size[,free]" on host "YY-COMP" failed: first network error, wait for 15 seconds
1394:20201017:002043.521 Zabbix agent item "system.uptime" on host "YY-COMP" failed: another network error, wait for 15 seconds
1394:20201017:002058.554 Zabbix agent item "agent.ping" on host "YY-COMP" failed: another network error, wait for 15 seconds
1394:20201017:002113.579 temporarily disabling Zabbix agent checks on host "YY-COMP": host unavailable
1394:20201017:003815.366 enabling Zabbix agent checks on host "YY-COMP": host became available
В любом случае, основным источником данных о том, что и как делает процесс Zabbix-сервера, есть ли у него проблемы и другую связанную с ним информацию можно найти в его логах. Метод “тыка” тоже работает, но эффективнее просто посмотреть в файл лога событий.
Мониторинг системы мониторинга
Благодаря тому, что Zabbix позволяет собирает метрики о состоянии самого себя, мы можем отслеживать некоторые проблемы с его помощью. После установки сервера, по умолчанию в списке хостов содержится сам сервер с шаблоном “Template App Zabbix Server”.

Этот шаблон является ключевым для диагностики работы Zabbix, т.к. содержит множество полезных метрик и триггеров на критичные события.

Например, если Вы увидите уведомления о проблеме “Zabbix poller processes more than 75% busy” от одного из триггеров этого шаблона, то идем в официальную документацию и читаем что это. Можно увидеть, что проблему можно решить изменив параметр “StartPollers” в файле конфигурации Zabbix-сервера.
Вообще, оптимизация настроек этой системы мониторинга отдельная тема, но должно быть понятно, что следить за сервером Zabbix является неотъемлемой частью мониторинга. Иначе как Вы узнаете, что пора актуализировать настройки сервера или проапгрейдить железо?
Все в очередь
Кроме логов и мониторинга Zabbix-сервера есть еще один важный показатель, демонстрирующий общую картину производительности процессов системы мониторинга. Причем помогает диагностировать проблемы не только в работе сервера, но и агентов Zabbix.
Речь идет про очередь обработки элементов данных, которая отлично описана в официальной документации. На следующем скриншоте показана идеальная картина, когда никаких очередей нет и все элементы обрабатываются за минимальное время.

Самыми распространёнными причинами увеличения очереди являются:
- Агент сбора данных стал недоступен и не присылает данные / не может ответить на запрос.
- У сервера не хватает ресурсов для выполнения обработки присланных элементов данных или опроса хостов (зависит от типа агента — активный или пассивный).
В случаях, когда Вы будете наблюдать большие значения очередей с периодом обработки более 1 минуты, то стоит насторожиться и начать диагностику сервера и агентов.
Вы всегда можете посмотреть элементы очереди детально, чтобы понять, где именно появилась проблема. Плюс ко всему, очередь обработки сообщений можно добавить в метрики сбора данных мониторинга и привязать на них триггеры. Таким образом, очереди позволяют отслеживать общее состояние как сервера Zabbix, так и состояние всего мониторинга с учетом агентов.
База данных требует внимания
Zabbix хранит данные метрик в одной из поддерживаемых СУБД: MySQL или PostgreSQL. Для оптимальной производительности обязательно нужно выполнить их настройку. Я предпочитаю использовать PostgreSQL, но тут все полностью зависит от задач.
Касательно PostgreSQL нужно обязательно адаптировать ее настройки под ресурсы сервера, т.к. по умолчанию там установлены максимальные ограничения на используемую память и другие ресурсы. Рекомендую зайти на сайт PGTune, который поможет подобрать параметры СУБД под Ваш сервер. Просто берете и переносите их в свой файл конфигурации “postgresql.conf”.
Конечно, со временем может понадобиться адаптировать эти параметры под свою нагрузку и задачи. Подробнее о настройках Вы можете прочитать здесь.

То же самое относится и к MySQL. Вы можете обратиться к официальной документации, чтобы узнать больше.
Главное помнить, что настройки сервера баз данных являются ключевым фактором для достижения высокой производительности всей системы мониторинга.
Агент еще жив
Основные способы диагностики сервера Zabbix мы рассмотрели. А что на счет агентов на хостах, которые входят в мониторинг?
Выше уже было упомянуто, что у агента есть свои логи. Именно они и являются основным источником данных для диагностики его работы. Если мы говорим о *.nix системах, то обычно файл лога находится в “/var/log/zabbix/zabbix_agent.log”. Вот, например, его содержимое при старте процесса агента.
[ypermitin@zabbix zabbix]$ tail -n 30 /var/log/zabbix/zabbix_agentd.log
88139:20201017:164146.511 Starting Zabbix Agent [Zabbix server]. Zabbix 4.0.25 (revision 32662425e6).
88139:20201017:164146.511 **** Enabled features ****
88139:20201017:164146.511 IPv6 support: YES
88139:20201017:164146.511 TLS support: YES
88139:20201017:164146.511 **************************
88139:20201017:164146.511 using configuration file: /etc/zabbix/zabbix_agentd.conf
88139:20201017:164146.511 agent #0 started [main process]
88140:20201017:164146.511 agent #1 started [collector]
88141:20201017:164146.512 agent #2 started [listener #1]
88144:20201017:164146.513 agent #5 started [active checks #1]
88143:20201017:164146.515 agent #4 started [listener #3]
88142:20201017:164146.516 agent #3 started [listener #2]
Это идеальный вариант, когда агент был запущен и никаких проблем с его работой не наблюдается. Но там могут быть и ошибки или информация о проблемах связи. Например, вот это событие говорит о том, что что-то блокирует доступ агента к серверу Zabbix.
3900:20201017:002349.716 active check configuration update from [192.168.11.149:10051] started to fail (cannot connect to [[192.168.11.149]:10051]: (null))
Может не открыт порт на сервере? Или сервер недоступен? Или ошибка в конфигурационном файле агента?
Аналогичный файл лога есть для агентов всех поддерживаемых операционных систем, в том числе и Windows. Его расположение можно уточнить в самом конфигурационном файле агента в параметре “LogFile”. Для Windows это может быть каталог самого агента, например:
### Option: LogFile
# Log file name for LogType 'file' parameter.
#
# Mandatory: no
# Default:
# LogFile=
LogFile=C:Program FilesZabbixAgentzabbix_agentd.log
В любом случае, если у Вас проблемы в работе агента, то первым делом идем в его логи и смотрим что вообще происходит.
Решение некоторых проблем
Рассмотрим решение некоторых проблем в работе сервера и агента. Это ни в коем случае не полноценный мануал, а скорее пара заметок. Небольшая порция “траблшутинга”. Более развернутую информацию Вы можете найти в официальной Wiki.
Немного опечатались
Иногда бывает так, что порты и все доступы настроены, агент установлен, ошибок в логах нет, но метрики не приходят или приходят не полностью. В самом Zabbix хост “горит зеленым” и непонятно, что вообще происходит.

Можно потратить много времени на разбор ситуации, а причина окажется очень проста — ошибка в файле конфигурации из-за “копипасты”. То есть конфигурацию скопировали, но в файле не поменяли параметр “Hostname”. В итоге сервер Zabbix говорит, что агент доступен, но сам агент присылает данные для другого хоста. Вот так выглядит список дисков для проблемной машины. Нет никакой информации о дисках, но при этом общие показатели агент все же передал.

Как только мы исправим в файле конфигурации параметр “Hostname” на нужный (в нашем случае это “SRV-SQL-01-VM”), то картина сразу же изменится. В списке появятся все диски сервера.

Данные могут появиться не сразу, т.к. правила обнаружения выполняются не так часто, как получение обычных метрик, но Вы можете запустить их вручную в настройках хоста.
Копипаст — зло! Будьте осторожны!
Ребут и агента нет
Бывают случаи, когда агент был успешно установлен и настроен на хосте, мониторинг работает как надо. НО! При очередном запланированном перезапуске сервера (хоста) Zabbix-агент не смог запуститься.
Причин тому может быть несколько:
- Агент запускается от доменной учетной записи, но на момент старта сервера связи с доменом не оказалось.
- В момент запуска агент пытался запуститься, когда еще не “поднялся” доступ к сети.
При этом в файле лога агента может не быть какой-либо полезной информации, но она есть в системных журналах ОС. Чаще всего это поведение встречал в ОС Windows.
Решение достаточно простое: нужно установить для службы Windows режим запуска “Автоматически (отложенный запуск)”. В большинстве случаев проблема будет решена.

Быстро и просто!
Особые проблемы со счетчиками
Особой проблемой, которая встречается не очень часто, бывают проблемы со счетчиками производительности Windows. После настройки мониторинга на сервере можно увидеть для хоста элементы данных со статусом “Не поддерживается”. При этом все они получаются через показатели производительности Windows. Обратившись к логам агента Zabbix можно увидеть следующее.
zabbix agent log: check_counter_path(): cannot make counterpath
zabbix agent log: A required argument is missing or not correct.... active check "perf_counter[....]" is not supported
При этом для хоста у элементов данных будет такая ошибка.
ZBX_NOTSUPPORTED: Cannot obtain system information.
Проблема в некорректном списке доступных счетчиков производительности Windows на хосте с агентом, то есть на машине, которую мы собираемся мониторить. Можно проверить наличие нужного счетчика через “Монитор производительности” (perfmon.exe) или через ветку реестра:
"HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindows NTCurrentVersionPerflib09"
# Ключ "Counter" содержит список всех доступных счетчиков производительности.
Если нужного счетчика нет, то можно попытаться перестроить все счетчики ОС командой:
lodctr /r
# Утилита находится в "C:WINDOWSSystem32"
В большинстве случаев это помогает. Если остаются проблемы со счетчиками производительности сторонних приложений, то нужно изучить документацию по этим счетчикам. Например, для Microsoft SQL Server можно отдельно восстановить счетчики из поставляемых настроек. Подробнее можно узнать здесь.
Счетчики производительности для мониторинга Windows — отличный инструмент. И его, конечно же, нужно использовать.
Таймаут выполнения скриптов
Еще небольшой ошибкой может быть ситуация, когда на сервер не поступают данные по каким-либо элементам данных, а в логах агента можно увидеть ошибки вида:
ZBX_NOTSUPPORTED: Timeout while executing a shell script
Так происходит, поскольку выполняемый скрипт не укладывается в заданное время выполнения. Время задается также в конфигурации агента Zabbix и по умолчанию составляет 3 секунды.
### Option: Timeout
# Spend no more than Timeout seconds on processing
#
# Mandatory: no
# Range: 1-30
# Default:
# Timeout=3
Имеется три основных варианта решения:
- Увеличить таймаут до подходящего значения. Например, до 30 секунд:
### Option: Timeout
# Spend no more than Timeout seconds on processing
#
# Mandatory: no
# Range: 1-30
# Default:
# Timeout=3
Timeout=30
-
Второй вариант — разобраться в причинах долгого выполнения и попытаться их исправить. Конечно, если это возможно.
-
Отказаться от сбора этих метрик

В любом случае, посмотрите почему скрипт может выполняться дольше, чем запланировано. Только после этого меняйте настройки.
Продолжение следует
Это была еще одна небольшая публикация по теме мониторинга с помощью Zabbix. В следующих статьях мы поговорим об обновлении Zabbix с версии 4.0 на 5.0, создадим свой шаблон для сбора метрик и рассмотрим некоторые особенности этого процесса, настроим уведомления в Telegram-канал, а также получении данных с Prometheus и визуализации данных в Grafana. И, конечно же, оптимизация производительности сервера мониторинга Zabbix!
Будьте на связи 
Будьте в курсе
Создание материалов будет продолжаться. Хотите быть в курсе последних обновлений? Подписывайтесь на канал.
По любым вопросам пишите на электронную почту. Адрес в самом низу страницы.
Recommended: ASR Pro
Download this software and fix your PC in minutes.
In the past few days, some users reported that they faced the first network error from zabbix.
6024: 20200313: 153058.081 SNMP agent element 'net.if.status [ifOperStatus.232]' on node 'sw-isp-1.domain.net' failed: first network error, please wait 15 seconds 5887: 20200313: 150425.014 Error of Zabbix agent element "net.if.in [xenbr3]" when building "xen-qa-5.srv.domain": first network error, hang for 15 seconds 6024: 20200313: 150425.029 Zabbix insurance agent item "system.boottime" on host "xen-qa-2.srv.domain" failed: first network error, wait 11 seconds 6048: 20200313: 150425.072 Zabbix agent module "vfs.fs.size [/ var / log, pfree]" on host "xen-qa-1.srv.domain" failed: first network error, wait 13 seconds 5906: 20200313: 150425.101 Zabbix agent entry "net.if.in [vive10.2]" on host "xen-qa-6.srv.domain" failed first: market error, please wait 15 seconds 6052: 20200313: 150449.791 Zabbix resumes agent checks via host "xen-qa-1.srv.domain": connection reestablished 6128: 20200313: 150449.791 Return to Zabbix agent when checking table "xen-qa-6.srv.domain": connection restored 6073: 20200313: 150449.791 Returns to Zabbix agent "xen-qa-2.srv.domain": connection has been restored 6094: 20200313: 150449.797 Continue checking host Zabbix agent for "xen-qa-5.srv.domain": port restored 6009: 20200313: 150842.939 Zabbix agent target "net.if.out [eth2]" on host "xen-qa-1.srv.domain" failed: network error firstbka wait 17 seconds 5981: 20200313: 150842 .946 Zabbix agent item "net.if.out [vive16.0]" on host "xen-qa-5.srv.domain" failed: first website 2.0 error, please wait 15 seconds 5928: 20200313: 150843.096 Zabbix agent item "net.if.out [vive26.3]" failed on host "xen-qa-4.srv.domain": first web 2.0 error, wait seconds 15 6129: 20200313: 150859.177 Returning to Zabbix agent checks many "xen-qa-5.srv.domain": connection reestablished 6077: 20200313: 150859.177 Zabbix agent type "xen-qa-1.srv.domain" is being checked: connection reestablished 6118: 20200313: 150859.188 Zabbix falls back to agent checks on host "xen-qa-4.srv.domain": greetings restored 5927: 20200313: 151413.109 Zabbix agent "net.if.in [vive1.3]" on host "xen-qa-4.srv.domain" does not work at first: network error, please wait 17 seconds 5955: 20200313: 151413.138 Zabbix agent program 'net.if.in [vive17.3]' failed on host 'xen-qa-5.srv.domain': transient error, network wait 15 seconds 6013: 20200313: 151413.156 Zabbix agent item "vfs.fs.size [/ var / log, used]" failed on host "xen-qa-6.srv.domain": first internet connection error, please wait 15 seconds 5929: 20200313: 151413.163 Failure of Zabbix agent item "net.if.out [vive28.1]" on host server "xen-qa-3.srv.domain": first network error, 15 seconds delay 6126: 20200313: 151428.459 ReturnGo to agent Zabbix checks host on your "xen-qa-6.srv.domain": connection reestablished 6055: 20200313: 151428.462 Zabbix agent continuation to check host "xen-qa-4.srv.domain": greetings restored 6126: 20200313: 151428.468 Continue checking by Zabbix employee on host "xen-qa-5.srv.domain": add-on restored 6099: 20200313: 151428.470 will continue checking the Zabbix agent host for "xen-qa-3.srv.domain": connection reestablished
I may have found out that there is more, but I think mine might be a little different, so I’ll make another post …

I have installed Zabbix 2.2.4. I have nvps 24 so it doesn’t really matter. I think even the processor and terminals are fine …
Recommended: ASR Pro
Are you tired of your computer running slowly? Is it riddled with viruses and malware? Fear not, my friend, for ASR Pro is here to save the day! This powerful tool is designed to diagnose and repair all manner of Windows issues, while also boosting performance, optimizing memory, and keeping your PC running like new. So don’t wait any longer — download ASR Pro today!

The problem is that I have more hosts with the disease, as explained, specifically for one host:
The host has more than 300 titles (about 330). I check the connection with the internet host every 4 seconds and look for its “nameStation” every 10 seconds. The rest of the items are read every 150 seconds.

The problem starts when Zabbix starts up with a host request for more than 300 items … As far as tcpdump performance is concerned, there are manyo requests that are answered almost simultaneously, but only occasionally by snmp. And after an error occurs and Zabbix does not read any new values, perhaps the host (late) even triggers snmp responses …
After a while you continue and the situation repeats itself. This works until Zabbix wants to install these 300+ items. It’s almost 5 minutes …
1823: 20140904: 123638.996 Host SNMP agent part ‘rTxFrequency’ on ‘X’ failed: error in first circle, please wait 15 seconds
1893: 20140904: 123653.913 Resume SNMP Management Agent if Host X: Connection Reestablished
1824: 20140904: 124138.988 SNMP Agent Element Node ‘ifType [1]’ found on ‘X’ failed: first network error held for 15 seconds
1888: 20140904: 124154.005 Return to SNMP agent checks on storage “X”: connection restored
1857: 20140904: 124638.970 SNMP Alternate Agent “stTermServNumber” on Host “X” Broken: First Network Error, Wait 15 Seconds
1884: 20140904: 124654.137 Resuming SNMP advisor checks on host “X”: ownership restored
Can I somehow configure Not zabbix so that you want to have all the values ”withonce “?
(I think maybe changing the repetition to other values could solve your problem? Instead of 300 seconds, set yourself to 290 seconds, 291 seconds, 292 seconds, …)
Or in newer Zabbix (2 version 4), where there is a hint in the exception notes (for the beta provided by the experts), the snmp-bulk request would be customizable … so I could say “just ask to find 5 values in the big quantity of another request “?
Download this software and fix your PC in minutes.
Zabbix 첫 번째 네트워크 오류
Pervaya Setevaya Oshibka Zabbix
Zabbix Erster Netzwerkfehler
Primer Error De Red De Zabbix
Zabbix Eerste Netwerkfout
Zabbix Forsta Natverksfel
Zabbix Pierwszy Blad Sieci

Содержание
- Диагностика работы Zabbix
- Проблемы, проблемы, проблемы…
- Как себя чувствует сервер
- Логи наше все
- Мониторинг системы мониторинга
- Все в очередь
- База данных требует внимания
- Агент еще жив
- Решение некоторых проблем
- Немного опечатались
- Ребут и агента нет
- Особые проблемы со счетчиками
- Таймаут выполнения скриптов
- Продолжение следует
- Будьте в курсе
- Zabbix — проблема с получением значений некоторых IPMI сенсоров
Диагностика работы Zabbix
Диагностика работы сервера и агента Zabbix. Самые простые способы найти причины неработоспособности.
Проблемы, проблемы, проблемы…
В предыдущей статье мы рассматривали процесс установки Zabbix. Сегодня мы коснемся основных способов диагностики работы сервера и агента Zabbix, а также решение некоторых возникающих проблем.
Ничего сверхестественного. Только базовая информация, которая дает представление о том куда нужно двигаться при наличии проблем в работе мониторинга на базе Zabbix.
Как себя чувствует сервер
Бывает, что на сервере возникают какие-либо проблемы, связанные как с самой службой Zabbix-сервера, так и с его взаимодействием с агентами или связанными компонентами. Первый источник информации, который может помочь в поиске причин проблем — это логи Zabbix-сервера. Еще одним важным источником данных может быть сама система мониторинга, которая мониторит сама себя.
Логи наше все
Логи по традиции мира *.nix хранятся в текстовых файлах и располагаются в каталоге ‘/var/log/zabbix’.
В этом же каталоге можно увидеть файлы логов Zabbix-агента. Чаще всего на сервере Zabbix для отслеживания работы сервера установлен агент. Да, Zabbix-сервер следит сам за собой.
Прочитать содержимое можно стандартными для Linux способами:
- Смотрим файл логов с возможностью прокрутки.
- Просмотр файла логов в реальном времени.
- Получаем только записи с ошибками
В общем, это самые простые способы прочитать содержимое файла логов. Если Вы знаете что нужно искать, то grep Вам в помощью. В противном случае в бой вступает tail, но можно выполнять анализ и более сложными способами.
Вот, например, вывод последних 10 событий из файла логов.
Здесь мы видим события процесса housekeeper, который отвечает за удаление устаревшей информации из базы данных мониторинга. Далее идут более интересные события об ошибке связи с хостом “YY-COMP”, а также события последующего восстановления соединения с агентом этого хоста.
В любом случае, основным источником данных о том, что и как делает процесс Zabbix-сервера, есть ли у него проблемы и другую связанную с ним информацию можно найти в его логах. Метод “тыка” тоже работает, но эффективнее просто посмотреть в файл лога событий.
Мониторинг системы мониторинга
Благодаря тому, что Zabbix позволяет собирает метрики о состоянии самого себя, мы можем отслеживать некоторые проблемы с его помощью. После установки сервера, по умолчанию в списке хостов содержится сам сервер с шаблоном “Template App Zabbix Server”.
Этот шаблон является ключевым для диагностики работы Zabbix, т.к. содержит множество полезных метрик и триггеров на критичные события.
Например, если Вы увидите уведомления о проблеме “Zabbix poller processes more than 75% busy” от одного из триггеров этого шаблона, то идем в официальную документацию и читаем что это. Можно увидеть, что проблему можно решить изменив параметр “StartPollers” в файле конфигурации Zabbix-сервера.
Вообще, оптимизация настроек этой системы мониторинга отдельная тема, но должно быть понятно, что следить за сервером Zabbix является неотъемлемой частью мониторинга. Иначе как Вы узнаете, что пора актуализировать настройки сервера или проапгрейдить железо?
Все в очередь
Кроме логов и мониторинга Zabbix-сервера есть еще один важный показатель, демонстрирующий общую картину производительности процессов системы мониторинга. Причем помогает диагностировать проблемы не только в работе сервера, но и агентов Zabbix.
Речь идет про очередь обработки элементов данных, которая отлично описана в официальной документации. На следующем скриншоте показана идеальная картина, когда никаких очередей нет и все элементы обрабатываются за минимальное время.
Самыми распространёнными причинами увеличения очереди являются:
- Агент сбора данных стал недоступен и не присылает данные / не может ответить на запрос.
- У сервера не хватает ресурсов для выполнения обработки присланных элементов данных или опроса хостов (зависит от типа агента — активный или пассивный).
В случаях, когда Вы будете наблюдать большие значения очередей с периодом обработки более 1 минуты, то стоит насторожиться и начать диагностику сервера и агентов.
Вы всегда можете посмотреть элементы очереди детально, чтобы понять, где именно появилась проблема. Плюс ко всему, очередь обработки сообщений можно добавить в метрики сбора данных мониторинга и привязать на них триггеры. Таким образом, очереди позволяют отслеживать общее состояние как сервера Zabbix, так и состояние всего мониторинга с учетом агентов.
База данных требует внимания
Zabbix хранит данные метрик в одной из поддерживаемых СУБД: MySQL или PostgreSQL. Для оптимальной производительности обязательно нужно выполнить их настройку. Я предпочитаю использовать PostgreSQL, но тут все полностью зависит от задач.
Касательно PostgreSQL нужно обязательно адаптировать ее настройки под ресурсы сервера, т.к. по умолчанию там установлены максимальные ограничения на используемую память и другие ресурсы. Рекомендую зайти на сайт PGTune, который поможет подобрать параметры СУБД под Ваш сервер. Просто берете и переносите их в свой файл конфигурации “postgresql.conf”.
Конечно, со временем может понадобиться адаптировать эти параметры под свою нагрузку и задачи. Подробнее о настройках Вы можете прочитать здесь.
То же самое относится и к MySQL. Вы можете обратиться к официальной документации, чтобы узнать больше.
Главное помнить, что настройки сервера баз данных являются ключевым фактором для достижения высокой производительности всей системы мониторинга.
Агент еще жив
Основные способы диагностики сервера Zabbix мы рассмотрели. А что на счет агентов на хостах, которые входят в мониторинг?
Выше уже было упомянуто, что у агента есть свои логи. Именно они и являются основным источником данных для диагностики его работы. Если мы говорим о *.nix системах, то обычно файл лога находится в “/var/log/zabbix/zabbix_agent.log”. Вот, например, его содержимое при старте процесса агента.
Это идеальный вариант, когда агент был запущен и никаких проблем с его работой не наблюдается. Но там могут быть и ошибки или информация о проблемах связи. Например, вот это событие говорит о том, что что-то блокирует доступ агента к серверу Zabbix.
Может не открыт порт на сервере? Или сервер недоступен? Или ошибка в конфигурационном файле агента?
Аналогичный файл лога есть для агентов всех поддерживаемых операционных систем, в том числе и Windows. Его расположение можно уточнить в самом конфигурационном файле агента в параметре “LogFile”. Для Windows это может быть каталог самого агента, например:
В любом случае, если у Вас проблемы в работе агента, то первым делом идем в его логи и смотрим что вообще происходит.
Решение некоторых проблем
Рассмотрим решение некоторых проблем в работе сервера и агента. Это ни в коем случае не полноценный мануал, а скорее пара заметок. Небольшая порция “траблшутинга”. Более развернутую информацию Вы можете найти в официальной Wiki.
Немного опечатались
Иногда бывает так, что порты и все доступы настроены, агент установлен, ошибок в логах нет, но метрики не приходят или приходят не полностью. В самом Zabbix хост “горит зеленым” и непонятно, что вообще происходит.
Можно потратить много времени на разбор ситуации, а причина окажется очень проста — ошибка в файле конфигурации из-за “копипасты”. То есть конфигурацию скопировали, но в файле не поменяли параметр “Hostname”. В итоге сервер Zabbix говорит, что агент доступен, но сам агент присылает данные для другого хоста. Вот так выглядит список дисков для проблемной машины. Нет никакой информации о дисках, но при этом общие показатели агент все же передал.
Как только мы исправим в файле конфигурации параметр “Hostname” на нужный (в нашем случае это “SRV-SQL-01-VM”), то картина сразу же изменится. В списке появятся все диски сервера.
Данные могут появиться не сразу, т.к. правила обнаружения выполняются не так часто, как получение обычных метрик, но Вы можете запустить их вручную в настройках хоста.
Копипаст — зло! Будьте осторожны!
Ребут и агента нет
Бывают случаи, когда агент был успешно установлен и настроен на хосте, мониторинг работает как надо. НО! При очередном запланированном перезапуске сервера (хоста) Zabbix-агент не смог запуститься.
Причин тому может быть несколько:
- Агент запускается от доменной учетной записи, но на момент старта сервера связи с доменом не оказалось.
- В момент запуска агент пытался запуститься, когда еще не “поднялся” доступ к сети.
При этом в файле лога агента может не быть какой-либо полезной информации, но она есть в системных журналах ОС. Чаще всего это поведение встречал в ОС Windows.
Решение достаточно простое: нужно установить для службы Windows режим запуска “Автоматически (отложенный запуск)”. В большинстве случаев проблема будет решена.
Быстро и просто!
Особые проблемы со счетчиками
Особой проблемой, которая встречается не очень часто, бывают проблемы со счетчиками производительности Windows. После настройки мониторинга на сервере можно увидеть для хоста элементы данных со статусом “Не поддерживается”. При этом все они получаются через показатели производительности Windows. Обратившись к логам агента Zabbix можно увидеть следующее.
При этом для хоста у элементов данных будет такая ошибка.
Проблема в некорректном списке доступных счетчиков производительности Windows на хосте с агентом, то есть на машине, которую мы собираемся мониторить. Можно проверить наличие нужного счетчика через “Монитор производительности” (perfmon.exe) или через ветку реестра:
Если нужного счетчика нет, то можно попытаться перестроить все счетчики ОС командой:
В большинстве случаев это помогает. Если остаются проблемы со счетчиками производительности сторонних приложений, то нужно изучить документацию по этим счетчикам. Например, для Microsoft SQL Server можно отдельно восстановить счетчики из поставляемых настроек. Подробнее можно узнать здесь.
Счетчики производительности для мониторинга Windows — отличный инструмент. И его, конечно же, нужно использовать.
Таймаут выполнения скриптов
Еще небольшой ошибкой может быть ситуация, когда на сервер не поступают данные по каким-либо элементам данных, а в логах агента можно увидеть ошибки вида:
Так происходит, поскольку выполняемый скрипт не укладывается в заданное время выполнения. Время задается также в конфигурации агента Zabbix и по умолчанию составляет 3 секунды.
Имеется три основных варианта решения:
- Увеличить таймаут до подходящего значения. Например, до 30 секунд:
Второй вариант — разобраться в причинах долгого выполнения и попытаться их исправить. Конечно, если это возможно.
Отказаться от сбора этих метрик 🙂
В любом случае, посмотрите почему скрипт может выполняться дольше, чем запланировано. Только после этого меняйте настройки.
Продолжение следует
Это была еще одна небольшая публикация по теме мониторинга с помощью Zabbix. В следующих статьях мы поговорим об обновлении Zabbix с версии 4.0 на 5.0, создадим свой шаблон для сбора метрик и рассмотрим некоторые особенности этого процесса, настроим уведомления в Telegram-канал, а также получении данных с Prometheus и визуализации данных в Grafana. И, конечно же, оптимизация производительности сервера мониторинга Zabbix!
Будьте на связи 🙂
Будьте в курсе
Создание материалов будет продолжаться. Хотите быть в курсе последних обновлений? Подписывайтесь на канал.
По любым вопросам пишите на электронную почту. Адрес в самом низу страницы.
Источник
Zabbix — проблема с получением значений некоторых IPMI сенсоров


Заметил, что хосты очень плохо мониторятся через IPMI, никак не мог понять в чём дело. И вот сегодня звёзды сложились так, что удалось подметить некоторую закономерность в поведении хостов.
С помощью ipmitool получаем значения сенсоров одного из хостов. Получение информации о сенсорах IPMI с помощью ipmitool. В примере ниже это my_server_dns_name, не суть важно:
В качестве примера я оставил только сенсоры вентиляторов.
Если присмотреться, то четвёртого вентилятора нет, — это первый пункт, который следует взять на заметку. Вентилятора и правда нет, вот такой сервер. В шаблоне заббикса, который используется для этого хоста, имеются все сенсоры вентиляторов с первого по шестой и все в статусе enabled, — это второй пункт для заметки.
Третий пункт: в заббиксе относительно нормально отображаются значения первых трёх вентиляторов, хотя график всё равно рваный. А пятый и шестой почти не отображаются или не отображаются вовсе. Думал, что IPMI сервис плохо работает на серверах, но нет.
Случайно заметил в логах zabbix-сервера такую картину:
Это четвёртый пункт. Странность заключается в том, что сенсор один и тот же, а сервера разные.
Если обобщить все странности, то получается следующее:
- Zabbix-сервер имеет таблицу IPMI сенсоров и бежит циклом по этим сенсорам в алфавитном порядке.
- Берет FAN1, получает значение этого сенсора для каждого хоста, которому это значение нужно получить.
- Пишет полученные значения, потом берет следующий сенсор FAN2, потом FAN3, пока всё в порядке.
- Доходит до сенсора в состоянии «na» — у нас это FAN 4 — не находит его на server1 и пишет «first network error, wait for 15 seconds».
- И получение IPMI сенсоров для server1 останавливается на 15 секунд, для всех IPMI сенсоров!
- Дальше zabbix-сервер пытается найти FAN4 у server2, если его не находит, то » wait for 15 seconds».
- Пробегает по всем остальным хостам, уже не важно находит он у них FAN4 или нет, хосты заканчиваются.
- Zabbix-сервер берет FAN5, бежит по серверам, доходит до server1. А хост-то всё ещё » wait for 15 seconds», 15 секунд не прошли, заббикс пропускает этот сервер.
- В итоге для server1 значение FAN5 не записывается, хотя сенсор прекрасно работает.
- С FAN6 та же история, если 15 секунд не прошли, то значение не записывается.
- Потом 15 секунд простоя истекают, хост дальше нормально мониторится.
В результате имеем дырки не меньше 15 секунд в значениях у работающих IPMI сенсоров, рваные графики и даже вовсе пустые значения.
Что делать? Избавляться от «na» сенсоров. Проанализируем наши шаблоны. Если все сервера внутри шаблона имеют одинаковую конфигурацию, то ставим все сенсоры «na» в disabled. Если сервера имеют разную конфигурацию (у кого-то сенсор работает, у кого-то нет), то ставим все сенсоры «na» в disabled уже на каждом конкретном хосте.
Сделал так в рамках одного из шаблонов, — провалы прекратились, полёт нормальный.
Источник
На днях, у меня наконец-то дошли руки до обновления Zabbix.
С момента прочтения статьи Вышел Zabbix 2.2 в соответствующем блоге, я не мог дождаться, когда же в Gentoo размаскируют версию 2.2. Практически не было такого нововведения в этой версии, которое бы мне не было интересно и полезно в «быту». Это и мониторинг VMware, и ускорение системы, и улучшения в LLDP, короче практически каждый пункт.
Шли месяцы, а версии 2.2 не было даже в замаскированных.
Иногда я откладываю текучку в сторону и занимаюсь чем-нибудь «параллельным» относительно срочных и важных задач и работ. В этот раз я вспомнил о желании обновить Zabbix до версии 2.2.
Проверил в маскированных*, ну наконец-то, есть 2.2.5
Ну все, переходим, прошел уже год с момента выпуска, версия stable’е не бывает, так что что бы ни случилось, решим.
Размаскировываем, собираем везде где нужно (основное это конечно сервер и прокси), перезапускаем. Переустанавливаем web интерфейс ииии…
И ничего, идет обновление БД.
Штука это не быстрая, база у меня не маленькая, а потом процесс вообще завис.
Ну думаю, началось, как говорится не успели начать, а уже все плохо.
В логах mysql было Error number 28 means ‘No space left on device’, места везде было более чем достаточно. Как говорится «при наличии гугла, я богоподобен» (с), не сразу, но удалось найти/догадаться что этот device это ibdata1 и ibdata2, размер которых регулируется параметром innodb_data_file_path. После того как я поменял max с 256M на 512М обновление базы завершилось успешно и сервер стартанул.
На прокси тоже были проблемы, и тоже из-за базы данных. Просто sqlite не обновляется, поэтому останавливаем прокси, удаляем старую базу и запускаем прокси. Как говорится внимательнее читайте Upgrade notes
Конечно за время обновления накопилось много просроченных данных, поэтому проверяем то что можем проверить, что в интерфейсе все показывается, и ждем, пока все устаканится и актуализируется.
Через пару часов, смотрим график:
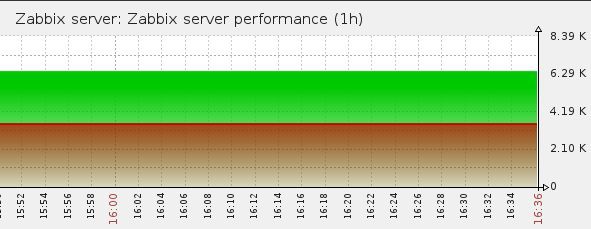
День начинал становиться томным.
У нас очередь. Откуда?.. Основные просроченные данные с одного из прокси. А что за данные. А данные получаемые по SNMPv3.
Отлично. Были и раньше у меня к этому функционалу вопросы, но все руки не доходили, да была надежда что обновление эти вопросы решит. А тут система становится практически не работоспособной. В свое время, читая о том как люди с помощью одного сервера или прокси мониторят сотни сетевых девайсов я не мог понять в чем же дело? У меня несколько десятков устройств, и все работает на пределе. Уж и БД оптимизирована донельзя, и сервер положен на быстрый датастор, и памяти ему дано немало.
Откатываться назад не хотелось, поэтому было решено во что бы то ни стало попробовать разобраться с проблемой.
Я выбрал один из прокси, за которым больше всего SNMP устройств, и начал разбираться.
Вот что у нас в логах на прокси**:
4447:20141218:124053.605 SNMP agent item "ifAdminStatus.["10130"]" on host "co-xx02" failed: first network error, wait for 15 seconds
4468:20141218:124108.270 resuming SNMP agent checks on host "co-xx02": connection restored
И так беспорядочно по всем SNMP хостам, с разными итемами.
Сетевых проблем у меня точно нет, но для верности я конечно же по быстрому проверил связность, скорость и логи коммутаторов. Проверяем сам SNMP с помощью snmpwalk причем дергаем вообще все дерево. Никаких проблем.
Гуглим. У кого-то забиты поллеры, у кого-то некорректные таймауты, какой-то баг связанный с этим исправлен в версии 2.2.3. У кого-то хитрая проблема с сетью и теряется UDP. Но это все не наш случай.
Что тогда?..
Интересный факт, если перезагрузить прокси
/etc/init.d/zabbix-proxy restart
То видно как начинает сокращаться очередь, но потом бах, опять что-то происходит и она моментально вырастает***.
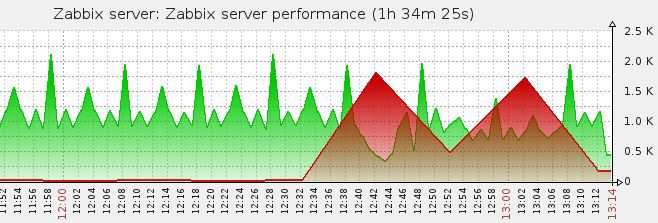
Что же происходит?..
Включаем расширенное логирование на zabbix-proxy
DebugLevel=4
Перезапускаем zabbix-proxy и ждем появления ошибок
Теперь вместо Network Error видим более полную информацию
Выглядит это примерно так
5414:20141218:125955.481 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
5414:20141218:125955.481 End of zbx_snmp_get_values():NETWORK_ERROR
5414:20141218:125955.481 End of zbx_snmp_process_standard():NETWORK_ERROR
5414:20141218:125955.481 In zbx_snmp_close_session()
5414:20141218:125955.481 End of zbx_snmp_close_session()
5414:20141218:125955.481 getting SNMP values failed: Cannot connect to "192.168.x.x:161": Too long.
5414:20141218:125955.481 End of get_values_snmp()
5414:20141218:125955.481 In deactivate_host() hostid:10207 itemid:43739 type:6
5414:20141218:125955.481 query [txnlev:1] [begin;]
5414:20141218:125955.481 query [txnlev:1] [update hosts set snmp_errors_from=1418896795,snmp_disable_until=1418896810,snmp_error='Cannot connect to "192.168.x.x:161": Too long.' where hostid=10207]
5414:20141218:125955.481 query [txnlev:1] [commit;]
5414:20141218:125955.481 SNMP agent item "ifOperStatus.["10143"]" on host "co-xx04" failed: first network error, wait for 15 seconds
5414:20141218:125955.481 deactivate_host() errors_from:1418896795 available:1
5414:20141218:125955.482 End of deactivate_host()
Статус 1, статус ошибки -1, число элементов 94
Здесь же вывод что это NETWORK_ERROR
И чуть ниже расшифровка Too long и деактивация хоста. Понятно что если хост деактивирован, данные с него получить нельзя, данные ставятся в очередь, вот и объяснение очереди.
Сразу же заинтересовал параметр errstat
Делаем cat /var/log/zabbix/zabbix_proxy.log | grep errstat
5412:20141218:130351.410 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:11
5433:20141218:130351.470 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
5430:20141218:130351.476 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
5417:20141218:130353.442 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:5
5420:20141218:130353.534 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
Ага, копаем глубже
Здесь должна быть картинка We need to go deeper, но не будет. Мне кажется она всех достала.
Делаем cat /var/log/zabbix/zabbxi_proxy.log | grep errstat:-1
5416:20141218:130353.540 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
5412:20141218:130355.571 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
5417:20141218:130355.591 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
...
5420:20141218:130453.187 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
5412:20141218:130455.206 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
5413:20141218:130455.207 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
Пришло время отключить мониторинг всех устройств за прокси кроме одного, т.к. иначе в логе слишком сложно разбираться. Все равно система в таком виде как сейчас для мониторинга не пригодна.
Отключаем, делаем
cat /var/log/zabbix/zabbxi_proxy.log | grep mapping_num
и перезагрузим прокси
Никаких ошибок первое время, да и mapping_num потихоньку растет от 1 все больше и больше (вырезаны отдельные строчки чтобы показать принцип)
Можно вечно смотреть за тем как растет mapping_num
7876:20141218:131251.660 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:4
7872:20141218:131251.681 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:6
7872:20141218:131251.919 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:8
7876:20141218:131251.919 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:9
7868:20141218:131351.965 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:13
10502:20141218:135237.884 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:31
10507:20141218:135238.244 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:62
12429:20141218:141637.942 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:31
12429:20141218:141637.966 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:31
12433:20141218:141651.142 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
А потом оппа 94, и -1 и too long. Т.е. сразу после запуска прокси тестирует устройства, посылает им SNMP запросы, увеличивая количество итемов в одном запросе. Очередь начинает быстро сокращаться. Потом он (то бишь прокси) доходит до волшебного числа 94, происходит сбой и устройства начинают отключаться заббиксом на 15 секунд, что в свою очередь начинает резко увеличивать очередь.
Как видим, здесь уже совсем не Network error, здесь уже Too long.
Ладно пробуем что-то найти по zabbix snmp too long, ничего.
Опять таймауты, перегрузка поллера… В одном интересном посте была информация, что такая ошибка возникала когда был неверно сформирован OID для итема, так что я дважды проверил все свои OID’ы в том числе через snmpget
Т.е. в итоге гугл мне помочь не смог.
Будем разбираться сами, это полезно.
Итак, что у нас есть?
Как только число итемов становится 94 (т.е. достаточно большим) что-то происходит и система сбивается.
Здесь опять картинка, которой не будет 
Пора лезть в код. В gentoo ничего качать не надо, уже все есть, так что я просто распаковал все в рабочую директорию.
Найдем сначала где выводится ошибка. Ищем по errstat
На удивление всего два таких места в файле с говорящим названием checks_snmp.c
вот эти два места:
со строки 745
/* communicate with agent */
status = snmp_synch_response(ss, pdu, &response);
zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld max_vars:%d",
__function_name, status, NULL == response ? (long)-1 : response->errstat, max_vars);
и со строки 938
status = snmp_synch_response(ss, pdu, &response);
zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld mapping_num:%d",
__function_name, status, NULL == response ? (long)-1 : response->errstat, mapping_num);
Пока нас интересует второй кусок (исходя из того что mapping_num есть только в нем)
Даже не программист видит, что у нас response NULL, а почему?..
Вспомним, что при errstat:-1, который теперь понятно откуда берется, у нас status:1. Т.е. функция snmp_synch_response возвращает 1, а что это значит?..
А это значит STAT_ERROR (1) (а еще она умеет STAT_TIMEOUT (2) и STAT_SUCCESS (0))
Как говорится непонятно, но здорово…
Зайдем с другой стороны, где-то здесь же в этом файле должен быть возврат NETWORK_ERROR попробуем разобраться где и почему.
Первое же вхождение в функции zbx_get_snmp_response_error (что как бы намекает)
Посмотреть код zbx_get_snmp_response_error
static int zbx_get_snmp_response_error(const struct snmp_session *ss, const DC_INTERFACE *interface, int status,
const struct snmp_pdu *response, char *error, int max_error_len)
{
int ret;
if (STAT_SUCCESS == status)
{
zbx_snprintf(error, max_error_len, "SNMP error: %s", snmp_errstring(response->errstat));
ret = NOTSUPPORTED;
}
else if (STAT_ERROR == status)
{
zbx_snprintf(error, max_error_len, "Cannot connect to "%s:%hu": %s.",
interface->addr, interface->port, snmp_api_errstring(ss->s_snmp_errno));
switch (ss->s_snmp_errno)
{
case SNMPERR_UNKNOWN_USER_NAME:
case SNMPERR_UNSUPPORTED_SEC_LEVEL:
case SNMPERR_AUTHENTICATION_FAILURE:
ret = NOTSUPPORTED;
break;
default:
ret = NETWORK_ERROR;
}
}
else if (STAT_TIMEOUT == status)
{
zbx_snprintf(error, max_error_len, "Timeout while connecting to "%s:%hu".",
interface->addr, interface->port);
ret = NETWORK_ERROR;
}
else
{
zbx_snprintf(error, max_error_len, "SNMP error: [%d]", status);
ret = NOTSUPPORTED;
}
return ret;
}
Ага. Т.е. мы со своим STAT_ERROR входим в switch где не попадаем ни под одно из приведенных условий, и таким образом получаем NETWORK_ERROR по дефолту.
Мы уже поняли что этот дефолт дезориентирует нас, нужно выяснить что же это за ошибка на самом деле. Код ошибки хранится в ss->s_snmp_errno, добавим вывод переменной в лог.
Программист из меня так себе, так что быстренько с помощью лома и чьей-то матери (с) сляпал патчик, вот такой:
diff -urN zabbix-2.2.5/src/zabbix_server/poller/checks_snmp.c zabbix-2.2.5.new/src/zabbix_server/poller/checks_snmp.c
--- zabbix-2.2.5/src/zabbix_server/poller/checks_snmp.c 2014-07-17 17:49:45.000000000 +0400
+++ zabbix-2.2.5.new/src/zabbix_server/poller/checks_snmp.c 2014-10-10 16:38:31.000000000 +0400
@@ -938,7 +938,7 @@
status = snmp_synch_response(ss, pdu, &response);
zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld mapping_num:%d",
- __function_name, status, NULL == response ? (long)-1 : response->errstat, mapping_num);
+ __function_name, status, NULL == response ? (STAT_ERROR == status ? (long) ss->s_snmp_errno : (long)-1) : response->errstat, mapping_num);
if (STAT_SUCCESS == status && SNMP_ERR_NOERROR == response->errstat)
{
Если статус STAT_ERROR выводить ss->s_snmp_errno
Закинул исходник заббикса в локальный репозиторий, быстро подправил ебилд и вперед.
Компилим, перезапускаем, ждем.
И вот она наша реальная ошибка.
11211:20141218:155253.362 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:18
11210:20141218:155253.393 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-5 mapping_num:94
Ошибка -5
Смотрим Net-SNMP snmp_api.h
#define SNMPERR_TOO_LONG (-5)
Что-то похожее было видно в логах, но по словосочетанию Too Long мы найти ничего не смогли, посмотрим что же это за ошибка и когда возникает.
в snmp_api.c можно это увидеть
еще немного кода
/*
* Make sure we don't send something that is bigger than the msgMaxSize
* specified in the received PDU.
*/
if (pdu->version == SNMP_VERSION_3 && session->sndMsgMaxSize != 0 && length > session->sndMsgMaxSize) {
DEBUGMSGTL(("sess_async_send",
"length of packet (%lu) exceeds session maximum (%lu)n",
(unsigned long)length, (unsigned long)session->sndMsgMaxSize));
session->s_snmp_errno = SNMPERR_TOO_LONG;
SNMP_FREE(pktbuf);
return 0;
}
/*
* Check that the underlying transport is capable of sending a packet as
* large as length.
*/
if (transport->msgMaxSize != 0 && length > transport->msgMaxSize) {
DEBUGMSGTL(("sess_async_send",
"length of packet (%lu) exceeds transport maximum (%lu)n",
(unsigned long)length, (unsigned long)transport->msgMaxSize));
session->s_snmp_errno = SNMPERR_TOO_LONG;
SNMP_FREE(pktbuf);
return 0;
}
Есть всего два варианта:
1. Длина данных которые мы хотим послать больше чем параметр msgMaxSize определенный в полученном PDU
2. Нижележащий транспорт не способен послать пакет такой длины
Возникает вопрос как же пофиксить эту ошибку. Из вышесказанного следует, что нужно искать получаем ли мы msgMaxSize, правильно ли мы это обрабатываем и т.д. и т.п. Но я исходники zabbix вижу в первый раз, а C во второй (ну ладно в третий).
Короче не вызывает энтузиазма… Да и поломать наверное что-нибудь можно будет.
Лирическое отступление:
Надо сказать, что во время разбирательств с этой проблемой, я в том числе наткнулся на информацию о массовой обработке SNMP. Т.е. zabbix одним запросом может запросить множество SNMP элементов данных.
Подробности SNMP bulk processing
Суть в том, что zabbix умеет запрашивать до 128 значений одним запросом, но не все устройства способны обработать эти 128 значений за один раз. И в zabbiх используется стратегия поиска максимального значения для каждого конкретного устройства. Мы кстати видели это в логах. Постепенное повышение mapping_num. Как только zabbix получает ошибку от устройства SNMPERR_TOO_BIG он по определенному алгоритму ищет максимальное значение возвращающее результаты без ошибок.
К чему это я.
Механизм обработки ошибки переполнения (назовем его так) в заббиксе есть, надо его всего лишь расширить на еще один случай.
Сам алгоритм расписан под выводом нашей ошибки.
Опять этот код
else if (1 < mapping_num &&
((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status))
{
/* Since we are trying to obtain multiple values from the SNMP agent, the response that it has to */
/* generate might be too big. It seems to be required by the SNMP standard that in such cases the */
/* error status should be set to "tooBig(1)". However, some devices simply do not respond to such */
/* queries and we get a timeout. Moreover, some devices exhibit both behaviors - they either send */
/* "tooBig(1)" or do not respond at all. So what we do is halve the number of variables to query - */
/* it should work in the vast majority of cases, because, since we are now querying "num" values, */
/* we know that querying "num/2" values succeeded previously. The case where it can still fail due */
/* to exceeded maximum response size is if we are now querying values that are unusually large. So */
/* if querying with half the number of the last values does not work either, we resort to querying */
/* values one by one, and the next time configuration cache gives us items to query, it will give */
/* us less. */
if (*min_fail > mapping_num)
*min_fail = mapping_num;
if (0 == level)
{
/* halve the number of items */
int base;
ret = zbx_snmp_get_values(ss, items, oids, results, errcodes, query_and_ignore_type, num / 2,
level + 1, error, max_error_len, max_succeed, min_fail);
if (SUCCEED != ret)
goto exit;
base = num / 2;
ret = zbx_snmp_get_values(ss, items + base, oids + base, results + base, errcodes + base,
NULL == query_and_ignore_type ? NULL : query_and_ignore_type + base, num - base,
level + 1, error, max_error_len, max_succeed, min_fail);
}
else if (1 == level)
{
/* resort to querying items one by one */
for (i = 0; i < num; i++)
{
if (SUCCEED != errcodes[i])
continue;
ret = zbx_snmp_get_values(ss, items + i, oids + i, results + i, errcodes + i,
NULL == query_and_ignore_type ? NULL : query_and_ignore_type + i, 1,
level + 1, error, max_error_len, max_succeed, min_fail);
if (SUCCEED != ret)
goto exit;
}
}
}
То есть все просто, нам надо добавить свое условие, не нарушив работу имеющихся. Для этого у нас есть все данные:
- status должен быть STAT_ERROR
- ss->s_snmp_errno должен быть SNMPERR_TOO_LONG
Учитываем еще что у нас два таких места (равно как и два вывода в лог-файл) и результирующий патч будет таким:
Наконец-то
diff -urN zabbix-2.2.5/src/zabbix_server/poller/checks_snmp.c zabbix-2.2.5.new/src/zabbix_server/poller/checks_snmp.c
--- zabbix-2.2.5/src/zabbix_server/poller/checks_snmp.c 2014-07-17 17:49:45.000000000 +0400
+++ zabbix-2.2.5.new/src/zabbix_server/poller/checks_snmp.c 2014-10-10 16:38:31.000000000 +0400
@@ -746,10 +746,10 @@
status = snmp_synch_response(ss, pdu, &response);
zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld max_vars:%d",
- __function_name, status, NULL == response ? (long)-1 : response->errstat, max_vars);
+ __function_name, status, NULL == response ? (STAT_ERROR == status ? (long)ss->s_snmp_errno : (long)-1) : response->errstat, max_vars);
if (1 < max_vars &&
- ((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status))
+ ((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status || (STAT_ERROR == status && SNMPERR_TOO_LONG == ss->s_snmp_errno)))
{
/* The logic of iteratively reducing request size here is the same as in function */
/* zbx_snmp_get_values(). Please refer to the description there for explanation. */
@@ -938,7 +938,7 @@
status = snmp_synch_response(ss, pdu, &response);
zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld mapping_num:%d",
- __function_name, status, NULL == response ? (long)-1 : response->errstat, mapping_num);
+ __function_name, status, NULL == response ? (STAT_ERROR == status ? (long) ss->s_snmp_errno : (long)-1) : response->errstat, mapping_num);
if (STAT_SUCCESS == status && SNMP_ERR_NOERROR == response->errstat)
{
@@ -1001,7 +1001,7 @@
}
}
else if (1 < mapping_num &&
- ((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status))
+ ((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status || (STAT_ERROR == status && SNMPERR_TOO_LONG == ss->s_snmp_errno)))
{
/* Since we are trying to obtain multiple values from the SNMP agent, the response that it has to */
/* generate might be too big. It seems to be required by the SNMP standard that in such cases the */
Компилируем, перезапускаем…
И вот результат:
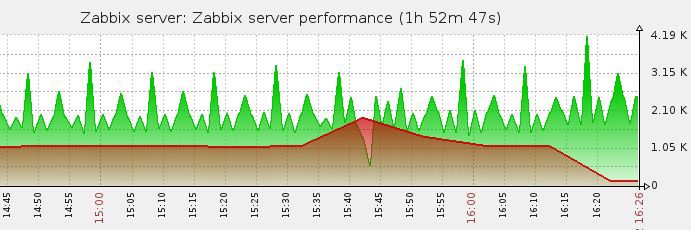
Ошибка Network Error пропала из логов.
Ура!..
Послесловие
Конечно, в действительности, поиск ошибки и решения занял больше времени. Пришлось больше ковырять исходники и zabbix и net-snmp, чтобы в итоге остановиться на двух местах в коде.
Но ощущение победы над «косной материей» бесценно.
* желание накатило 7 октября, а тогда 2.2.5 еще была замаскирована. По случайному совпадению ее размаскировали 10 октября;
** на время не смотрите, для написания статьи сымитировал ситуацию позже. Во время разборок, выдергивать из логов данные совершенно не было времени, поток, куда деваться;
*** да, да, картинку я тоже смоделировал. Представьте что там где зеленое в начале, там все красное А потом пила во время рестартов.
2014.12.31 UPD: По результатам обсуждения статьи, был открыт тикет (thanx to alexvl):
failure to send SNMPv3 requests that are «Too long» is not handled properly by SNMP bulk
Он был успешно закрыт (thanx to Aleksandrs Saveljevs) начиная с версий 2.2.9rc1, 2.4.4rc1, 2.5.0